你有没有觉得,有时候问大模型一个简单问题,它却"想太多",慢吞吞地输出一长串你并不需要的推理过程?这种"过度思考"不仅拖慢了响应速度,还悄悄燃烧着宝贵的计算资源。
现在,快手给出了一个优雅的解决方案。他们旗下Kwaipilot团队扔出了一颗重磅炸弹:开源了具备"自动思考"(AutoThink)能力的400亿参数大模型------KAT-V1。
这不仅仅是又一个开源模型,它可能代表着大模型推理效率的一次范式革命。简单来说,KAT-V1是一个懂得"什么时候该动脑,什么时候该凭直觉"的聪明家伙。
像人一样,拥有"快思"与"慢想"
KAT-V1最迷人的地方,就是它的AutoThink机制。它内置了一套判断系统,能根据你提出任务的复杂度,在两种模式间无缝切换:
- 直答模式(Think-off):当你问"法国的首都是哪里?"这种简单事实时,它会立刻给出答案"巴黎",干净利落,绝不废话。
- 思考模式(Think-on):当你抛出一个复杂的数学题或需要调试一段棘手的代码时,它会自动开启"学霸模式",启动逻辑严密的思维链(Chain-of-Thought)进行多步推理,确保答案的准确性。
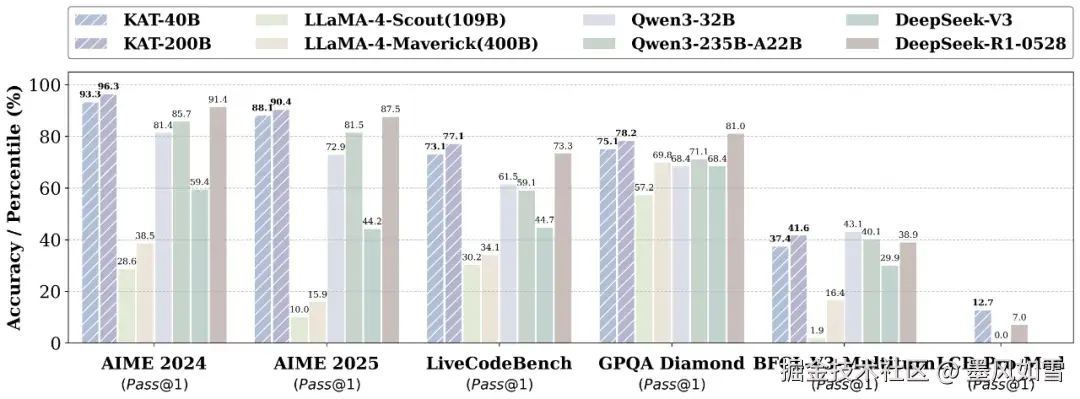
