高并发系统40问
通用设计方法:
- 横向扩展:例如数据库一主多从、分库分表、存储分片;
- 缓存
- 异步
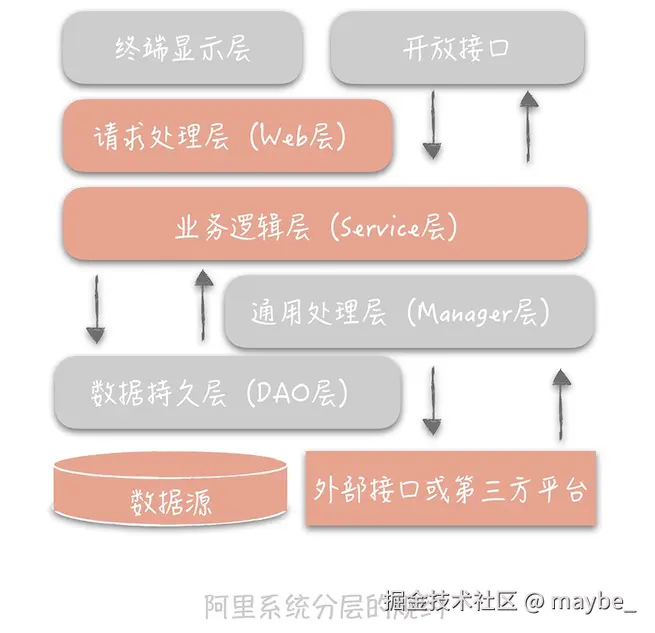
架构分层思想
MVC:表现层、逻辑层、数据访问层。 网络分层:OSI七层模型、TCP/IP四层模型。 Linux文件系统分层设计:VFS, Ext3/Ext4, General Block Device Layer。 分层的架构可以为横向扩展提供便捷。
系统设计目标
三大目标:高性能、高可用、可扩展。 可扩展:流量分为平时流量和峰值流量,可扩展的系统能够在短时间完成扩容,支撑峰值流量。
高性能
性能度量指标:分位值
从用户使用体验的角度来看,200ms是第一个分界点:接口的响应时间在200ms之内,用户是感觉不到延迟的,就像是瞬时发生的一样。而1s是另外一个分界点:接口的响应时间在1s之内时,虽然用户可以感受到一些延迟,但却是可以接受的,超过1s之后用户就会有明显等待的感觉,等待时间越长,用户的使用体验就越差。所以,健康系统的99分位值的响应时间通常需要控制在200ms之内,而不超过1s的请求占比要在99.99%以上。
高并发的性能优化:
- 提升并发能力
- 减少单次响应时间
提升并发能力
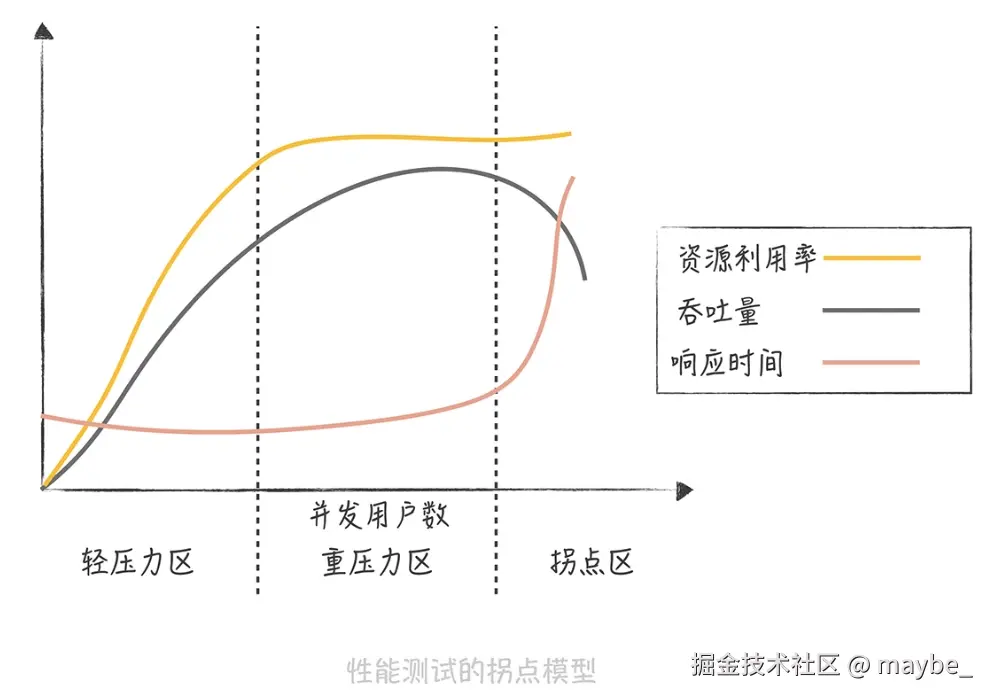
性能测试中的拐点模型。性能测试的目的就是找到拐点。
减少单次响应时间
根据系统类型:
- CPU密集型:选用高效算法;
- IO密集型:掌握找瓶颈点的工具,不同原因采用不同的应对方法;
高可用(HA)
可用性度量指标
- MTBF(Mean Time Between Failure): 平均故障间隔,越大越好。
- MTTR(Mean Time To Reapir):故障的平均恢复时间,越小越好。
系统可用性 Availability = MTBF / (MTBF + MTTR). 这个公式计算出来是一个比例,我们会使用几个九来描述系统可用性。 一般来说,我们的核心业务系统的可用性,需要达到四个九,非核心系统的可用性最多容忍到三个九。在实际工作中,你可能听到过类似的说法,只是不同级别,不同业务场景的系统对于可用性要求是不一样的。
高可用系统设计思路
- 系统设计:Design for failure,设计时考虑failover、超时控制、降级和限流。
- 系统运维:灰度发布、故障演练。
