一. 准备训练文件
总结:采用的前后端分离的结构
- 根据上篇文章安装好yolov5所依赖的环境
- 使用yolov5识别的车牌,LPRNet识别车牌文字
- 前后端交互采用flask发送的json数据
- 前端使用的vue3全家桶
- 我这边使用的是CCPD2020数据集的车牌,在csdn搜索一下就可以找到,执行下面py文件可以得到yolo的训练集文件,然后按要求创建好文件夹和文件
ini
# ConvertYOLOFormat.py
import os
import os.path
import re
import shutil
import cv2
from tqdm import tqdm
def listPathAllfiles(dirname):
"""
遍历指定目录下的所有文件并返回一个包含这些文件路径的列表。
"""
result = []
for maindir, subdir, file_name_list in os.walk(dirname):
for filename in file_name_list:
apath = os.path.join(maindir, filename)
result.append(apath)
return result
if __name__ == '__main__':
# 原始数据集的路径,改为自己要保存的路径
data_path = "E:\yolo\CCPD2020\ccpd_green\val"
# 转换后数据的保存路径,改为自己要保存的路径
save_path = "E:\yolo\CCPD2020\ccpd_green\valData"
# 图片和标签文件的保存路径
images_save_path = os.path.join(save_path, "images")
labels_save_path = os.path.join(save_path, "labels")
# 如果不存在则创建图片和标签的保存文件夹
if not os.path.exists(images_save_path): os.makedirs(images_save_path)
