上一篇文章《产品级AI应用的核心:上下文工程》介绍了上下文工程的一些设计方式,今天我们继续来聊聊其中的一个很重要的技术细节:Prompt Caching。
Agent技术让大模型的应用得到了飞速的发展,但同时也带来了巨大的token消耗。各家模型厂商纷纷推出了上下文缓存功能,一方面用于节省自身的算力资源,同时帮应用方节省成本。另一方面也可以显著降低首token的延迟,提升用户体验。
"
拿Claude Sonnet举例,缓存的输入token成本为0.30美元/百万token,而未缓存的成本为3美元/百万token------相差10倍。 gemini 2.5 pro的的输入百万token计价,无缓存是1.25美元,缓存的是0.31美元,成本效应明显。
这篇文章,就来详细唠唠大模型上下文缓存的技术细节,以及我们在AI应用开发中应该如何有效应用这一机制。
Prefix Caching详解
从我们的研发经验直觉来看,最简单的缓存方案是按整个Prompt缓存,也就是只有当新请求的Prompt和缓存中的某个Prompt完全一致时才能命中,显而易见,这种方案的命中率会很低。
所以,现在很多大模型厂商使用一种称为前缀缓存(Prefix Caching) 的技术方案,核心思想很简单:缓存已经处理过的请求(Prompt)的前缀部分,当新请求的开头与缓存中的前缀相同时,直接复用这些缓存,从而避免对相同部分的重复计算。
接下里我用一个具体的事例来解释这个算法流程,相信比枯燥的算法设计公式更容易理解。
Prefix Caching算法流程
首先算法会对一个请求Prompt按照token来分块(Block),假设我这里设置的块大小为4,即每个块能存储4个token。
此时,来了第一个请求,假设是"Once upon a time in a land far away lived a king who had three",数一数,一共15个token。
算法会按照块大小,对这个promp进行分词并缓存,针对第一个请求的操作如下:
[Once, upon, a, time]-> 填满并缓存为Block 0[in, a, land, far]-> 填满并缓存为Block 1[away, lived, a, king]-> 填满并缓存为Block 2[who, had, three]-> 填入Block 3,因为还未填满,所有暂时不会缓存。
接着,模型为第一个请求生成了第16个token,比如是daughters,算法会将daughters填入Block 3 ,现在Block 3 已满([who, had, three, daughters]),也会被缓存。如果模型还在继续生成新的token,则会申请新的Block,继续填充和缓存。
请注意 ,这里缓存的每个Block都有唯一的哈希值作为它的"身份证",哈希值的计算方式也非常巧妙,充分体现了前缀缓存 算法中前缀这一特性。一个Block的哈希值由以下三部分共同决定:
- 父哈希值: 指向上一块的哈希值,例如Block 1 的父Block就是Block 0,以此类推。
- 块内token: 当前块内包含的所有token,例如Block 1 的内部次元就是
[in, a, land, far]] - 额外哈希: 这个主要用于处理一些特殊情况,例如有多模态输入时(比如图片),虽然在token序列里只是一些占位符,但实际内容千差万别。因此,需要把图片本身的哈希值也加入计算,以区分不同图片。
拿上述的第一个请求来说:
- Block 0的哈希:
hash((父哈希=None,块内token="Once upon a time")) - Block 1的哈希:
hash((父哈希=Block 0的哈希,块内token="in a land far")) - Block 2的哈希:
hash((父哈希=Block 1的哈希,块内token="away lived a king"))
可以看到,Block缓存存在严格的前缀依赖关系,一个新的Prompt请求若想要重用Block 1 的缓存,那么它的前缀必须和[Block 0, Block 1]保持一致,想要重用Block 2 的缓存,那么前缀必须和[Block 0, Block 1, Block 2]保持一致。这就是前缀缓存的核心理念。
接着往下看,此时来了第二个请求,假设是"Once upon a time in a land far away lived a queue",这次是12个token。
按照块大小,正好可以被划分成三块[Once upon a time],[in, a, land, far],[away, lived, a, king],接着,算法开始检查是否有可重用的缓存。
[Once, upon, a, time]命中了Block 0 ,[in, a, land, far]由于其块内token和前缀都与Block 1 一样,因此可以复用Block 1 。第三部分[away, lived, a, king],由于其块内token与Block 2 不同,通过上述的哈希算法计算,无法直接使用Block 2的缓存,此时算法会重新申请一个新的Block来承载这4个token。
当大模型处理完每个请求时,会尝试释放其所占用的缓冲块,若此时缓存块的引用计数为0时(每次重用,引用计数会加1),算法会将此块放入一个LRU的的空闲队列中,等待下次复用,若在指定阈值的时间内依旧没有复用,则直接销毁,节约内存。
到这里,大致的算法流程也就讲清楚了,具体到单个缓存结构的设计、缓存池的设计、缓存淘汰策略等非常细节的问题,由于会干扰主线内容理解,这里就不展开了,感兴趣的读者可以通过这篇文章深入了解:docs.vllm.ai/en/stable/d...
