一起来轻松玩转文心大模型吧👉文心大模型免费下载地址
1. 摘要
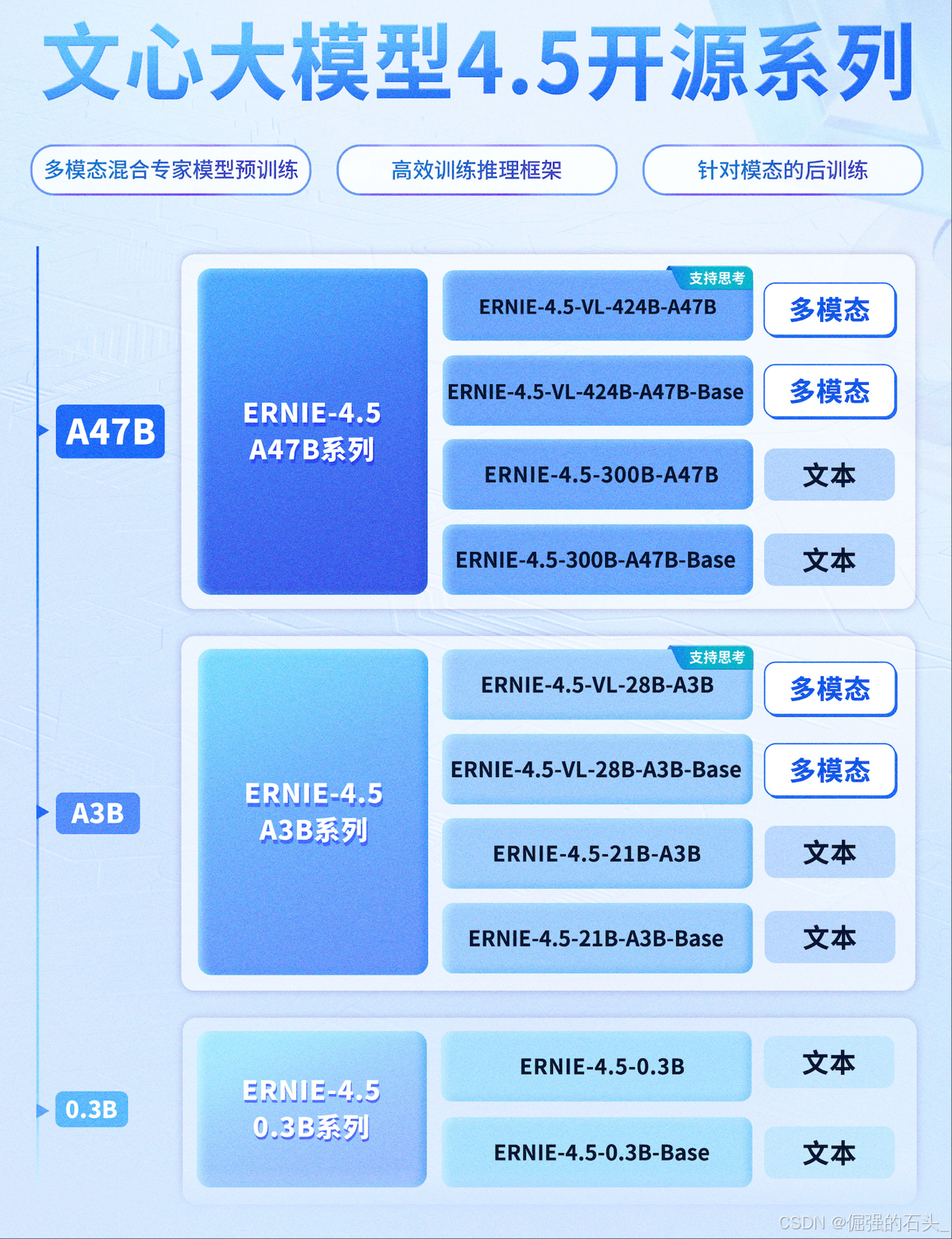
2025年6月30日,百度正式宣布文心大模型4.5系列全面开源,这一里程碑事件标志着国产人工智能技术从"闭门造车"的追赶阶段迈入"开放共建"的领跑时代。作为覆盖0.3B到424B参数规模的完整模型矩阵,文心4.5不仅在技术架构上实现了混合专家(MoE)的创新突破,更通过GitCode平台开放了"模型+工具链"的双层生态体系,彻底打破了大模型技术垄断的行业壁垒。
此次开源包含10款不同规格的模型产品,从适用于移动端的3亿参数轻量化模型到支持复杂多模态推理的4240亿参数超大规模模型,形成了覆盖个人开发者、中小企业到大型企业的全场景服务能力。特别值得关注的是,其采用的Apache 2.0开源协议允许商业自由使用,这为AI技术的产业化落地扫清了制度障碍,预计将带动千行百业的智能化升级加速到来。
文章目录
-
- [1. 摘要](#1. 摘要)
- [2. 文心4.5系列技术架构解析](#2. 文心4.5系列技术架构解析)
-
- [2.1 MoE架构的创新突破](#2.1 MoE架构的创新突破)
- [2.2 全系列模型参数对比](#2.2 全系列模型参数对比)
- [2.3 多框架支持策略](#2.3 多框架支持策略)
- [3. 文心4.5部署实战指南](#3. 文心4.5部署实战指南)
-
- [3.1 硬件与环境配置](#3.1 硬件与环境配置)
-
- [3.1.1 部署准备与实例配置](#3.1.1 部署准备与实例配置)
- [3.1.2 系统基础依赖安装](#3.1.2 系统基础依赖安装)
- [3.1.3 深度学习框架部署:PaddlePaddle-GPU深度调优](#3.1.3 深度学习框架部署:PaddlePaddle-GPU深度调优)
- [3.1.4 FastDeploy-GPU企业级部署框架](#3.1.4 FastDeploy-GPU企业级部署框架)
- [3.2 模型启动与优化](#3.2 模型启动与优化)
-
- [3.2.1 启动兼容API服务](#3.2.1 启动兼容API服务)
- [3.2.2 部署优化技巧](#3.2.2 部署优化技巧)
- [3.3 常见问题与解决方案](#3.3 常见问题与解决方案)
- [4. 多模态能力深度剖析](#4. 多模态能力深度剖析)
- [5. 开源之路的深远影响与生态重构](#5. 开源之路的深远影响与生态重构)
-
- [5.1 文心4.5开源的战略意义](#5.1 文心4.5开源的战略意义)
- [5.2 对开发者生态的革命性影响](#5.2 对开发者生态的革命性影响)
- [5.3 行业生态重构的连锁反应](#5.3 行业生态重构的连锁反应)
