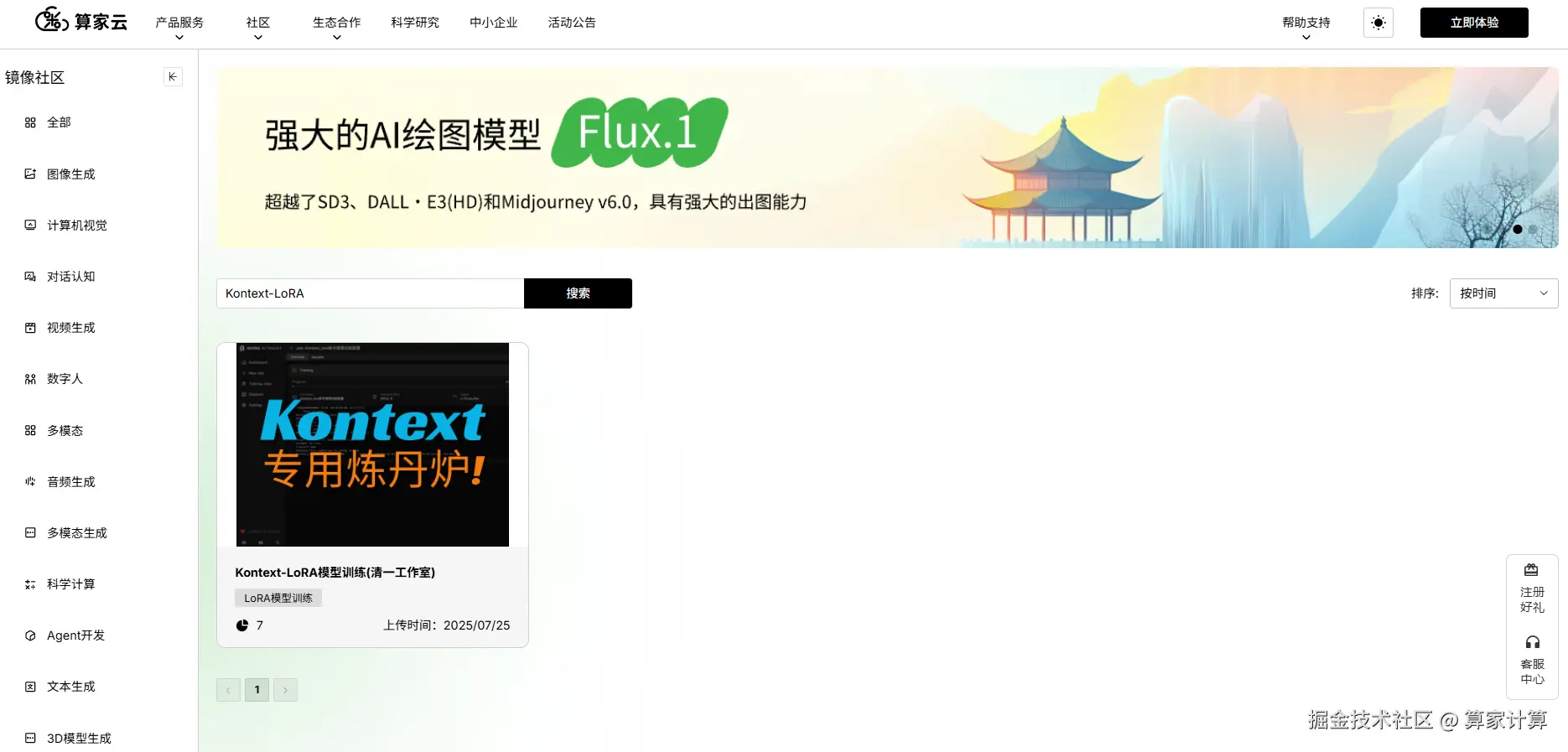
注:该模型可进入算家云"镜像社区"构建
1.打开浏览器翻译插件(可选)
有需要的朋友,推荐使用" 沉浸式翻译"。免费好用!
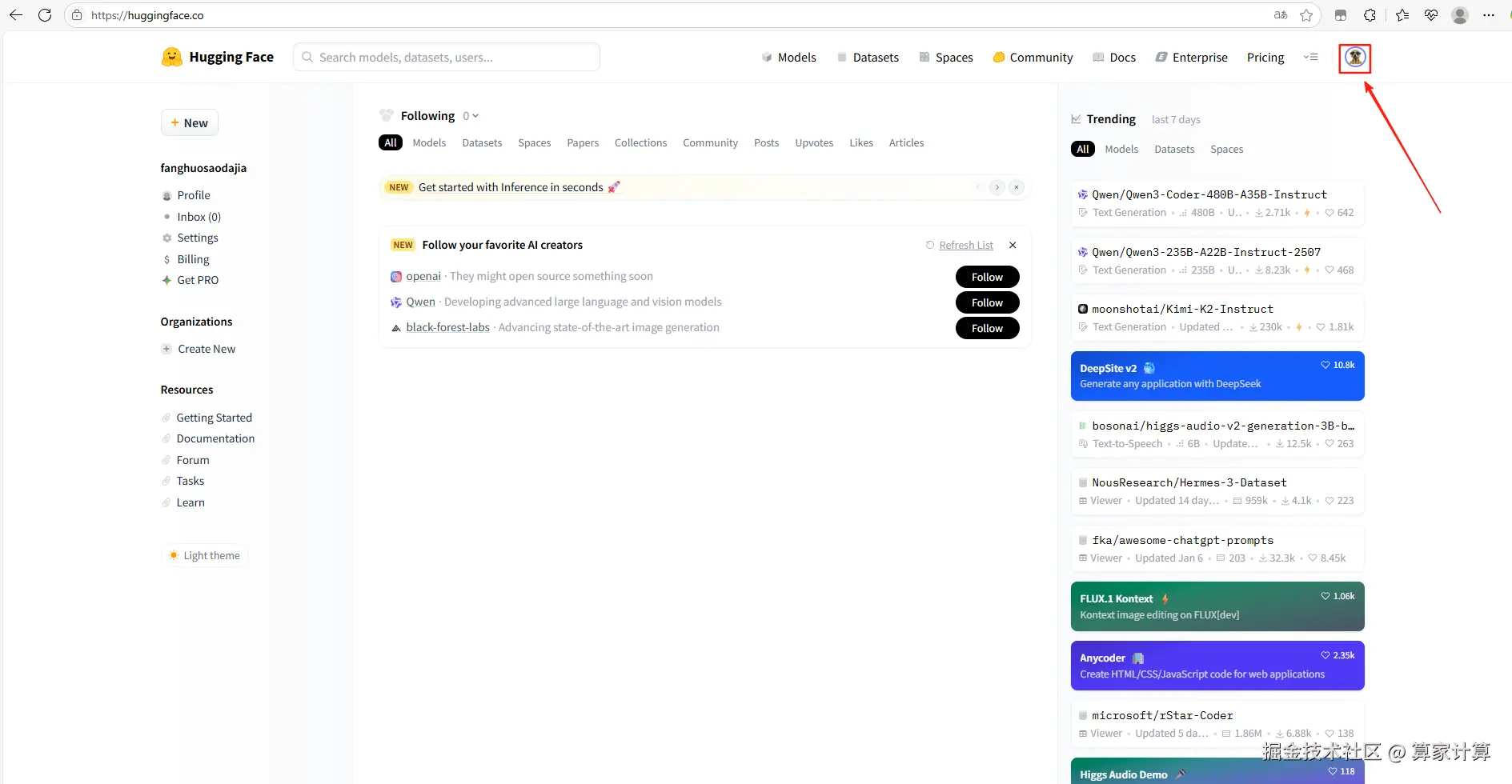
2.创建 Huggingface Token
2.1.登录后,点击头像
