引言
在Kafka的消费者组机制中,重平衡(Rebalance)是一个核心且复杂的过程。它负责在消费者组发生变化时,重新分配分区与消费者之间的对应关系,确保每个分区仅被组内一个消费者消费。想象一个场景:某电商平台的消费者组原本由3个消费者组成,共同处理10个分区的订单消息。当其中一个消费者因故障下线后,重平衡机制会自动将该消费者负责的分区分配给剩余的两个消费者,保证消息消费不中断。
重平衡的设计初衷是实现消费能力的动态均衡,但过程中会导致消费者短暂停止消费(类似JVM的"Stop The World"),因此理解其全流程对优化Kafka性能至关重要。本文将从触发条件、通知机制、状态流转、消费者与Broker端交互等维度,全面解析重平衡的底层逻辑,并结合生产实践提供优化建议。
重平衡的触发条件:何时需要重新分配?
重平衡并非随时发生,它仅在特定条件被满足时触发。了解这些条件是理解重平衡的基础,也是生产中避免不必要重平衡的关键。
三大触发条件
Kafka定义了三类触发重平衡的场景,其中组成员变化最为常见:
-
组成员数量变化 这是最频繁的触发因素,包括消费者实例的启动、正常退出(调用
close()方法)或异常崩溃。例如,消费者组启动时,首个消费者加入会触发重平衡;运行中某个消费者因网络故障下线,也会触发重平衡。 -
订阅主题数量变化 当消费者通过正则表达式(如
Pattern.compile("order-.*"))订阅主题时,若新增符合表达式的主题(如order-refund),消费者组会感知到订阅列表变化,从而触发重平衡。 -
订阅主题的分区数变化 主题分区数扩容(如从5个分区增加到10个)后,消费者组需要重新分配这些新分区,因此会触发重平衡。
生产环境中的常见触发场景
-
消费者重启:部署新版本时,逐个重启消费者实例会多次触发重平衡。
-
资源不足:消费者因GC停顿、CPU过载等无法及时发送心跳,被协调者判定为"死亡",引发重平衡。
-
主题扩容:为提升吞吐量增加分区数,会触发一次重平衡。
注意:频繁的重平衡会导致消费停顿,影响下游业务。例如,某支付系统因网络波动导致消费者频繁下线,每小时触发数十次重平衡,造成交易消息处理延迟达分钟级。
重平衡的通知机制:心跳线程的"秘密任务"
重平衡的触发并非悄无声息,协调者(Coordinator)需要将"重平衡开始"的信号传递给所有存活的消费者,这一过程依赖于消费者的心跳机制。
心跳线程:从主线程到独立线程的演进
在Kafka 0.10.1.0版本之前,心跳请求由消费者主线程(调用poll()方法的线程)发送。这种设计存在严重缺陷:若消息处理耗时过长(如超过session.timeout.ms),主线程会阻塞,导致心跳无法发送,协调者误判消费者"死亡"并触发重平衡。
0.10.1.0版本引入独立心跳线程,专门负责发送心跳请求,解决了主线程阻塞的问题。心跳线程与主线程并行工作,即使消息处理耗时较长,心跳仍能正常发送,避免不必要的重平衡。
重平衡的通知信号:REBALANCE_IN_PROGRESS
协调者决定开启重平衡后,会在心跳响应中嵌入REBALANCE_IN_PROGRESS标志。消费者的心跳线程收到该标志后,会通知主线程:重平衡已启动,需要暂停消费并参与重平衡。
这一机制确保所有存活的消费者能快速感知重平衡,例如:
-
协调者触发重平衡后,在给消费者A的心跳响应中加入
REBALANCE_IN_PROGRESS。 -
消费者A的心跳线程解析响应后,通知主线程停止消费。
-
消费者A进入重平衡流程,发送
JoinGroup请求。
关键参数:heartbeat.interval.ms的双重意义
heartbeat.interval.ms(默认3秒)表面上是心跳发送间隔,实则控制重平衡的通知速度:
-
较小的值(如1秒):消费者能更快收到重平衡通知,缩短响应时间。
-
较大的值(如10秒):减少网络开销,但重平衡通知延迟增加。
建议:根据业务对延迟的敏感度调整,核心业务可设为1-2秒,非核心业务设为5-10秒。
消费者组状态机:重平衡的"指挥系统"