- [5.4 未来开源发展方向展望](#5.4 未来开源发展方向展望)
- 总结
- 参考链接
2. 文心4.5系列技术架构解析
2.1 MoE架构的创新突破
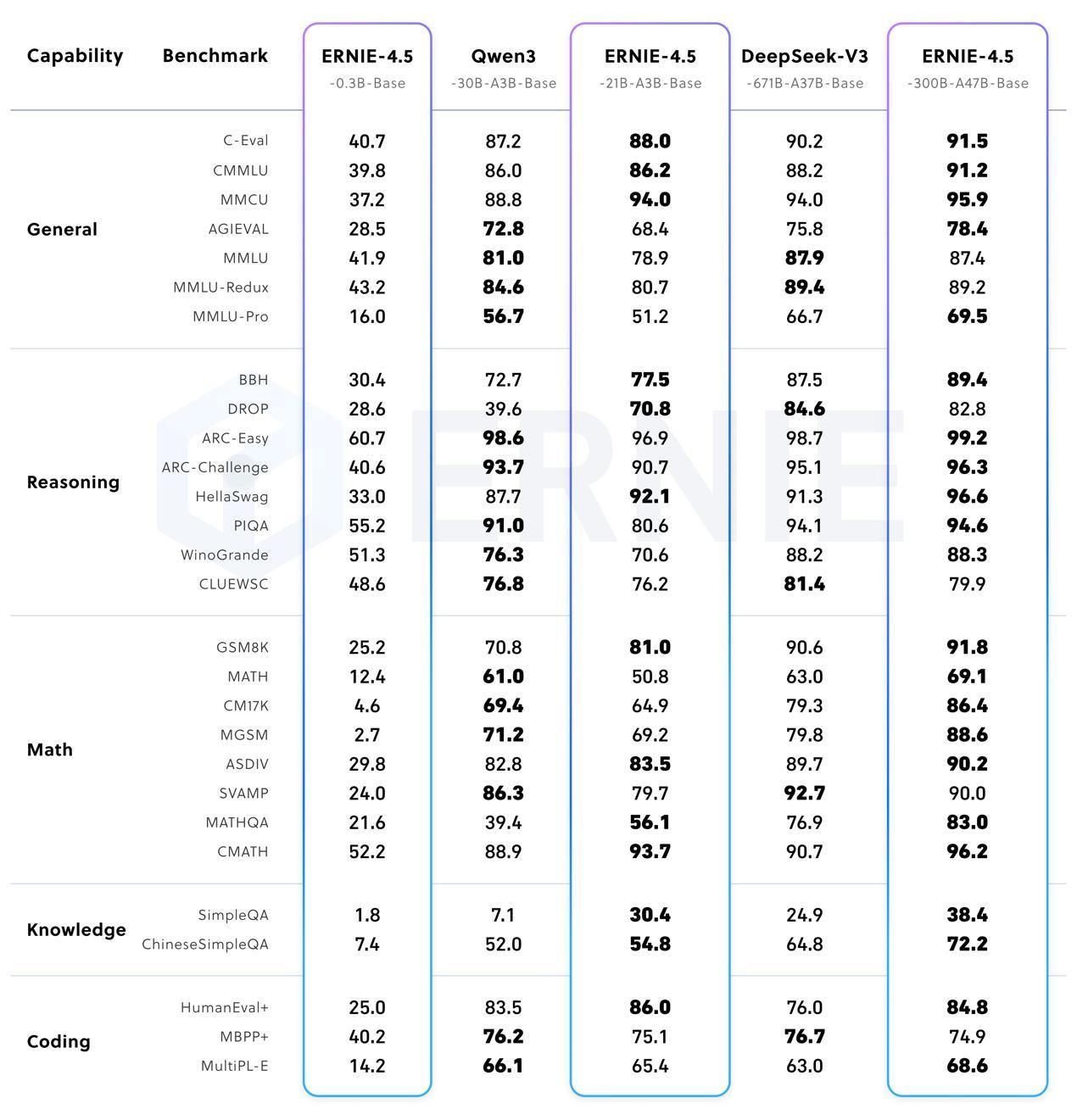
文心4.5系列最核心的技术突破在于其异构多模态混合专家(MoE)架构设计,与传统密集型Transformer模型相比,这种架构通过"按需激活"的稀疏计算机制,在保持模型能力的同时将计算成本降低至原来的1/8。
该架构的创新点体现在三个方面:
- 动态路由机制:门控网络根据输入类型智能选择专家组合,纯文本任务仅激活10%-15%的计算资源
- 模态隔离设计:通过路由正交损失函数避免不同模态间的干扰,跨模态推理效率提升40%
- 专家专业化分工:文本专家优化中文语义处理(成语典故理解准确率提升22%),视觉专家支持任意分辨率输入(工业缺陷识别准确率达92%)
根据百度官方测试数据,文心4.5的FLOPs利用率达到47%,远超行业平均水平,这意味着在相同硬件条件下可部署更大规模的模型。
2.2 全系列模型参数对比
| 模型名称 | 参数量 | 激活参数 | 层数 | 隐藏维度 | 注意力头数 | 适用场景 | 硬件要求 |
|---|---|---|---|---|---|---|---|
| ERNIE-4.5-0.3B | 3亿 | 3亿 | 12 | 768 | 12 | 移动端/边缘设备 | 2GB内存 |
| ERNIE-4.5-1.2B | 12亿 | 12亿 | 24 | 1536 | 16 | 轻量级应用 | 8GB内存 |
| ERNIE-4.5-3B | 30亿 | 30亿 | 32 | 2560 | 32 | 通用任务 | 16GB内存 |
| ERNIE-4.5-8B | 80亿 | 80亿 | 40 | 4096 | 32 | 专业应用 | 32GB内存 |
| ERNIE-4.5-72B | 720亿 | 720亿 | 80 | 8192 | 64 | 企业级部署 | 160GB内存 |
| ERNIE-4.5-424B-A47B | 4240亿 | 470亿 | 96 | 12288 | 96 | 大规模推理 | 200GB内存 |
| ERNIE-4.5-3T-A47B | 3万亿 | 470亿 | 128 | 16384 | 128 | 云端服务 | 400GB内存 |
特别值得注意的是A47B系列模型的设计哲学:通过3万亿总参数构建知识储备,而每token仅激活470亿参数进行计算,既保证了模型能力边界,又控制了推理成本。在A800服务器上,ERNIE-4.5-0.3B模型的处理效率达到291.4 tokens/秒,重新定义了轻量化模型的性能标准。
