背景
前要回顾:在全链路埋点监控项目完成的初期,我们针对埋点sdk设计了"内核+插件"的架构。其中,内核针对的是埋点上报的逻辑实现,而插件,则是可扩展的不同的采集监控系统。作为传统的前端埋点监控系统,我们通过智能双队列的策略实现了不同种类的数据上报,但随着后续埋点测试的业务越来越复杂,我们决定重构做一个高性能的前端埋点上报系统。
全链路埋点监控链路流程回顾:
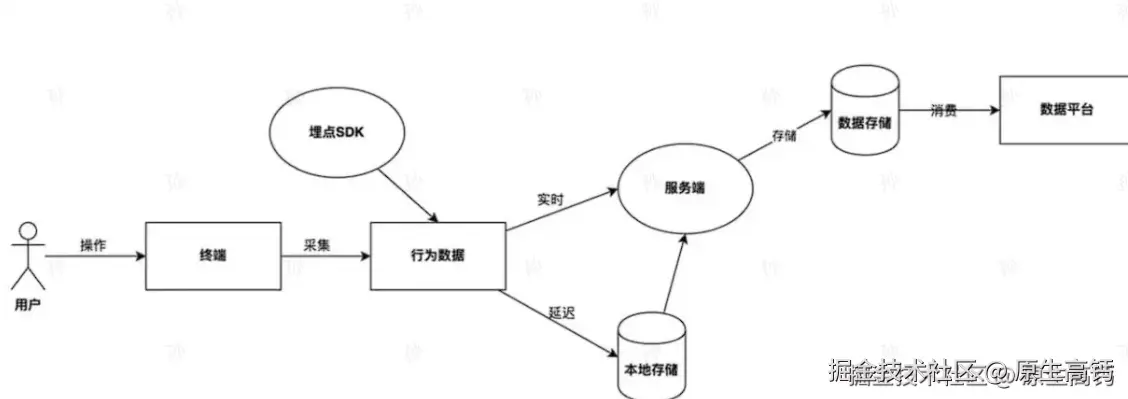
架构设计俯瞰
埋点sdk旨在为前端应用提供高性能,可扩展,低侵入的埋点采集与上报能力,涵盖性能监控,行为监控,错误监控等多种场景,并支持灵活的插件机制和多策略上报。
大致架构如下:
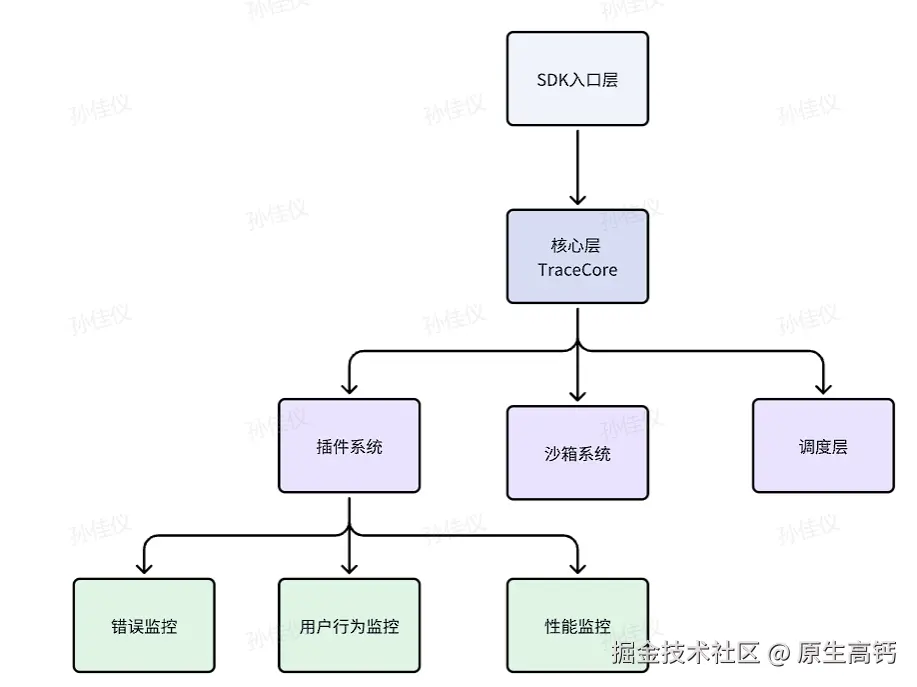
与以前的"内核+插件"传统架构相比,我们在此基础上引入了沙箱,调度器等机制,进一步提升了插件运行的安全性以及数据采集上报的扩展性等功能。相比传统实现,这种架构更适合复杂可扩展的前端监控/埋点/数据采集类 SDK 场景。
插件系统
插件系统还是分为三模块,分别是错误监控插件,用户行为插件和性能监控插件。都有如下特点:
- 每个插件通过标准接口与内核对接。
- 插件可独立开发,按需加载,动态注册。
- 每个插件各自实现具体的业务功能。
具体的插件系统架构我做了如下的思维导图:
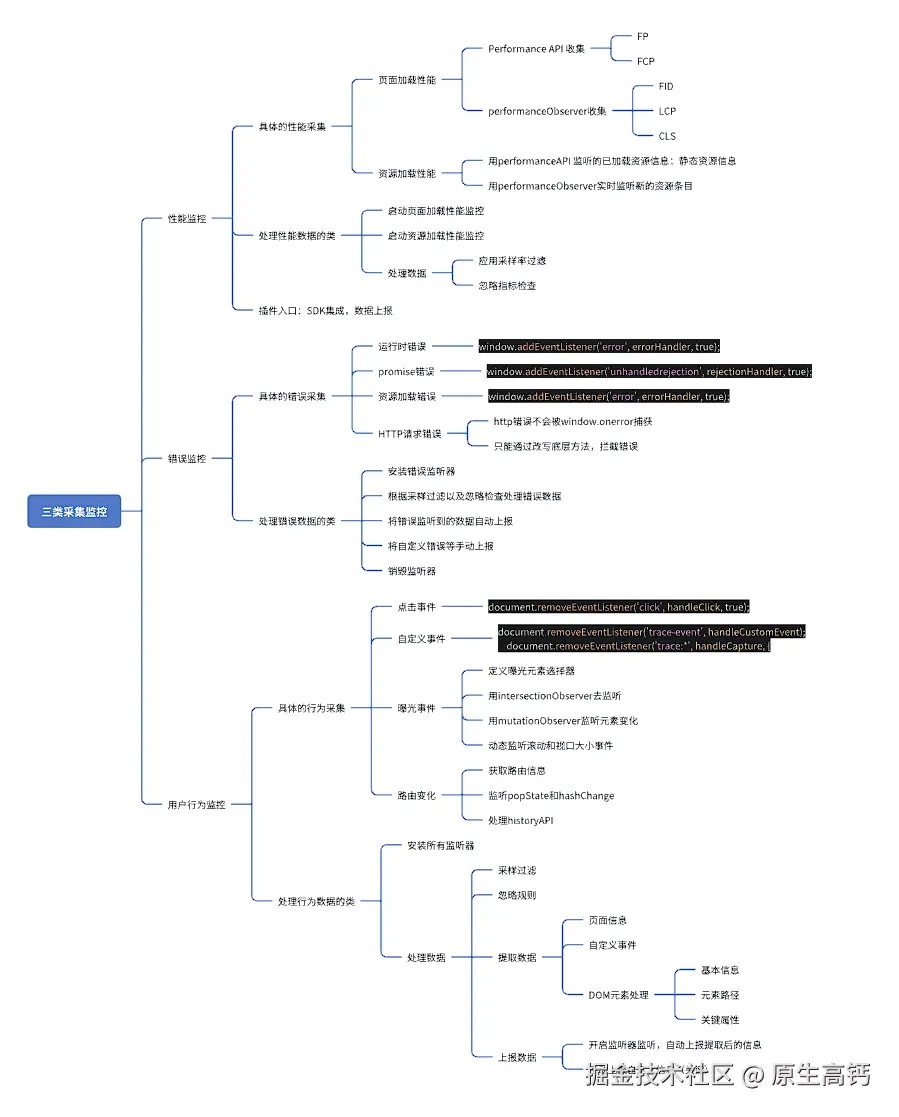 综上,我们可以得到每类监控的具体采集放到了handlers目录,具体处理数据的类单独放在一个文件中,最后以接口的方式导出插件的。
综上,我们可以得到每类监控的具体采集放到了handlers目录,具体处理数据的类单独放在一个文件中,最后以接口的方式导出插件的。
新增模块
对于我们重构后的高性能埋点系统中,我们基于传统架构又引入了沙箱系统,调度系统以及重构的内核系统。
我们在此先讲沙箱和内核系统,调度系统放到上报模块再去细讲。
沙箱系统
架构方面:
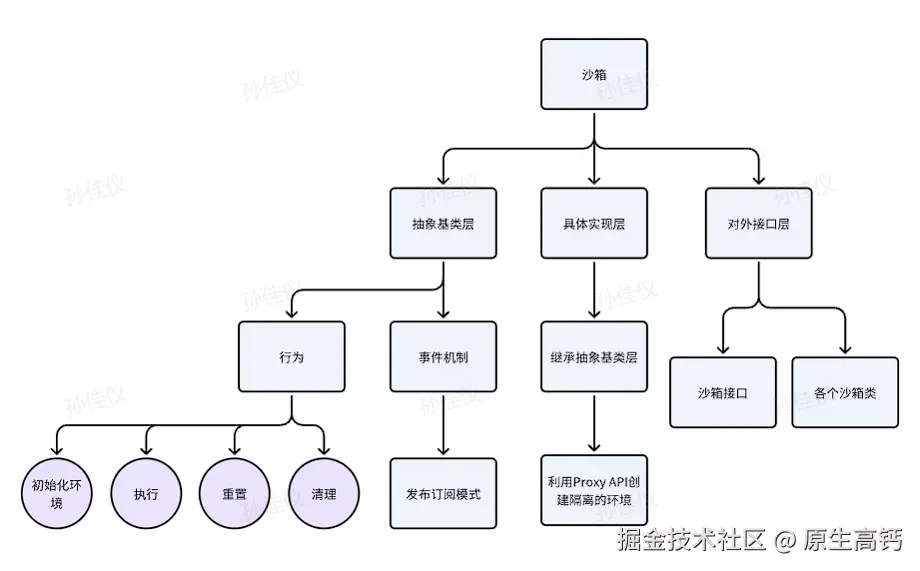
由以上架构图我们可以得知,整个沙箱系统分为三部分:抽象基层类,具体实现层和对外接口层。
