0.遗留问题:什么是LoRA
在本次的Baseline调优中,我们使用了LoRA技术来对讯飞星火平台上的模型进行微调,那么什么是LoRA技术呢?
LoRA技术的核心思想,是针对预训练大语言模型(LLM)的参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)而提出的一种创新方法。其核心在于利用低秩分解(Low-Rank Decomposition)来建模模型微调过程中所需的参数变化量。或者更加直接明了一些来说,LoRA技术就是希望通过在降低数据量的同时,保证大模型可以做出符合我们预期的回答。我们这里采用的LoRA技术属于大模型微调的技术中的一种,微调本身可以提升大模型的表现,比如定制化风格,纠正提示工程和上下文学习中难以修正的错误等。
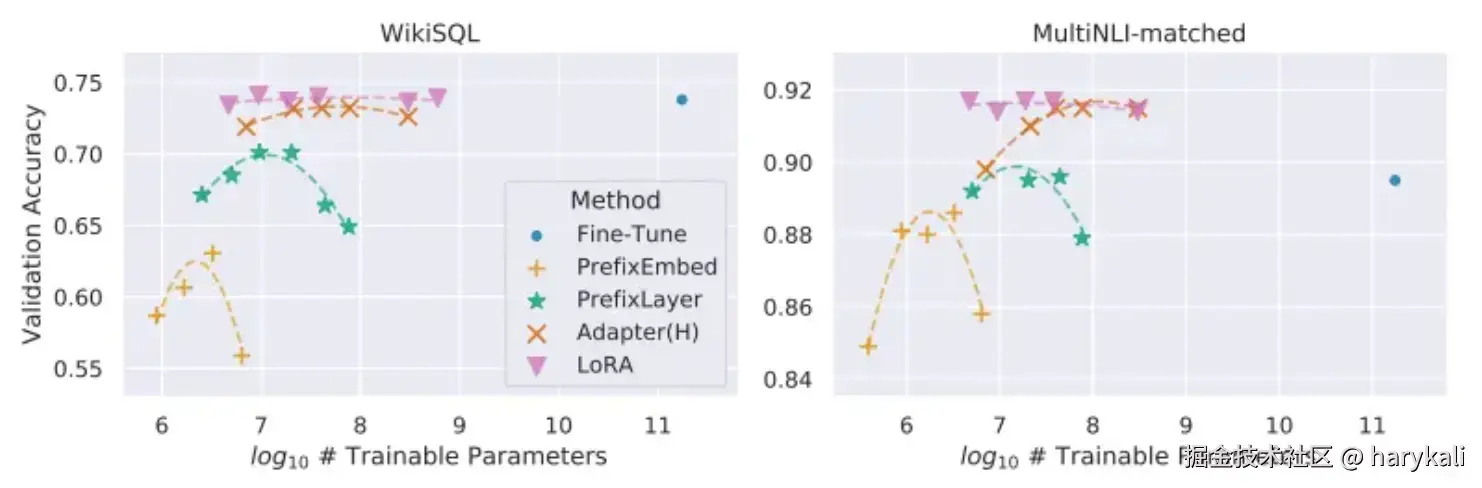
如我们之前几篇博客中所提到的,LoRA本身并非大模型调优的唯一选择,实际上也还有其他的模型调优选择,另外两种比较知名的大模型微调的方法分别为Adapter与Prefix tuning,下图来自LoRA的论文本身,对比了LoRA和另外两种方案的,可以用户可以根据自己的需求选择特定的模型来完成对模型的微调
1.深入理解赛题:
本次的赛题其实目标非常简单:
我们需要对模型进行调优,使其可以尽可能准确地回答用户有关于列车时刻的问题
这里实际上涉及到模型两个方面的能力:
- 让模型学习如何解析和表示表格数据。
- 回答与表格数据对应的自然语言问题。
模型一般会面对以下7类问题:

