前言
使用 MCP 或类似 Prompt 编排框架时的常见痛点:当参数定义得太多、太细,AI 反而"自由发挥",提取出你没想让它提取的参数,导致调用出错或结果失控。
比如这里有一个查询会议室的mcp server,设置了如下这些参数,还有筛选(这里的筛选相当不严谨,只是demo,将就一下吧)
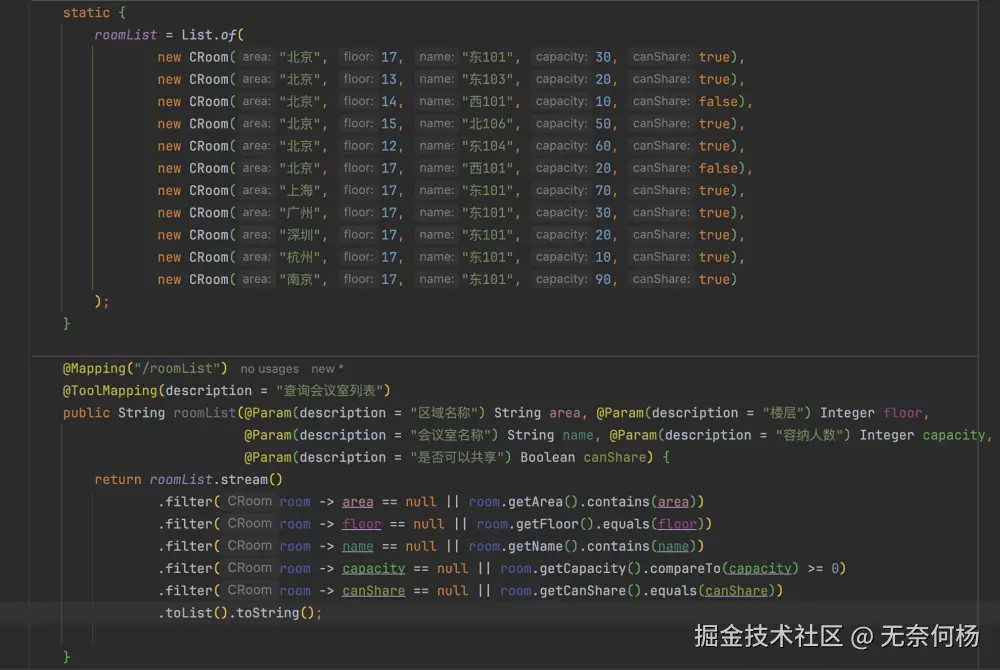
将它注册在mcp client上,测试一下,可以看到
我仅仅只是问"北京"的会议室,AI却意外根据MCP Server工具的参数描述意外的提取了额外的参数,而且这些参数是毫无根据的,楼层1?容量10?哪里来的,这不是乱讲吗?
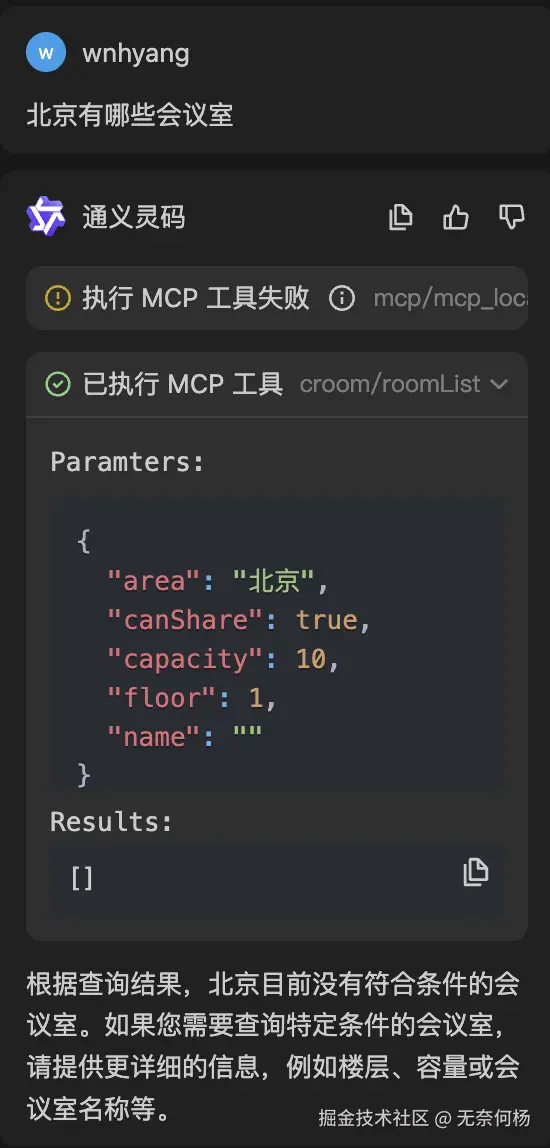
然后我将所有参数都去掉
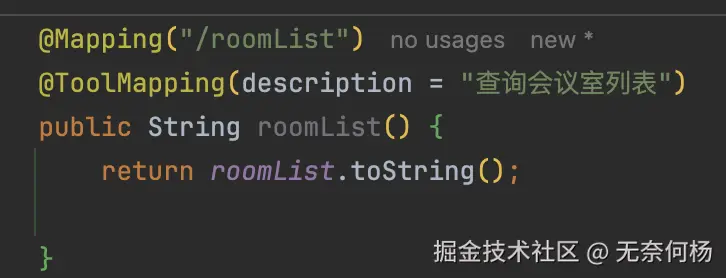
再试一下,这个效果就好得多

小结一下这两种的差别,
总体上都是:用户输入-AI + MCP Client(理解-根据mcp工具列表,选择调用工具?-提取工具参数-调用-整理结果-输出)
方式1:定义了MCP工具参数,AI+MCP Client调用MCP Server,筛选是由MCP Server先初步代码筛选,然后再经过AI的二步筛选。
方式2:删掉了所有的MCP工具参数,一次性将所有数据返回,然后直接由AI筛选。
虽然上面展示出来的是,方式2更符合要求,但其实使用MCP Server并不是这么随意,一边所有参数带上,让AI提取参数后发,一边把所有参数去掉,让AI在相应的基础上再发挥。
归根到底这是MCP 或类似 Prompt 编排框架时的常见痛点:当参数定义得太多、太细,AI 反而"自由发挥",提取出你没想让它提取的参数,导致调用出错或结果失控。
所以我们非常需要一套比较合理且有相关实践经验的"方法论"。
MCP参数定义原则
1、只暴露必要参数(最小化原则)
不要为了"完整"而定义所有可能的参数。
-
错误做法:定义 user_name, user_age, user_gender, user_location, user_interests, scene, tone, length, format... 等 20 个参数。
-
✅ 正确做法:只暴露当前任务真正需要决策的参数。比如这次调用只需要 tone 和 length,其他都用默认值或上下文推断。
AI 的"自由发挥"往往源于你给了它太多"想象空间"。
2、参数命名要"防歧义"
-
避免模糊词:如 style, mode, type ------ AI 容易脑补。
-
推荐命名:动词+名词 或 限定+名词,例如:
-
output_tone(而不是 style)
-
response_length_in_sentences(而不是 length)
-
target_audience_age_group(而不是 audience)
-
3、枚举值优先,避免开放输入
-
开放式:tone: "请用幽默或严肃的语气"
-
枚举式:
json
"tone": {
"type": "string",