2.2.点击 setting
2.3点击 Access Tokens
2.4创建并复制 Token
点击Create new token 新建令牌
输入令牌名字
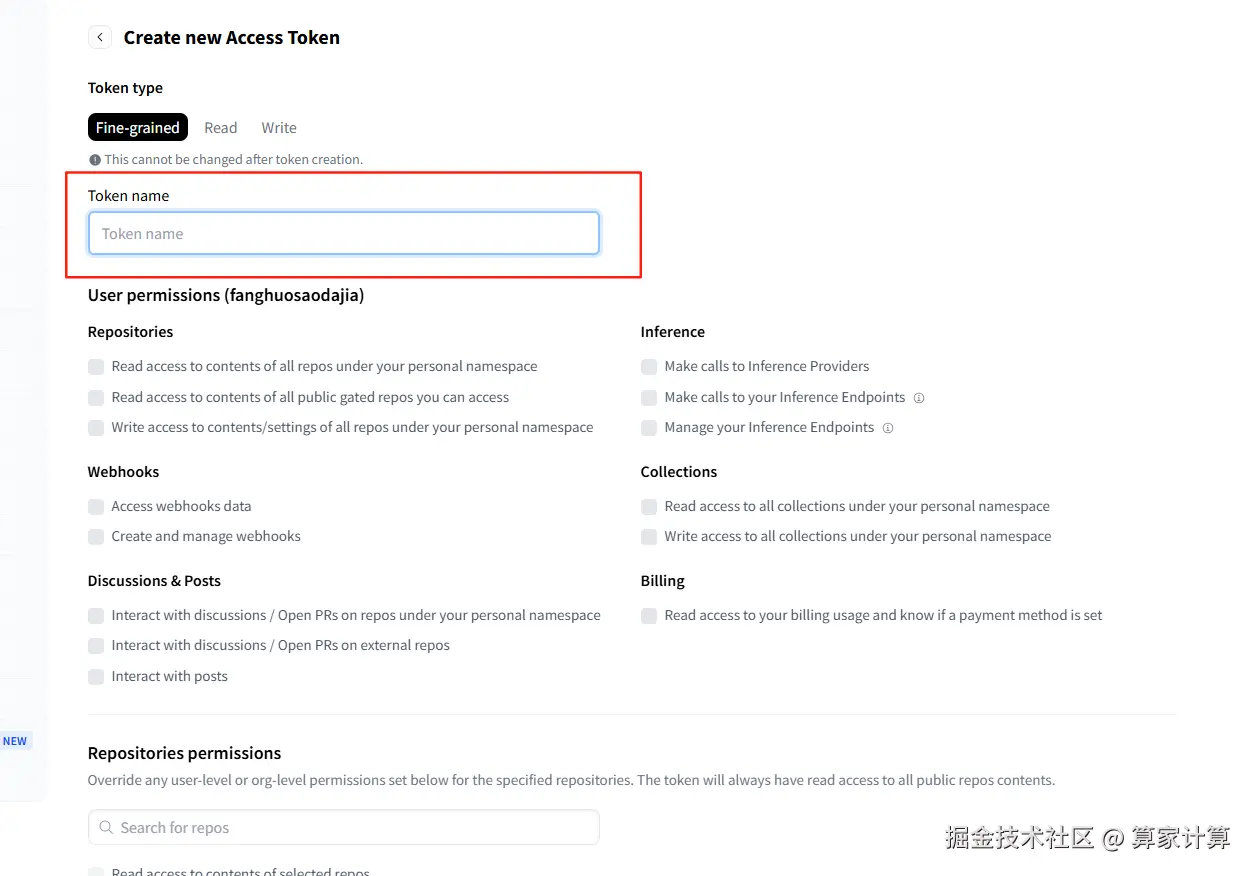
将画框部分打勾,给予权限,然后保存。
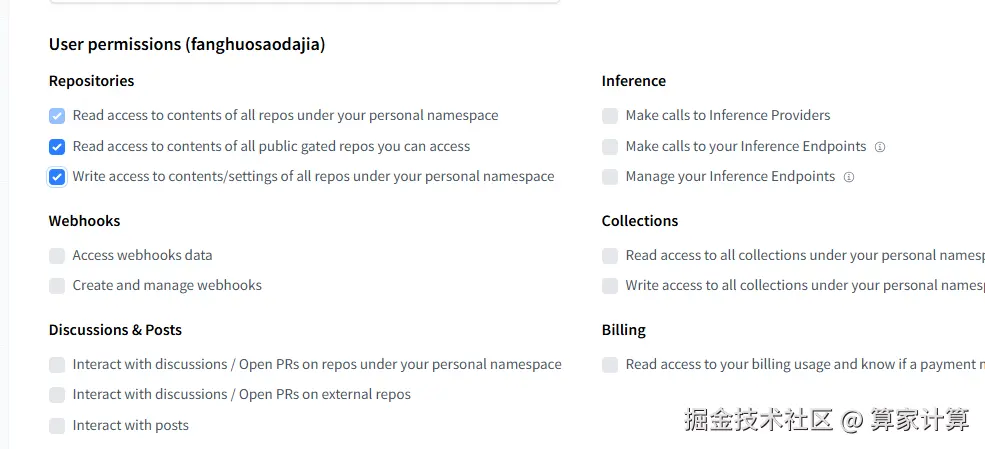