而我们需要给出包含数值结果、文本描述及必要推理步骤的结构化回答,能够直接展示提取的指标和相关信息。
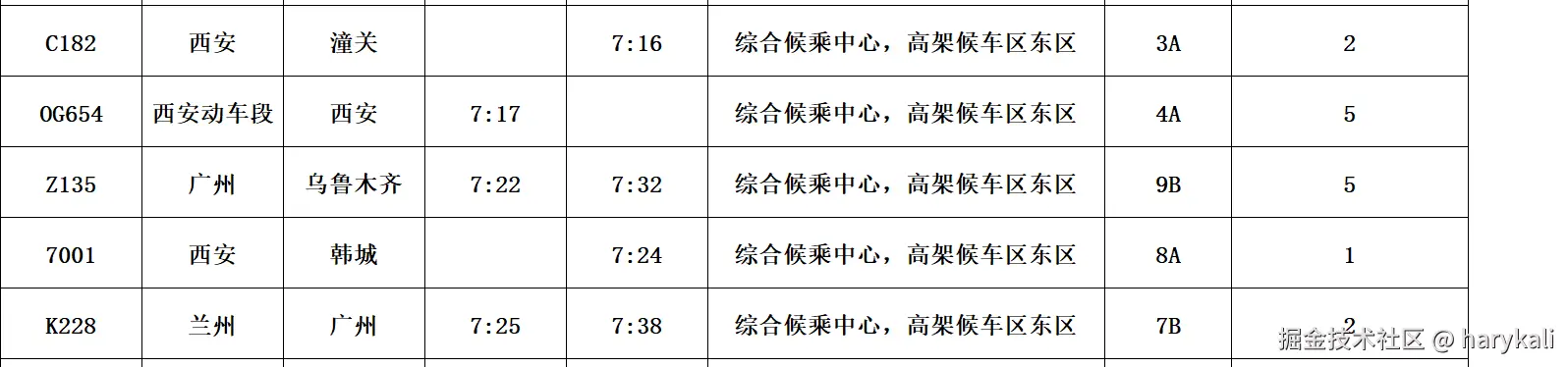
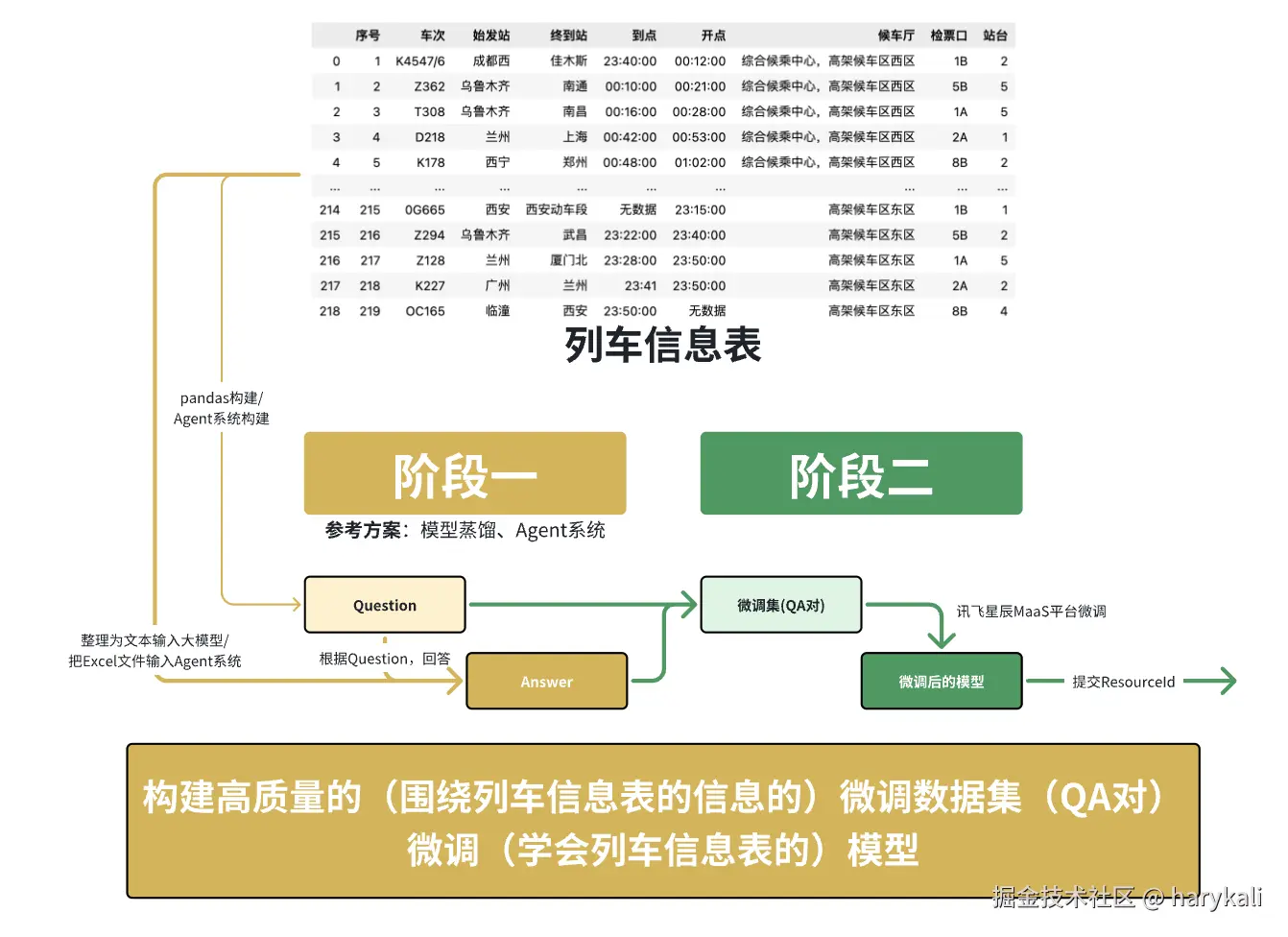
我们打开官方给的数据文件,先浏览我们手中的数据
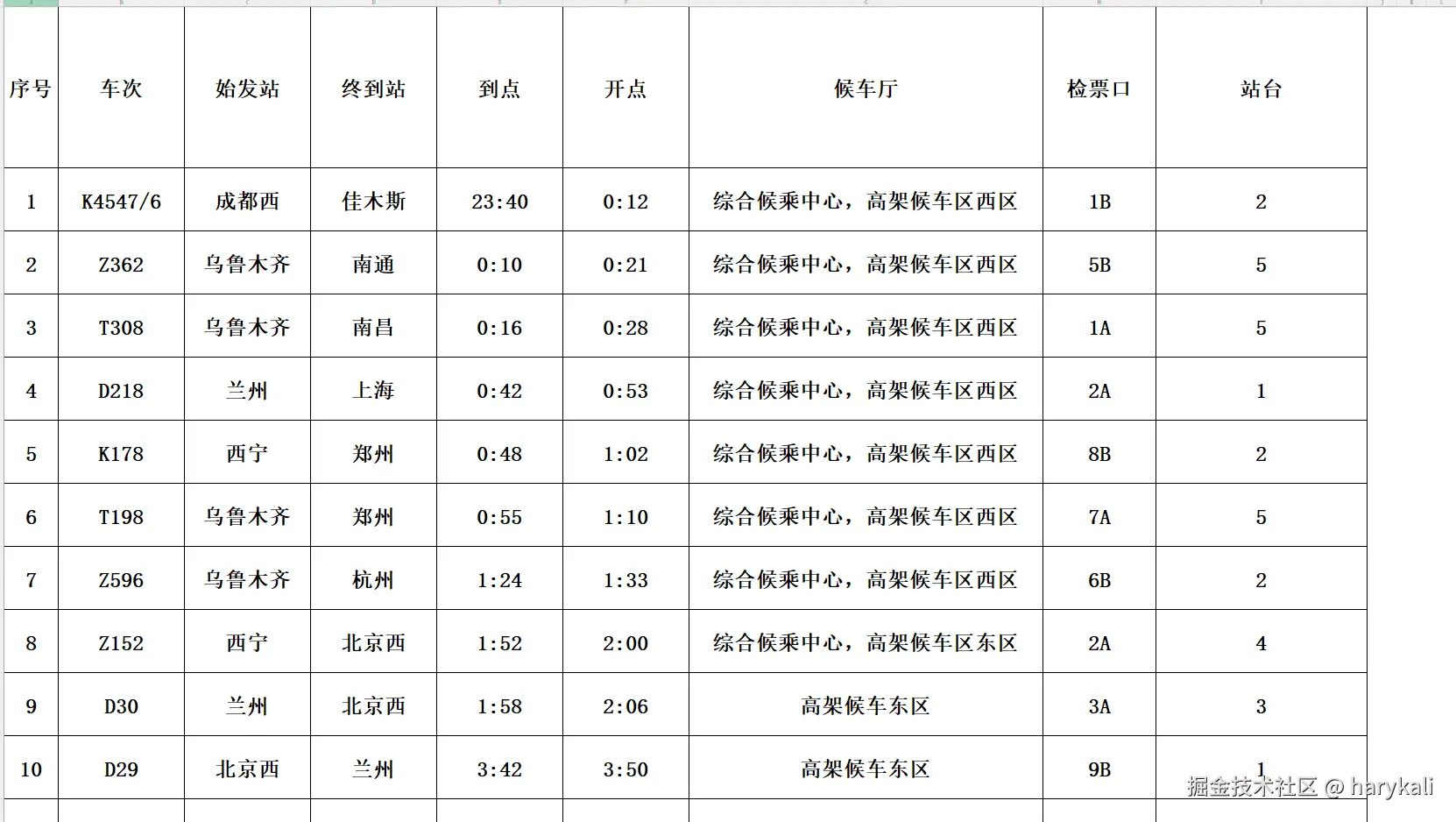
这个文件包括一些车次的信息,包括"序号"、"车次"、"始发站"、"终到站"、"到点"、"开点"、"候车厅"、"检票口"、"站台"等信息。
但是值得留意的是并不是所有数据的所有字段的信息都是完整的,我们可以针对数据缺失进行补全
整体的流程如下图所示:
2.基于模型蒸馏的baseline的调优方案:
在应对结构化数据问答任务初期,我们采用了最直接的方法:利用大语言模型(LLM)端到端地生成训练所需的"问题-答案"对。
具体而言,策略是向大模型输入单行表格数据,并指令其严格依据预设的输出模板生成相应的、包含问题和答案的JSON结构。
这种"大模型同时生成问题与答案"的策略存在一个根本性缺陷:无法有效保证生成结果的准确性。
核心问题主要在于在于以下两点:
- 问题的合理性:模型可能生成与表格数据无关、语义不清或逻辑错误的无效问题。
- 答案的保真度:生成的答案可能存在与输入表格信息不一致、计算错误或捏造信息的情况。
这个时候我们选择引入模型蒸馏的方案来对模型进行
简单来说,我们会选取一个能力更强的模型作为老师模型,老师模型会教会学生模型如何推理出正确的答案(注意此处不是简单的教会学生模型如何输出正确答案,同时还会保证学生模型理解这推理个过程)