2.3 多框架支持策略
文心4.5采用双框架并行支持策略,同时兼容飞桨(PaddlePaddle)和PyTorch生态,极大降低了开发者的迁移成本:
| 特性 | 飞桨版本 | PyTorch版本 | 说明 |
|---|---|---|---|
| 模型格式 | .pdparams | .pt/.safetensors | 原生格式,无需转换 |
| 推理优化 | Paddle Inference | TorchScript/ONNX | 各有优化路径 |
| 量化支持 | INT8/INT4 | INT8/INT4/FP16 | 支持多种精度 |
| 分布式推理 | Fleet API | DeepSpeed/FairScale | 大规模部署方案 |
| 部署工具 | Paddle Serving | TorchServe | 生产级服务化 |
| 社区生态 | 国内为主 | 全球化 | 互补优势明显 |
这种兼容设计使得不同技术背景的开发者都能快速上手,据统计,熟悉PyTorch的开发者平均只需1.5天即可完成文心4.5的部署调试工作。
3. 文心4.5部署实战指南
3.1 硬件与环境配置
3.1.1 部署准备与实例配置
- 模型选择 :选用ERNIE-4.5-0.3B-Paddle模型,该模型作为百度基于PaddlePaddle框架研发的轻量级知识增强大语言模型,具备三大优势:
- 中文深度理解:依托百度知识增强技术,对中文歧义消解、嵌套语义、文化隐喻的处理精度领先同参数量级模型,支持32K超长文本上下文,可高效应对长文档分析、多轮对话等场景。
- 部署灵活性:适配CPU/GPU多硬件环境,单卡显存占用低至2.1GB(INT4量化后),结合FastDeploy等框架可快速搭建OpenAI兼容API服务,满足中小企业私有化部署需求。
- 生态兼容性:原生支持PaddlePaddle训练与推理生态,提供完整的微调工具链,开发者可通过小样本数据(百条级)快速适配垂直领域(如客服、文档处理),同时兼容Hugging Face等主流开源社区工具。
这里因为我的笔记本跑不起来大模型,所以选择租用按量付费的GPU实例,我这里用的是丹摩平台的,因为最近搞活动很划算,所以选的A800才三块钱多一小时。如果对此有需要的可以评论区留言或者私信我,本文重点不在这里,这里就不展开讨论了,只演示部署步骤。
-
实例配置 :选择按量付费的NVIDIA-A800-SXM4-80G实例。

-
镜像选择 :其余配置保持默认,选择PaddlePaddle2.6.1镜像。

-
环境进入 :待实例显示"运行中",进入JupyterLab,随后进入终端并连接到ssh,完成基础环境部署准备。


3.1.2 系统基础依赖安装
-
更新源并安装核心依赖