其中,我们将沙箱的基本行为以及事件机制放到抽象基类层,具体实现层去继承,然后利用Proxy API创建隔离的沙箱环境去实现插件在沙箱中的运行流程,最后以接口的形式暴露出来给各类插件去使用。
沙箱的选型:
首先我们做一个常见沙箱类型的认识:
沙箱是一种安全隔离机制,用于在受控环境中运行不可信代码或第三方程序,防止对主系统造成破坏或数据泄漏。沙箱通过资源隔离,权限控制和执行限制,确保代码在允许的范围内运行,即使发送错误或恶意行为,也不会影响宿主环境。
- Proxy 代理:轻量级的逻辑隔离。在沙箱环境中,Proxy可以限制对全局对象的访问,比如阻止插件修改window对象或访问敏感API的。由于仅能拦截API的调用,所以一方面性能开销较低;另一方面,恶意代码仍可能通过其他方式攻击主线程,因此安全性不是特别好。
- Web Worker:物理线程隔离。Web Worker将插件代码运行在独立的线程中,完全隔离于主线程,无法直接访问DOM或其他主线程资源。因此Web Worker虽然更安全,但通信成本高,且无法直接操作DOM,需要消息传递。
- iframe:浏览器进程隔离。每个iframe有独立的渲染进程和JavaScript执行环境,安全性极高。但它的资源消耗极大,每个iframe需要加载完整的文档环境,因此对于需要频繁创建和销毁的场景并不合适。
综上,Web Worker 适合纯计算任务,而iframe不适合埋点SDK这种高性能和低资源占用的场景。对于埋点SDK我们采取Proxy代理:灵活轻量,适合精细控制权限的场景。
具体沙箱的执行流程如下:
- 创建沙箱实例(合并默认沙箱配置项和类型配置)
- setupContext 创建上下文
- Run 执行代码,做类型判断
- 最后 Proxy 做属性拦截,执行出结果
- 执行完以后,自动恢复环境,保证每次执行互不干扰
- 最后销毁沙箱
沙箱在插件的使用:
- 插件将需要隔离的代码交给沙箱,沙箱在安全环境中执行,保证主应用的安全与稳定
- 各类插件在沙箱中实现安全隔离,防止一个有 bug 牵一发而动全身。
- 插件可通过沙箱的发布订阅模式灵活监听沙箱的生命周期,做日志,监控等处理
