Apache Doris:存算一体MPP分析型数据库的深度技术解析
1. 整体介绍
1.1 概要说明
Apache Doris 是一个由 Apache 软件基金会托管的顶级开源项目。其源代码仓库位于 GitHub: https://github.com/apache/doris。截至分析时点,该项目已获得超过 10,000 个 Star 和 2,900+ 个 Fork,社区活跃度很高,日均提交活跃,反映了其受关注程度和技术迭代速度。
本项目旨在提供一个高性能、易运维的实时分析型数据库。它采用 MPP (Massively Parallel Processing) 架构与 列式存储 ,核心设计目标是:在海量数据背景下,以简化的架构提供低延迟的实时查询与高吞吐的复杂分析能力。
1.2 主要功能与技术特性
Apache Doris 的功能特性紧密围绕其设计目标展开:
- 极简架构:仅包含 Frontend (FE) 和 Backend (BE) 两类进程。FE 负责元数据管理、查询协调与规划;BE 负责数据存储与分布式计算。这种存算一体的设计(尽管可独立扩缩容)极大地简化了部署与运维复杂度。
- 高性能查询:通过列式存储、向量化执行引擎、预聚合(Aggregate Key 模型)及丰富的索引(前缀索引、Bloom Filter、倒排索引等)实现。其 Pipeline 执行模型能有效利用多核并避免线程膨胀。
- 高兼容性与易用性:完全兼容 MySQL 网络协议与大部分语法,用户可直接使用 MySQL 客户端、各类 BI 工具(如 Tableau, Superset)进行连接,学习与迁移成本低。
- 实时与批量数据接入:支持通过 Stream Load(HTTP)、Routine Load(Kafka)、Broker Load(HDFS/S3)以及 Flink/Spark Connector 等多种方式导入数据,满足流批一体需求。
- 联邦查询 :支持通过
Multi-Catalog功能直接查询外部数据源,如 Apache Hive, Iceberg, Hudi 以及 MySQL、Elasticsearch 等,无需数据迁移即可进行统一分析。
1.3 面临问题与目标场景
在传统大数据分析领域,常面临以下痛点,而 Doris 正致力于解决它们:
| 问题要素 | 传统解决方案的不足 | Apache Doris 的对应场景与解决思路 |
|---|---|---|
| 实时性要求高 | Hive/Spark 批处理延迟高;Kylin 预计算不灵活。 | 实时数仓与报表:支持秒级数据摄入与亚秒级查询,适用于实时监控、实时大屏。 |
| 架构复杂运维难 | Lambda 架构需要维护实时和离线两套系统;存算分离引入网络开销与协调复杂性。 | 统一分析平台:通过存算一体架构和标准的 MySQL 接口,简化技术栈,降低运维成本。 |
| 即席查询响应慢 | 基于 MapReduce 或 Tez 的引擎启动开销大,无法快速响应无预计算的复杂查询。 | 交互式即席查询:基于 MPP 和向量化引擎,快速执行多表关联、复杂聚合等查询。 |
| 高并发点查询 | HBase 等 KV 存储分析能力弱;传统数仓并发能力有限。 | 高并发数据服务:优化单行检索,支持高并发根据主键或索引的点查,可用于用户画像实时查询。 |
| 数据孤岛 | 数据分散在 HDFS、RDBMS、数据湖中,难以统一分析。 | 联邦查询与湖仓加速:通过外部表功能,对数据湖、关系库进行统一 SQL 查询,加速分析过程。 |
对应人群主要为:数据工程师、数据分析师、平台架构师。他们需要在保证数据准确性和系统稳定性的前提下,提升数据分析的时效性、降低系统复杂度和总体拥有成本。
1.4 解决方法演进
以往方式:
- 混合架构:使用"Hadoop (Hive/Spark) + RDBMS (MySQL/Greenplum) + 流计算引擎 (Flink/Storm)"的混合架构,技术栈复杂,数据一致性、时效性、运维难度挑战大。