划到最后点击Create token
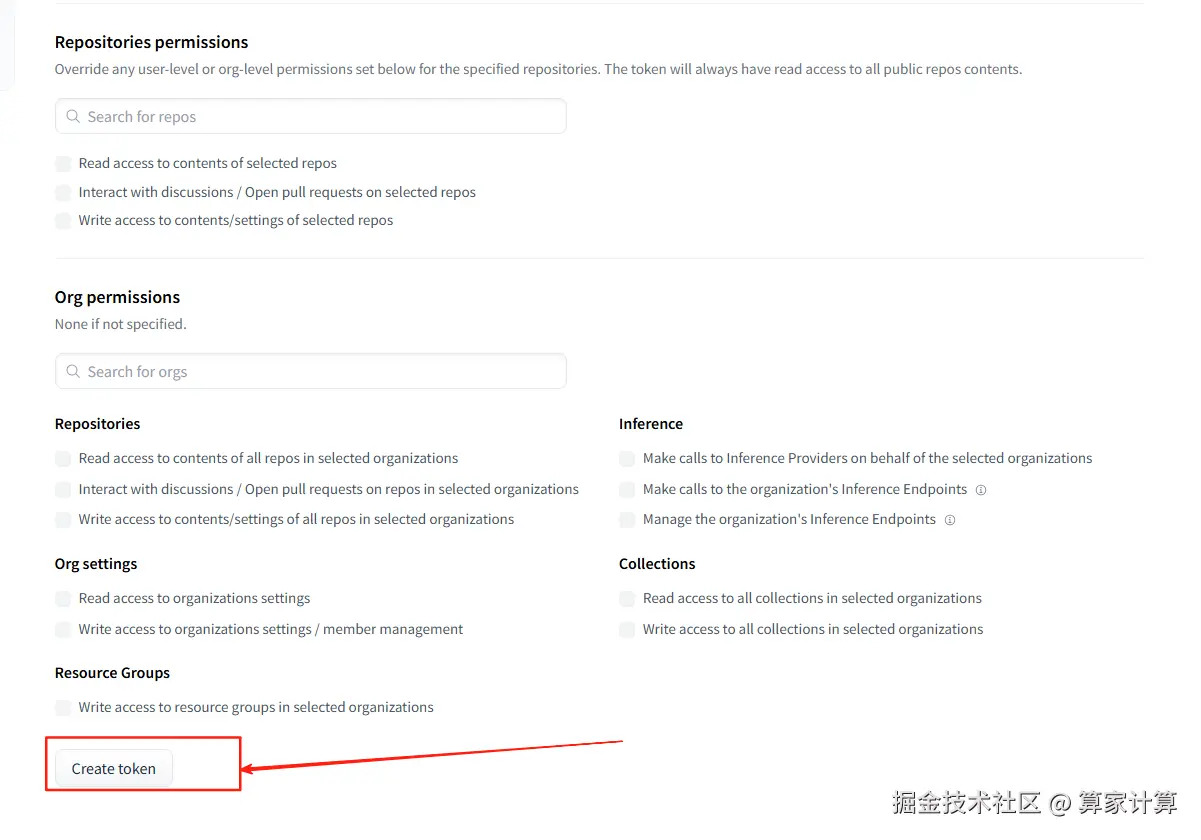
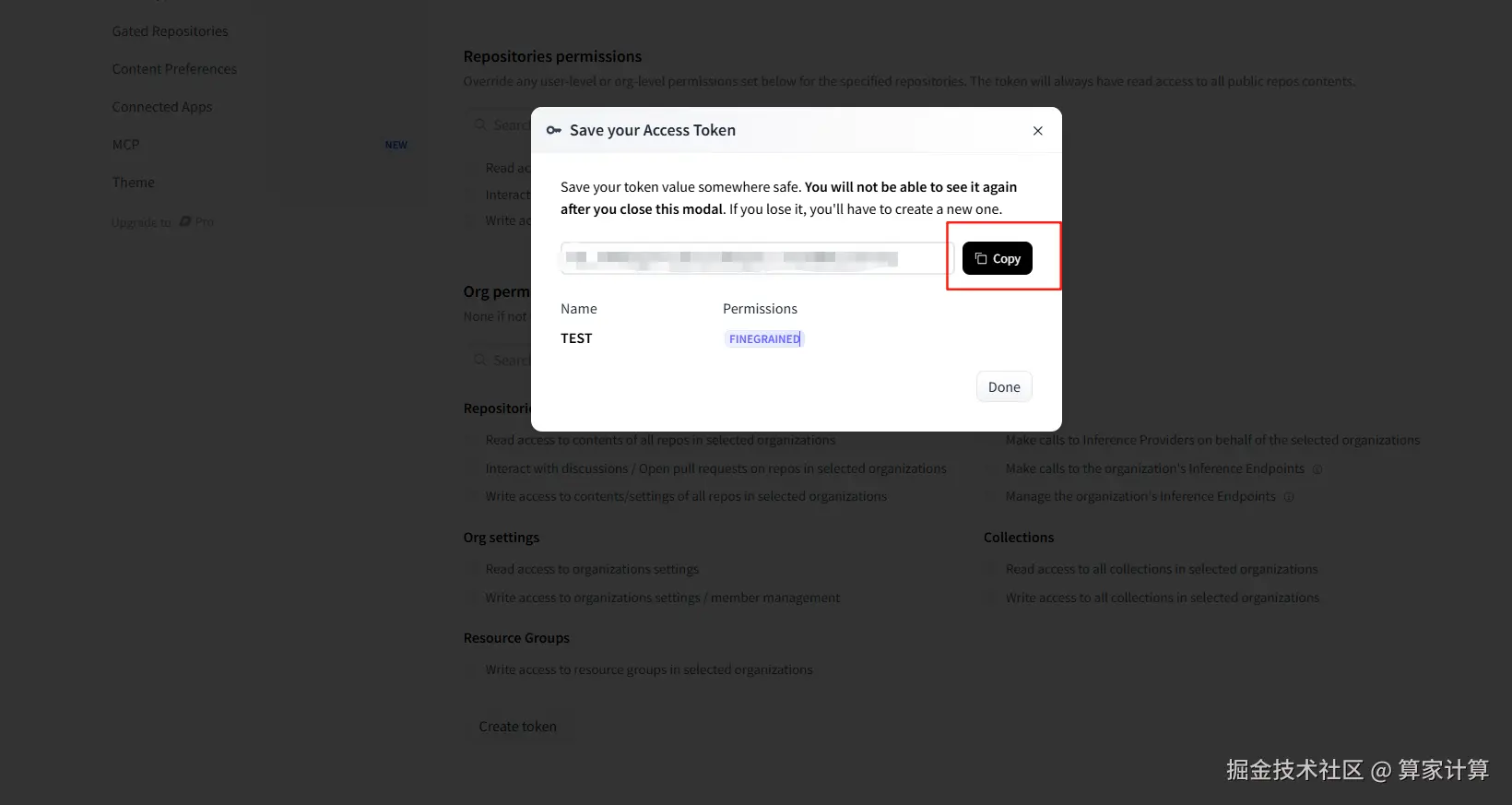
创建成功后,点击复制,复制令牌
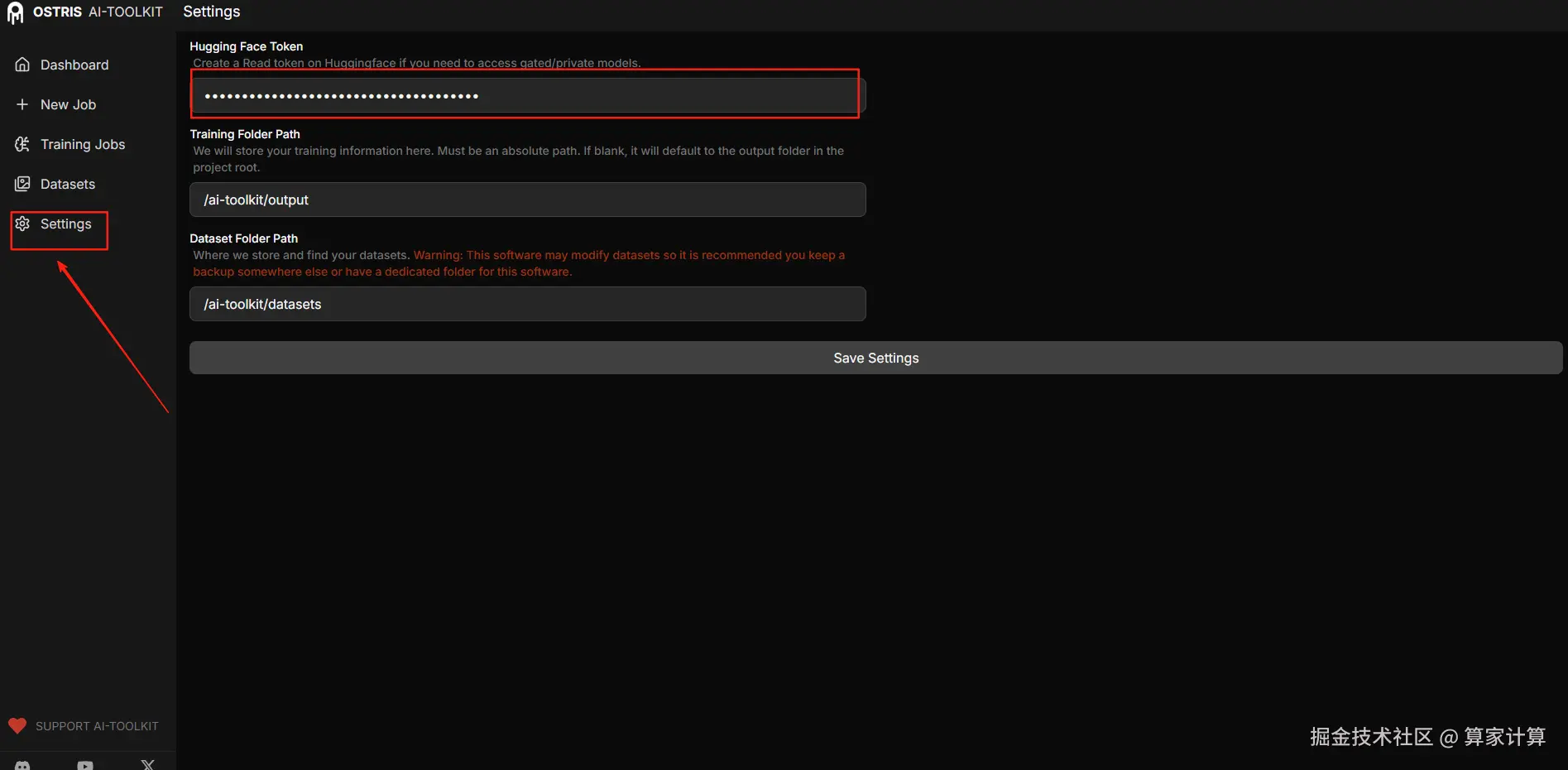