- 插件将需要执行的用户自定义代码和高风险代码在沙箱中执行
typescript
import { ProxySandbox } from '../sandbox/ProxySandbox';
class EventPlugin {
private sandbox: ProxySandbox;
constructor() {
this.sandbox = new ProxySandbox({
allowList: ['console', 'window'],
denyList: ['document.cookie', 'localStorage'],
autoRestore: true,
});
}
handleUserEvent(userCode: string, eventData: any) {
try {
// 在沙箱中执行用户自定义事件处理代码
this.sandbox.run(userCode, eventData);
} catch (e) {
// 处理沙箱执行中的异常
console.error('沙箱执行用户事件代码出错', e);
}
}
}除此,对于此沙箱系统上可优化的点:当我们在正常业务接入SDK时,要保证的是SDK不能影响业务主线程的执行。因此,我们可以将支付等安全系数高或者计算任务重的事件采集代码放到 Web Worker 中开辟一个单独的线程去处理。
上报升级
在项目重构前,我们上报系统采取的是智能双队列+localStorage的兜底机制的做法,所谓双队列,一个是基于时间的实时队列,另一个是基于数量的批量的队列。传统上报系统的局限性如下:
- 频繁上报对于主线程性能的影响和数据俩个过大的队列溢出问题;
- 所有插件都依赖于上报内核,其中一个有bug容易上报过程中相互影响;
- 还有队列管理复杂,需处理断网,弱网,持久化等问题。
那么针对于传统架构的局限性,我们重构后的上报系统通过沙箱、调度器、异步机制以及缓冲区等创新设计,能更好地解决这些问题,适应复杂业务和大规模数据采集场景。
首先了解架构以前,我们要知道上报干了什么事:
一句话总结:将各类SDK采集到的数据做统一封装处理,最后根据上报架构上报到后端。