我们结合这个比赛的案例来了解一下模型蒸馏
模型蒸馏如同让新调度员(小模型)学习资深专家(大模型)的经验。新调度员重点学习这种思维模式,而非简单结论,最终能以更小的模型体积和更快的速度,做出正确的判断
3.Baseline的具体实现
我们这里采用了Datawhale所提供的代码
python
import pandas as pd
import requests
import re
import json
from tqdm import tqdm
# 读取数据
data = pd.read_excel('data/info_table(训练+验证集).xlsx')
data = data.fillna('无数据')
def call_llm(content: str):
"""
调用大模型
Args:
content: 模型对话文本
Returns:
list: 问答对列表
"""
# 调用大模型(硅基流动免费模型,推荐学习者自己申请)
url = "https://api.siliconflow.cn/v1/chat/completions"
payload = {
"model": "Qwen/Qwen3-8B",
"messages": [
{
"role": "user",
"content": content # 最终提示词,"/no_think"是关闭了qwen3的思考
}
]
}
headers = {
"Authorization": "", # 替换自己的api token
"Content-Type": "application/json"
}
resp = requests.request("POST", url, json=payload, headers=headers).json()
# 使用正则提取大模型返回的json
content = resp['choices'][0]['message']['content'].split('</think>')[-1]
pattern = re.compile(r'^```json\s*([\s\S]*?)```$', re.IGNORECASE) # 匹配 ```json 开头和 ``` 结尾之间的内容(忽略大小写)
match = pattern.match(content.strip()) # 去除首尾空白后匹配
if match:
json_str = match.group(1).strip() # 提取JSON字符串并去除首尾空白
data = json.loads(json_str)
return data
else:
return content
return response['choices'][0]['message']['content']
def create_question_list(row: dict):
"""
根据一行数创建问题列表
Args:
row: 一行数据的字典形式
Returns:
list: 问题列表
"""
question_list = []
# ----------- 添加问题列表数据 begin ----------- #
# 检票口
question_list.append(f'{row["车次"]}号车次应该从哪个检票口检票?')