if not os.path.exists(labels_save_path): os.makedirs(labels_save_path)
# 获取数据集中所有的图片文件路径
images_files = listPathAllfiles(data_path)
# 初始化计数器用于生成新的文件名
cnt = 1
# 使用tqdm显示进度条
for name in tqdm(images_files):
# 只处理图片文件
if name.endswith(".jpg") or name.endswith(".png"):
# 读取图片
img = cv2.imread(name)
# 获取图片的高度和宽度
height, width = img.shape[0], img.shape[1]
# 使用正则表达式从文件名中提取坐标信息
str1 = re.findall('-\d+&\d+_\d+&\d+-', name)[0][1:-1]
str2 = re.split('&|_', str1)
# 提取边界框坐标
x0 = int(str2[0])
y0 = int(str2[1])
x1 = int(str2[2])
y1 = int(str2[3])
# 计算边界框的中心点坐标以及宽度和高度,并进行归一化
x = round((x0 + x1) / 2 / width, 6)
y = round((y0 + y1) / 2 / height, 6)
w = round((x1 - x0) / width, 6)
h = round((y1 - y0) / height, 6)
# 构建标签文件名和路径
txtfile = os.path.join(labels_save_path, "green_plate_" + str(cnt).zfill(6) + ".txt")
# 构建图片文件名和路径
imgfile = os.path.join(images_save_path,
"green_plate_" + str(cnt).zfill(6) + "." + os.path.basename(name).split(".")[-1])