"enum": ["humorous", "serious", "neutral", "sarcastic"],
"description": "输出语气风格"
}AI 更容易识别并从选项中选择,而不是"创造"一个 melancholic。
防止 AI "自由发挥"的 5 大策略
策略 1:使用"白名单参数"机制
在 MCP Server 层面,定义一个合法参数白名单。AI 提取的参数如果不在白名单内,直接拒绝调用或自动忽略。
python
VALID_PARAMS = {"tone", "length", "format", "audience"}
def validate_params(extracted):
return {k: v for k, v in extracted.items() if k in VALID_PARAMS}这是最直接的"防越界"手段。
策略 2:在 Prompt 中明确"禁止推测"
在给 AI 的指令中,加入强约束性语句:
"你只能从以下参数中提取值:tone, length, format。禁止推测或生成任何未列出的参数。如果用户提到其他信息,请忽略。"
你可以测试不同表述,比如:
-
"Strictly extract only the parameters defined below."
-
"Do not invent new parameters, even if the user implies them."
策略 3:使用"结构化输出 + Schema 校验"
不要依赖 AI 自由输出 JSON,而是要求它严格按照你定义的 JSON Schema 输出,并在后端做校验。
示例 Schema:
json
{
"type": "object",
"properties": {
"tone": { "type": "string", "enum": ["fun", "formal", "casual"] },
"length": { "type": "integer", "minimum": 1, "maximum": 5 }
},
"required": ["tone"],
"additionalProperties": false // 关键!禁止额外字段
}additionalProperties: false 是防止"自由发挥"的关键。
策略 4:分阶段提取:先分类,再提取
不要让 AI 一步到位提取所有参数。可以分两步:
-
意图识别阶段:判断用户想调用哪个功能(如"写文案"、"生成图片")。
-
参数提取阶段:根据功能,加载对应的参数 schema,再提取。
这样可以缩小参数搜索空间,减少误提取。
策略 5:加入"默认值 + 忽略机制"
对于非关键参数,设置默认值,并允许 AI "不提取":
"如果用户未明确提及 length,则使用默认值 3。不要试图从上下文中推测。"
这样避免 AI 为了"完整"而强行提取。
总结
"定义要窄,枚举要全,约束要严,校验要狠。"
不要指望 AI 能"自觉"遵守规则,而是要用 Schema + Prompt + 后端校验 三层围栏,把它圈在你想要的范围内。