看到这里,我们可能会产生两个疑问:
- 前文反复提到的Block缓存,其中缓存的到底是什么内容?
- 每个Block缓存是否能够复用,为何不能只看Block内部的token是否一致,而一定要求它们之前的所有token(前缀)也一样?
要理解这两个问题,就要深入到大模型的注意力机制,咱们接着往下看。
为何这样设计 - 大模型的注意力机制
注意力机制是现代各类大模型的核心,我公众号的第一篇文章《大语言模型(LLM)的原理与应用》对其基础原理有过详细的解读。要了解上述的两个问题,我们需要再次深入其中。
首先要明白,大模型在处理"我爱你"这三个字的时候,它本身是无法理解其顺序的。它看到的只是一堆独立的token。而同样一个词,在不同的句子中,甚至是在同一个句子的不同位置,所表达的语义都可能不同,因此,位置很重要。
为了让大模型理解"我"在第一个,"爱"在第二个,"你"在第三个,注意力机制中引入了一个关键技术 ------ 位置编码。
上述的输入中的每个字,实际送入注意力机制模块的真正输入为:输入向量 = 词向量 + 位置编码
- 词向量 (Token Embedding): 句子中的每个词或字(token)都会被转换成一个数学向量。这个向量代表了该词的"语义含义"。比如,"苹果"和"香蕉"的词向量在空间中会比较接近。这个阶段,向量本身不包含位置信息。
- 位置编码 (Positional Encoding): 为句子中的每一个"位置"(第1个、第2个、第3个...)创建一个专属的、独一无二的向量,也就是"位置向量"。
现在,每个token有了携带位置信息的输入向量。接下来,大模型会为每个token生成它专属的Q、K、V三个向量。
- Q (Query, 查询): 代表为了更好地理解当前这个 token,我需要去寻找什么样的信息。
- K (Key, 键): 代表我这个 token 能提供什么样信息的"标签"或"索引"。
- V (Value, 值): 代表我这个 token 实际蕴含的"信息内容"。
至于这三个向量如何计算得到的,可以去看那篇原理解读的文章,这里就不再详述。
因为GPT类模型都是一种自回归式的生成模型,依据历史的token信息,不断生成新的token。生成每一个新token时,都需要执行自注意力的计算,大致流程为:
- 对于当前要生成的新token,大模型先计算出它的Q向量。
- 这个Q向量会去和它前面所有token的键向量K进行匹配,计算出相关性分数。
- 然后用这个分数,对前面所有的token的值向量V进行加权求和,得到一个融合了上下文信息的向量。
- 这个融合后的向量,再经过几步处理,最终生成新的token。
通过这个流程,我们可以了解到,当大模型生成第100个token时,它需要用到前面99个token的K和V向量,当它生成第101个token时,它又需要用到前面100个token的K和V向量。这过程非常重复和耗时。
假设我们有这样一个场景, 比如一个客服机器人:
第一次请求的Prompt:系统指令:你是一个专业的汽车销售顾问,请根据客户问题回答。客户问题:我想买一辆适合家用的SUV,预算30万,有什么推荐?
大模型需要逐字处理这个长长的Prompt,计算每一个token的K和V向量,为生成回答做准备。假设这个过程需要2秒。
第二次请求的Prompt:系统指令:你是一个专业的汽车销售顾问,请根据客户问题回答。客户问题:我对电车更感兴趣,有什么建议吗?