- 专用系统:使用 ClickHouse 做实时分析,Hive 做离线处理,两者之间数据同步与口径统一困难。
- 云数仓:商业解决方案如 Snowflake、Redshift 等,性能好但成本高昂,且存在供应商锁定风险。
Doris 新方式的优点:
- 架构简化:存算一体(逻辑统一,物理可分离部署),仅两类进程,去除了对 HDFS、ZooKeeper 等外部系统的强依赖,降低了部署和故障排查的复杂度。
- 性价比:作为开源软件,在满足高性能实时分析需求的同时,避免了商业数仓的许可费用。其高效的列式压缩能节省存储成本。
- 生态友好:MySQL 协议兼容性使其无缝融入现有技术生态;支持多种数据源联邦查询,便于向数据湖演进或整合现有系统。
- 开源可控:代码开源,企业可根据自身需求进行定制化开发或深度优化,避免了供应商锁定。
1.5 商业价值预估(逻辑推演)
商业价值可从 成本节约 与 效益提升 两个维度进行估算:
-
成本侧估算逻辑:
- 软件许可成本:相较于同等处理能力的商业 MPP 数仓(如 Teradata, Greenplum 商业版,或云上按需付费的 Snowflake),采用 Doris 可直接节省每年数百万至数千万元的软件许可或服务费用。
- 开发运维成本:简化架构减少了需要维护的组件数量,降低了系统集成、数据同步、故障诊断的复杂性,从而节省了相应的人力与时间成本。粗略估计,可减少约30%-50%与底层平台相关的开发和运维投入。
- 硬件与存储成本:高效的列式压缩(通常可达5-20倍)直接降低了存储硬件开销。向量化执行引擎提升了 CPU 利用率,可能降低同等负载下的计算资源需求。
-
效益侧估算逻辑:
- 决策时效性提升价值:将 T+1 的报表提速到分钟级甚至秒级,能使业务决策(如营销活动调整、风险监控)更快响应市场变化,其带来的业务增长或风险规避价值难以精确量化但至关重要。
- 人力分析效能提升:即席查询响应从分钟级降至秒级,显著提升了数据分析师和数据科学家的探索效率,加速了从数据到洞察的进程。
- 机会成本降低:统一的技术栈避免了多系统间重复开发ETL、数据口径不一致等问题,让团队更专注于业务逻辑而非底层平台差异。
综合估算 :对于一个中型互联网企业,引入 Doris 替换或优化原有混合架构,在 1-2 年 内,通过节省的软硬件采购、云服务费用以及提升的运营效率,其总体拥有成本(TCO)的降低和业务效能的提升,完全有可能覆盖迁移和实施成本,并产生持续的正向收益。
2. 详细功能拆解
从产品与技术融合的视角,Doris 的核心功能可拆解如下:
| 功能模块 | 产品视角(用户价值) | 技术视角(核心设计) |
|---|---|---|
| 数据建模与导入 | 提供多种数据模型(Duplicate/Aggregate/Unique)适应不同场景;提供简单易用的 Web UI 和多种导入方式(HTTP/Kafka/HDFS),降低数据接入门槛。 | 实现内存物化视图(预聚合)、Delete-and-Insert 的更新语义(Unique 模型)、高效的批量与流式数据导入框架,保证数据最终一致性或事务性。 |
| 高性能查询 | 用户获得亚秒级查询响应,支持高并发;兼容标准 SQL 和主流 BI 工具,分析师无需学习新语法。 | MPP 分布式执行框架、全链路向量化计算引擎(基于 Apache Arrow 格式)、CBO/RBO 优化器、Pipeline 异步执行模型、局部性感知的任务调度。 |
| 联邦查询 | 分析师可用一套 SQL 语句同时查询 Doris 本地表与外部 Hive/Iceberg/MySQL 表,打破数据孤岛。 | 实现 Multi-Catalog 元数据管理层,为不同外部数据源开发对应的 Scanner 和 Runtime Filter 下推能力,优化跨源查询性能。 |