这种动态切换的能力,解决了行业内普遍存在的"过度思考"顽疾。它不再对所有问题都"杀鸡用牛刀",从而大幅降低了响应延迟和Token消耗。根据官方报告,KAT-V1的平均Token使用量能减少约30%,这意味着更快、更省钱。

如何炼成这身"偷懒"的绝活?
让模型学会判断任务复杂度,听起来玄乎,但快手团队用了一套扎实的组合拳:
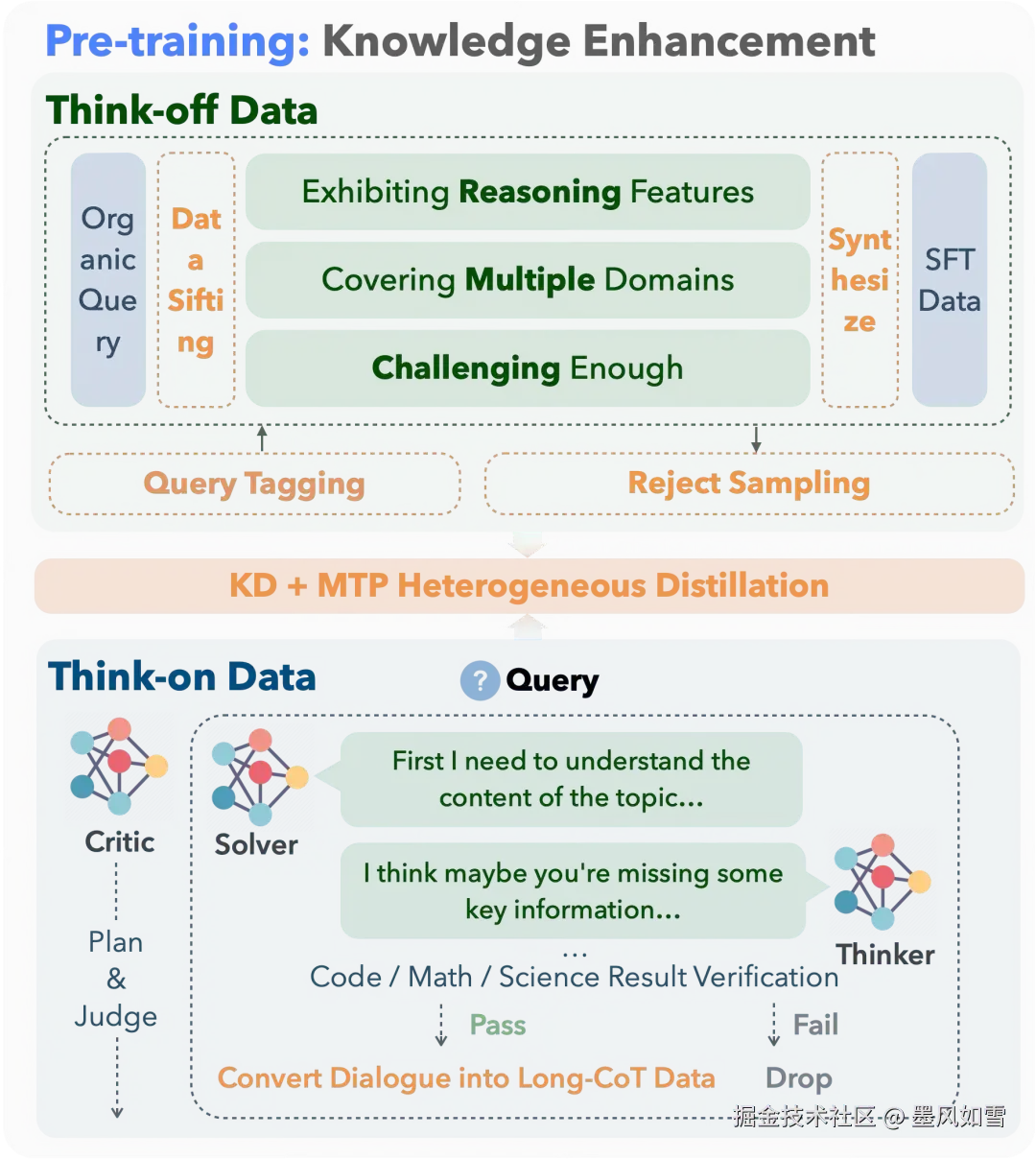
首先,他们构建了一套独特的"双模式"数据集,专门用来训练模型区分哪些任务需要深思熟虑,哪些可以快速作答。
其次,在训练中,他们巧妙地玩起了"知识蒸馏"。他们请来了两位"顶级家教"------一个擅长推理的老师(如DeepSeek-R1)和一个擅长直答的老师(如DeepSeek-V3),通过一种叫MTP(多标记预测)的高效方法,让KAT-V1以极低的成本学到了两位老师的精髓。
最后,为了让模型的判断力更上一层楼,团队引入了名为Step-SRPO的强化学习算法。这个算法设计了双重奖励:不仅最终答案要对,选择的"思考模式"也要对。选对了方法有奖,选错了要"挨罚",通过这种方式,KAT-V1的决策能力被磨练得炉火纯青。
不只高效,而且强大
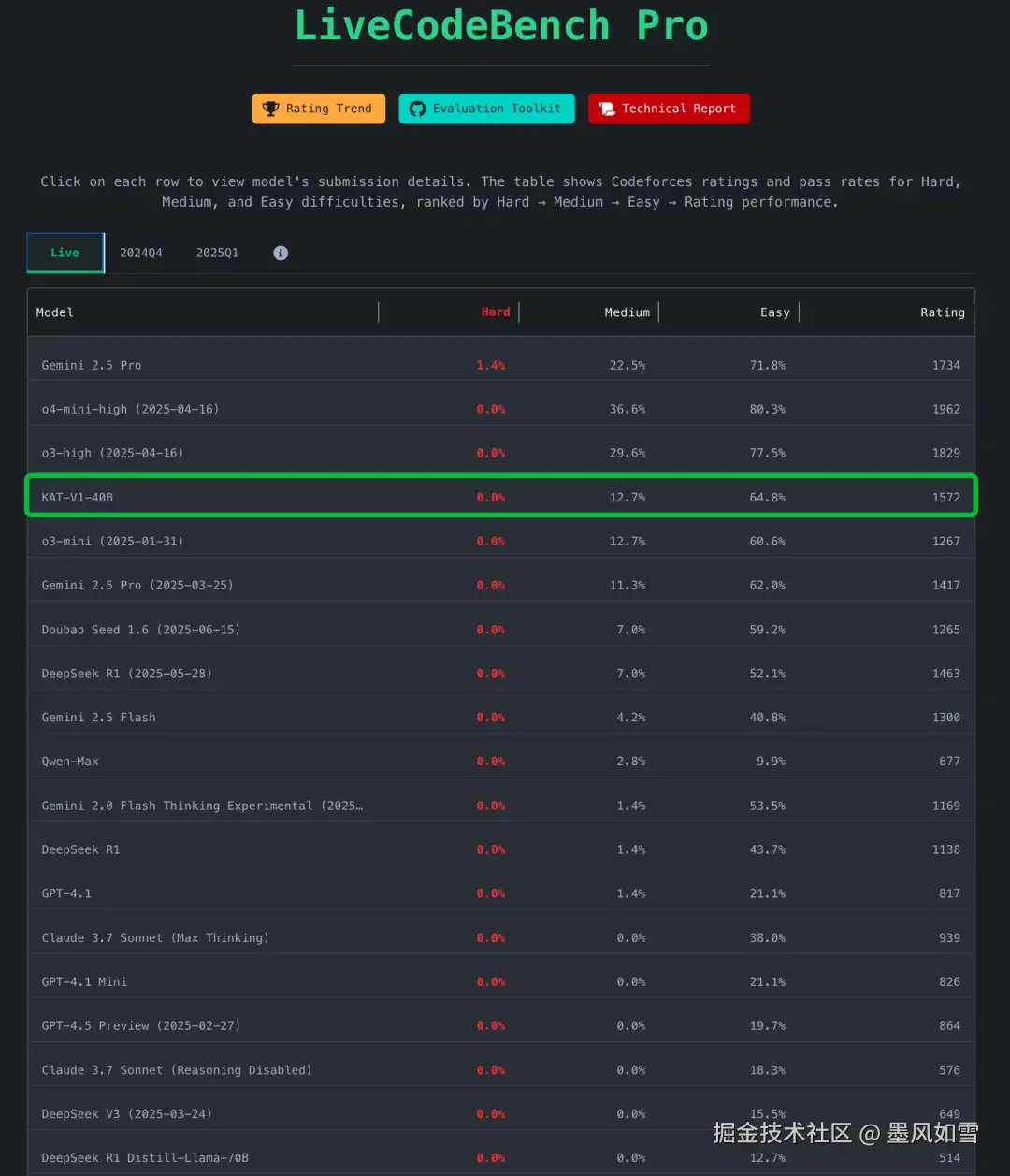