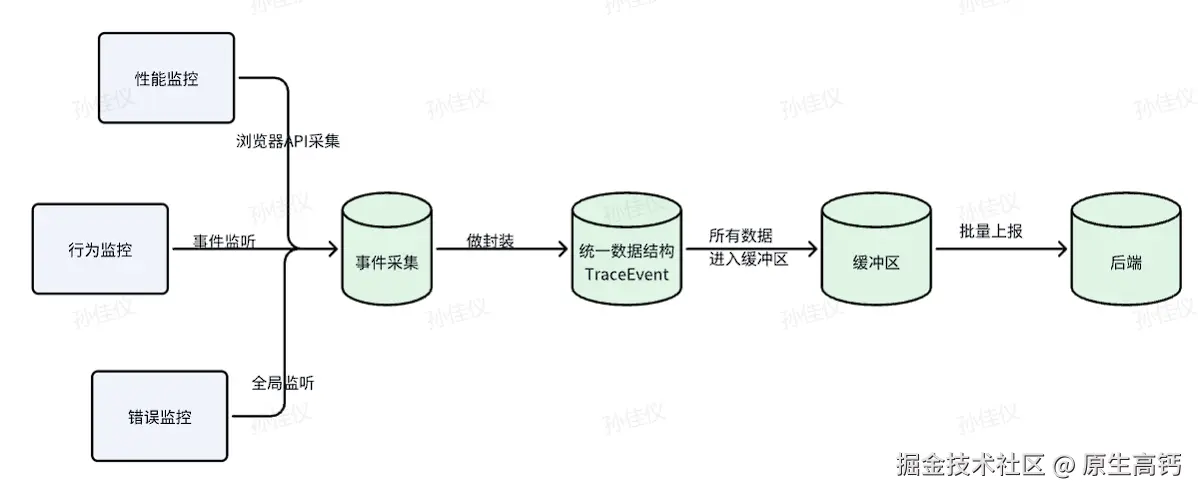
埋点上报机制:
-
设计目标:根据数据的优先级,实现"实时,批量,空闲的三种上报策略"。
-
上报组成:
根据数据优先级做入队处理,三队列机制
空闲调度器:利用 requestIdleCallback 这个钩子,让浏览器在空闲时间处理低优先级的任务
策略配置:上报方式的开关,各种参数
-
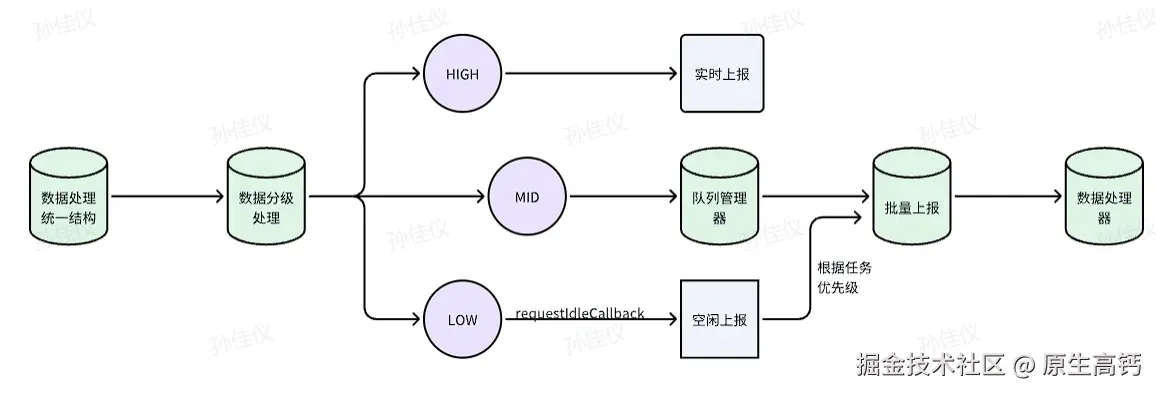
上报机制详解:
埋点上报架构
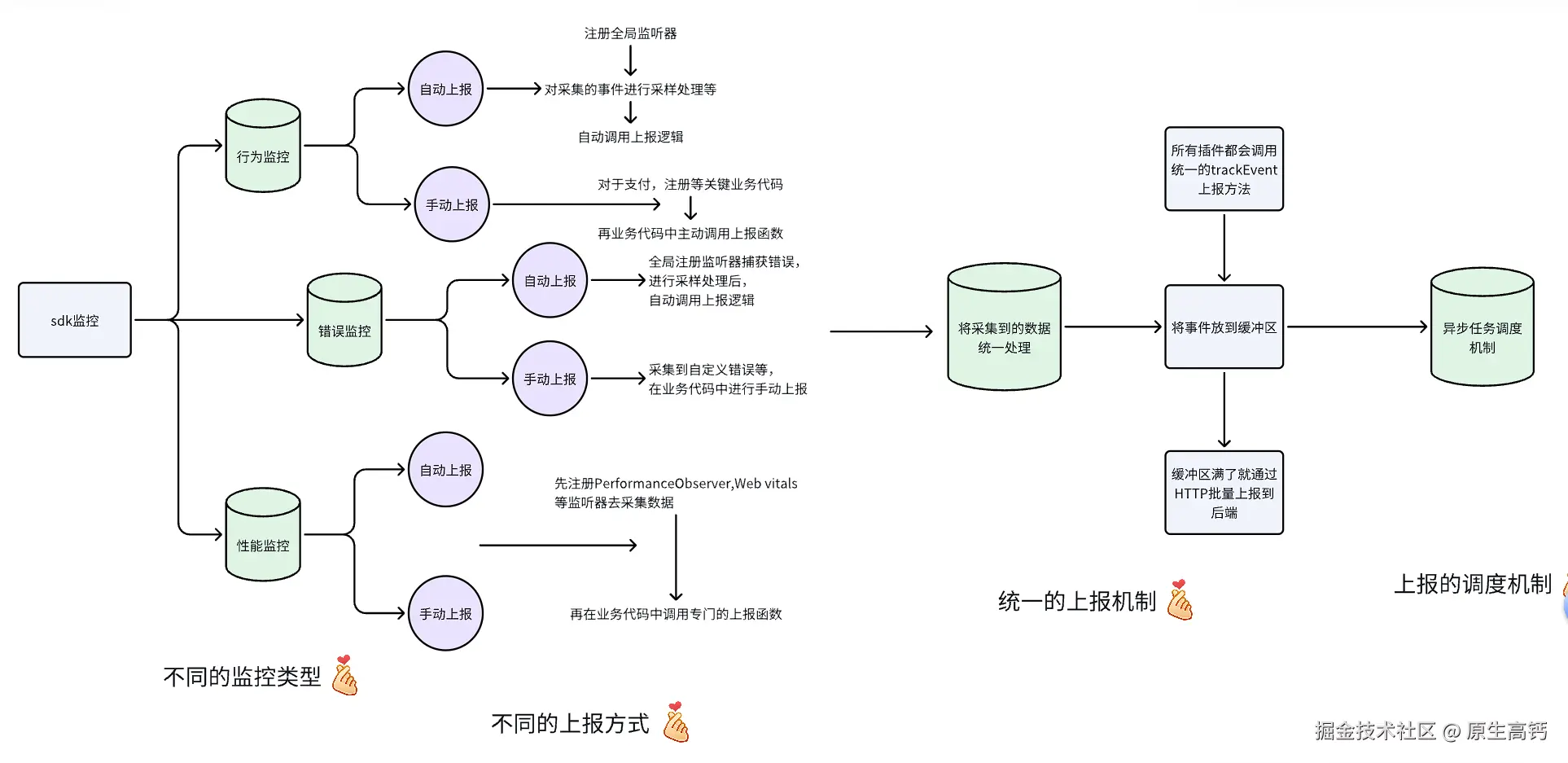
从上图中我们总结,
- 对于上报方式,根据事件的重要性,我们将关键的业务数据采取手动上报的方式,其他监听器监听到的采取自动上报。例如,在性能监控中,监控到了CLS(Cumulative Layout Shift,累计布局偏移 衡量页面稳定性的指标。它量化了用户在浏览网页时,页面元素发生以外移动的程度)>2.5的异常指标我们要去手动上报;在用户行为监控中,监控的支付注册等关键业务也需要手动上报;在错误监控中,监听器无法捕获的,业务需要捕获的自定义异常(前端校验失败等非JS运行时异常)以及特殊告警等需要调用手动上报函数去进行手动上报。
- 对于上报数据的存储位置,我们采取缓冲区+批量上报作为优化点
- 对于上报的异步调度机制,我们将低优先级队列的埋点数据利用 requestIdleback 钩子去实现浏览器空闲处理的效果
重构时的亮点与思考
思考1:缓冲区+批量上报的亮点
- 相比一次上报一条,
减少了网络请求频率 - 针对批量上报的机制,将数据暂存,异步或在浏览器空闲时统一上报
,减少了对主线程的干扰,提高了页面流畅度 - 多条数据合并为一个请求包体,减少请求头等重复内容的传输,
减少带宽,提升上报效率 - 缓冲区可在网络异常时暂存数据,待网络恢复后统一上报
,保证数据不丢失 - 缓冲区的存在,简化了实时上报和批量上报的逻辑。想要实现实时上报,只需将缓冲区大小设置为1;想实现批量上报,将缓冲区大小设置为大于1的值即可
kotlin