# 站台
question_list.append(f'{row["车次"]}号车次应该从哪个站台上车?')
# 目的地
question_list.append(f'{row["车次"]}次列车的终到站是哪里?')
# ----------- 添加问题列表数据 end ----------- #
return question_list
# 简单问题的prompt
prompt = '''你是列车的乘务员,请你基于给定的列车班次信息回答用户的问题。
# 列车班次信息
{}
# 用户问题列表
{}
'''
output_format = '''# 输出格式
按json格式输出,且只需要输出一个json即可
```json
[{
"q": "用户问题",
"a": "问题答案"
},
...
]
```'''
train_data_list = []
error_data_list = []
# 提取列
cols = data.columns
# 遍历数据(baseline先10条数据)
i = 1
for idx, row in tqdm(data.iterrows(), desc='遍历生成答案', total=len(data)):
try:
# 组装数据
row = dict(row)
row['到点'] = str(row['到点'])
row['开点'] = str(row['开点'])
# 创建问题对
question_list = create_question_list(row)
# 大模型生成答案
llm_result = call_llm(prompt.format(row, question_list) + output_format)
# 总结结果
train_data_list += llm_result
except:
error_data_list.append(row)
continue
# 转换训练集
data_list = []
for data in tqdm(train_data_list, total=len(train_data_list)):
if isinstance(data, str):
continue
data_list.append({'instruction': data['q'], 'output': data['a']})
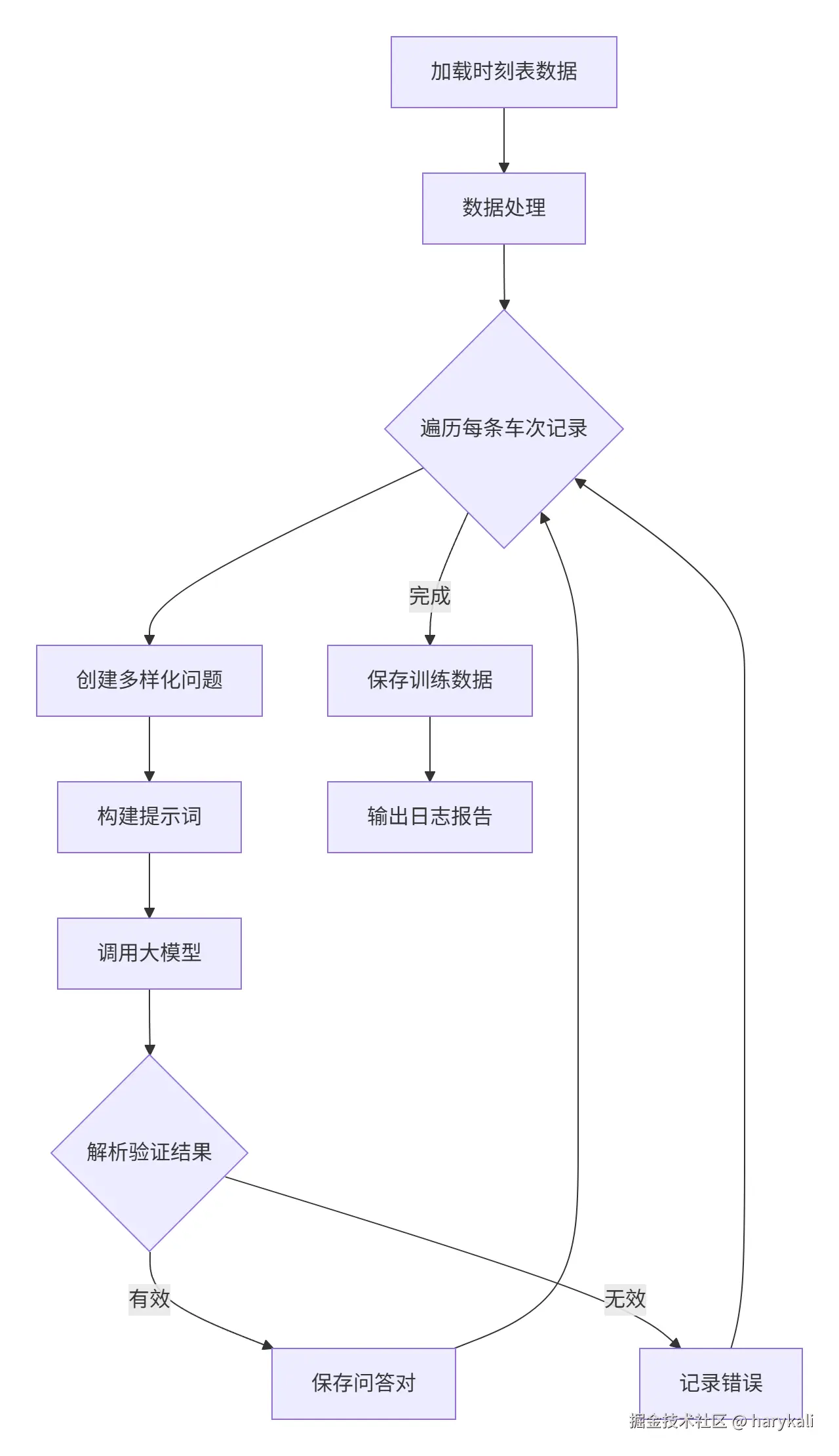
json.dump(data_list, open('train_data/single_row.json', 'w', encoding='utf-8'), ensure_ascii=False)本次的代码大约可以分为4个阶段
- 数据准备阶段
- 读取Excel格式的列车时刻表数据
- 自动处理缺失值(填充为"无数据")
- 转换为字典形式便于处理
- 问题生成阶段
- 我们这次的蒸馏模型是
Qwen/Qwen3-235B-A22B-Instruct-2507 - 提示词覆盖检票口、站台、目的地、时间等关键信息
- 提示词尽可能覆盖每个字段的多个问法
- 提示词明确角色设定(专业乘务员)
- 提示词强调严格基于给定数据回答
- 包含严格的JSON输出格式要求
- 实现带重试机制的可靠请求
- 自动解析模型返回的JSON格式响应
- 数据后处理阶段
- 验证生成问答对的有效性
- 转换为标准微调格式(instruction-output结构)
- 错误日志记录与异常处理
- 结果输出阶段
- 保存为single_row.json训练文件
整个代码的流程大约如下图所示
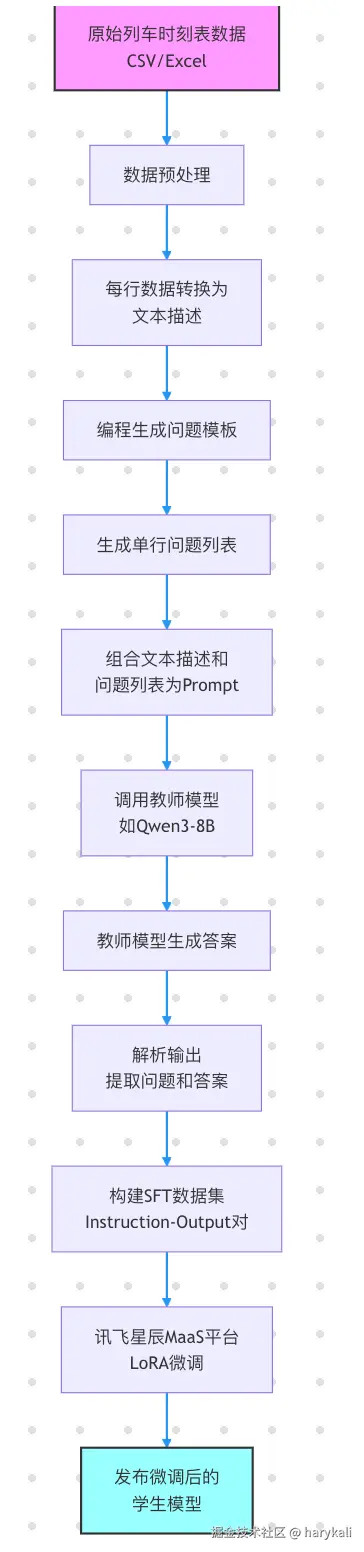
整体的baseline的整体的结构如下图所示:
4.结果展示

