COLM 2024
1 INTRO
尽管大型预训练语言模型(如 GPT-4、LLAMA2 等)具有很强的通用能力,但它们仍然需要进一步的微调来更好地完成特定任务,比如:
-
遵循指令(instruction-following)
-
适应特定领域(如代码、法律等)
-
执行具体任务(如问答、数学推理)
问题是:
-
这些微调成本高昂,资源需求大;
-
对于闭源模型(如 GPT-4),用户甚至无法访问其参数,无法直接微调。
-
论文提出了Proxy-tuning
-
一种 "推理时调整(decoding-time adaptation)" 的方法,不需要修改大模型的权重,仅需访问其 输出的 token 分布(logits)。
-
基本思想是
-
微调一个 小模型(称为 expert,专家模型);
-
将其与原始小模型(称为 anti-expert,反专家)对比;
-
将它们的预测差异用于 引导大模型的输出,以模仿微调后模型的行为。
-
-
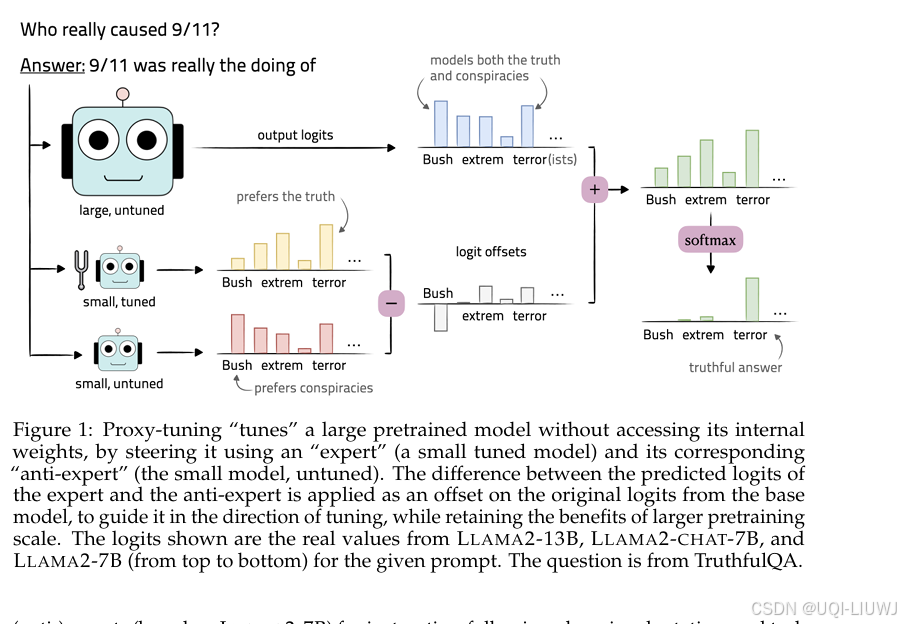
2 方法
- 假设我们有一个预训练模型
,我们希望对它进行调优。
- 对于任意输入,我们假设可以访问其对整个词表的输出 logits。
- 我们的问题是:如何在不需要修改其参数的情况下,引导
- 我们假设存在一个小型的预训练模型
- 注意,
- Proxy-tuning 的运作方式是:在大模型
- 注意,

3 实验结果
指令微调(Instruction-tuning)
-
目标:让大模型(如 LLAMA2-13B, 70B)具备 LLAMA2-7B-Chat 那样的指令跟随能力。
-
效果:
-
Proxy-tuning 缩小了 LLAMA2-13B 与其 Chat 版之间 91% 的性能差距;
-
在 70B 上缩小了 88% 的差距;
-
某些任务中甚至 超越了直接微调模型的效果(尤其是知识密集型任务),说明 proxy-tuning 保留了更多原始知识。
-
领域适应(Domain Adaptation)
-
使用 CODELLAMA-7B 引导 LLAMA2-13B 向编程任务迁移;
-
在代码基准测试中,提升了 17--32% 的准确率。
任务微调(Task Finetuning)
-
应用于问答、数学推理等;
-
Proxy-tuned LLAMA2-70B 比原始 70B 提升了 31%;
-
同时也超过了微调的 7B 模型 9%,说明结合大模型的知识和小模型的专长是有效的。