本教程仅用于技术研究,请确保遵守目标网站的服务条款。实际使用前应获得官方授权,避免高频请求影响服务器,否则可能承担法律责任。
此脚本仅拦截公开评论接口,不涉及用户私密数据。请勿修改代码监听其他请求。
分享一下爬某抖评论的爬虫学习,有一定的风险(代理部署导致浏览器连接断开,但有解决方案,需要认真学习)
首先,需要的软件:nodejs与mitmproxy可以先下载,避免后面断档了(问deepseek),最好下载个vscode(编辑代码和终端都有,参考deepseek,给他这些代码让他去教你把文件放到同一个文件夹里面)
然后直接发脚本代码:
文件名(不能修改):server.js,如下:
const http = require('http');
const fs = require('fs');
const path = require('path');
const PORT = 3000;
// 存储所有视频评论数据
const allVideoComments = {};
// 启动服务器
const server = http.createServer((req, res) => {
if (req.method === 'POST') {
let body = '';
req.on('data', chunk => body += chunk);
req.on('end', () => {
try {
const params = new URLSearchParams(body);
const fullUrl = params.get('url');
const responseRaw = params.get('response');
console.log('📥 收到评论请求副本 URL:', fullUrl);
console.log(params,'params')
if (!responseRaw || responseRaw.trim().length === 0) {
console.warn('⚠️ 副本中没有包含评论响应内容');
res.writeHead(200);
return res.end('空响应');
}
// 打印部分原始内容
console.log('📦 原始评论内容预览:');
console.log(responseRaw.slice(0, 300));
const response = JSON.parse(responseRaw);