public trackEvent(event: TraceEvent): void {
console.log('trackEvent called, buffer length:', this.eventBuffer.length, 'maxBufferSize:', this.options.maxBufferSize);
// 添加到缓冲区
this.eventBuffer.push({
...event,
timestamp: event.timestamp || Date.now(),
});
// 如果缓冲区已满,则执行上报
if (this.eventBuffer.length >= (this.options.maxBufferSize || 100)) {
this.flushEvents();
}
}思考2:这个缓冲区限制数据量吗,该如何合理的设置缓冲区大小
- 有了缓冲区的存在,我们就不用将数据存到localStorage等浏览器的地方,缓冲区实际存数据的位置在js的运行数组
- 但如若这个maxBufferSize设置不当,很容易造成常见的**
js数组内存溢出问题**
css
/**
* 最大缓冲事件数量,默认为 100
*/
maxBufferSize?: number;-
那我们该如何合理的设置maxBufferSize就是一个很现实的问题
-
针对这个问题,我做出了如下的思考:
首先,我们需要计算单条上报数据的实际大小,再取平均值
其次,
maxBufferSize=目标缓冲区总字节数/平均单条数据字节数但是,我们**
在设置时要远小于此值**,因为对于高频数据来说,短时间内会产生大量数据,如果来不及上报,会在内存中大量堆积以至于页面卡顿,还有可能会有数据丢失的风险
思考3:相比于以前localStorage做的兜底机制,请对比并说明缓冲区做兜底机制的优势
- 横向对比
| 方法 | 存储位置 | 持久性 | 读写速度 | 容量限制 | 线程安全 |
|---|---|---|---|---|---|
| localStorage | 浏览器本地磁盘 | 持久 | 较慢,涉及磁盘IO | 一般为5MB | 多Tab共享,安全一般 |