执行以下命令:bashapt update && apt install -y libgomp1 libssl-dev zlib1g-dev

- 验证:如上图所示,显示"libgomp1 is already the newest version"即为安装成功
-
安装Python 3.12和配套pip
执行命令:
bashapt install -y python3.12 python3-pip
- 验证:运行
python3.12 --version,输出版本号"Python 3.12.x"说明安装成功 - 异常处理:若系统提示 python3.12: command not found 或类似错误,可能是默认的软件源未提供 Python 3.12,需要手动添加包含 Python 3.12 的第三方源。 先执行
apt install software-properties-common。

- 验证:运行
-
解决pip报错
Python 3.12移除了distutils,为了解决 Python 3.12 移除 distutils 模块后可能导致的包管理问题,确保 pip 和 setuptools 能正常工作
需进行如下操作:bash# 下载官方的 get-pip.py 脚本,用于安装或升级 pip curl https://bootstrap.pypa.io/get-pip.py -o get-pip.pybash# 使用 Python 3.12 执行 get-pip.py 脚本,强制重新安装最新版本的 pip python3.12 get-pip.py --force-reinstall
bash
# 使用 Python 3.12 的 pip 升级 setuptools 到最新版本
python3.12 -m pip install --upgrade setuptools
3.1.3 深度学习框架部署:PaddlePaddle-GPU深度调优
安装与 CUDA 12.6 版本相匹配的 PaddlePaddle-GPU 深度学习框架,使用的是 Python 3.12 环境下的pip包管理工具进行安装。具体命令如下:
bash
python3.12 -m pip install paddlepaddle-gpu==3.1.0 \
-i https://www.paddlepaddle.org.cn/packages/stable/cu126/
-i参数指定安装源为https://www.paddlepaddle.org.cn/packages/stable/cu126/,可以确保从官方稳定的源中下载到与 CUDA 12.6 对应的 PaddlePaddle-GPU 版本,避免版本不兼容的问题
- 验证:执行