你会发现,两个 Prompt 有一个非常长、完全相同的前缀,如果没有缓存技术,模型会傻傻地把这个长前缀 重新计算一遍,再次生成其中每个 token 的 K 和 V 向量,又浪费了将近 2 秒的时间。
现在可以回答Block缓存的到底是什么结果了:缓存中其实就是这个Block里的每个token(比如前文提到的Block大小是4,那一个Block就有4个Token),它们在模型所有的注意力层里计算出的K和V向量。
为什么不缓存Q(Query)向量呢? 通过以上简化描述的注意力计算流程,我们可知,Query 向量是为当前正在处理的 token 生成的,它代表"我要去问什么",是主动方。而K和V向量代表上下文历史,是被动方。当处理新token时,我们会为这个新token生成一个新的Q向量,然后用这个Q去匹配缓存中海量的历史K、V。所以K和V是可以复用的状态信息,而Q是每次新生成的。
再来上文中的第二个问题:复用为何一定要求前缀一样?
通过前文自注意力计算的流程可知,每个token会关注它前面的所有token,并根据相关性计算出一个加权和,也就是融合了上下文信息的上下文向量。而一个token的缓存要能被复用,它们除了token的语义向量需要一致外,上下文向量也必须一致。因此,就强制要求了必须有相同的前缀。
如何应用Prefix Caching
前文详细分析了前缀缓存的设计原理,很明显,只要缓存命中率较高,它能大大减少首个token的生成时间,以及模型推理的成本。
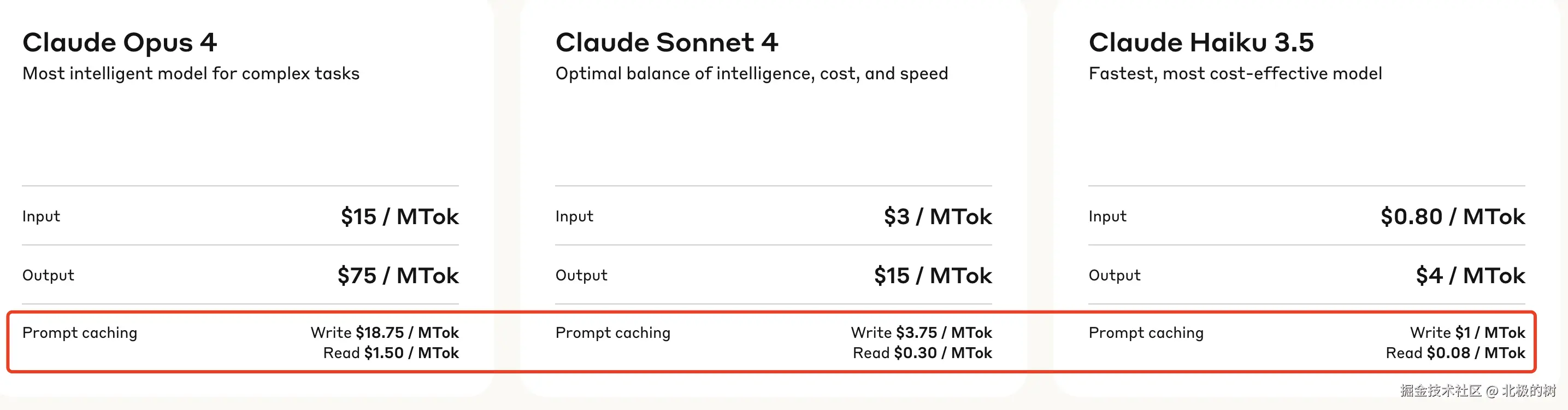
可以看到,Claude Sonnet 4缓存的输入成本仅0.3美元/百万token,是未缓存的1/10。
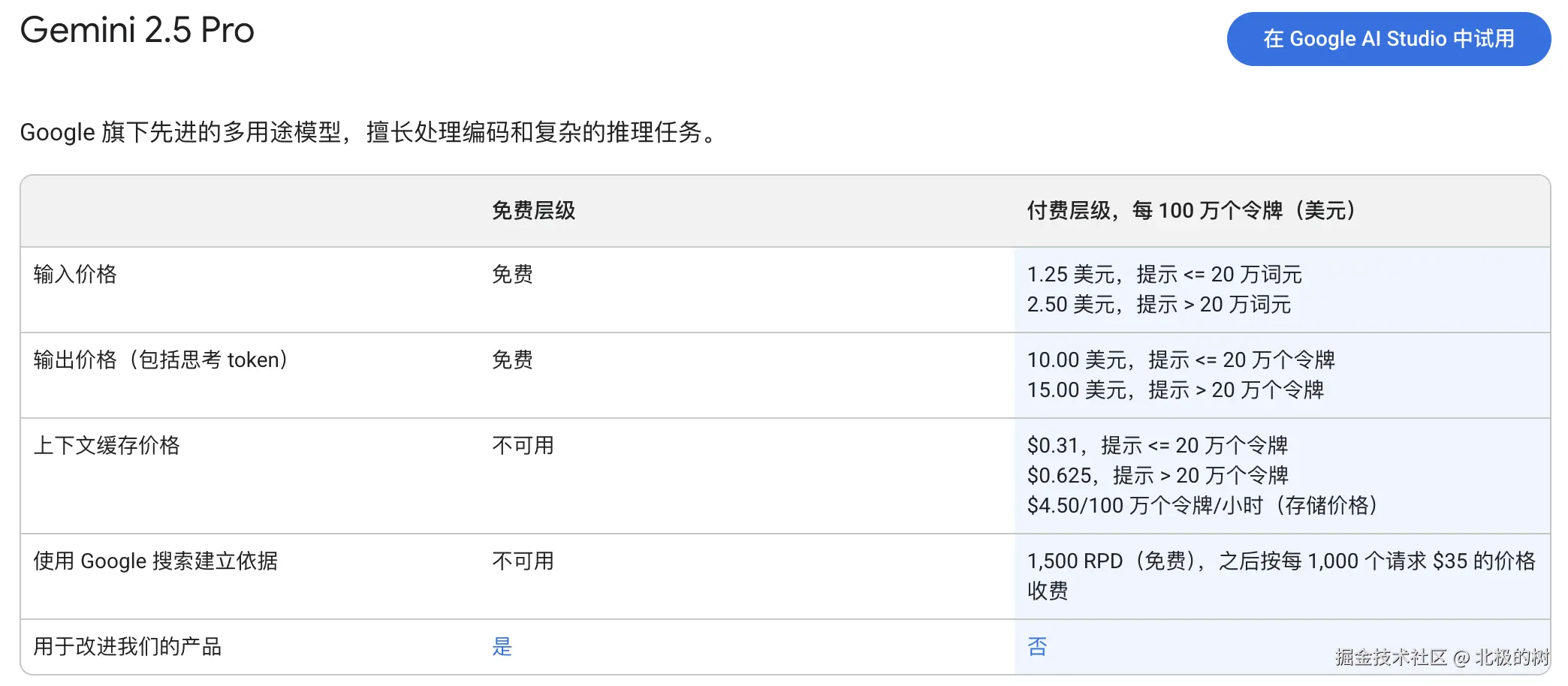
Gemini的缓存价格相比于未缓存也大幅下降。
