🔥 官方演示 : Baidu AI Studio |
📝 论文 : 技术报告
简介
PaddleOCR-VL 是一款专为文档解析设计的顶尖且资源高效的模型。其核心组件是 PaddleOCR-VL-0.9B,一个轻量但强大的视觉语言模型(VLM),它结合了 NaViT 风格的动态分辨率视觉编码器与 ERNIE-4.5-0.3B 语言模型,以实现精准的元素识别。这一创新模型高效支持 109 种语言,擅长识别复杂元素(如文本、表格、公式和图表),同时保持极低的资源消耗。通过对广泛使用的公开基准测试和内部基准测试的全面评估,PaddleOCR-VL 在页面级文档解析和元素级识别中均达到 SOTA 性能。它显著优于现有解决方案,在与顶级 VLMs 的竞争中展现出强劲实力,并提供快速的推理速度。这些优势使其非常适合实际场景中的部署。
核心特性
-
轻量而强大的 VLM 架构: 我们提出了一种专为高效推理设计的创新视觉语言模型,在元素识别中表现卓越。通过将 NaViT 风格的动态高分辨率视觉编码器与轻量级 ERNIE-4.5-0.3B 语言模型相结合,我们显著提升了模型的识别能力和解码效率。这一集成在保持高精度的同时降低了计算需求,使其非常适合高效且实用的文档处理应用。
-
文档解析的 SOTA 性能: PaddleOCR-VL 在页面级文档解析和元素级识别中均达到最先进的性能。它显著优于现有的基于流水线的解决方案,并在文档解析领域与领先的视觉语言模型(VLMs)展现出强劲的竞争力。此外,它在识别复杂文档元素(如文本、表格、公式和图表)方面表现出色,适用于包括手写文本和历史文档在内的多种挑战性内容类型。这使得它具有高度通用性,适用于广泛的文档类型和场景。