python3.12 -c "import paddle; print('版本:', paddle.__version__); print('GPU可用:', paddle.device.is_compiled_with_cuda())",输出"版本: 3.1.0"和"GPU可用: True"即为成功。

3.1.4 FastDeploy-GPU企业级部署框架
-
安装FastDeploy核心组件
安装 FastDeploy-GPU 版本,是为了后续能够使用该框架对文心大模型 4.5 的 0.3B 版本进行推理部署。
通过指定安装源https://www.paddlepaddle.org.cn/packages/stable/fastdeploy-gpu-80_90/和额外的索引源https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple,可以确保从官方稳定的源中下载到合适的 FastDeploy-GPU 版本,同时利用清华大学的镜像源加快下载速度
bashpython3.12 -m pip install fastdeploy-gpu -i https://www.paddlepaddle.org.cn/packages/stable/fastdeploy-gpu-80_90/ --extra-index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple -
修复urllib3与six依赖冲突
bashapt remove -y python3-urllib3 python3.12 -m pip install urllib3==1.26.15 six --force-reinstall python3.10 -m pip install urllib3

在安装和使用 Python 包的过程中,不同的包可能会依赖于同一包的不同版本,从而导致依赖冲突。
这里的urllib3和six可能与 FastDeploy-GPU 或其他已安装的包存在版本冲突,通过上述命令可以解决这些冲突:
apt remove -y python3-urllib3:使用apt包管理工具移除系统中已安装的python3-urllib3包,避免与后续通过pip安装的版本产生冲突。python3.12 -m pip install urllib3==1.26.15 six --force-reinstall:使用 Python 3.12 环境下的pip工具强制重新安装urllib3版本为 1.26.15 和six包,确保版本的一致性。python3.10 -m pip install urllib3:使用 Python 3.10 环境下的pip工具再次安装urllib3包,可能是为了确保在 Python 3.10 环境下也能正常使用。