协调者通过一套状态机管理消费者组的生命周期,确保重平衡有序进行。这套状态机包含5种状态,状态间的流转反映了重平衡的不同阶段。
五种状态的含义与流转
| 状态名称 | 含义 | 典型触发场景 |
|---|---|---|
| Empty | 组内没有任何成员,但消费者组可能存在已提交的位移数据,而且这些位移尚未过期。 | 所有成员退出后,位移未过期 |
| Dead | 同样是组内没有任何成员,但组的元数据信息已经在协调者端被移除。协调者组件保存着当前向它注册过的所有组信息,所谓的元数据信息就类似于这个注册信息。 | Empty状态超时(默认7天),位移数据被清理 |
| PreparingRebalance | 消费者组准备开启重平衡,此时所有成员都要重新请求加入消费者组。 | 新成员加入、现有成员退出 |
| CompletingRebalance | 消费者组下所有成员已经加入,各个成员正在等待分配方案。该状态在老一点的版本中被称为AwaitingSync,它和CompletingRebalance是等价的。 | 所有成员发送JoinGroup请求后 |
| Stable | 消费者组的稳定状态。该状态表明重平衡已经完成,组内各成员能够正常消费数据了。 | 分配方案通过SyncGroup请求下发后 |
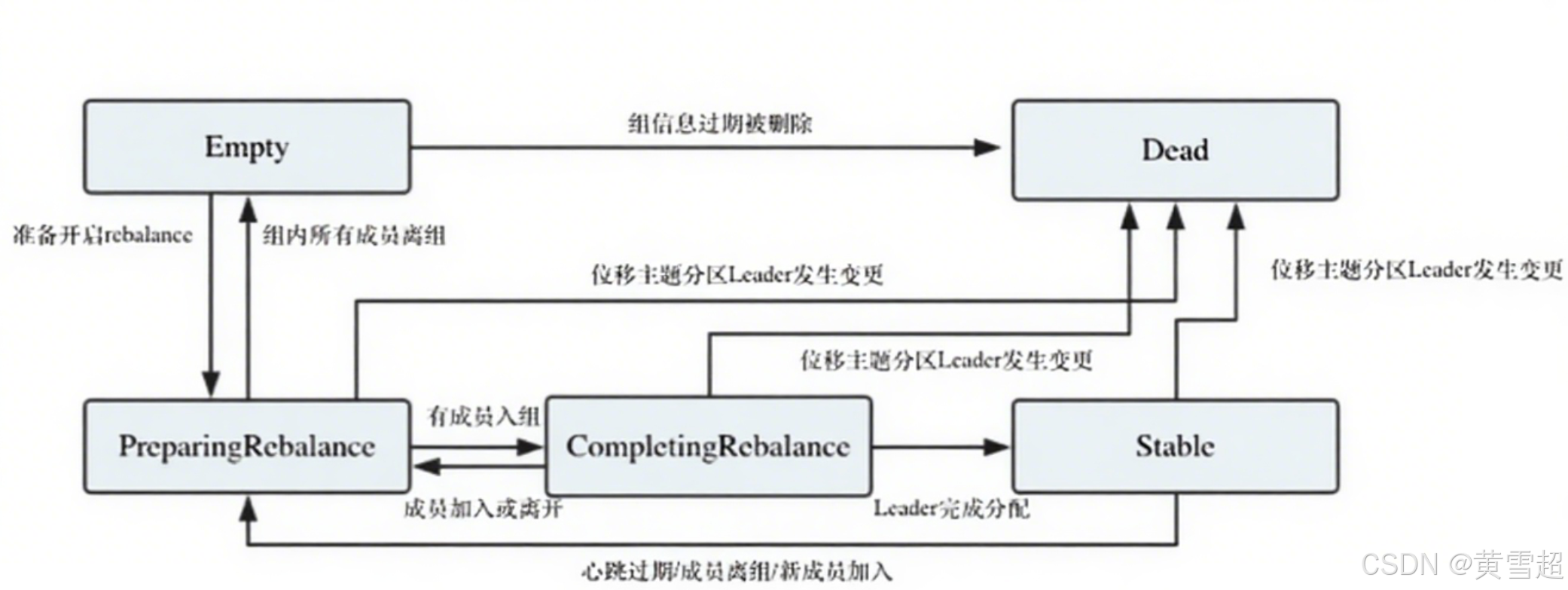
状态流转的核心逻辑
-
Empty到Dead的转换 :Empty状态持续时间超过
offsets.retention.minutes(默认7天),协调者会删除该组的元数据和位移数据,状态转为Dead。这就是为何长期停止的消费者组重启后,可能需要从头消费(位移已被删除)。 -
Stable到PreparingRebalance的转换:任何触发重平衡的条件满足时,协调者会立即将组状态转为PreparingRebalance,强制所有成员重新加入。
状态监控的实践意义
通过监控消费者组状态,可提前发现异常:
-
频繁在
PreparingRebalance和CompletingRebalance间切换,表明重平衡频繁触发,可能是网络不稳定或成员故障导致。 -
长期处于
Empty状态,需检查是否所有消费者已退出,或位移数据是否即将过期。
消费者端重平衡流程:从加入组到接收分配方案
消费者参与重平衡的过程可分为两个关键步骤,分别通过JoinGroup和SyncGroup请求完成。
第一步:加入组(JoinGroup请求)
JoinGroup请求的核心目的是让协调者收集所有成员的订阅信息,并选举领导者消费者。
-
发送JoinGroup请求 : 消费者收到重平衡通知后,向协调者发送
JoinGroup请求,包含自身订阅的主题列表(如["order-topic"])。 -
协调者收集请求 : 协调者等待所有成员发送
JoinGroup请求(等待时间由group.initial.rebalance.delay.ms控制,默认3秒),收集全组的订阅信息。 -
选举领导者消费者 : 协调者指定第一个发送
JoinGroup请求的成员作为领导者(Leader Consumer)。领导者的职责是基于订阅信息制定分区分配方案。 -
返回JoinGroup响应 : 协调者向领导者返回全组订阅信息,向其他成员返回领导者身份,状态从
PreparingRebalance转为CompletingRebalance。
示例 : 成员1和成员2加入组,成员1先发送JoinGroup请求成为领导者。协调者向成员1返回{成员1: ["topicA"], 成员2: ["topicA"]},向成员2返回{leader: 成员1}。
第二步:同步分配方案(SyncGroup请求)
领导者制定分配方案后,通过SyncGroup请求将方案同步给所有成员。
-
领导者发送分配方案 : 领导者基于订阅信息和分配策略(如
RangeAssignor)制定方案(如{成员1: [分区0,1], 成员2: [分区2,3]}),并通过SyncGroup请求发送给协调者。 -
其他成员发送空请求 : 非领导者成员也发送