-
多语言支持: PaddleOCR-VL 支持 109 种语言,涵盖全球主要语言,包括但不限于中文、英文、日文、拉丁文和韩文,以及具有不同书写系统和结构的语言,如俄文(西里尔字母)、阿拉伯文、印地文(天城体)和泰文。这种广泛的语言覆盖大幅提升了该系统在多语言和全球化文档处理场景中的适用性。
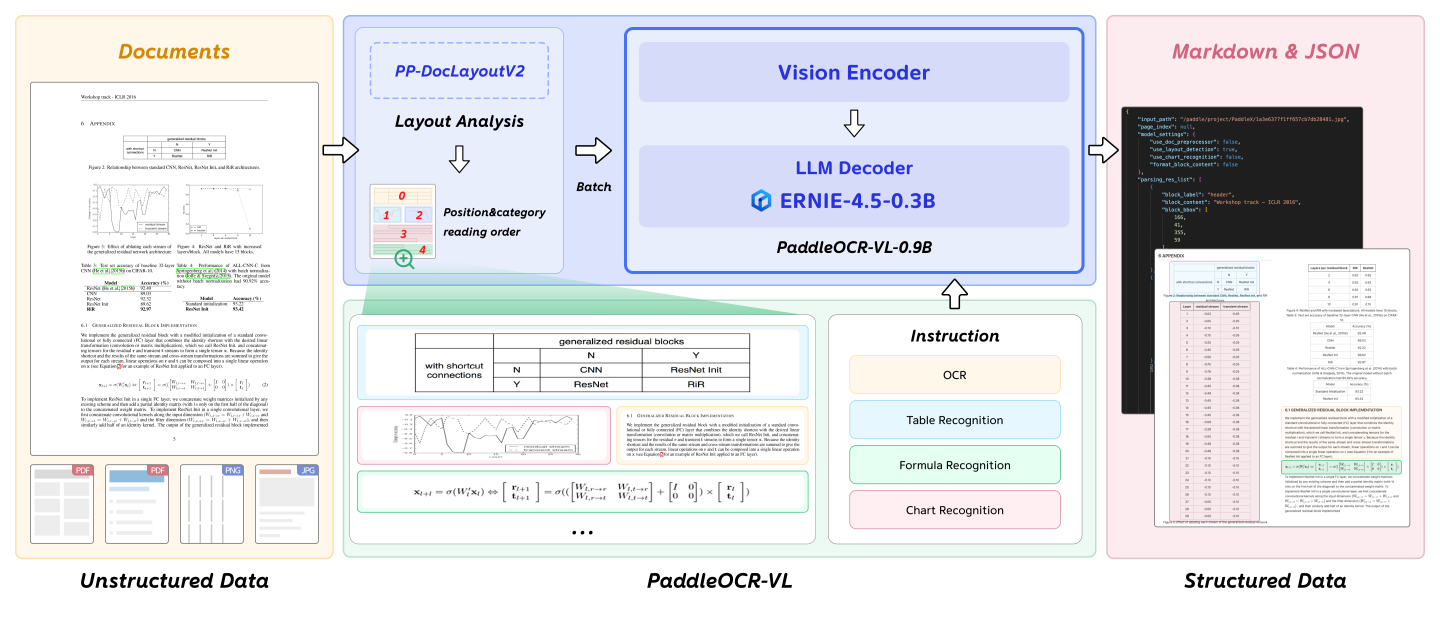
模型架构
新闻
2025.10.16🚀 我们发布了PaddleOCR-VL------一个通过0.9B超紧凑视觉语言模型实现多语言文档解析的工具,具备SOTA性能。
使用说明
安装依赖
bash
python -m pip install paddlepaddle-gpu==3.2.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
python -m pip install -U "paddleocr[doc-parser]"
python -m pip install https://paddle-whl.bj.bcebos.com/nightly/cu126/safetensors/safetensors-0.6.2.dev0-cp38-abi3-linux_x86_64.whlWindows 用户请使用 WSL 或 Docker 容器。
基本用法
命令行用法:
bash