const awemeId = new URL(fullUrl).searchParams.get('aweme_id');
const videoUrl = `https://www.douyin.com/video/${awemeId}`;
if (!response.comments) {
console.warn('⚠️ 评论数据中无 comments 字段');
res.writeHead(200);
return res.end('无评论字段');
}
// 初始化数据结构
if (!allVideoComments[videoUrl]) {
allVideoComments[videoUrl] = {
video_id: awemeId,
comments: []
};
}
// 格式化评论
const formattedComments = response.comments.map(comment => ({
user_id: comment.user?.uid || '未知用户',
user_nickname: comment.user?.nickname || '匿名用户',
comment_content: comment.text,
comment_date: new Date(comment.create_time * 1000).toISOString(),
like_count: comment.digg_count,
ip_region: comment.ip_label,
is_hot: comment.is_hot,
reply_count: comment.reply_comment_total
}));
allVideoComments[videoUrl].comments.push(...formattedComments);
saveToFile(allVideoComments);
res.writeHead(200, { 'Content-Type': 'application/json' });
res.end(JSON.stringify({
video_url: videoUrl,
comment_count: formattedComments.length,
comments: formattedComments
}, null, 2));
console.log(`✅ 已保存 ${formattedComments.length} 条评论(${videoUrl})`);
} catch (err) {