"偷懒"的背后,是绝对的实力。在多个公认的推理密集型基准测试(如数学、代码、常识推理)中,40B参数的KAT-V1表现出了惊人的战斗力,其性能媲美甚至超过了一些参数量远大于它的模型,比如DeepSeek-R1和Qwen2-72B。
更重要的是,它已经在快手内部的代码助手Kwaipilot中得到了实战检验,证明了其在真实工业环境下的稳定与可靠。这不仅仅是一个躺在论文里的概念,而是一个已经能创造价值的生产力工具。

开源,与社区共赴未来
快手这次的开源诚意十足。他们不仅放出了40B模型的权重,还提供了详尽的技术报告和Hugging Face上的预览版,让每一位开发者都能亲手体验这个会"思考"的模型。
- 技术报告 :arXiv:2507.08297v1
- 模型地址 :Hugging Face: Kwaipilot/KAT-V1-40B
团队还透露,一个更强大的200B参数MoE版本正在训练中,未来还将陆续开源1.5B、7B、13B等更小规模的模型,以及相关的训练数据与强化学习代码。
总而言之,KAT-V1的出现,让我们看到了大模型发展的另一个重要方向:在追求更强的能力之外,如何让AI变得更"知情识趣"、更高效实用。它不再是一个只会埋头苦算的"书呆子",而更像一个懂得权衡、张弛有度的"智慧伙伴"。这波,快手玩得相当漂亮。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站