paddleocr doc_parser -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.pngPython API 用法:
python
from paddleocr import PaddleOCRVL
pipeline = PaddleOCRVL()
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png")
for res in output:
res.print()
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")加速视觉语言模型推理的优化服务器方案
-
启动VLM推理服务器(默认端口为
8080):bashdocker run \ --rm \ --gpus all \ --network host \ ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlex-genai-vllm-server -
调用PaddleOCR命令行接口或Python应用程序接口:
bashpaddleocr doc_parser \ -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png \ --vl_rec_backend vllm-server \ --vl_rec_server_url http://127.0.0.1:8080/v1pythonfrom paddleocr import PaddleOCRVL pipeline = PaddleOCRVL(vl_rec_backend="vllm-server", vl_rec_server_url="http://127.0.0.1:8080/v1") output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png") for res in output: res.print() res.save_to_json(save_path="output") res.save_to_markdown(save_path="output")
更多使用详情和参数解释,请参阅文档。
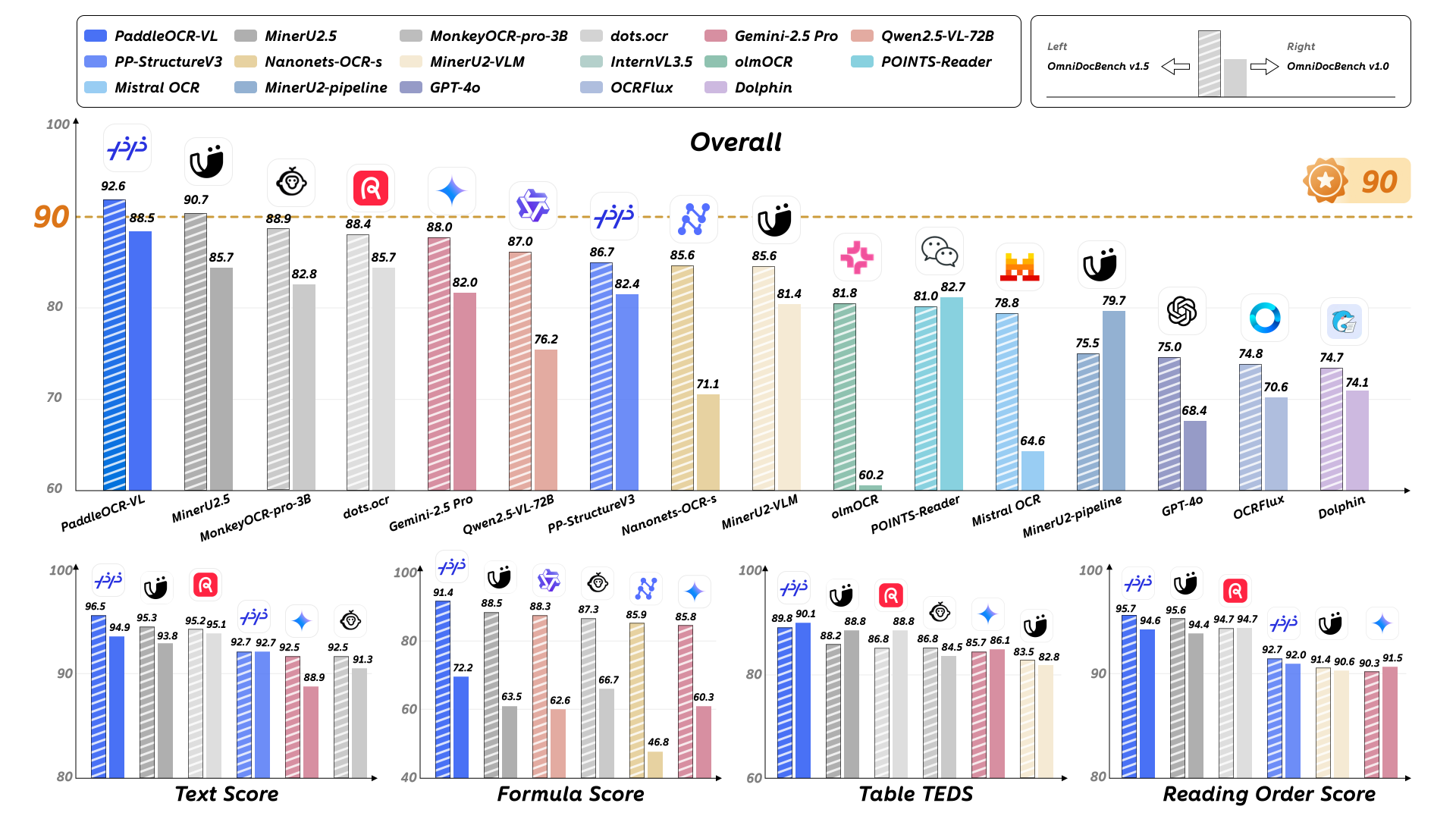
性能表现
页面级文档解析
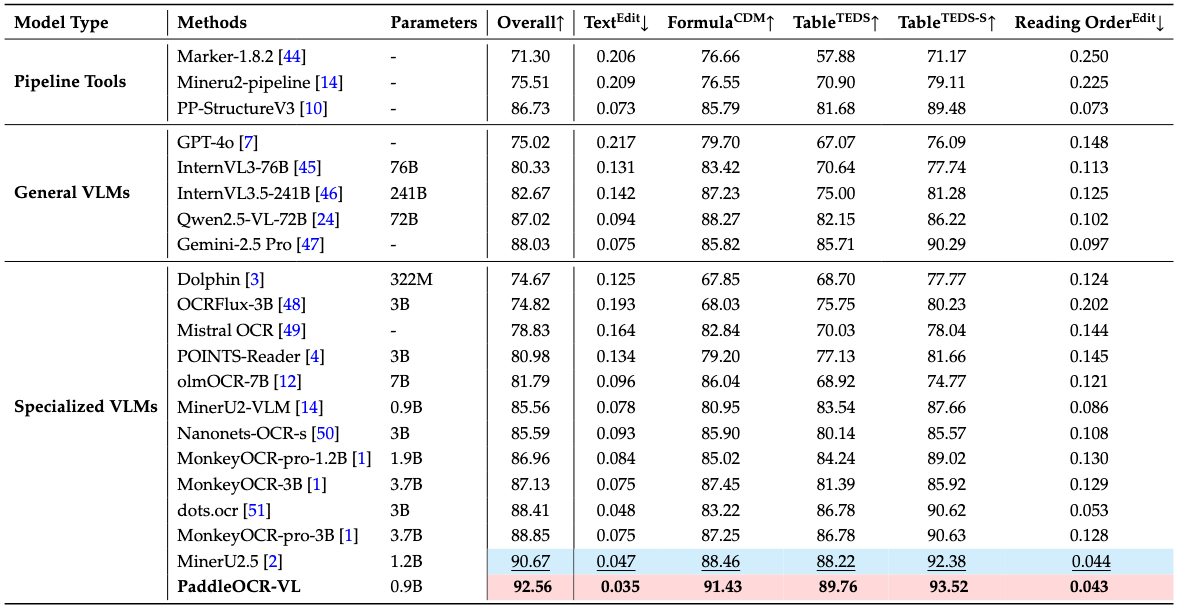
1. OmniDocBench v1.5
PaddleOCR-VL在OmniDocBench v1.5评测中,整体指标及文本、公式、表格、阅读顺序任务均达到SOTA效果
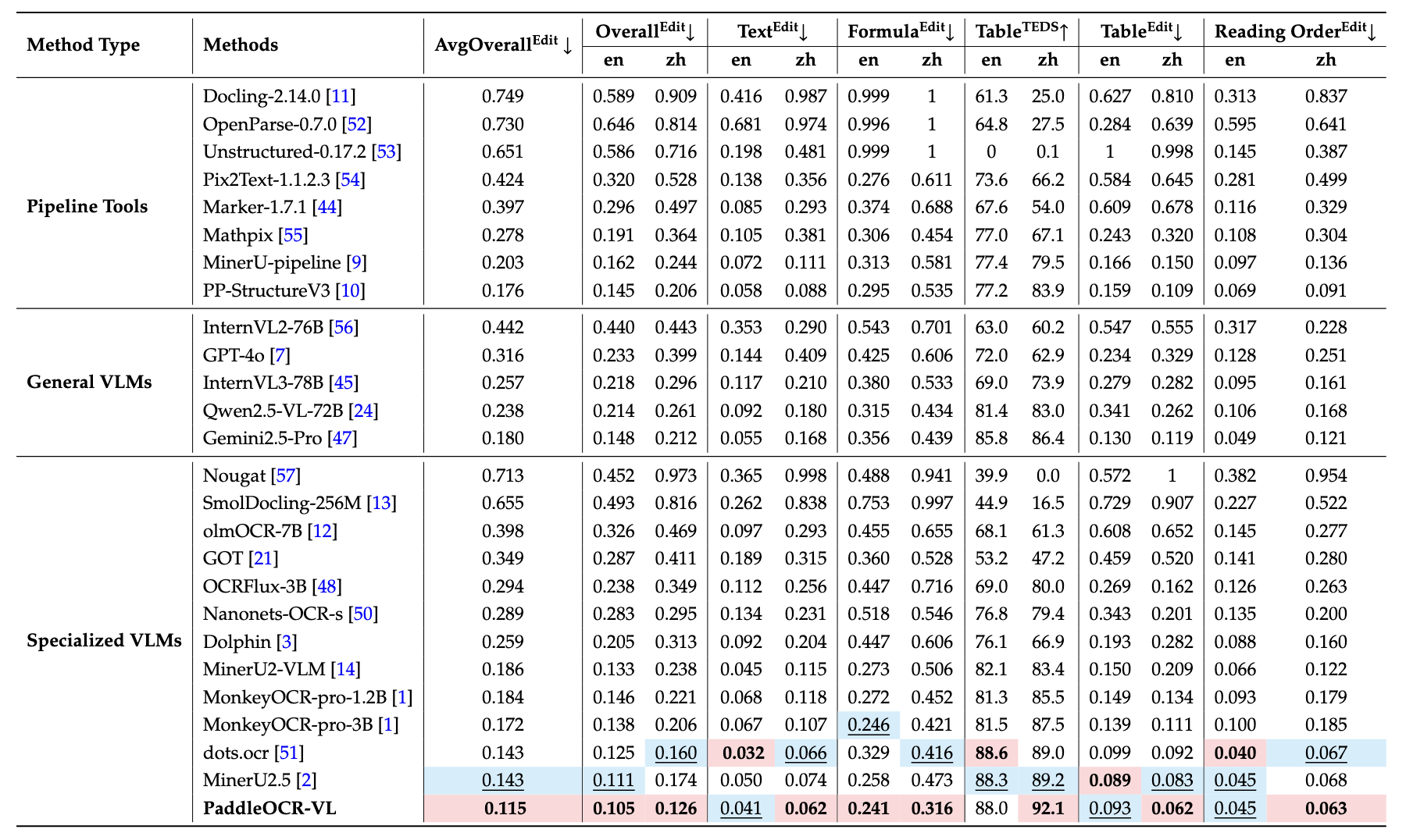
2. OmniDocBench v1.0
PaddleOCR-VL 在 OmniDocBench v1.0 的总体、文本、公式、表格和阅读顺序几乎所有指标上都达到了 SOTA 性能
说明:
- 指标数据来自MinerU、OmniDocBench以及我们内部的评估结果。
