Find Content Fast in PDF Documents
Let your application locate and extract specific text from PDF files, whether for navigation, validation, or data extraction.
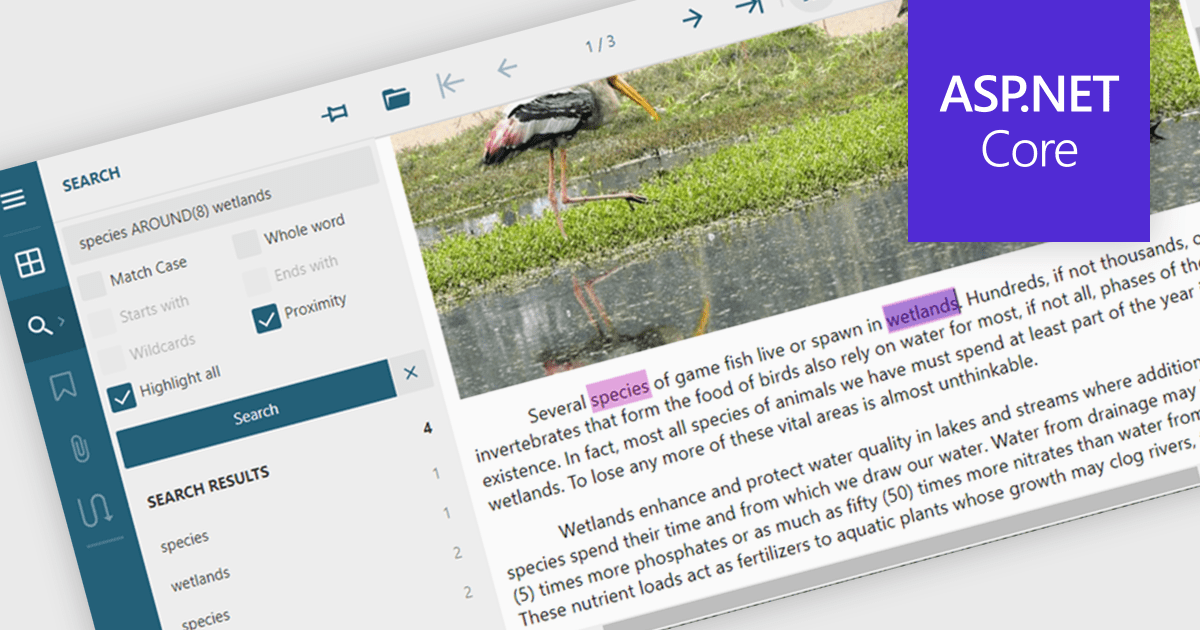
Text searching in a PDF component refers to the ability to programmatically locate and extract text within a PDF document based on specific search criteria. This functionality typically supports case sensitivity, whole word matching, and regular expressions, enabling precise querying across pages or document sections. For developers, it facilitates building features such as keyword highlighting, document indexing, content validation, and automated redaction workflows. By integrating text search, applications can efficiently interact with PDF content without manual review, saving time and improving data accessibility and accuracy across business and document automation systems.