回到 Settings 界面,粘贴,然后保存即可。
3.创建数据集
清一已经提前帮大家创建好了所需的 2 个数据集。【control】代表原始图片,【dataset】代表训练目标图片。
3.1点击文字,即可进入详情界面
3.2.优先添加你的【control】图片
点击上传你的图片
3.4添加Dataset
与前面步骤一样
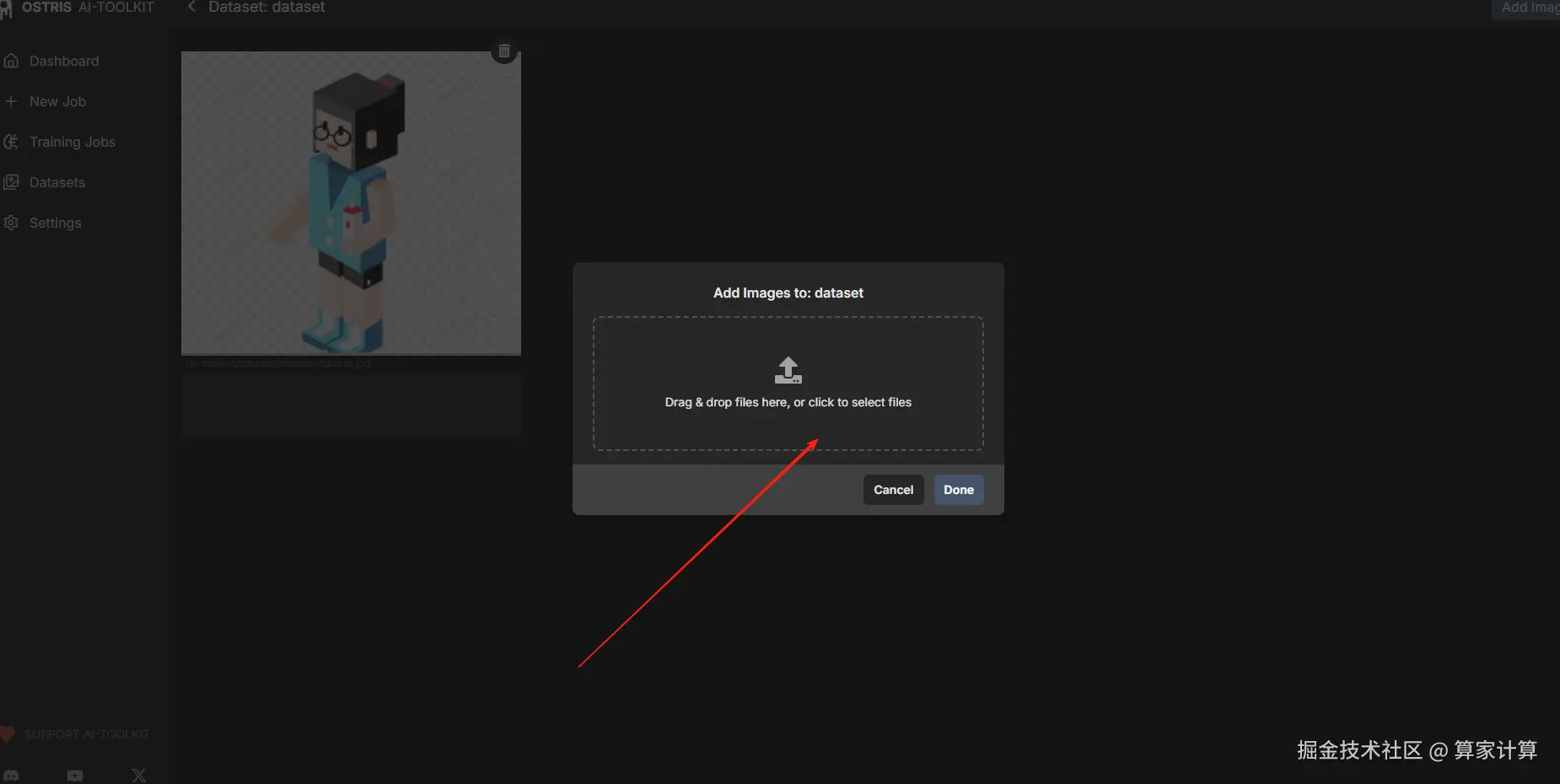