| 缓冲区 | js运行时内存 | 临时 | 极快,内存操作 | 受限于浏览器分配的内存 | 当前页面共享,安全高 |
-
为什么缓冲区做兜底机制更适配埋点监控系统
由于缓冲区存储数据的位置在内存,读写速度极快,因此适合那些高频,实时上报,保证性能和实时性。
缓冲区相比于localStorage可存储的扩展性更高,比如高频数据缓冲区大小可调的小一点,低频数据可将缓冲区大小调大一点
需要继续优化的问题:缓冲区将数据的存储位置是临时内存,那页面关闭时的这种情况,采集到的数据该怎么处理呢
遇到页面关闭这种数据无法存储于内存的情况,我们需要结合Navigator.sendBeacon+ localStorage/indexedDB去做持久化兜底。其中Navigator.sendBeacon可以保证数据在页面关闭时上报的可靠性,localStorage/indexedDB可以保证采集到没上报成功的数据先放在磁盘中去存储,页面下次打开时可以补发。
因此,对于这个点的优化,我建议前端数据采集的数据存储还是采取缓冲区+localStorage/indexedDB 相结合的策略。
与 React 调度机制的区别
React Fiber通过时间切片+优先级调度去做的调度渲染。
但是React做调度的钩子是 requestHostCallback 而不是我们调度系统用的 requestIdleCallback。那二者钩子有什么区别呢
| 对比方向 | 所属 | 适用场景 | 业务可用性 | 兼容性 | 是否可中断 |
|---|---|---|---|---|---|
| requestIdleCallback | 浏览器原生API | 低优先级,非紧急任务 | 业务代码可直接使用 | 不是所有浏览器都支持(可降级为 setTimeout) | 不能中断已执行的回调 |
| requestHostCallback | React Scheduler内部私有API | React任务调度 | 仅限React内部使用 | React 内部可自动降级 | 支持任务中断,优先级切换 |
思考一:埋点SDK为何更适用于 requestIdleCallback?