SyncGroup请求(请求体为空),目的是接收协调者下发的分配方案。 -
协调者分发方案 : 协调者接收领导者的方案后,将其封装到
SyncGroup响应中,分发给所有成员。成员收到方案后,状态转为Stable,开始消费分配到的分区。
示例 : 领导者(成员1)制定方案后,协调者通过SyncGroup响应告知成员1负责分区0、1,成员2负责分区2、3。
分配策略的影响
领导者制定分配方案时,会依据消费者配置的partition.assignment.strategy(默认RangeAssignor):
-
RangeAssignor:按主题分区序号范围分配(如成员1分分区0-1,成员2分分区2-3)。 -
RoundRobinAssignor:轮询分配分区(如成员1分0、2,成员2分1、3)。 -
StickyAssignor:尽量保留现有分配,仅调整必要的分区(减少重平衡的影响)。
选择合适的分配策略可减少分区迁移,例如StickyAssignor能在重平衡时最大限度保留原有分配,降低消费停顿时间。
Broker端重平衡流程:协调者的四大场景处理
协调者是重平衡的"指挥中心",负责在不同场景下触发、管理重平衡。以下解析四种典型场景的处理逻辑。
场景一:新成员入组
当组处于Stable状态时,新成员加入会触发重平衡,流程如下:
-
新成员发送JoinGroup请求 :新消费者启动后,向协调者发送
JoinGroup请求,表明希望加入组。 -
协调者通知现有成员 :协调者收到请求后,向所有存活成员的心跳响应中加入
REBALANCE_IN_PROGRESS,强制它们进入重平衡。 -
现有成员重新加入 :现有成员收到通知后,停止消费,发送
JoinGroup请求。 -
协调者收集请求并选举领导者 :协调者等待所有成员(包括新成员)发送
JoinGroup请求,选举领导者。 -
制定并分发分配方案 :领导者制定方案后,通过
SyncGroup请求同步给所有成员,组状态恢复Stable。
时序图解析 : 新成员发送JoinGroup后,协调者立即通过心跳响应通知成员1开启重平衡。成员1重新发送JoinGroup,最终协调者将新分配方案通过SyncGroup响应下发。
场景二:组成员主动离组
消费者调用close()方法主动退出时,流程如下:
-
发送LeaveGroup请求 :消费者在关闭前,向协调者发送
LeaveGroup请求,表明要退出组。 -
协调者标记成员离线:协调者立即将该成员标记为"离组",并触发重平衡。
-
通知其他成员:协调者通过心跳响应告知其他成员开启重平衡。
-
执行重平衡流程:后续步骤与新成员入组类似,现有成员重新加入,制定新分配方案。
优势 :主动离组能让协调者快速感知变化,减少重平衡的等待时间(无需等待session.timeout.ms)。
场景三:组成员崩溃离组
消费者因故障(如进程崩溃、网络中断)突然下线,协调者需通过超时机制检测:
-
心跳超时检测 :协调者记录每个成员的最后心跳时间,若超过
session.timeout.ms(默认10秒)未收到心跳,判定该成员"死亡"。 -
触发重平衡 :协调者将组状态转为
PreparingRebalance,并通知其他成员。 -
重新分配分区:剩余成员重新加入组,领导者制定新方案,排除已崩溃的成员。
关键参数 :session.timeout.ms控制检测崩溃的最长时间,建议设置为heartbeat.interval.ms的3-5倍(如心跳3秒,超时10秒)。
场景四:重平衡时的位移提交处理
重平衡前,协调者会给予成员一段缓冲时间提交位移,避免已消费消息因重平衡被重复处理:
-
协调者发送重平衡通知 :成员收到
REBALANCE_IN_PROGRESS后,需在max.poll.interval.ms(默认5分钟)内提交当前位移。 -
成员提交位移 :消费者调用
commitSync()或commitAsync()提交位移,确保协调者记录最新消费进度。 -
协调者处理位移:协调者接收位移后,在重平衡完成后,新分配分区的消费者会从已提交的位移开始消费。