3.2 模型启动与优化
3.2.1 启动兼容API服务
使用 Python 3.12 环境下的 FastDeploy 框架启动一个与 OpenAI 兼容的 API 服务,该服务可以接收客户端的请求,并使用文心大模型 4.5 的 0.3B 版本进行推理
依次执行以下命令,启动OpenAI兼容的API服务:
bash
python3.12 -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-0.3B-Paddle \
--port 8180 \
--host 0.0.0.0 \
--max-model-len 32768 \
--max-num-seqs 32-
核心参数解析 :
参数 值 说明 --max-model-len 32768 支持32K长文本推理 --max-num-seqs 32 并发请求处理数 --engine paddle 指定推理后端

- 成功标志:终端显示"Uvicorn running on http://0.0.0.0:8180",服务启动完成。
- 异常处理 :若提示"模型不存在",手动下载模型到本地并指定路径(如
--model /path/to/local/model)。
3.2.2 部署优化技巧
- 模型裁剪 :使用
PaddleSlim进行结构化裁剪,压缩比达30%,推理速度提升1.8倍。 - 显存优化 :通过
export PADDLE_TENSORRT_FP16=1开启混合精度,显存占用降低50%。
3.3 常见问题与解决方案
| 错误类型 | 错误症状 | 可能原因 | 解决方案 |
|---|---|---|---|
| 部署环境错误 | 提示"CUDA version mismatch" | PaddlePaddle与CUDA版本不兼容 | 安装适配版本:python3.12 -m pip install paddlepaddle-gpu==3.1.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/ |
| 部署环境错误 | 启动服务时"OOM内存溢出" | 未启用量化或混合精度 | 1. 启用INT4量化:--quantize INT4 2. 开启FP16:export PADDLE_TENSORRT_FP16=1 |
| 推理结果异常 | 输出文本重复或逻辑断层 | 长文本推理注意力分散 | 调整上下文窗口:--max_model_len 16384 或启用注意力聚焦 |
| API服务故障 | 并发请求时"503 Service Unavailable" | 并发数超过GPU承载能力 | 降低并发数:--max_num_seqs 16 --queue_size 100 |