所以问题的关键就变成了在实际的AI应用场景中,我们去设计上下文工程时,如何提升缓存的命中率。 换句话说,我们的设计方式应该如何与Prefix Caching的工作原理对齐。
接下里,我会列举一些在实际应用中提升缓存命中率的关键策略。
静态前置,动态后置
这是最核心,最重要的原则。在构建Prompt 模板时,将模板中的静态部分放在最前面,将动态变化的部分尽可能地向后推迟。
静态部分一般包括系统指令、角色设定、固定的 few-shot 示例、输出的格式要求等在多次请求中都保持不变的内容。而动态部分则是用户的具体提问、从向量库中检索的实时信息等。
这样可以确保最大长度的前缀被缓存和复用。
智能排序动态输入
如果你的 Prompt 包含多个动态输入,请按照共享范围从大到小的顺序来排列它们。
以一个典型的RAG应用为例,你有三个动态输入:
- 用户问题 :几乎每个请求都唯一。 (共享范围最小)
- 检索到的文档:可能会有多个用户查询到同一篇热门文档。 (共享范围中等)
- 用户所属部门:同一个部门的用户可能会有相似的查询模式,可以共享一些部门特定的指令或文档。 (共享范围较大)
理想的排序是[通用系统指令] [部门特定指令或信息] [检索到的文档] [用户问题],这样可以尽量让缓存能够复用。
优化对话历史的处理
聊天机器人是 Prefix Caching 的绝佳应用场景。对话历史本身就是一个不断增长的前缀。每一轮对话,用户的输入和模型的输出都会被追加到历史中。下一轮请求的 Prompt 就是完整的历史+用户的新输入。
由于前 N-1 轮的对话历史是完全固定的,它的缓存可以被完美复用,大模型只需对最新的用户输入进行增量计算即可。
我们要做的就是确保每一轮"User: ...\nAssistant: ...\n"的格式完全统一。
通过综合运用以上策略,我们可以在应用层面尽量却提升Prefix Caching的命中率,显著降低调用模型API的成本及首token延迟时间。