之后在这里输入提示词,也可以在上传阶段,直接选择.text 文本,将自动加载文本。
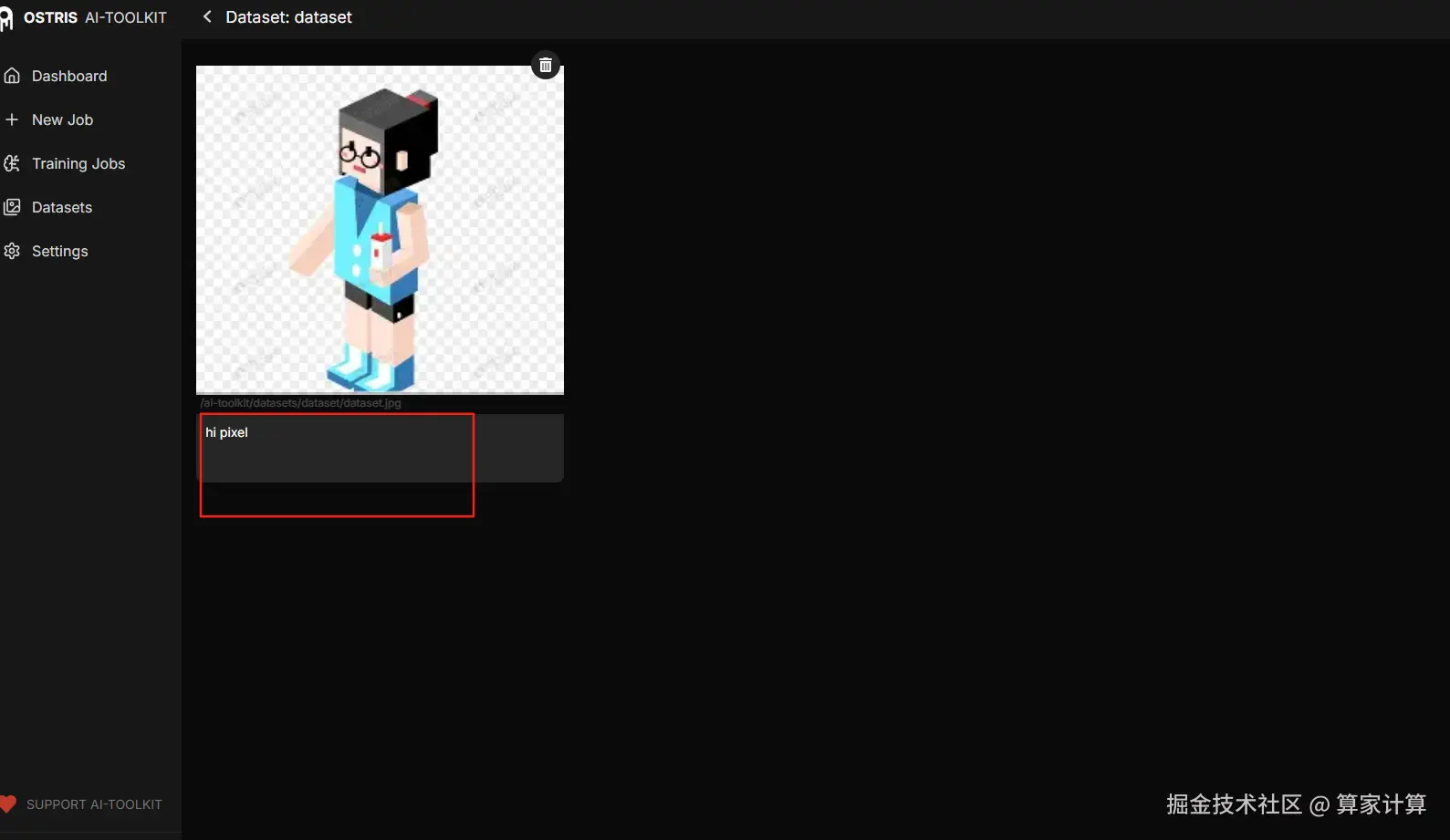
4.创建训练配置
4.1.点击进入

清一提前为大家设置好了"新人专属配置",点击图标即可进入快速配置界面。当然,也可以点击右上方的按钮,创建一个全新的训练 JOB。