| 可观测与运维 | 提供详细的 Web 监控指标(集群负载、查询统计、导入任务)、简单的扩缩容操作。 | 在 FE/BE 中埋点采集 Metrics,通过 HTTP API 暴露;实现基于元数据一致性协议(BDB JE)的节点管理、副本均衡与自动修复机制。 |
3. 技术难点挖掘
作为分布式分析型数据库,Apache Doris 攻克了诸多技术难点,这些难点是其技术深度的体现:
- 查询优化器的有效性:如何在海量可能的执行计划中,基于有限的统计信息,为复杂的多表关联、子查询、窗口函数等场景,选出接近最优的分布式执行计划?这是 Doris CBO 面临的核心挑战。
- 向量化引擎的全链路实现:不仅要在算子和表达式计算层面实现向量化,还需要在存储层(列式读取)、网络传输层(列式数据传输)乃至 UDF 接口上保持列式内存布局,这对整个系统的架构设计是颠覆性的。
- 高并发下的稳定性与性能平衡:如何在高并发点查询(短平快)与复杂大查询(长耗时、占资源)同时存在时,进行有效的资源隔离、排队与调度,避免相互影响?这涉及到精细化的资源组(Resource Group)管理与查询排队策略。
- 实时数据更新的效率:在支持 Unique Key 模型实现行级更新的同时,如何避免传统 Merge-on-Read 带来的查询性能抖动?Doris 的"标记删除 + 异步 compaction"机制需要在更新频率、查询性能和存储放大之间取得平衡。
- 分布式事务与一致性:在支持 Stream Load 等导入方式时,如何保证跨多个 Tablet(数据分片)的写入操作的原子性和一致性?这依赖于两阶段提交与全局事务管理器的设计。
4. 详细设计图
4.1 核心架构图
图:Apache Doris 核心架构图。FE 负责元数据管理与查询协调,BE 负责分布式存储与计算,通过 MySQL 协议对外提供服务,并支持丰富的外部数据源集成。
4.2 核心查询链路序列图(以简单聚合查询为例)
BE3 BE2 BE1 FE (Coordinator) Client BE3 BE2 BE1 FE (Coordinator) Client Fragment M1 (Scan + Local Agg) Fragment M2 (Shuffle/Data Exchange) Fragment M3 (Merge Agg) SELECT user_id, SUM(amount) FROM orders GROUP BY user_id SQL 解析、验证、CBO/RBO优化 生成分布式查询计划 (Fragment) 执行 Fragment M1 (扫描部分 orders 数据) 执行 Fragment M1 (扫描部分 orders 数据) 执行 Fragment M1 (扫描部分 orders 数据) 本地扫描、预聚合 本地扫描、预聚合 本地扫描、预聚合 发送预聚合结果 (按 user_id 分区) 发送预聚合结果 (按 user_id 分区) 全局聚合 (Merge) 返回最终聚合结果 返回查询结果集
图:一个分布式聚合查询的执行序列。展示了 MPP 架构下,查询如何被拆分为多个 Fragment 在不同的 BE 节点上并行执行,并通过数据交换(Shuffle)完成最终计算。
4.3 核心类图(简化版,聚焦查询执行上下文)
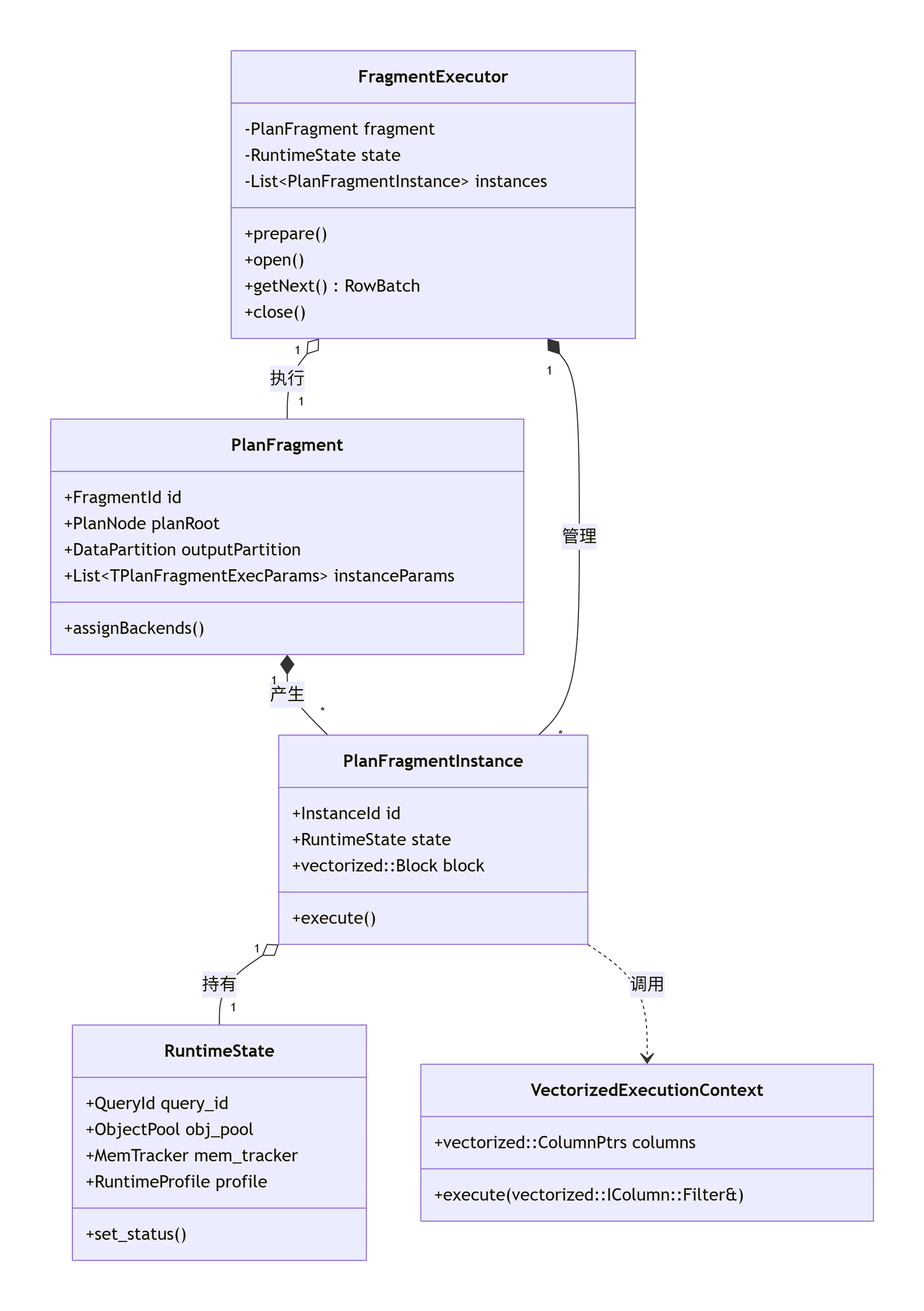
图:简化核心类图,展示了查询执行过程中,从 PlanFragment 到 FragmentExecutor 再到 PlanFragmentInstance 的创建与管理关系,以及用于向量化执行的上下文。
5. 核心函数解析
以下以向量化聚合算子的关键函数为例进行解析。这是 Doris 高性能查询的基石之一。
场景 :在 SELECT city, SUM(sales) FROM t GROUP BY city 查询中,BE 节点上本地聚合的执行过程。
cpp
// 文件:be/src/vec/exec/vaggregation_node.cpp