console.error('❌ 错误:', err);
res.writeHead(500);
res.end('解析失败');
}
});
} else {
res.writeHead(200);
res.end('请通过 POST 发送副本数据');
}
});
// 写入 JSON 文件
function saveToFile(data) {
const filePath = path.join(__dirname, 'douyin_comments.json');
fs.writeFileSync(filePath, JSON.stringify(data, null, 2), 'utf8');
console.log(`💾 已保存评论数据到:${filePath}`);
}
// 启动监听
server.listen(PORT, () => {
console.log(`🚀 本地服务已启动:http://localhost:${PORT}`);
console.log('📡 等待mitmproxy发送副本...');
});文件名(不能修改):dup_forward.py,如下:
from mitmproxy import http
import requests
def response(flow: http.HTTPFlow):
if "/aweme/v1/web/comment/list/" in flow.request.pretty_url:
try:
requests.post(
"http://127.0.0.1:3000", # 发送给本地 Node.js
data={
"url": flow.request.pretty_url,
"response": flow.response.get_text()
},
timeout=3
)
print("✅ 已转发副本:", flow.request.pretty_url)
except Exception as e:
print("❌ 副本发送失败:", e)文件名(不能修改):comment.js
const XLSX = require('xlsx');
const fs = require('fs');
// 1. 读取 JSON 文件
const jsonData = JSON.parse(fs.readFileSync('douyin_comments.json', 'utf8'));
// 2. 准备所有评论数据(带视频链接)