使用"新人专属配置",将无需添加 Huggingface Token 即可训练。如果你已经添加了,则可忽略。
对于新手而言,按提示修改图中 4 个部分即可。中间的训练配置无需修改。
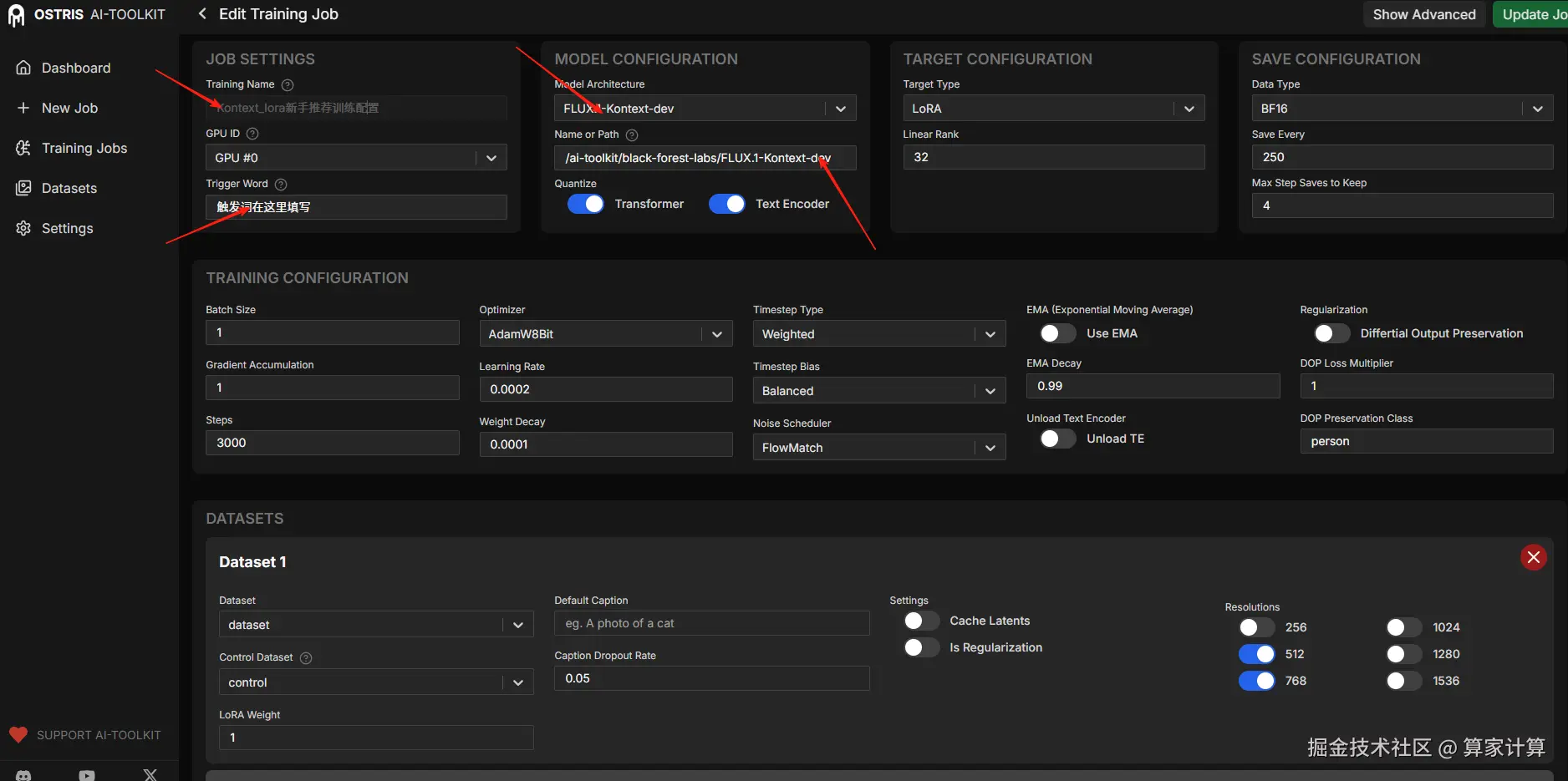
数据集部分,将【dataset】和【control】依次对齐。