目录
前言
使用场景:随着用户使用量的增加,用户投诉量也日益增加,为了方便售后人员处理解决投诉问题以及售后问题的分类以及分析,所以利用NLP对投诉进行文本分类,分类为:用户抱怨、整机、异味、硬件、软件等等类型。随着系统的使用,标签矫正,可以使得模型在持续迭代日益精准。
预训练模型:
bert-base-chinese
谷歌开源的预训练模型,2018年至今,依然bert神一般的存在,性价比高、使用成本低,无脑套用就完事了。
前置条件
下载项目
shell
git clone https://github.com/zpskt/MultiModelNLP.git
cd MultiModelNLP创建环境
shell
conda create -n sentiment --override-channels -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ python=3.12.11安装依赖
shell
conda activate sentiment
pip install -r src/bert/requirements.txt
#pip install -r src/bert/requirements.txt -i https://mirrors.aliyun.com/pypi/simple/激活环境
shell
conda activate sentiment下载模型
如果你没有vpn或者任何代理服务器,那么访问huggingface.co会显示失败。此时可以使用国内的源:https://hf-mirror.com
配置环境变量
Linux/Mac
bash
export HF_ENDPOINT=https://hf-mirror.com你也可以添加到bash中
bash
vim ~/.zshrc # linux为 vim ~/.bashrc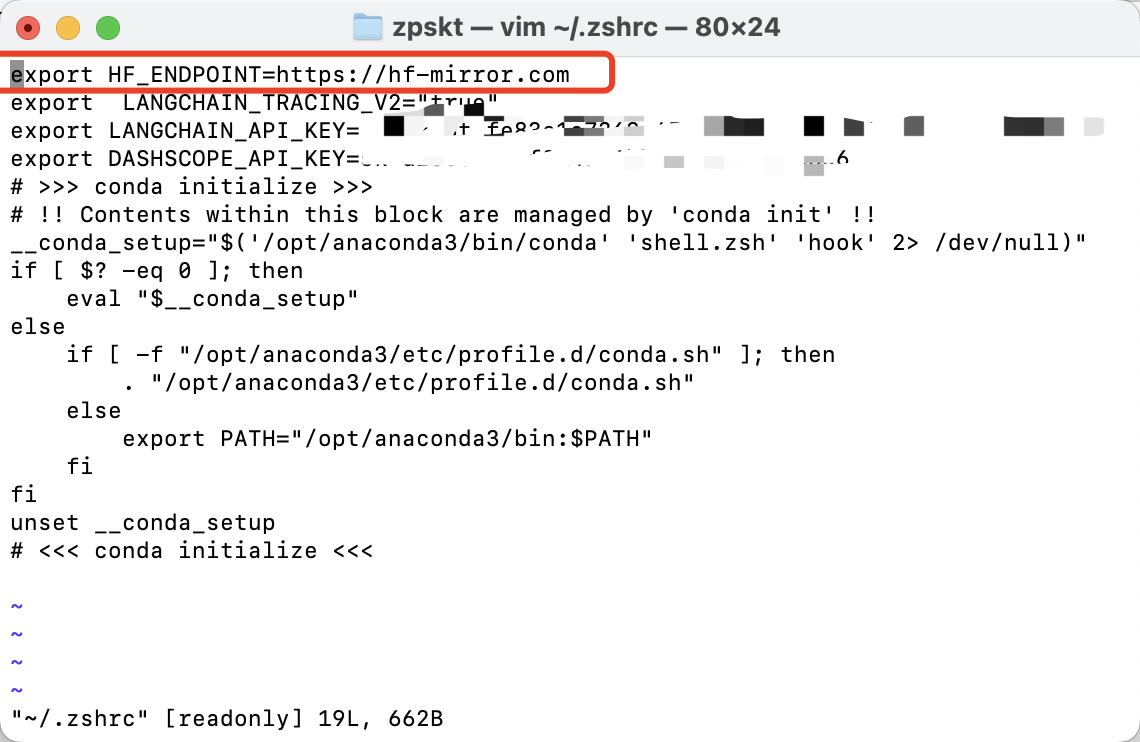
Windows(这里没贴图,可以自行查阅添加环境变量)
我的电脑-》环境变量
加上HF_ENDPOINT并配置值 https://hf-mirror.com
此时你就可以往后走了,如果后面还不通,在执行这里的步骤
如果你还是下载不下来,那么就下载到本地
如果下载失败,那么就手动下载模型