const allComments = [];
// 遍历每个视频
Object.keys(jsonData).forEach(videoUrl => {
const videoData = jsonData[videoUrl];
const videoId = videoData.video_id;
// 遍历当前视频的评论
videoData.comments.forEach(comment => {
allComments.push({
"视频链接": videoUrl, // 新增:标记评论所属视频
"视频ID": videoId, // 可选:方便筛选
"用户ID": comment.user_id,
"用户昵称": comment.user_nickname,
"评论内容": comment.comment_content,
"评论日期": comment.comment_date,
"点赞数": comment.like_count,
"IP属地": comment.ip_region,
"是否热门": comment.is_hot ? "是" : "否",
"回复数": comment.reply_count
});
});
});
// 3. 创建 Excel 工作簿
const workbook = XLSX.utils.book_new();
const worksheet = XLSX.utils.json_to_sheet(allComments);
// 4. 导出文件
XLSX.utils.book_append_sheet(workbook, worksheet, "某抖评论数据");
XLSX.writeFile(workbook, 'douyin_comments.xlsx');
console.log('✅ 数据已导出至 douyin_comments.xlsx');文件名(不能修改):comment50.js
const XLSX = require('xlsx');
const fs = require('fs');
// 1. 读取 JSON 文件
const jsonData = JSON.parse(fs.readFileSync('douyin_comments.json', 'utf8'));
// 2. 准备所有评论数据(带视频链接)
const allComments = [];
// 每个视频只保留前 50 条评论
const MAX_COMMENTS_PER_VIDEO = 50;