如果你使用的是 4090 显卡,推荐关闭 1024 分辨率,"有可能"会爆显存。
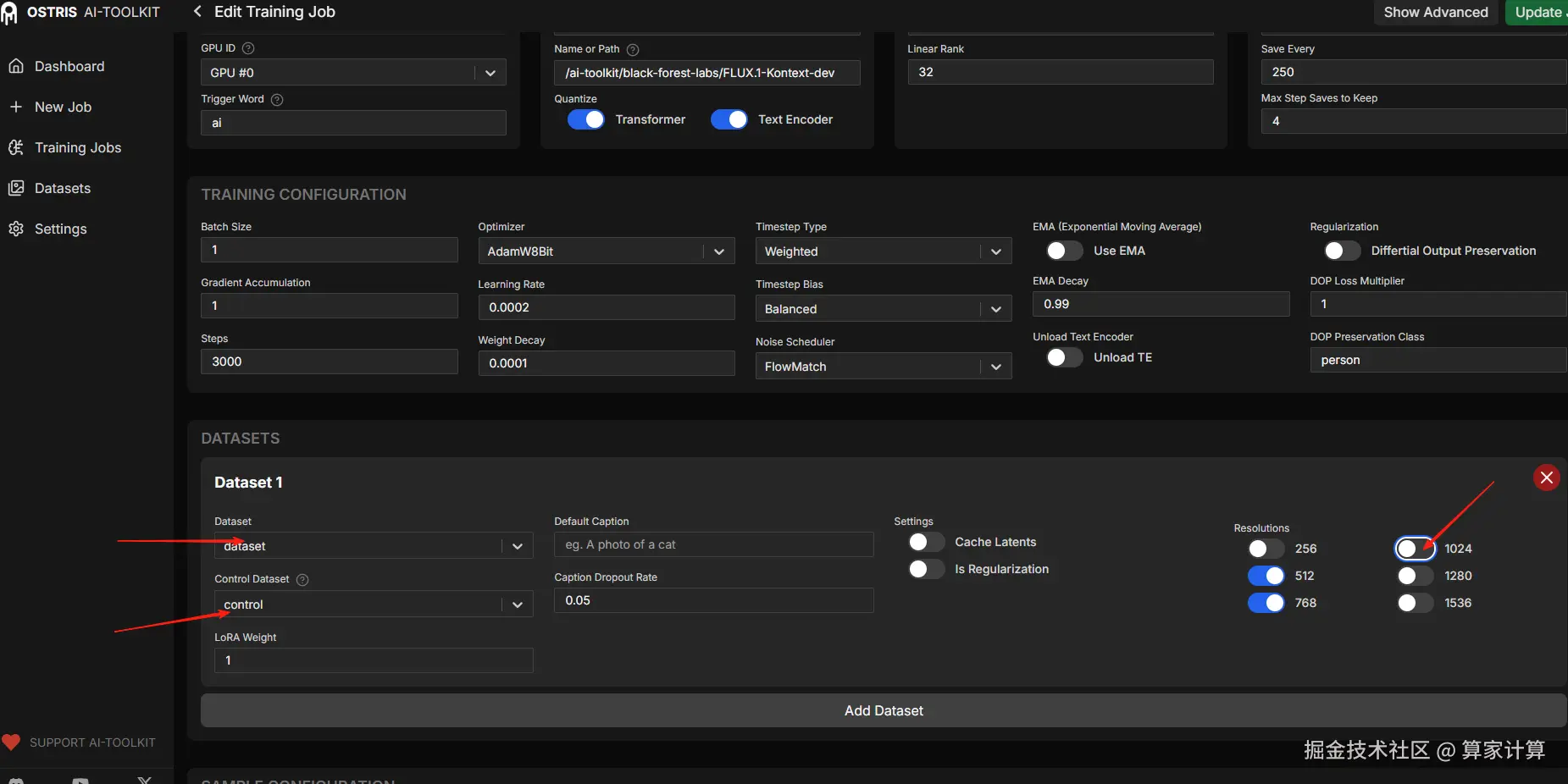
示例配置部分,跳过第一个样本。删除预设的 10 个提示词,按需填写适合自己的。在右边上传你的示例图片即可。
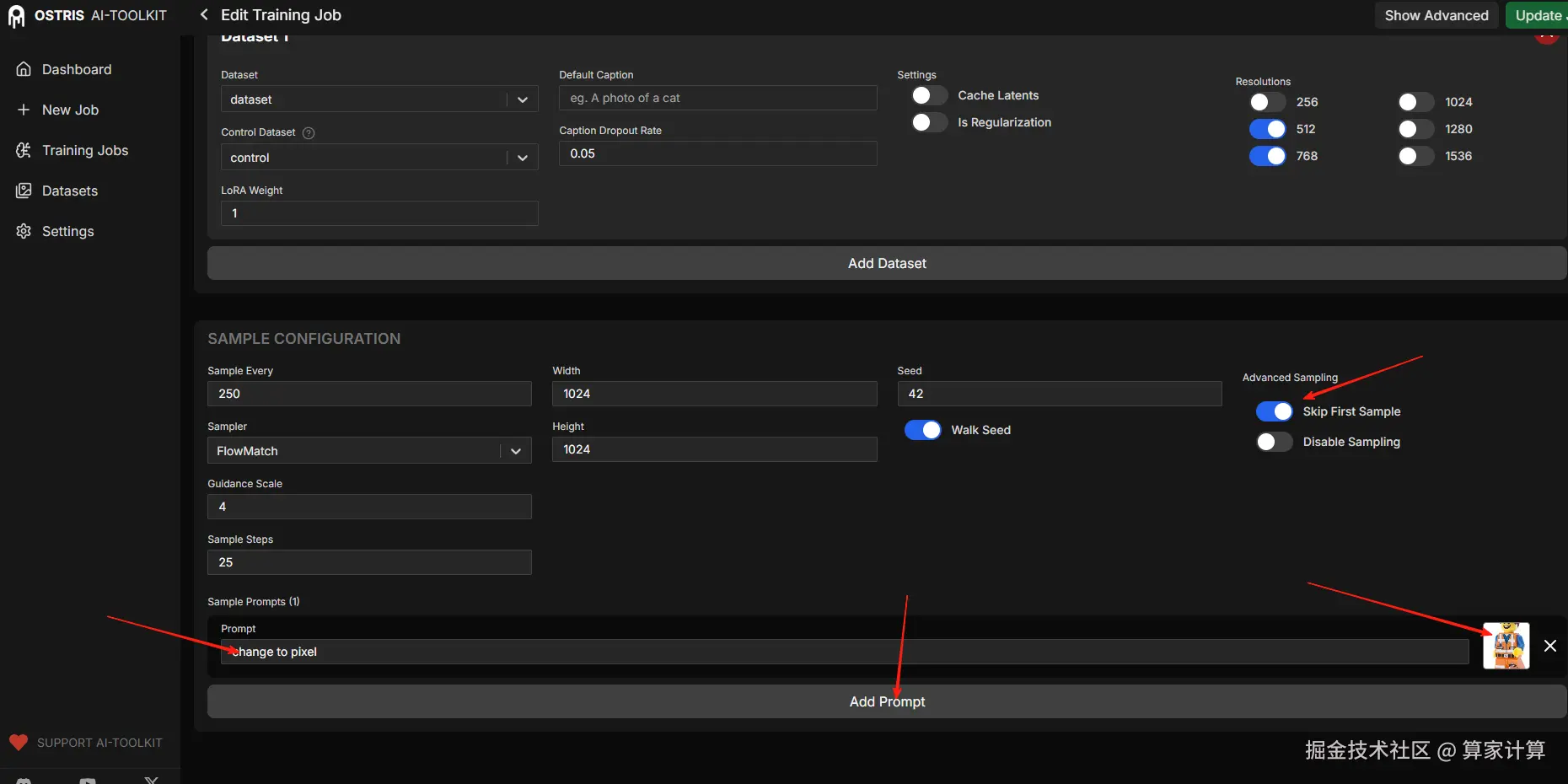