# 写入标签文件
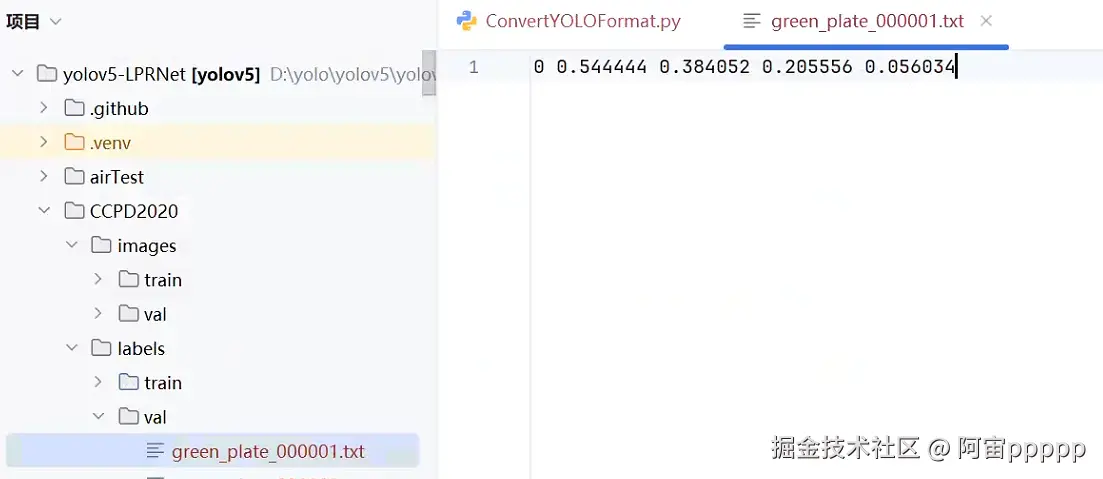
open(txtfile, "w").write(" ".join(["0", str(x), str(y), str(w), str(h)]))
# 移动图片到新位置
shutil.move(name, imgfile)
# 更新计数器
cnt += 1- 要改为yolo监测的文件夹结构

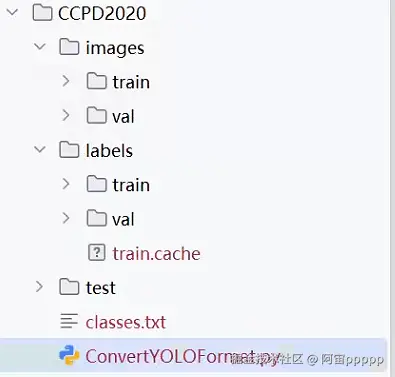
-
其中images中train和val存放的图片,要和label中的train和val标签文件一一对应
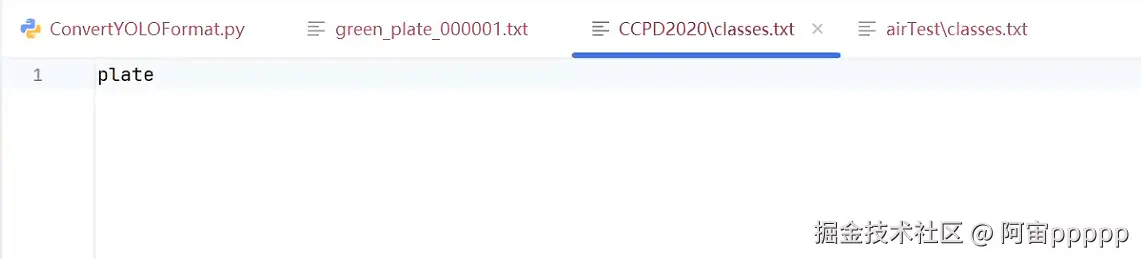
-
在images和val的同级目录下的classes.txt文件中放入监测的类型,这边监测的是一种类型,就是车牌(plate)
-
如果是两种就是这种格式