shell
wget -P model/bert-base-chinese https://hf-mirror.com/google-bert/bert-base-chinese/resolve/main/pytorch_model.bin
其他的我都下载完了,只需要下载一个bin就行了
准备训练数据
训练数据放置于data/train.csv,可以参照我的格式准备训练数据,需要你针对业务进行打标签处理,里面如果标签数据是中文,那么你就把labels中文映射一下即可。
使用
训练数据
开始训练
shell
python train.py 训练结束后,会在reslts文件下出现训练后的模型。
| 文件名 | 说明 |
|---|---|
| config.json(file://D:\zpskt\sentiment\model\bert-base-chinese\config.json) | 模型配置文件,保存模型的超参数和架构配置信息 |
model.safetensors |
模型权重文件,使用 safetensors 格式存储模型参数 |
optimizer.pt |
优化器状态文件,保存优化器的参数和状态,用于恢复训练 |
rng_state.pth |
随机数生成器状态文件,确保训练过程的可重现性 |
scheduler.pt |
学习率调度器状态文件,保存学习率调整策略的状态 |
trainer_state.json |
训练器状态文件,记录训练过程中的各种状态信息 |
training_args.bin |
训练参数文件,保存训练时使用的命令行参数配置 |
该目录保存了训练过程中的模型检查点,包含模型权重、配置和训练状态等文件
用于模型的恢复训练或推理部署
当使用时,加载模型选择某个文件夹模型即可,要保证结构与我的一致。
main方法启动
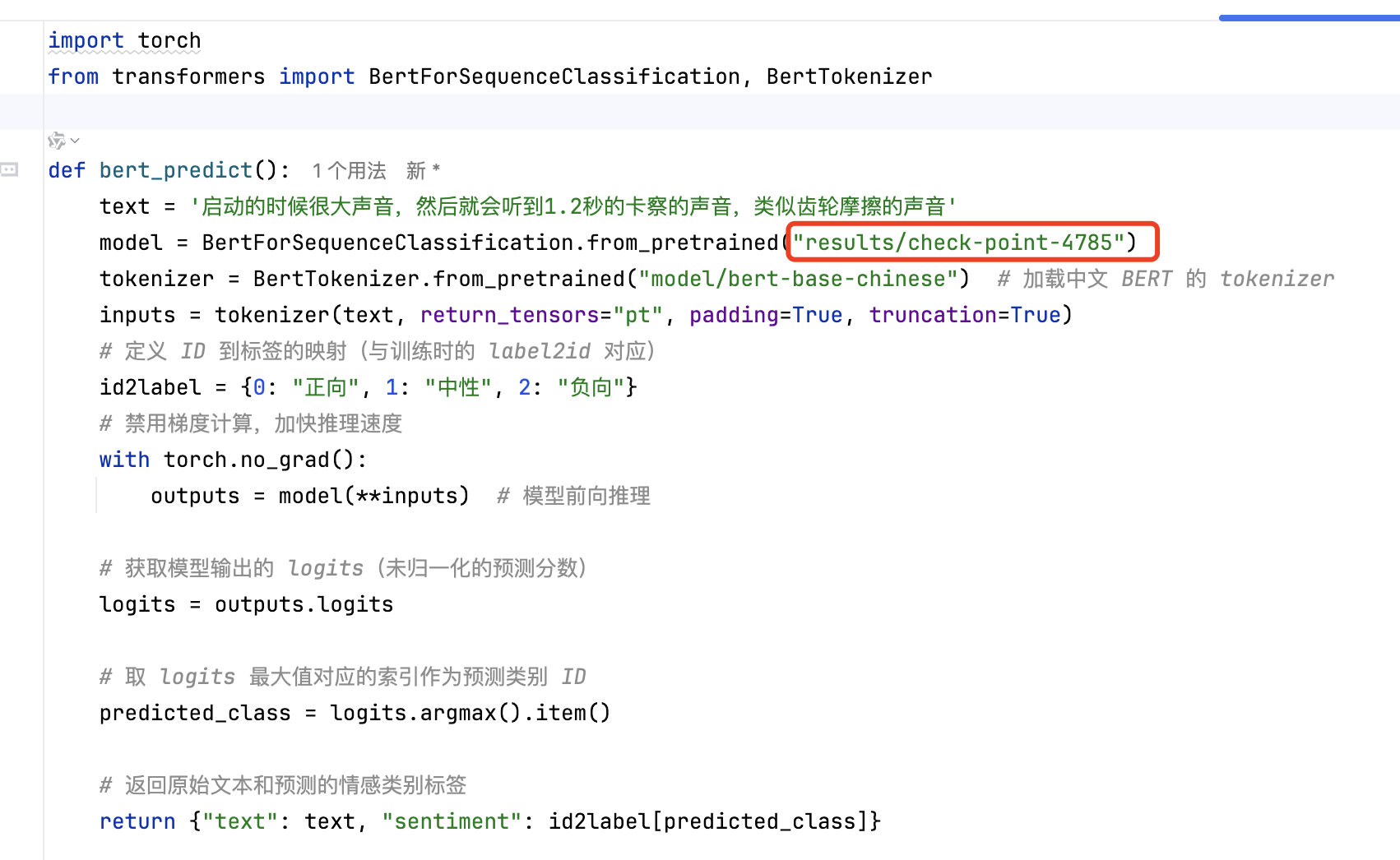
可以看到我这里路径已经改为训练后的路径了。
shell
cd src/bert
uvicorn api:app --reload持续迭代
因为后续的代码是在公司完成,所以没有上传,而且较为简单,所以省略了。
流程就是,每次纠正标签后,都将纠正后的标签数据整理到一个csv然后利用原来已经训练完的模型再接着训练得出新的即可。