// 类:VAggregationNode (向量化聚合节点)
// 核心函数:`open` 和 `get_next`
Status VAggregationNode::open(RuntimeState* state) {
START_AND_SCOPE_SPAN(state->get_tracer(), span, "VAggregationNode::open");
RETURN_IF_ERROR(ExecNode::open(state));
// 初始化所有聚合函数:例如,为 SUM(sales) 初始化一个 `SumAggregateFunction` 对象
RETURN_IF_ERROR(VExpr::open(_aggregate_evaluators, state));
// 初始化哈希表,用于存储分组键(city)和聚合状态(sum值)的映射
_hash_table_variants = std::make_unique<AggregatedDataVariants>();
// 根据分组键的数量和类型,选择最优的哈希表实现(如:针对单数字键的键值对,或针对多列键的PHMap)
init_agg_hash_variants(*_hash_table_variants, _probe_expr_ctxs);
// 预分配内存,减少运行时开销
_agg_arena_pool = std::make_unique<Arena>();
return Status::OK();
}
Status VAggregationNode::get_next(RuntimeState* state, vectorized::Block* block, bool* eos) {
INIT_AND_SCOPE_GET_NEXT_SPAN(state->get_tracer(), _get_next_span, "VAggregationNode::get_next");
SCOPED_TIMER(_exec_timer);
// 1. 从子节点(通常是 ScanNode)获取一批向量化数据(Block)
RETURN_IF_ERROR(_children[0]->get_next(state, &_input_block, &_input_eos));
if (!_input_block.rows() > 0 && _input_eos) {
// 2. 如果所有输入数据已处理完,则进入"输出结果"阶段
return _output_result(state, block, eos);
}
// 3. 核心:处理输入 Block,进行聚合计算
RETURN_IF_ERROR(_execute(state, _input_block));
// 4. 清空输入块,准备接收下一批数据
_input_block.clear();
// 5. 如果哈希表大小超过阈值,可能触发"溢写到磁盘"(外部聚合),此处简化
// 6. 设置 eos 为 false,表示可能还有数据
*eos = false;
return Status::OK();
}
// 关键子函数 `_execute` 的简化逻辑
Status VAggregationNode::_execute(RuntimeState* state, const vectorized::Block& block) {
// 1. 为当前 Block 中的分组列(city)计算哈希值,得到一个哈希向量
auto& places = _hash_table_variants->places; // 存储哈希表槽位
// 2. 批量查找/插入:根据哈希值,在哈希表中为每一行找到或创建对应的聚合数据位置
// 这是一个向量化操作,比行式逐行处理效率高得多。
_emplace_into_hash_table(_hash_table_variants.get(), places.data());