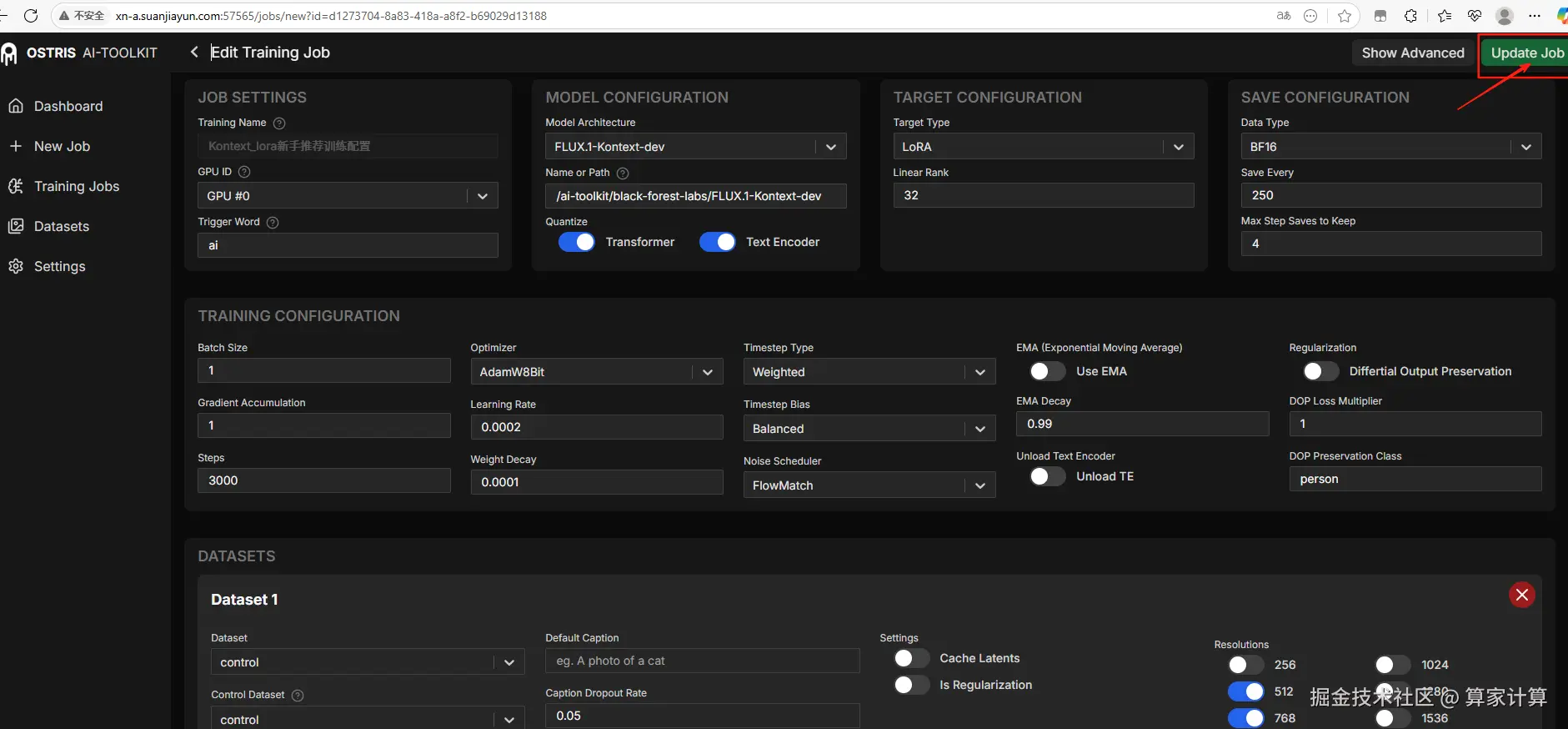
然后点击右上角的"创建",你会来到训练界面
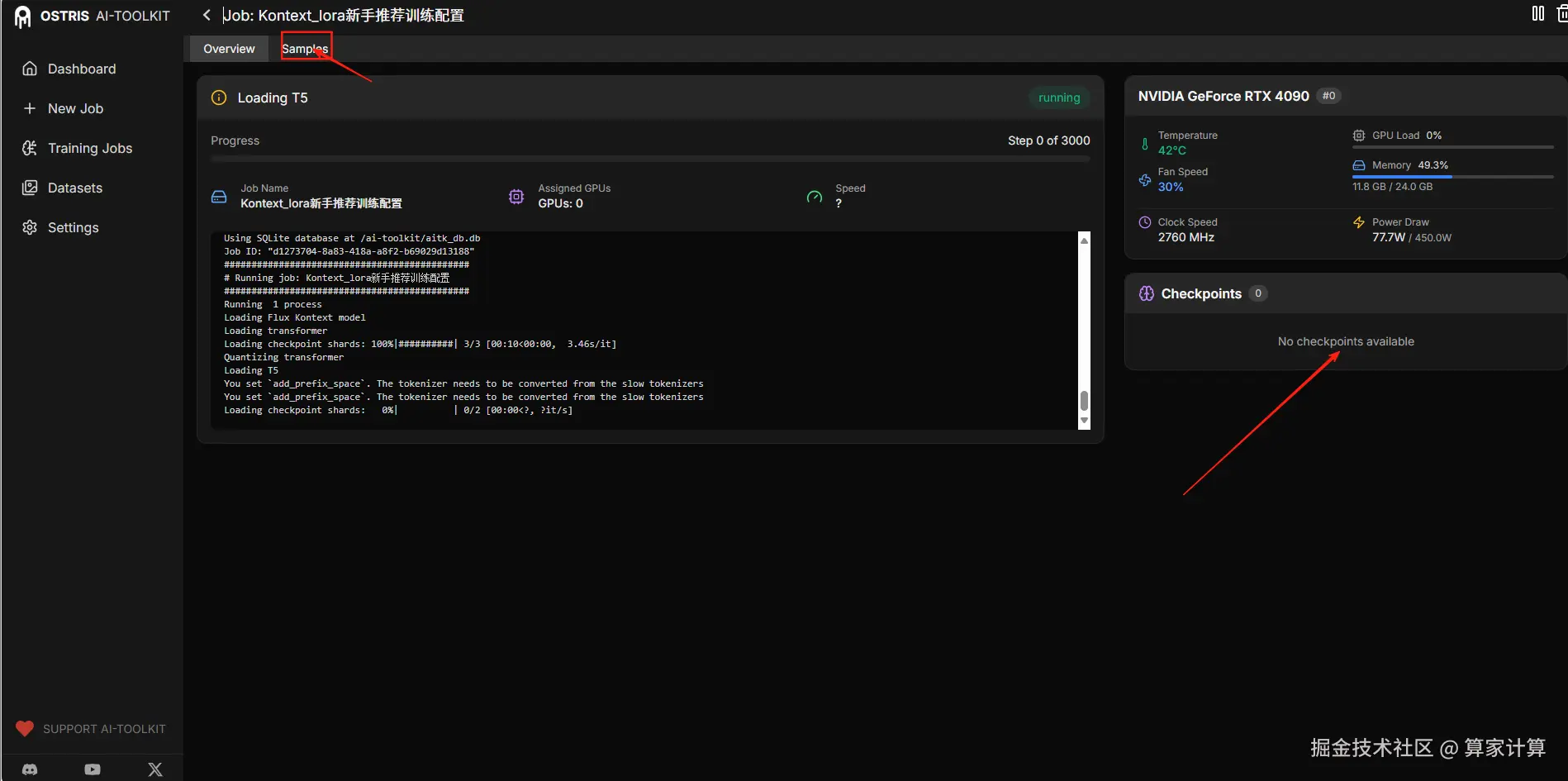
点击右上角的图标,即可开始训练
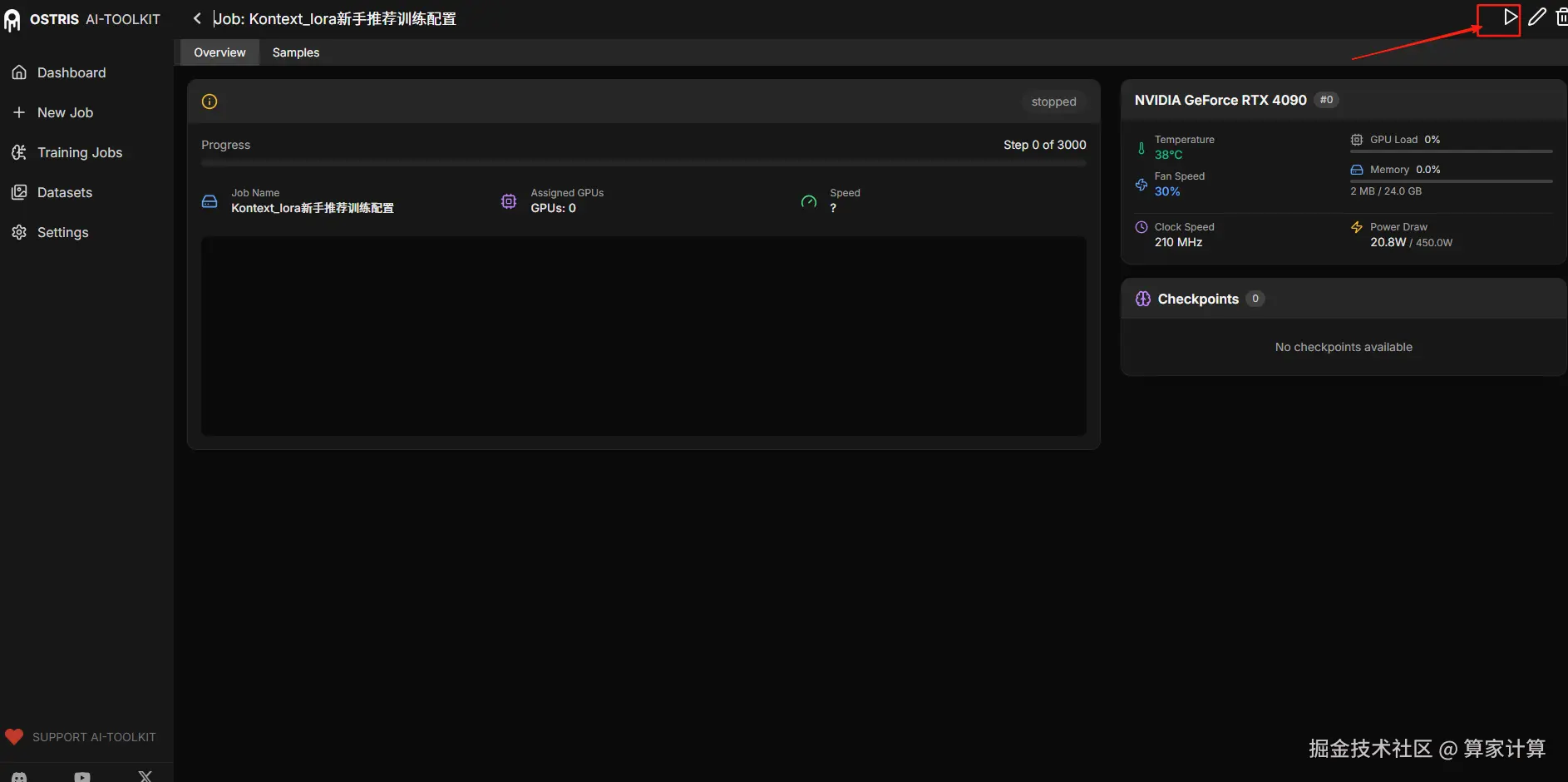
训练过程中的采样图和模型下载位置,可以箭头处找到。