在当今数据驱动的时代,实时数据处理能力已成为企业竞争力的关键因素。Apache Kafka作为实时数据流处理的领导者,凭借其高吞吐量、低延迟和强大的扩展性,成为众多企业的首选解决方案。本文将深入解析Kafka的核心概念,并提供详细的实战指南,帮助您快速构建自己的实时数据流处理系统。
一、Apache Kafka:实时数据流的强大引擎
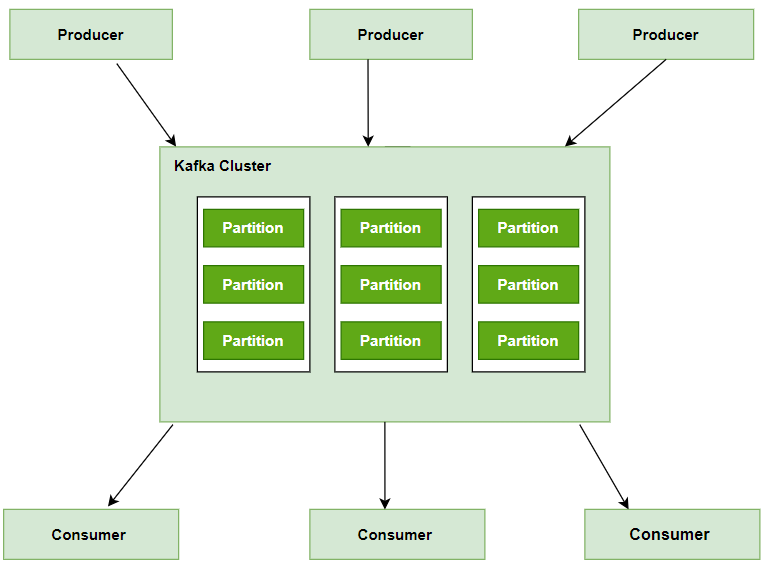
Apache Kafka是由Apache软件基金会开发的开源流处理平台,采用Scala和Java语言编写。其核心设计目标是提供一个统一、高吞吐量、低延迟的平台来处理实时数据流。Kafka采用发布-订阅模型,能够从多个数据源捕获数据,并将其高效地传递给相应的消费者。
Kafka的核心优势:
- 卓越的可扩展性:分布式架构设计,支持无缝扩展而无需停机
- 出色的性能表现:高吞吐量的发布/订阅操作,即使存储数TB消息也能保持稳定性能
- 强大的数据持久性:采用有序、容错的分布式提交日志,确保消息快速写入磁盘而不影响性能
- 便捷的集成能力:通过Kafka Connect实现数据导入/导出,Kafka Streams提供流处理库
二、实时数据流处理:数字化转型的关键
实时数据流处理是指在数据产生的瞬间进行捕获、处理和分析的过程。与传统的批处理模式(先收集存储再处理)不同,实时流处理能够在数据产生的毫秒级甚至秒级内完成处理。
实时数据流处理的核心价值:
- 即时决策支持:实时数据分析使企业能够快速做出业务决策
- 极致用户体验:即时数据处理支持个性化用户体验的实时生成
- 运营效率提升:自动化响应关键业务事件,减少人工干预和错误
- 风险实时管控:快速识别和缓解潜在风险

三、Kafka实时数据流处理实战指南
1. 环境准备与集群搭建
假设您使用的是Unix-like系统(Linux/MacOS),且已下载并解压Kafka:
# 解压Kafka
tar -xzf kafka_2.13-2.8.0.tgz
cd kafka_2.13-2.8.02. 启动Kafka服务
首先启动Zookeeper( Kafka依赖的服务),然后在新的终端窗口启动Kafka服务器:
# 启动Zookeeper
./bin/zookeeper-server-start.sh config/zookeeper.properties
# 在新终端启动Kafka服务器
./bin/kafka-server-start.sh config/server.properties3. 创建主题(Topic)
主题是Kafka中消息的分类单位:
# 创建主题(替换your_topic_name为您的主题名称)
./bin/kafka-topics.sh --create --topic your_topic_name --bootstrap-server localhost:9092 --replication-factor 1 --partitions 14. 数据生产与消费
生产数据(发送消息到主题):
# 启动生产者控制台
./bin/kafka-console-producer.sh --topic your_topic_name --bootstrap-server localhost:9092运行后,您可以在控制台直接输入消息发送到主题。
消费数据(从主题读取消息):
# 启动消费者控制台(从开始位置读取)
./bin/kafka-console-consumer.sh --topic your_topic_name --from-beginning --bootstrap-server localhost:90925. 监控与管理
# 列出所有主题
./bin/kafka-topics.sh --list --bootstrap-server localhost:9092
# 描述特定主题详情
./bin/kafka-topics.sh --describe --topic your_topic_name --bootstrap-server localhost:9092四、实战案例:电商用户行为实时分析
以电商网站为例,展示Kafka如何实现用户行为实时分析:
- 用户行为追踪:使用Kafka生产者发送用户活动数据到"user_activity"主题
- 实时处理:订阅"user_activity"主题的消费者实时处理所有事件
- 个性化推荐:基于实时分析结果生成个性化产品推荐
五、Kafka部署最佳实践
- 容量规划:根据消息吞吐量、保留策略和存储需求规划集群容量
- 高可用配置:跨可用区/数据中心部署多个broker,实现自动故障转移和复制
- 主题优化设计:合理设计分区、复制因子和保留策略
- 全面监控:实施监控和告警系统,跟踪集群健康状况
- 安全加固:采用加密、认证和授权机制保障数据安全
六、结语
Apache Kafka为实时数据流处理提供了革命性的解决方案,其可扩展性、容错性和高性能使其成为构建现代数据架构的理想选择。通过遵循本文提供的指南和最佳实践,企业可以充分利用Kafka构建弹性分析管道、部署事件驱动的微服务,并在各个行业推动创新。