元素级识别
1. 文本
OmniDocBench-OCR模块性能对比
PaddleOCR-VL在处理多样化文档类型时展现出强大且通用的能力,使其成为OmniDocBench-OCR模块性能评估中的领先方案。

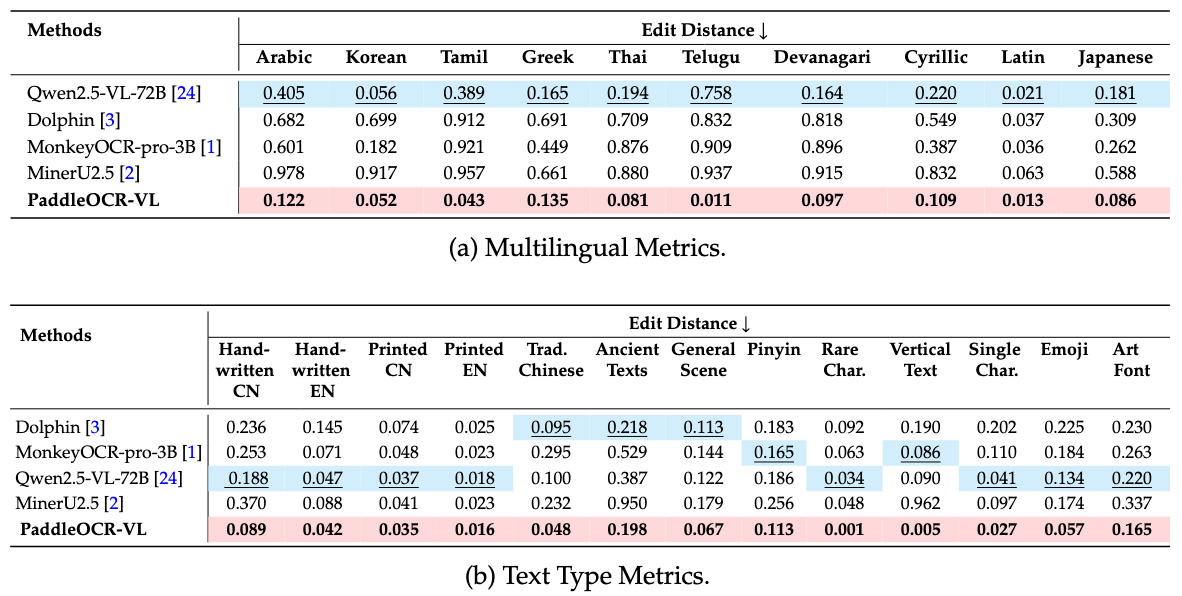
自研OCR性能对比
自研OCR提供了对多种语言和文本类型的性能评估。我们的模型在所有评测文字中均展现出卓越的准确率,保持着最低的编辑距离。
2. 表格
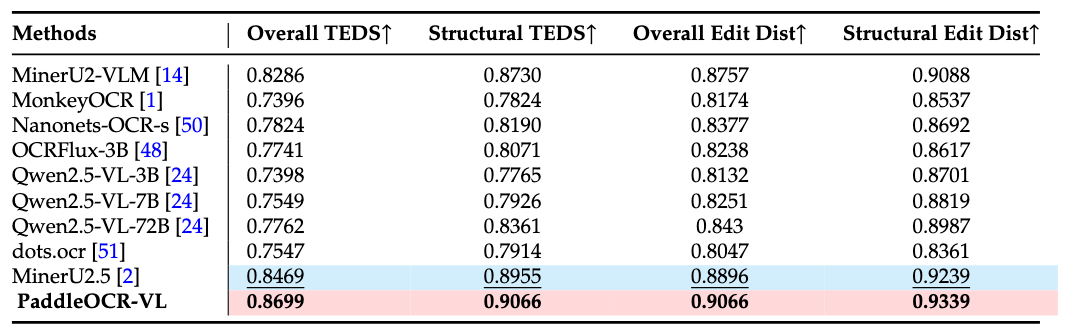
自研表格性能对比
我们的自建评测集涵盖了多种类型的表格图像,包括中文、英文、中英混合表格,以及具有不同特征的表格,例如全边框、部分边框或无边框,书籍/手册格式、列表、学术论文、合并单元格,以及低质量、带水印等。PaddleOCR-VL 在所有类别中均表现出色。
3. 公式
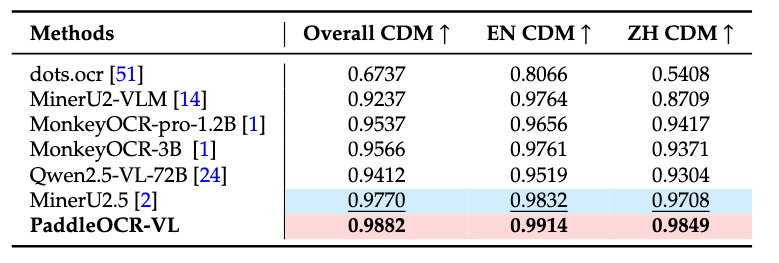
内部公式性能对比
内部公式评估集包含简单印刷体、复杂印刷体、摄像头扫描件和手写公式。PaddleOCR-VL在各类别中均展现出最优性能。
4. 图表
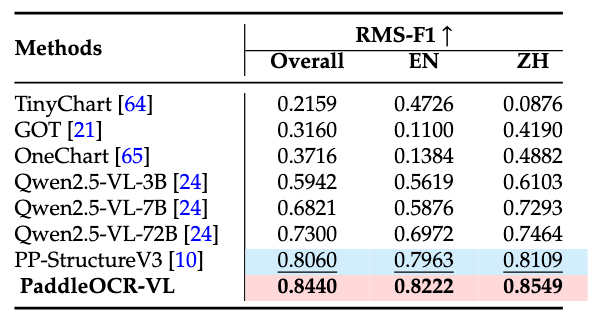
内部图表性能对比
评估集大致分为11个图表类别,包括柱线混合图、饼图、100%堆叠柱状图、面积图、柱状图、气泡图、直方图、折线图、散点图、堆叠面积图和堆叠柱状图。PaddleOCR-VL不仅优于专业的OCR视觉语言模型,还超越了一些72B级别的多模态语言模型。
可视化
全面的文档解析




文本


表格
公式


图表
 ## 致谢
## 致谢
我们要感谢ERNIE、Keye、MinerU、OmniDocBench提供了宝贵的代码、模型权重和基准测试数据。同时感谢所有人对本开源项目的贡献!
引用
如果您觉得PaddleOCR-VL对您有帮助,欢迎给我们点赞和引用。
bibtex
@misc{cui2025paddleocrvlboostingmultilingualdocument,
title={PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model},
author={Cheng Cui and Ting Sun and Suyin Liang and Tingquan Gao and Zelun Zhang and Jiaxuan Liu and Xueqing Wang and Changda Zhou and Hongen Liu and Manhui Lin and Yue Zhang and Yubo Zhang and Handong Zheng and Jing Zhang and Jun Zhang and Yi Liu and Dianhai Yu and Yanjun Ma},
year={2025},
eprint={2510.14528},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.14528},
}