Object.keys(jsonData).forEach(videoUrl => {
const videoData = jsonData[videoUrl];
const videoId = videoData.video_id;
// 取前 50 条评论(如果不足 50 条则取全部)
const topComments = videoData.comments.slice(0, MAX_COMMENTS_PER_VIDEO);
topComments.forEach(comment => {
allComments.push({
"视频链接": videoUrl,
"视频ID": videoId,
"用户ID": comment.user_id,
"用户昵称": comment.user_nickname,
"评论内容": comment.comment_content,
"评论日期": comment.comment_date,
"点赞数": comment.like_count,
"IP属地": comment.ip_region,
"是否热门": comment.is_hot ? "是" : "否",
"回复数": comment.reply_count
});
});
});
// 3. 创建 Excel 工作簿
const workbook = XLSX.utils.book_new();
const worksheet = XLSX.utils.json_to_sheet(allComments);
// 4. 导出文件
XLSX.utils.book_append_sheet(workbook, worksheet, "某抖评论数据");
XLSX.writeFile(workbook, 'douyin_comments.xlsx');
console.log('✅ 每个视频最多导出 50 条评论,已写入 douyin_comments.xlsx');package.json
{
"dependencies": {
"@alicloud/pop-core": "^1.8.0",
"@google/genai": "^1.9.0",
"@google/generative-ai": "^0.24.1",
"axios": "^1.10.0",
"dotenv": "^17.2.0",
"http-proxy": "^1.18.1",
"https-proxy-agent": "^7.0.6",