// 3. 批量聚合:对找到的每一行,更新其聚合状态(如 sum 值)
// for (每个聚合函数 evaluator) {
// evaluator->function->add_batch( places, 列数据, 行数 );
// }
// 这里的 add_batch 内部会利用 SIMD 指令进行循环展开,高效累加。
for (int i = 0; i < _aggregate_evaluators.size(); ++i) {
RETURN_IF_ERROR(_aggregate_evaluators[i]->execute_batch_add(block, _offsets_of_aggregate_states[i], places.data(), block.rows(), _agg_arena_pool.get()));
}
return Status::OK();
}
// 辅助函数:选择哈希表变体,体现性能优化
void init_agg_hash_variants(AggregatedDataVariants& variants, const VExprContextSPtrs& probe_exprs) {
if (probe_exprs.size() == 1) {
// 单列分组键
switch (probe_exprs[0]->root()->result_type()) {
case TYPE_TINYINT:
variants.type = AggregatedDataVariants::Type::int8_key; // 使用 int8_t 作为键的哈希表
break;
case TYPE_INT:
variants.type = AggregatedDataVariants::Type::int32_key;
break;
case TYPE_VARCHAR:
variants.type = AggregatedDataVariants::Type::string_key; // 使用 StringRef 作为键的哈希表
break;
// ... 其他类型
}
} else {
// 多列分组键,使用组合键的哈希表
variants.type = AggregatedDataVariants::Type::serialized;
}
}代码解析:
- 向量化批量处理 :
get_next和_execute函数操作的最小单位是Block(一批列式数据),而非单行。这减少了循环次数和虚函数调用。 - 高效的哈希聚合 :
_execute函数是性能核心。它先批量计算哈希值(_emplace_into_hash_table),然后批量更新聚合状态(execute_batch_add)。这两个步骤都针对批量数据进行了优化。 - 多态哈希表 :
init_agg_hash_variants函数根据分组键的类型和数量,选择内存布局和算法最优的哈希表实现(如int32_key,string_key)。这种"特化"避免了通用哈希表带来的类型转换和性能开销,是向量化引擎深入优化的典型体现。 - 内存管理 :使用
Arena(_agg_arena_pool) 进行聚合状态内存的集中分配与释放,提升内存局部性并降低碎片。 - 状态跟踪 :通过
RuntimeState、SCOPED_TIMER、RuntimeProfile等机制,方便进行性能剖析和问题诊断。
通过以上对 Apache Doris 的架构、核心难点、设计图及关键代码的剖析,我们可以看到,它并非简单的组件堆砌,而是一个在 MPP 并行框架、列式存储管理、向量化执行引擎、查询优化器、分布式事务 等多个深水区技术领域都有深入设计和持续优化的系统。其 极简架构 与 极致性能 的目标背后,是大量复杂而精巧的工程技术实现。对于寻求构建高性能、易运维、一体化实时数据分析平台的技术团队而言,深入理解 Apache Doris 的这些技术细节,是进行选型评估、性能调优和二次开发的基础。