为了不影响主线程业务以及页面流畅度等,我们需要将采集到的低优先级数据在浏览器空闲时期处理,这非常适用于埋点SDK中的批量处理延迟上报等。
思考二:React用 requestHostCallback 的优势
React Fiber的核心目标是"可中断渲染",将渲染任务拆分成小块,在浏览器空闲时分批进行,避免长时间阻塞主线程。早期 React 的调度渲染确实是 requestIdleCallback 这个钩子,但由于由于浏览器的兼容性问题,导致时间片的执行时长是不可控的,导致渲染卡顿或延迟等问题。因此,在此基础上 React 内部引入了 requestHostCallback 这个钩子,它不仅解决了requestIdleCallback 这个钩子的限制性,还可以中断已执行的回调,让更高任务的任务优先执行。
所以,requestHostCallback 这种自研钩子更适用于需要更强调度能力的 像 React 这种复杂 UI 框架。
测试效果
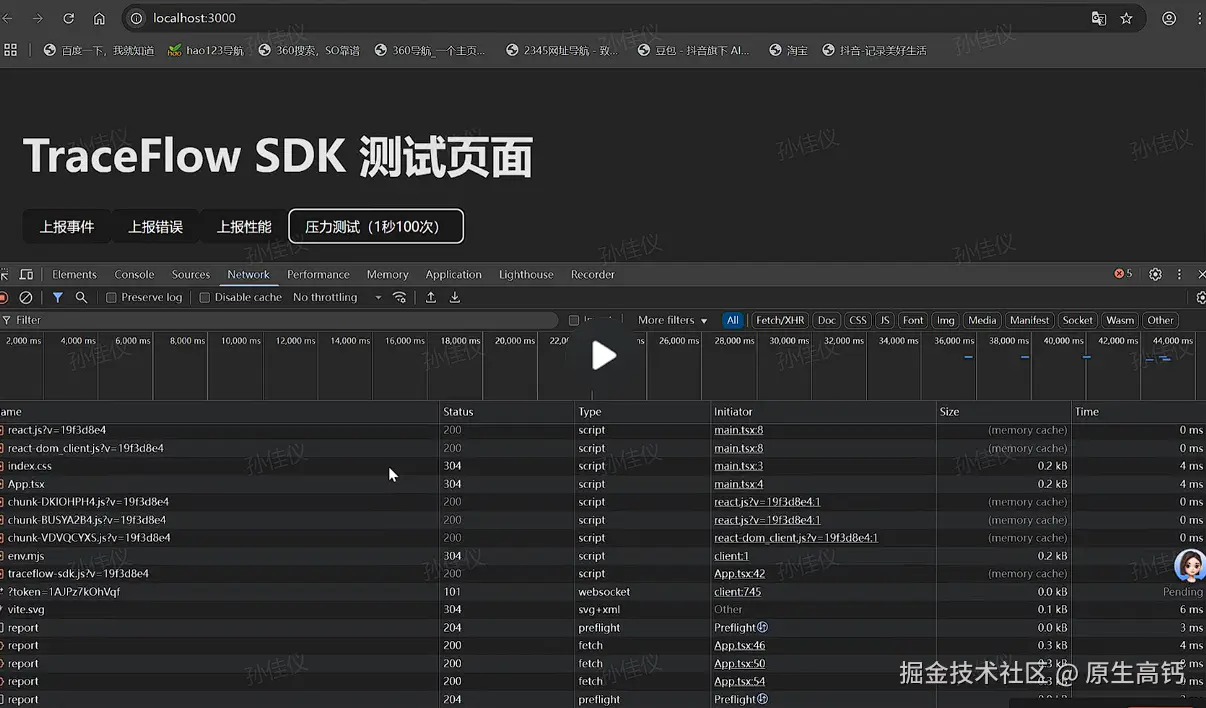
如下,是我做的测试页面:
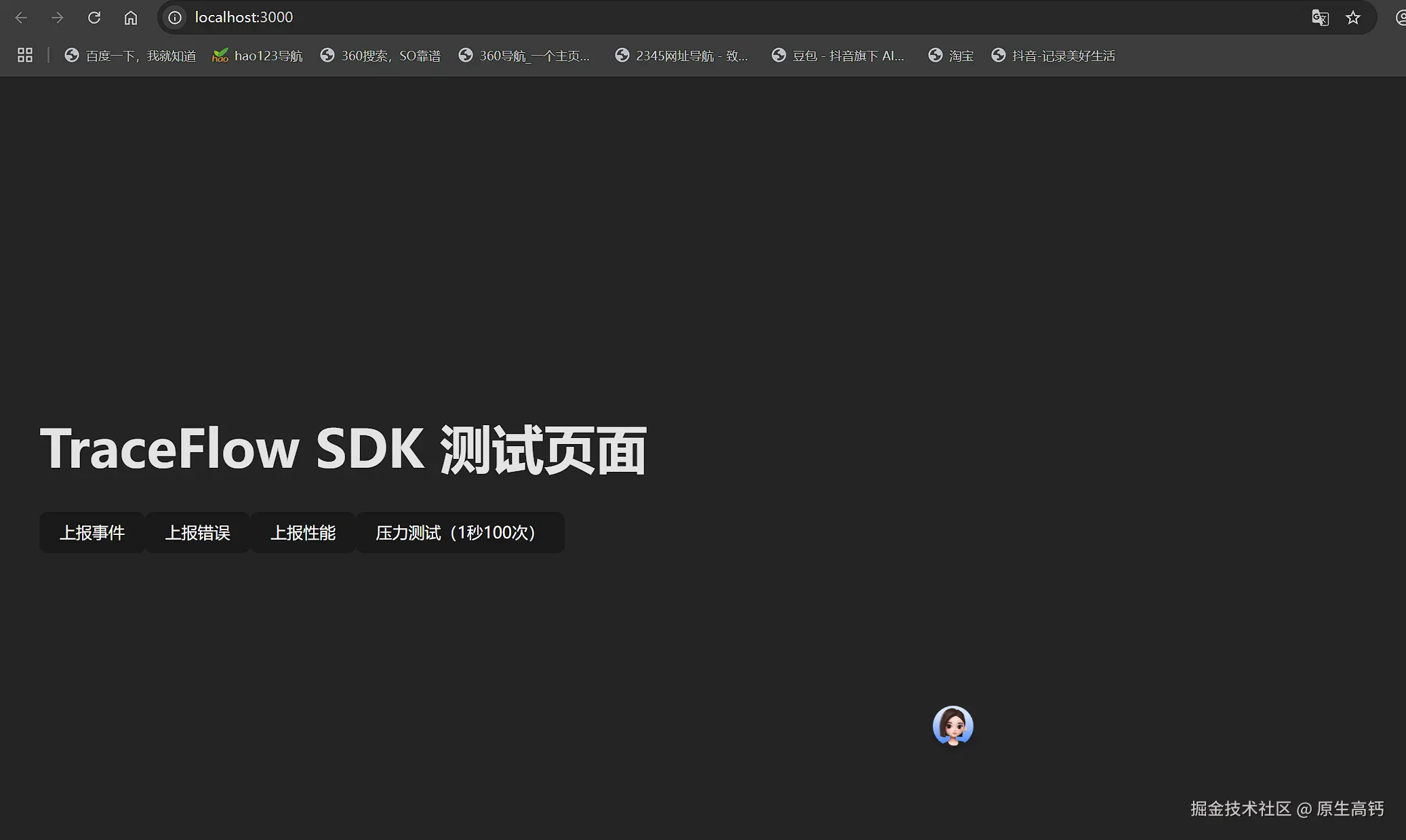
分别有三类上报按钮以及压力上报,我们测试结果是所有类型的网络请求都能正常发送
总结展望
TraceFlow 埋点SDK 采用了内核+插件的模块化架构,结合引入沙箱机制和调度队列,实现了高扩展性、高安全性和高性能的数据采集与上报。它支持性能、错误、用户行为等多维度监控,自动捕获常见异常,并通过sendBeacon、批量/延迟等方式提升数据上报的可靠性和效率。沙箱和调度器的引入,有效降低了对主线程的影响,保障了业务流畅性。当前SDK已能满足大部分Web端埋点需求,但,未来可进一步引入 Web Worker、本地持久化、动态插件机制和多端统一协议,持续优化数据可靠性和系统灵活性,助力企业实现更智能、更全面的前端监控与数据分析。