2. 准备好训练集文件后,创建yaml文件,改变train.py文件参数,再执行train.py训练模型
-
与yolov5官方提供的coco.yaml文件一样,创建一个plate.yaml文件,修改参数,指向刚刚的训练集文件夹路径
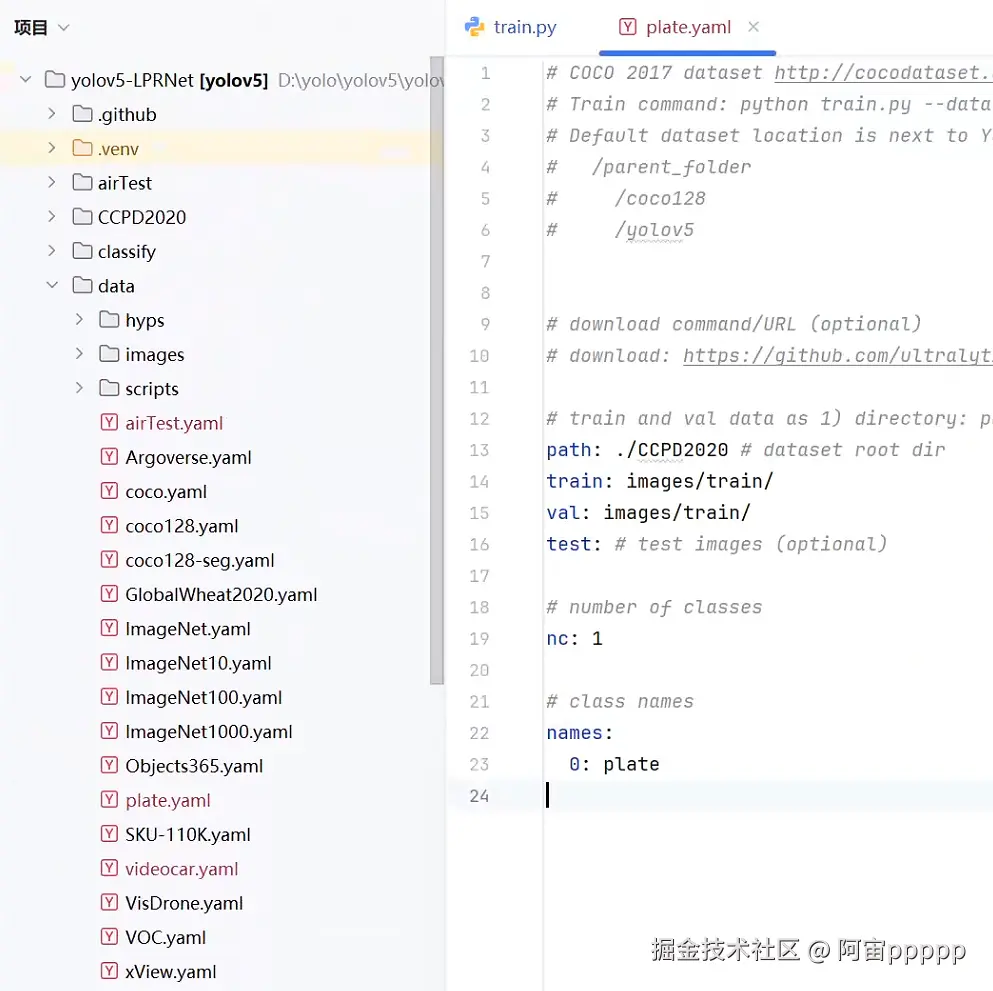
-
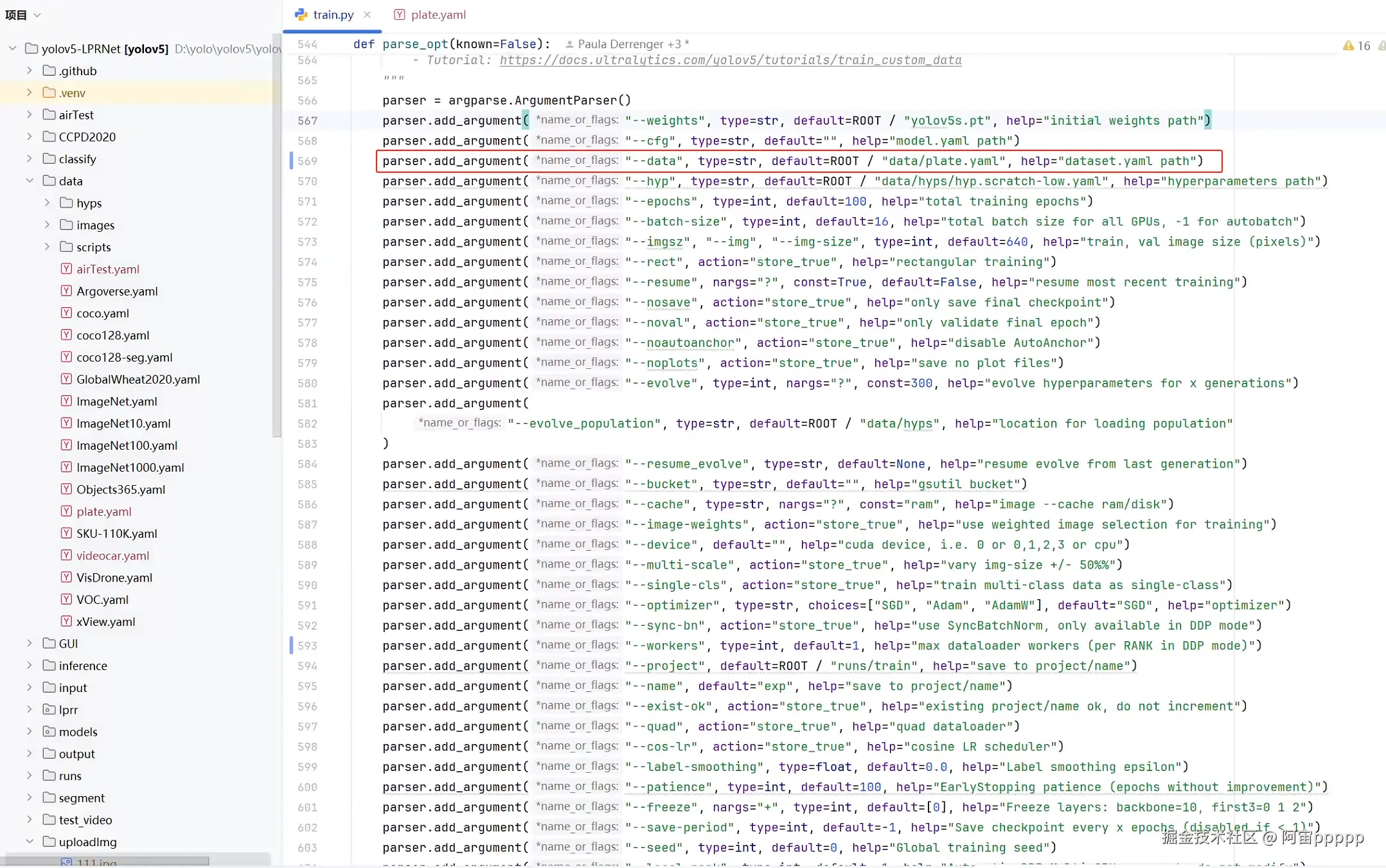
修改train.py的参数,使用plate.yaml
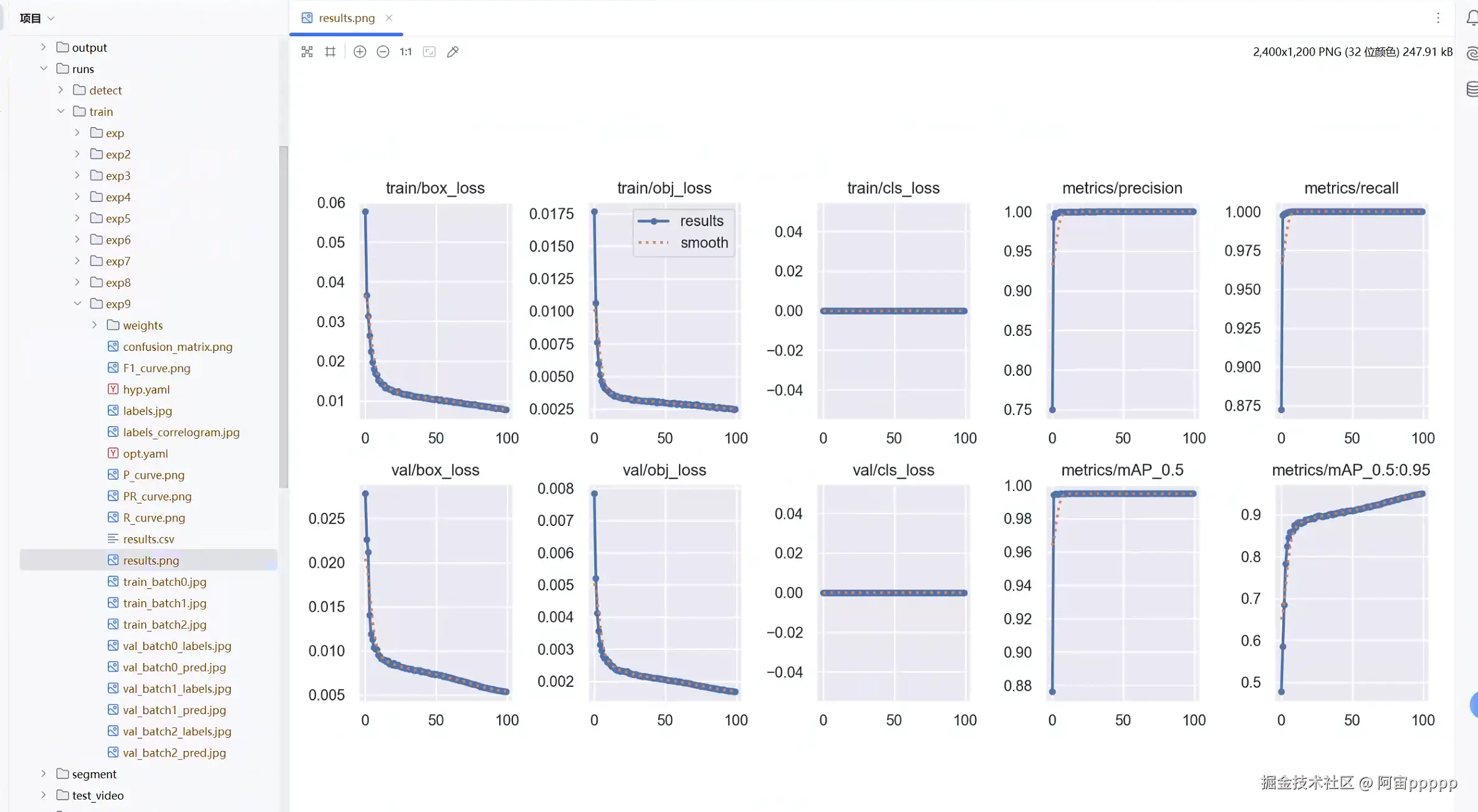
3. 执行train.py训练模型
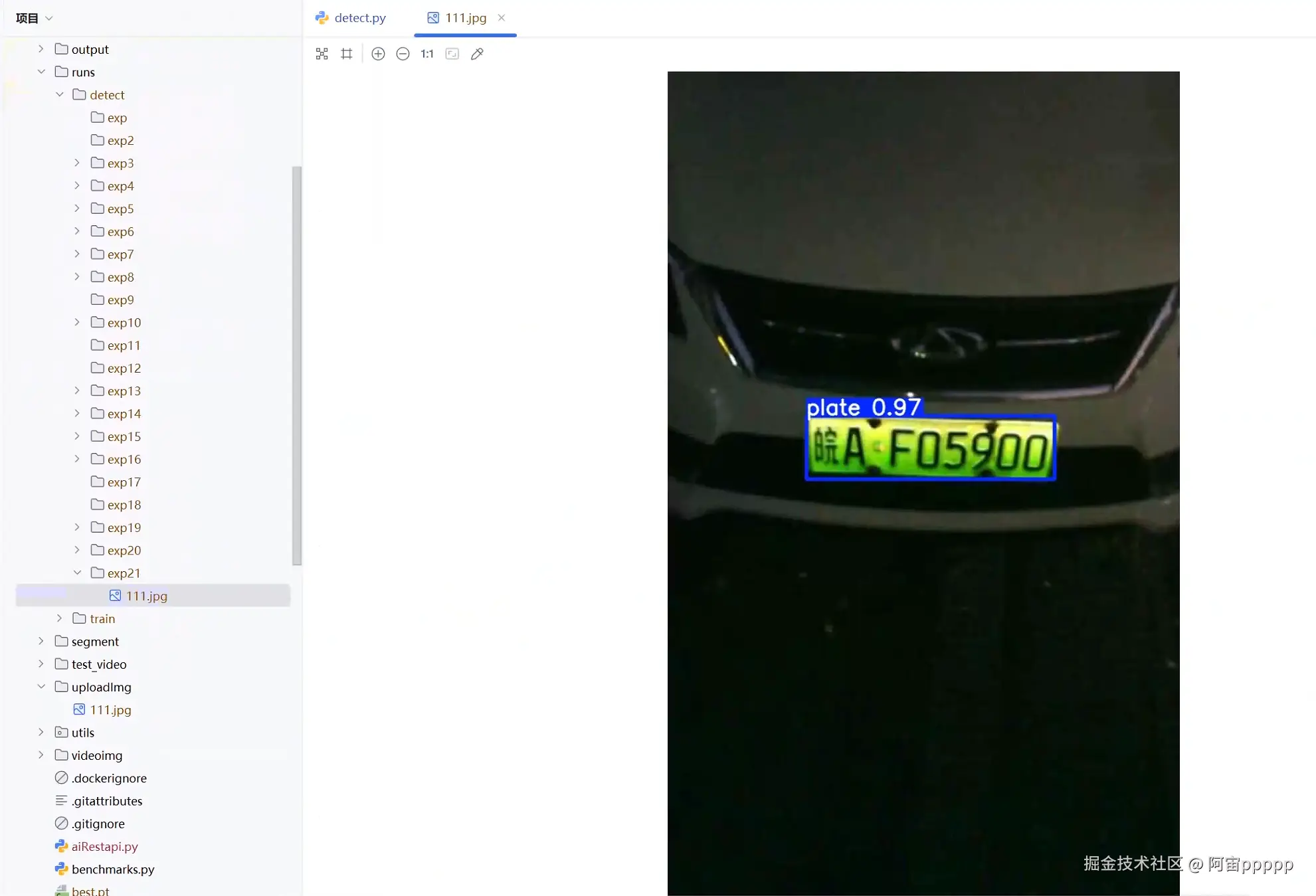
4.执行detect.py检测图片或视频
-
修改参数,刚刚训练好的权重文件best.pt路径,需要检测的图片或视频路径,plate.yaml路径
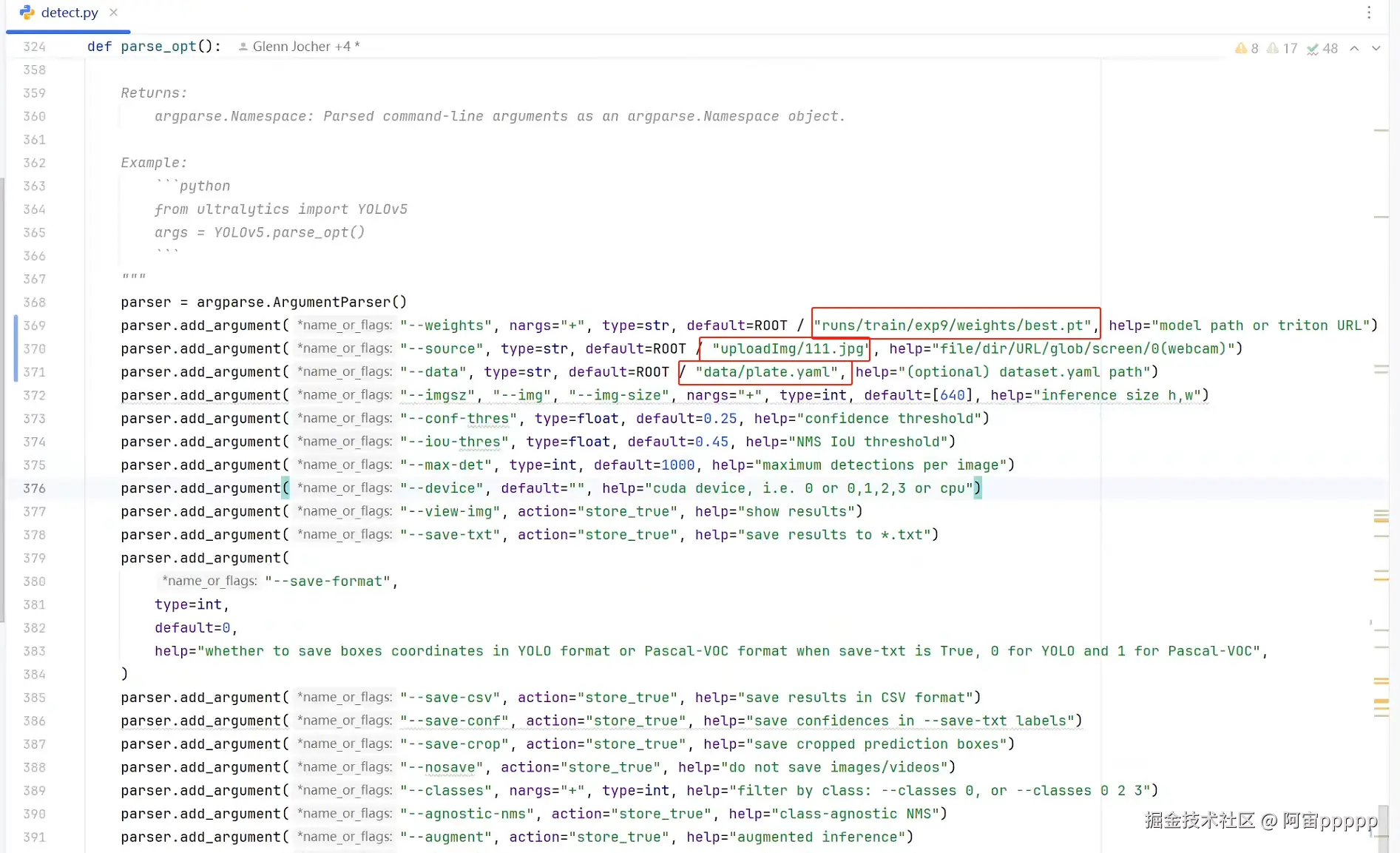
-
修改好后,执行detect.py文件,可以看到检测结果