"xlsx": "^0.18.5"
}
}用随便编辑器把他们几个文件放在同一个目录之下
类似这样(我这里有点乱):
然后你们需要在vscode里面打开终端:
 重复上述操作,因为要开两个终端,还是这个操作
重复上述操作,因为要开两个终端,还是这个操作
然后结果如下:你们会发现下面有一个栏,然后这个栏的右边是两个终端的按钮(一会需要切换) 然后先在终端执行代码,npm install,按一下空格。就会自动安装包依赖了(前提是你们前面已经下载了nodejs)
然后先在终端执行代码,npm install,按一下空格。就会自动安装包依赖了(前提是你们前面已经下载了nodejs)
 然后你们就会多一个node_modules这个东西,说明已经下载成功了。
然后你们就会多一个node_modules这个东西,说明已经下载成功了。
 然后就是开始部署代码了:
然后就是开始部署代码了:
终端输入node server.js,然后按空格,就会弹出本地服务已启动。
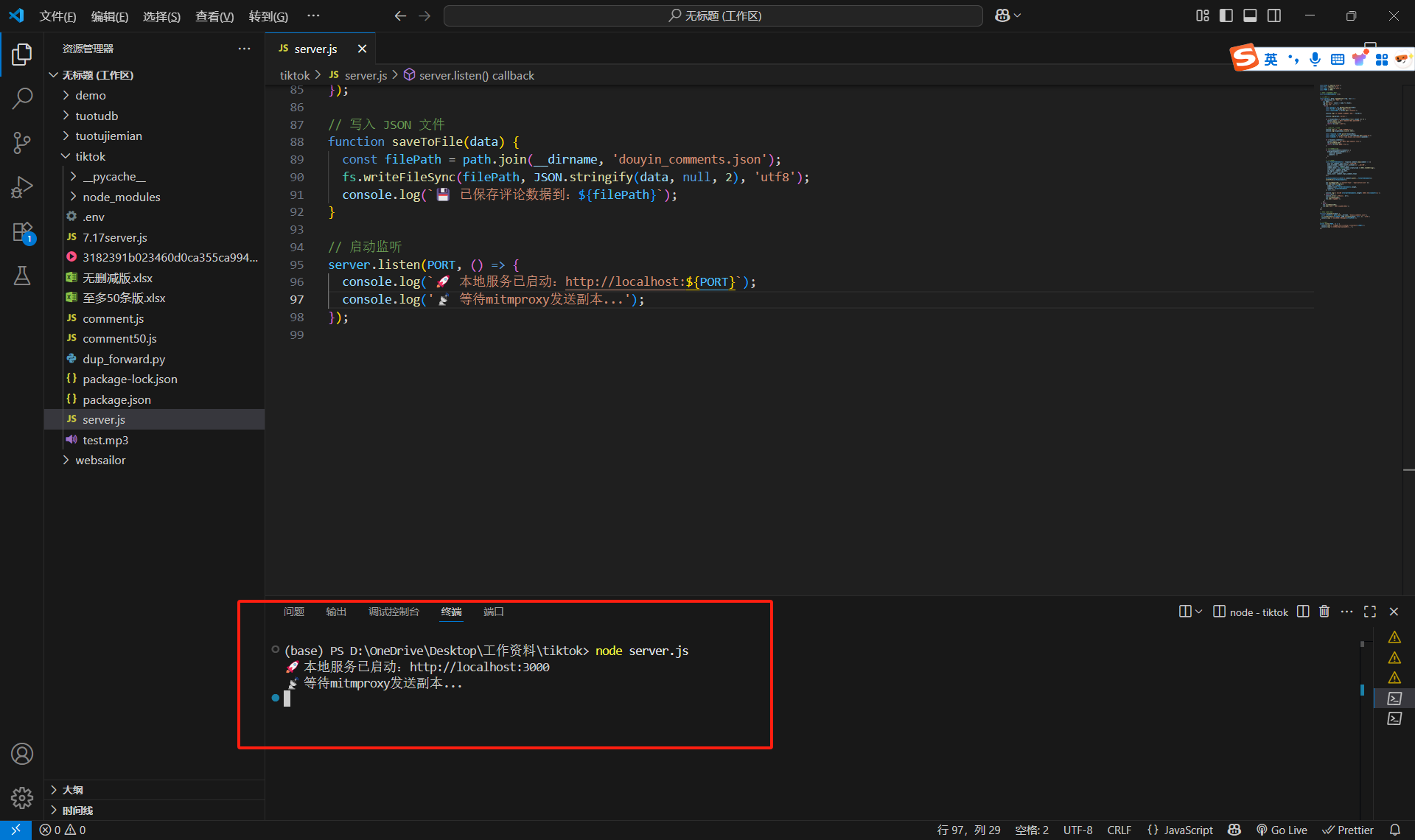
然后切换终端(注意!点红色的地方,这时候已经切换到第二个终端了)
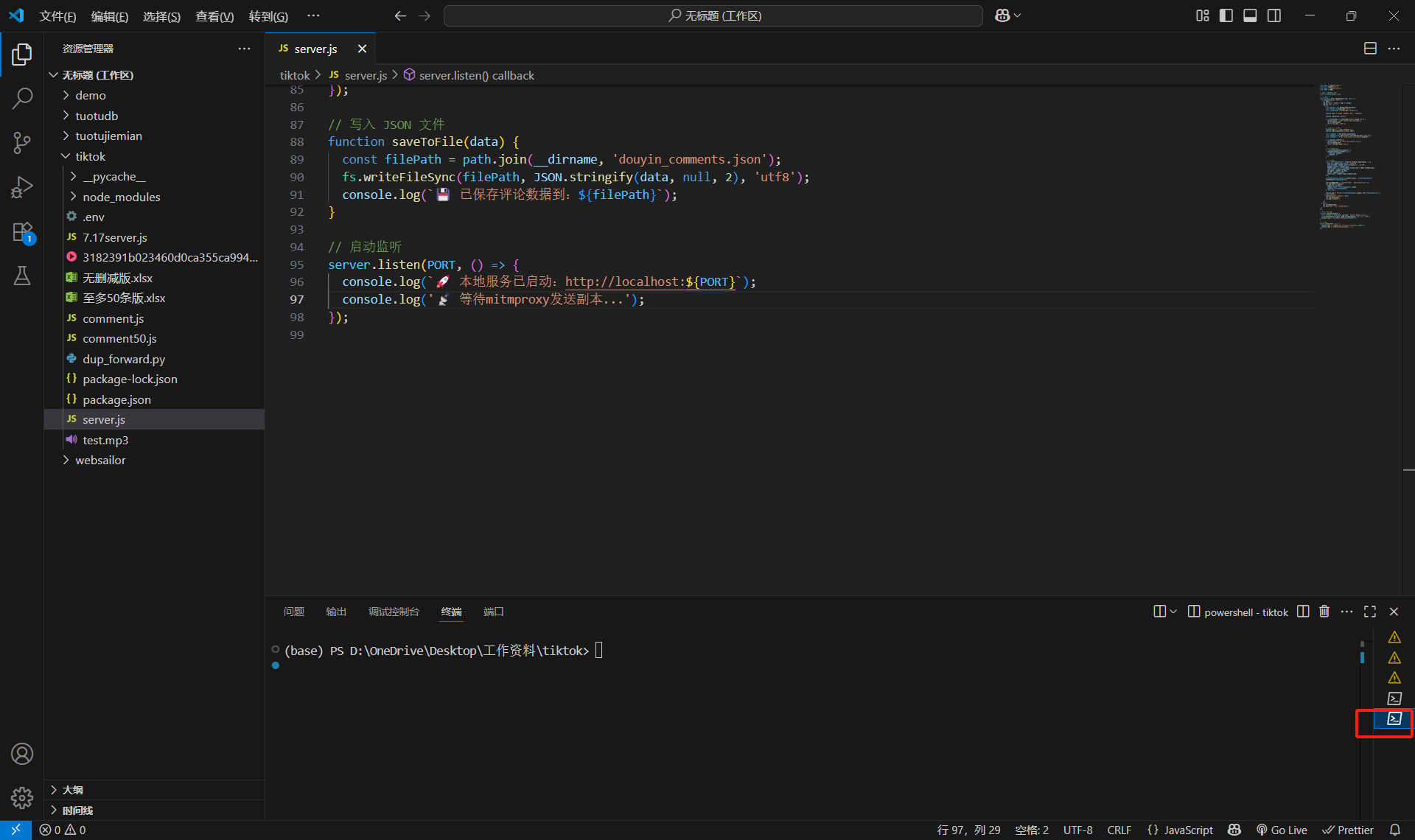
然后终端输入mitmproxy -s dup_forward.py,点击空格(一定要先下载mitmproxy,不然没用)
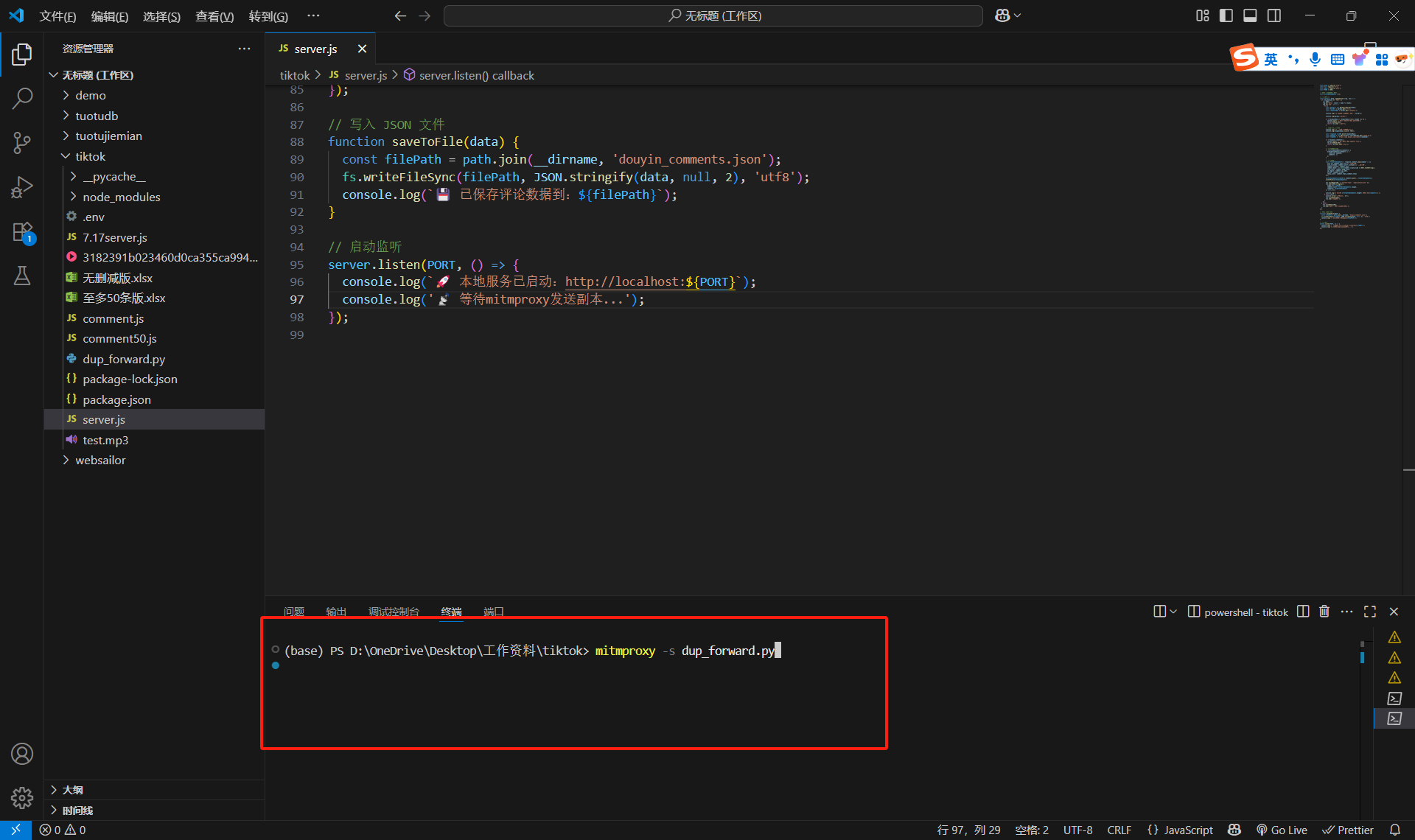 然后出现如下场景,才算成功:
然后出现如下场景,才算成功:
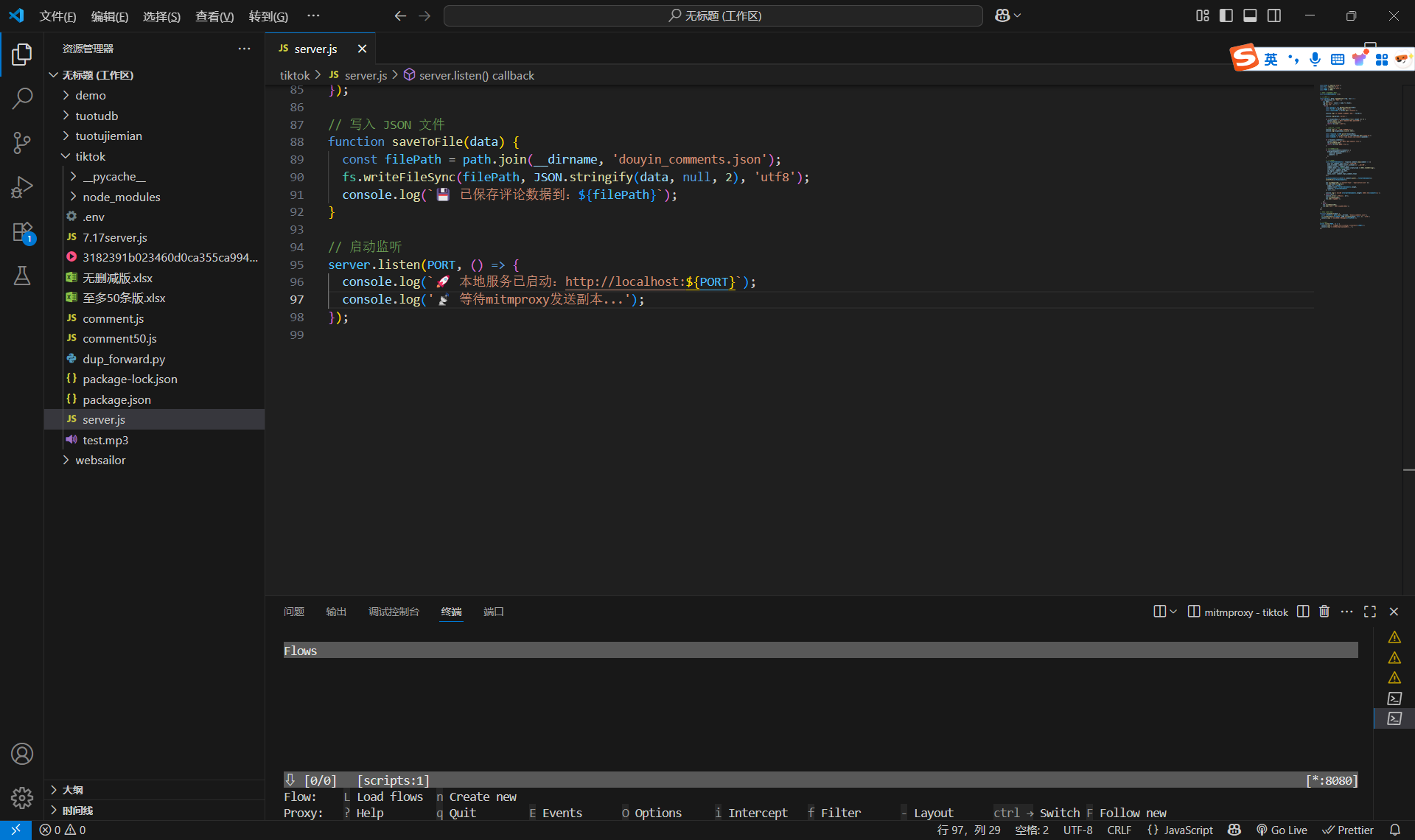 这个时候已经部署好两个服务器了,server.js是处理抓包数据的脚本,dup_forward.py是抓包脚本。
这个时候已经部署好两个服务器了,server.js是处理抓包数据的脚本,dup_forward.py是抓包脚本。
这个时候dup_forward.py监听的是8080端口,我们需要抓包某抖的评论,就需要让浏览器打开链接的时候请求走8080端口代理,这样我们就可以偷偷抓包了。所以下一步修改代理:
博主是windows11,如果是其他电脑可以问问deepseek怎么切换代理的端口(此操作有风险,可以提前看一下下面的注意事项)
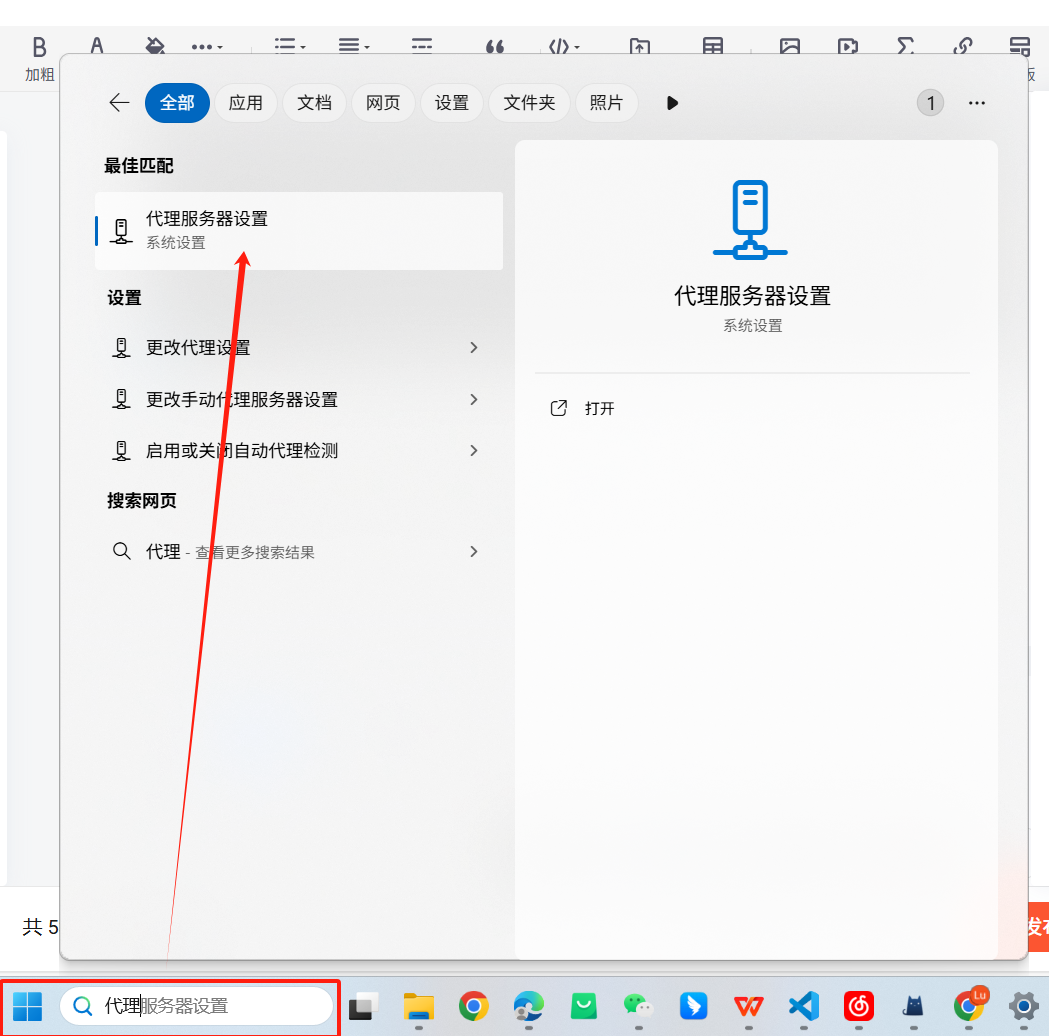
点击编辑:
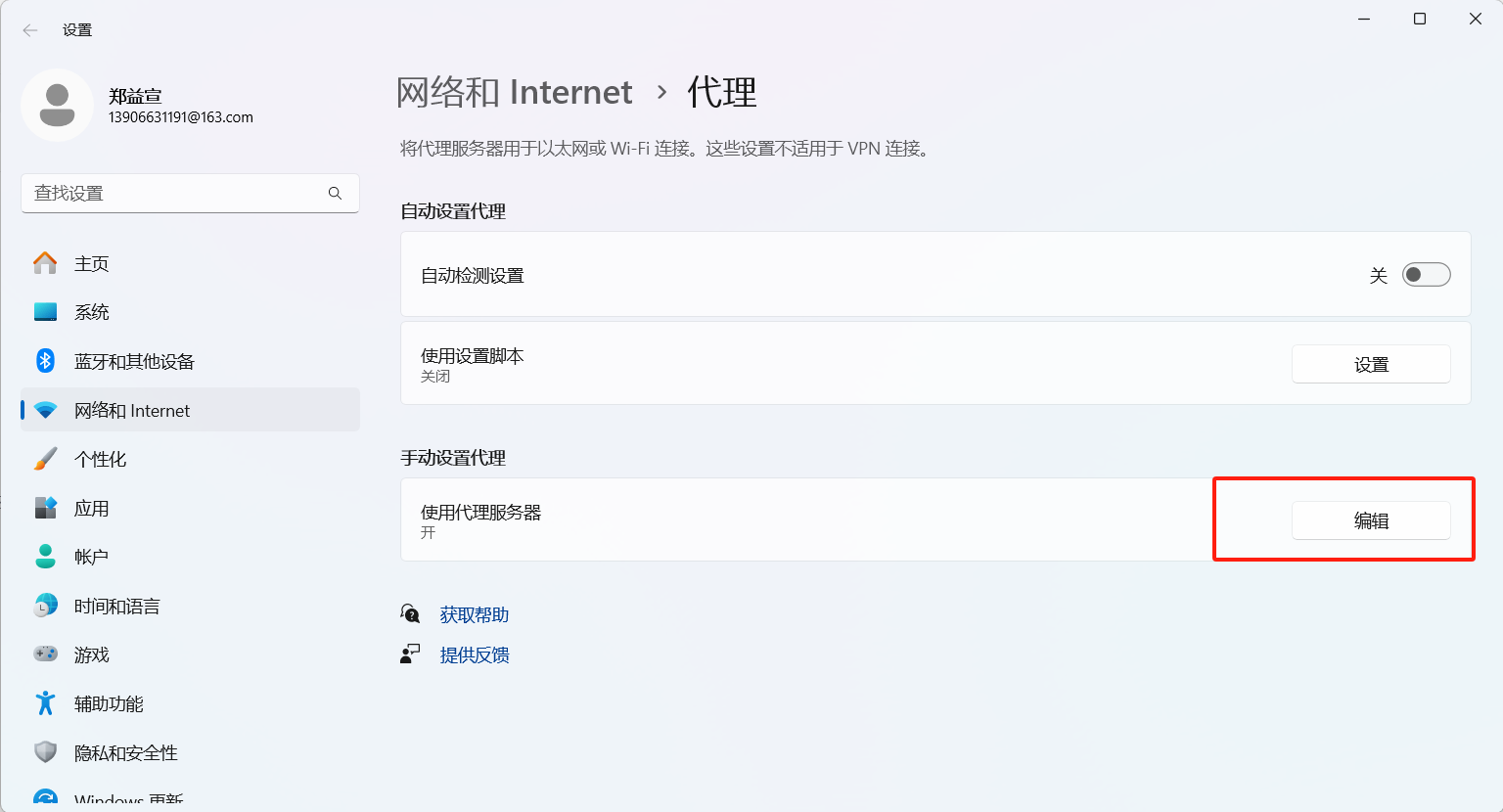