可扩展
系统不同分层上存在一些瓶颈点,制约着系统横向扩展能力。比如:带宽、LB、DB、缓存、第三方等。我们要知道系统并发到达不同量级时,哪一个因素会成为瓶颈点。
高可扩展设计思路
拆分:把庞大的系统拆分成独立的,有单一职责的模块。
- 存储层拆分:首先按业务维度,其次按数据特征水平拆分(最好一次性增加足够节点避免后续拆分需要数据迁移)。
- 业务层拆分:业务维度、重要性维度、请求来源维度。
池化技术
空间换时间。比如数据库连接池、HTTP连接池、Redis连接池、线程池。 常见的一些故障:
- 数据库域名对应的IP发生变更,池子的连接使用的还是旧IP。
- MySQL Server端wait_timeout超时关闭连接,Client端感知不到,使用时才会发现出错。
解决:定期检测池中的连接是否可用。
主从读写分离

主从读写分离的两个关键点:
- 主从复制:一个主库最多挂3~5个从库(log dump线程资源消耗)。
- 如何访问多个节点的数据库。
只写主库,只读从库。即使写请求会锁表或者锁记录,也不会影响到读请求的执行。 带来的问题:主从延迟。把从库落后的时间作为一个重点的数据库指标做监控和报警
分库分表
垂直拆分、水平拆分。 分库分表引入的一个最大的问题就是引入了分区键,我们之后所有的查询都需要带上这个字段,才能找到数据所在的库和表。
案例,在用户库中我们使用ID作为分区键,这时如果需要按照昵称来查询用户。可以建立一个昵称和ID的映射表,在查询的时候要先通过昵称查询到ID,再通过ID查询完整的数据,这个表也可以是分库分表的。
分库分表引入的另外一个问题是一些数据库的特性在实现时可能变得很困难,比如连表join和count。
分库分表后ID的全局唯一性
- 使用业务字段作为主键(易变更,不推荐)。
- 使用生成的唯一ID作为主键,单调递增,提升DB写入性能。
基于雪花算法的唯一ID生成-发号器
两种实现方式:
- 嵌入到业务代码里:需要更多的机器ID位数来支持更多的业务服务器,另外,由于业务服务器的数量很多,我们很难保证机器ID的唯一性,所以就需要引入ZooKeeper等分布式一致性组件来保证每次机器重启时都能获得唯一的机器ID。
- 部署为独立服务。 问题:时钟回拨问题。
坑:如果请求发号器的QPS不高,比如说发号器每毫秒只发一个ID,就会造成生成ID的末位永远是1,那么在分库分表时如果使用ID作为分区键就会造成库表分配的不均匀。