示例:成员1在重平衡前提交位移至1000,重平衡后该分区分配给成员2,成员2会从1001开始消费,避免重复处理。
重平衡的性能影响与优化策略
重平衡期间,所有消费者会暂停消费(通常持续几秒到几分钟),导致消息积压。优化重平衡的核心是减少频率和缩短持续时间。
重平衡的性能瓶颈
-
消费停顿:重平衡期间,消费者无法拉取消息,导致下游系统数据延迟。
-
资源消耗:频繁重平衡会增加Broker的CPU和网络开销,尤其是在大集群中。
-
重复消费:若重平衡前位移未提交,新分配分区的消费者会从上次提交的位移开始,导致中间消息被重复处理。
优化策略:从参数到架构
-
合理配置参数
-
heartbeat.interval.ms:设为1-2秒,加快重平衡通知。 -
session.timeout.ms:设为10-30秒,平衡故障检测速度和稳定性。 -
max.poll.interval.ms:根据消息处理耗时调整,避免因处理过慢触发重平衡。 -
group.initial.rebalance.delay.ms:首次重平衡延迟(默认3秒),若启动多个消费者,可设为5-10秒,减少启动时的重平衡次数。
-
-
减少不必要的重平衡
-
避免消费者频繁重启:采用滚动更新时,确保前一个实例完全关闭后再启动新实例。
-
优化消费者稳定性:减少GC停顿(如使用G1GC)、避免CPU/内存过载,防止被判定为"死亡"。
-
避免动态调整主题:如需扩容分区,选择业务低峰期进行,并提前通知下游。
-
-
采用增量重平衡(实验性) Kafka 2.4+引入增量重平衡(Incremental Rebalance),允许部分消费者继续消费,仅调整受影响的分区。该特性通过
enable.incremental.rebalance启用,适合大集群减少停顿时间。 -
监控与告警
-
监控
rebalance_latency_avg(重平衡平均耗时)和rebalance_rate(重平衡频率)。 -
当重平衡耗时超过5秒或频率超过每小时1次时,触发告警排查原因。
-
总结
重平衡是Kafka消费者组实现动态负载均衡的关键机制,其设计体现了分布式系统中一致性与可用性的平衡。通过本文的解析,我们可得出以下核心结论:
-
重平衡的本质:通过协调者与消费者的交互,在组状态变化时重新分配分区,确保消费的均衡性。
-
关键流程:触发条件→通知机制→状态流转→加入组→同步分配方案,每个环节都依赖特定的请求和参数。
-
优化方向:减少重平衡频率(如稳定消费者)、缩短持续时间(如合理配置参数)、采用增量重平衡。
在生产实践中,建议结合监控工具(如Kafka Manager、Prometheus)持续跟踪重平衡指标,通过参数调优和架构优化,将重平衡的影响降至最低,确保Kafka消费链路的稳定性和高效性。
附录:重平衡相关参数速查表
| 参数名称 | 默认值 | 作用描述 | 优化建议 |
|---|---|---|---|
| heartbeat.interval.ms | 3000ms | 心跳发送间隔,影响重平衡通知速度 | 核心业务设为1000-2000ms |
| session.timeout.ms | 10000ms | 会话超时时间,控制崩溃检测延迟 | 设为心跳间隔的3-5倍 |
| max.poll.interval.ms | 300000ms | 两次poll的最大间隔,超时会触发重平衡 | 根据消息处理耗时调整(如60000ms) |
| group.initial.rebalance.delay.ms | 3000ms | 首次重平衡的延迟时间,避免启动时频繁重平衡 | 多实例启动时设为5000-10000ms |
| offsets.retention.minutes | 10080min | Empty状态的超时时间,超时后删除位移数据 | 长期离线的组可设为1440min(1天) |
| partition.assignment.strategy | RangeAssignor | 分区分配策略 | 需减少迁移时用StickyAssignor |