然后使用墙的小伙伴们注意了
我这里改了代理,如果你们使用墙有可能后面会出错,因为你们墙也是一个代理,他监听的端口和我们这里用mitmproxy的端口不一样,所以用完后一定要修改代理配置回来,如下图是博主一打开时候的样子,到时候弄完得改回去!:
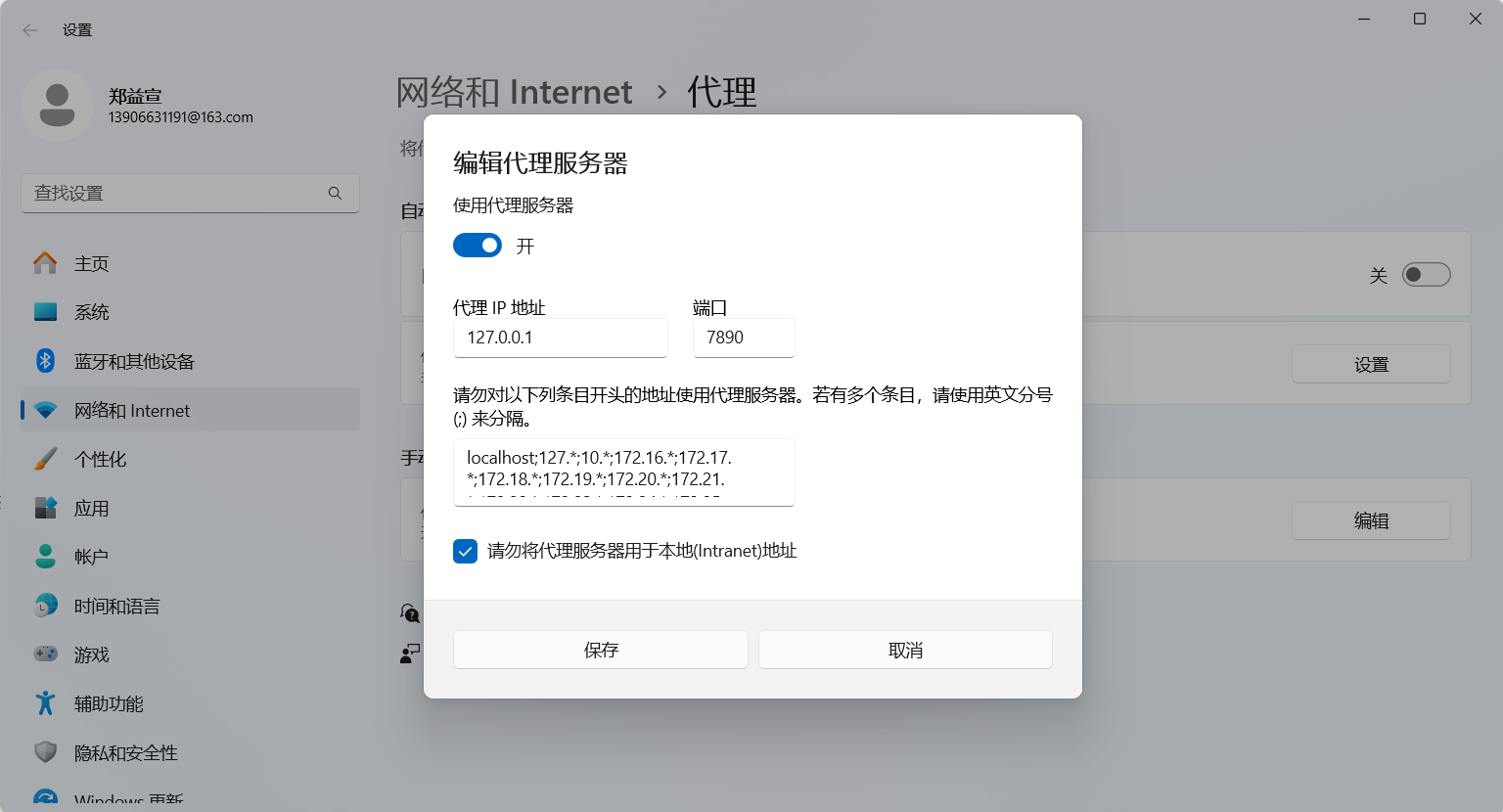
接下来是需要操作的,打开使用代理服务器,需要改端口为8080并保存(此操作前需要读一下后面的注意点,即"没用墙的小伙伴们注意了,这个非常重要,是全场最重要的一点",因为这个操作处理不好可能让浏览器访问不了网页的):
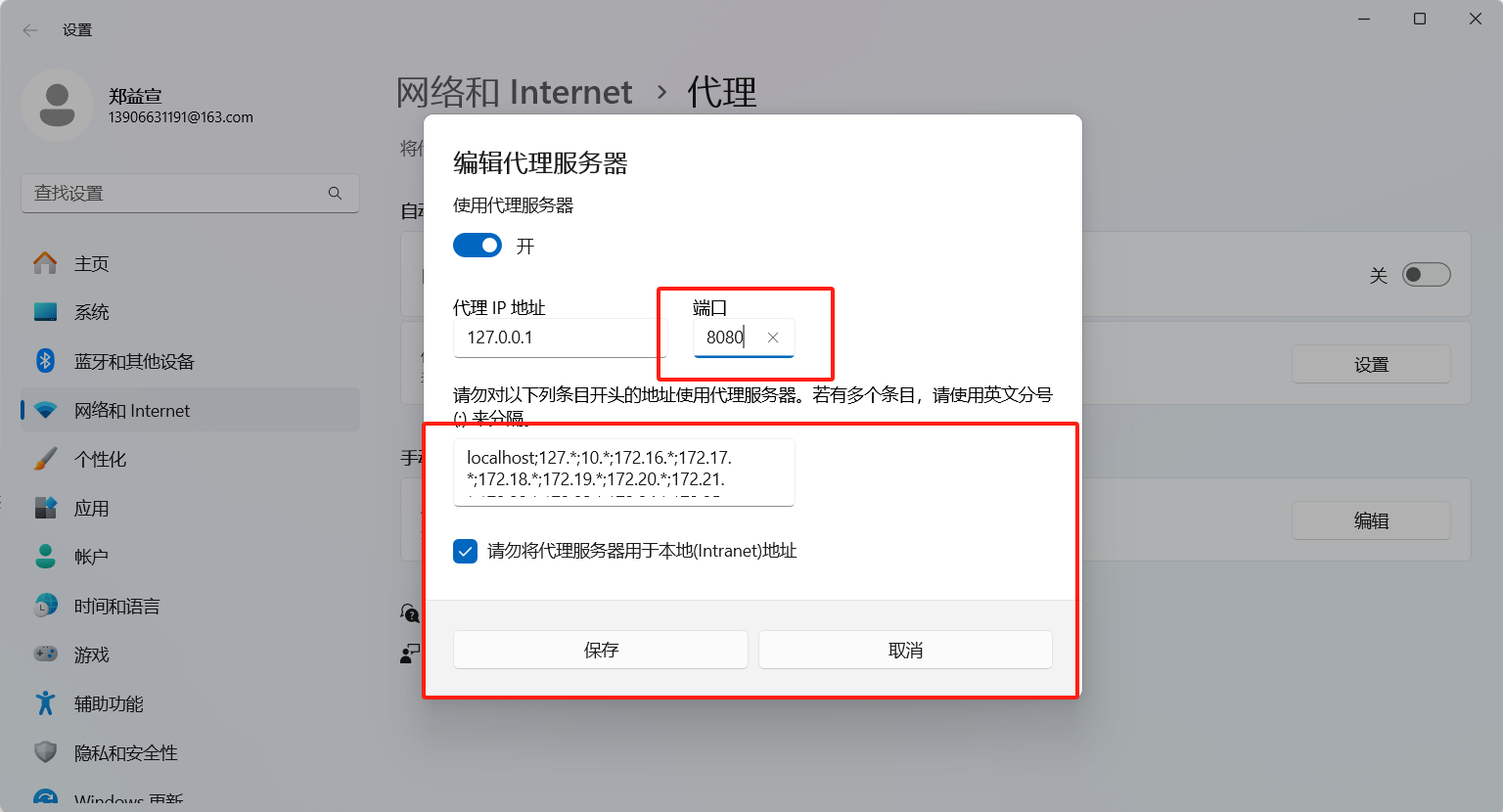
然后没用墙的小伙伴们注意了,这个非常重要,是全场最重要的一点!!请认真观看
因为你们一上来是没有开代理服务器的,点击了开代理服务器就意味着你们后面浏览器的请求要通过8080发送,8080是我们自己的服务器,如果你后面关掉了我们自己的8080服务器(即mitmproxy -s dup_forward.py)那个,那么你打开浏览器新页面将会看到如下场景"你尚未链接,代理服务器可能有问题"。

看起来像是你没网了一样,所以,如果你打开了代理服务器,再没有关闭这个代理服务器之前,你的浏览器是没法访问其他网站的,除非你按照我前面的操作部署了8080服务器(即mitmproxy -s dup_forward.py)
如果你临时想退出!或者临时想访问其他网页!!或者干脆就不想干了,你需要做的仅仅只是打开刚刚开代理的页面,然后把使用代理服务器关掉,一切就正常了。
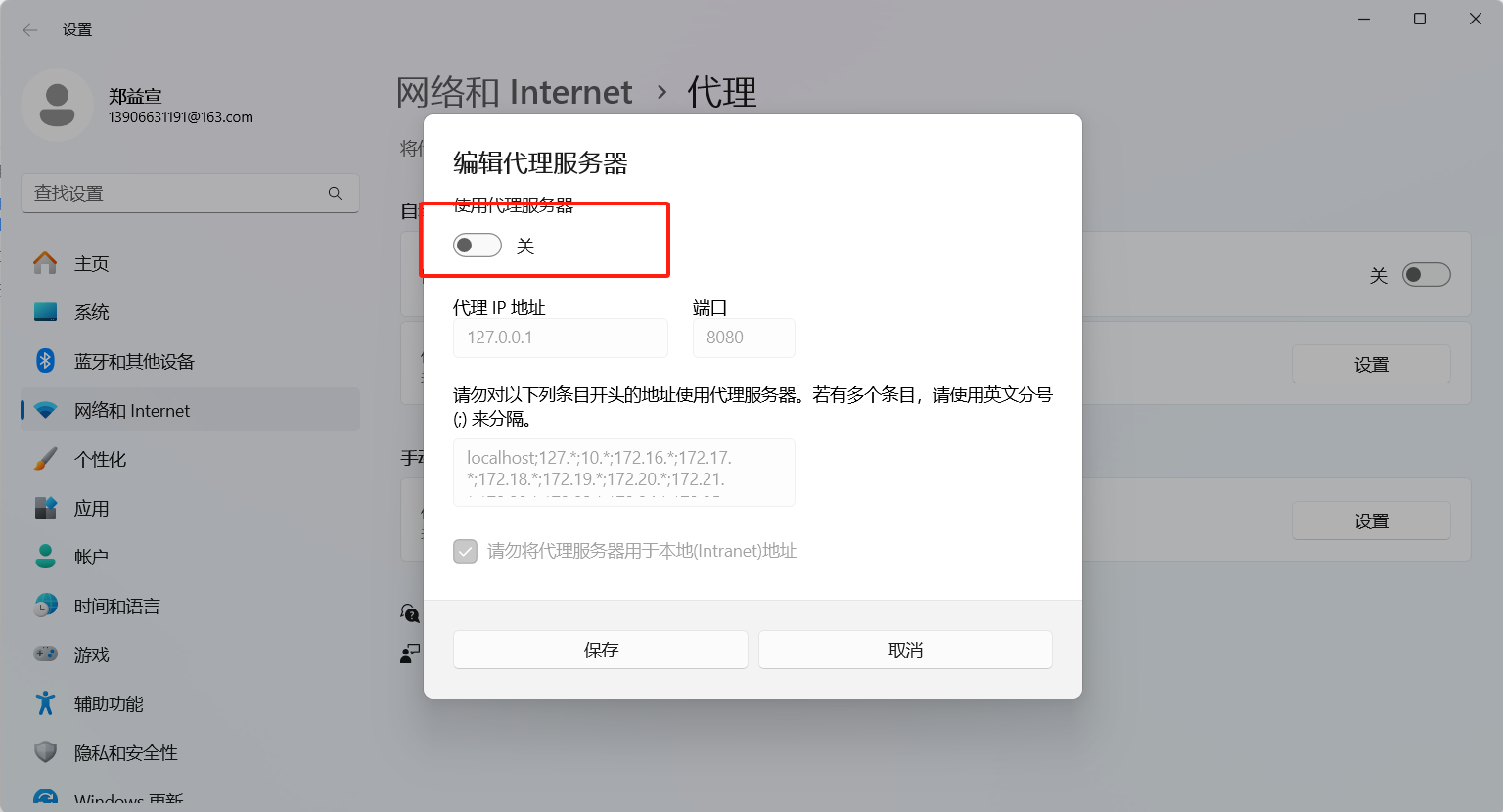
我需要再次强调的是:
我们用mitmproxy开的服务器是自己的服务器去监听8080端口。打开代理的8080端口,浏览器走会先走我们自己的mitmproxy服务器。如果我们服务器开启着,那一切都正常,因为我们服务器会转发请求,因此可以爬。
如果你不小心关掉了我们自己的服务器,那么请把"使用代理服务器"关掉,因为会"显示您尚未连接的",但如果你真的有需求还需要继续往下爬,那你可以终端输入" mitmproxy -s dup_forward.py**",浏览器走自己服务器转发,后面爬操作畅通无阻。**
这时候全部已经部署完成,然后可以开始爬了。
然后随便打开一个视频,然后往下滑动评论区,评论区加载多少,后台就能爬多少。
 爬多少取决于你往下加载的评论区多少,见同目录下的douyin_comments.json
爬多少取决于你往下加载的评论区多少,见同目录下的douyin_comments.json
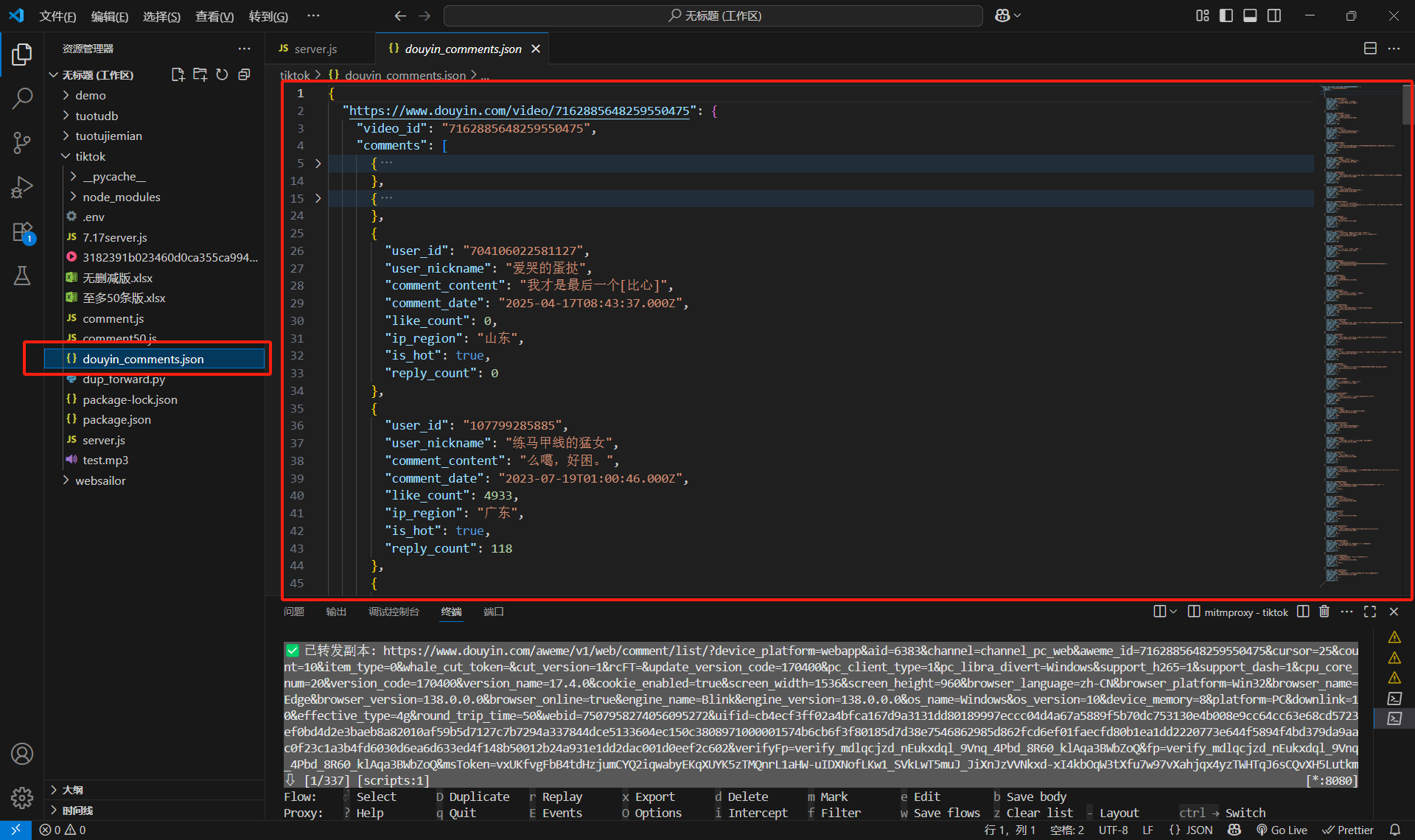 如果需要换下一个视频就直接打开一个新的链接就行,脚本会按网页自动分类的
如果需要换下一个视频就直接打开一个新的链接就行,脚本会按网页自动分类的
 然后这个时候数据还是json文件嘛,json文件不是那种xlsx看的不太爽(此时已经可以ai分析了)
然后这个时候数据还是json文件嘛,json文件不是那种xlsx看的不太爽(此时已经可以ai分析了)
如果需要转成xlsx那么前面有一个comment.js(所有都转xlsx)以及comment50.js(前50条转xlsx)
就派上用场了:新开一个终端,然后输入node comment.js或者node comment50.js

然后douyin_comments.xlsx就是了。
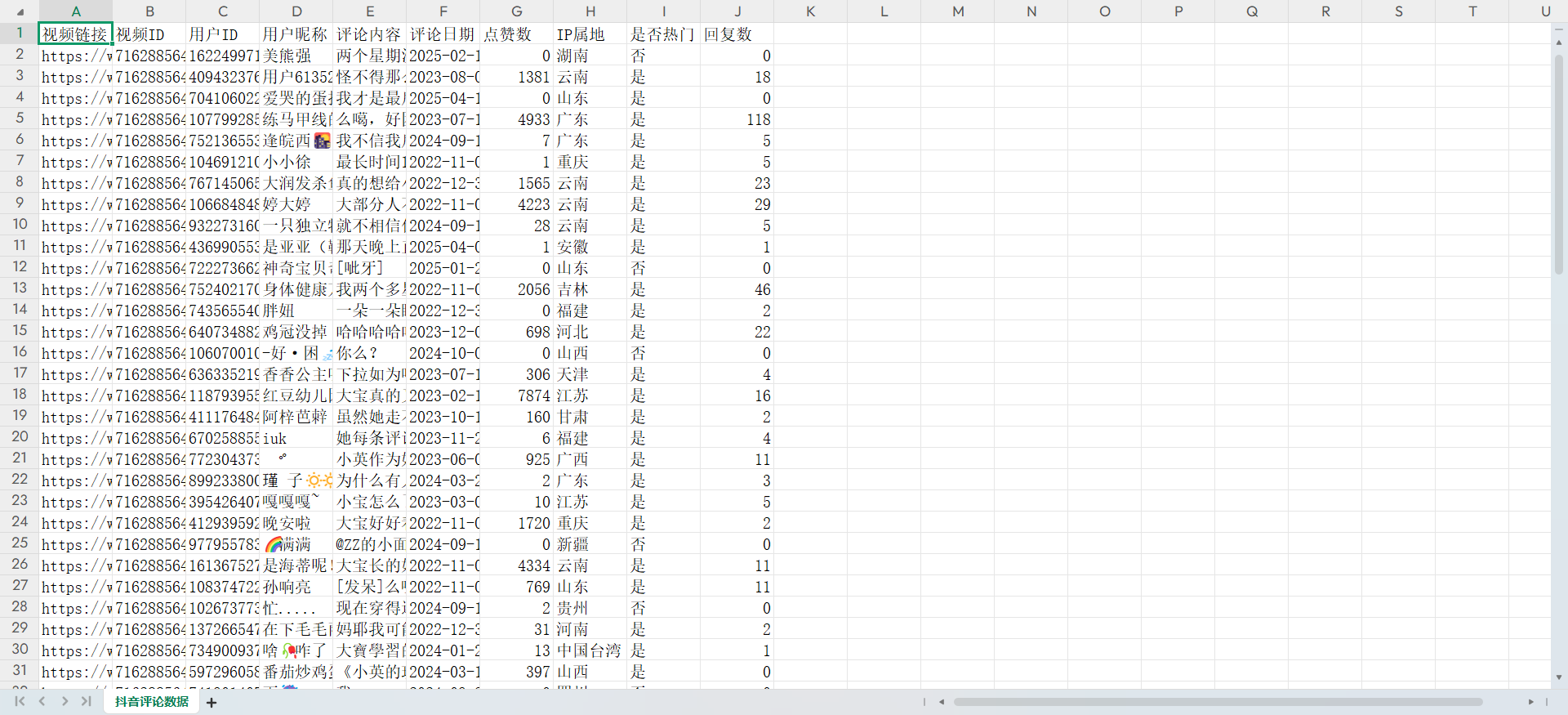
第二天爬的看:
然后由于大家肯定不是一次性一天全部爬完,终端一旦关闭,所有的缓存都删除,但是douyin_comments.json和douyin_comments.xlsx不会删除!!虽然不会删除,但是如果你第二天发现我还得爬,请你记住给原来的名字改掉,不然脚本又自动替换 掉原来的douyin_comments.json和douyin_comments.xlsx了!
douyin_comments.json这个文件如果你第二天一运行node server.js直接就全部清空了。
想重新开启服务器来的看:
如果你发现vscode调试的时候乱七八糟的,想重新服务器关掉重新开。
那么你可以切换到那个server.js的那个终端,然后按一下ctrl+c,就可以退出了,然后可以重新执行node server.js (此操作会清空douyin_comment.json啊别乱重启,如果真需要重启又要保留原来的json,请你把原来douyin_comment.json和douyin_comment.xlsx改个名呗)
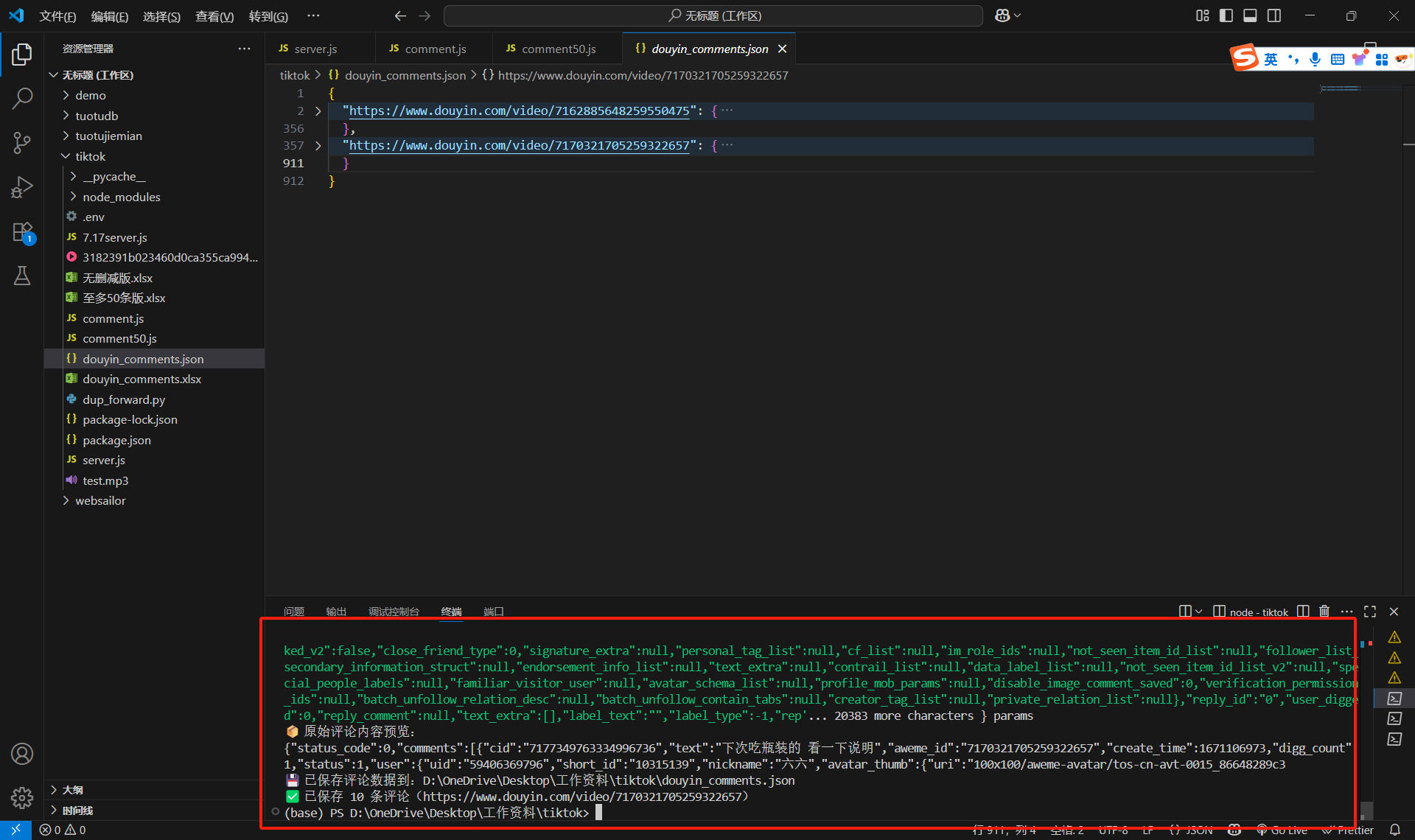
另一个服务器也是一样:先切换到dup_forward.py的那个终端,然后ctrl+c,然后最下面输入yes
重启的时候再执行mitmproxy -s dup_forward.py就行了
然后就可以重新爬取了,记住重启要改名啊!!!不然原来白白爬了。