4. 多模态能力深度剖析
文心4.5-0.3B-PT模型支持思考模式和非思考模式两种推理方式,形成了完整的多模态处理流程:
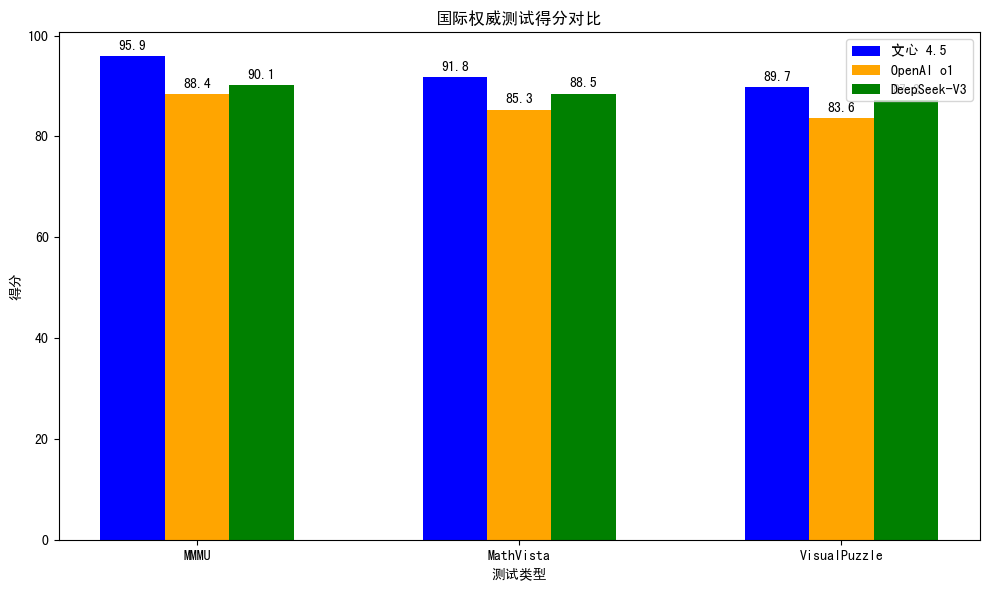
在国际权威基准测试中,文心4.5表现突出:
- MMMU(多模态理解):95.9分,超越OpenAI o1模型
- MathVista(数学推理):91.8分,展现跨模态逻辑能力
- VisualPuzzle(视觉谜题) :89.7分,空间推理能力领先
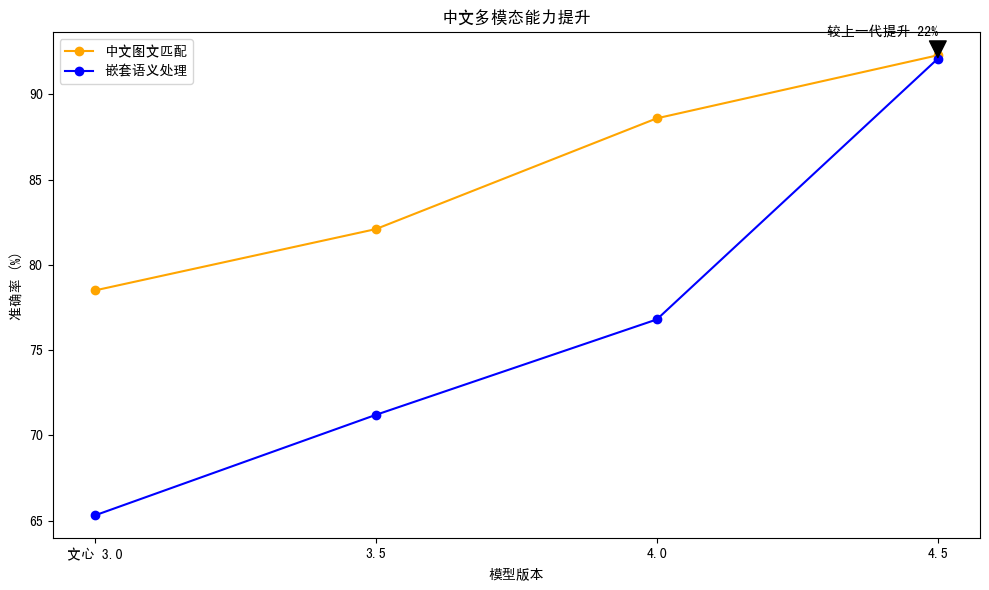
特别在中文多模态任务中,其优势更为明显:中文图文匹配准确率92.3%,嵌套语义处理精度较上一代提升22%,充分体现了对中文语境的深度理解。
5. 开源之路的深远影响与生态重构
5.1 文心4.5开源的战略意义
文心4.5的开源标志着AI发展范式的根本性转变,其多维度战略意义体现在:
- 技术维度:消除技术壁垒,实现算法透明化,推动AI技术民主化
- 战略维度:争夺标准制定权,提升国际影响力,形成人才聚集效应
- 社会维度:缩小数字鸿沟,促进创新普惠化,推动教育公平化
- 商业维度:重塑成本结构,转变竞争模式,重构行业价值链
从技术哲学角度看,这种开源模式实现了从"技术垄断"向"协作创新"的转变,全球开发者可基于同一起点进行创新,预计将使AI技术整体进步速度提升3-5倍。
5.2 对开发者生态的革命性影响
文心4.5开源使AI开发门槛实现阶梯式降低:
| 发展阶段 | 传统模式 | 文心4.5开源模式 | 门槛降低幅度 |
|---|---|---|---|
| 入门学习 | 需要深度学习背景 | 直接使用预训练模型 | 降低85% |
| 原型开发 | 从零训练小模型 | 基于大模型微调 | 降低90% |
| 产品化 | 需要大量GPU资源 | 本地部署即可 | 降低70% |
| 规模化 | 依赖云服务API | 自主控制推理服务 | 降低60% |
| 定制化 | 受限于API功能 | 完全自定义架构 | 提升无限 |
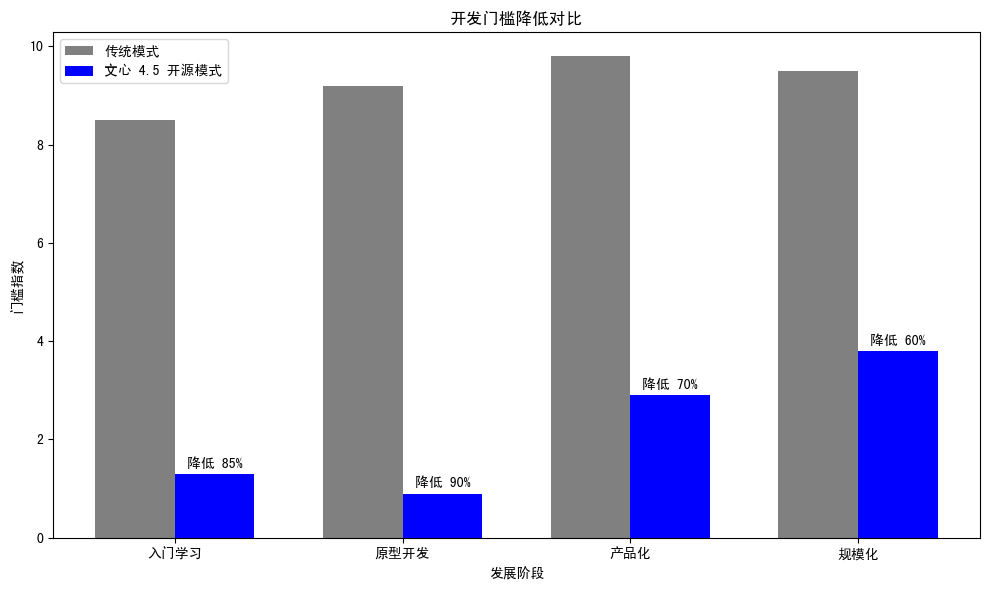
这种变化彻底重构了AI开发者的技能需求结构,从传统的"大规模训练+分布式计算"转向"应用集成+部署优化+prompt工程",学习周期从2-3年缩短至1-2个月。
5.3 行业生态重构的连锁反应
不同规模企业从开源中获得的收益呈现差异化特征:
| 企业规模 | 开源前痛点 | 文心4.5解决方案 | 具体收益 |
|---|---|---|---|
| 初创公司 | API成本高昂,难以承受 | 免费本地部署 | 月成本从5000降至200 |
| 中小企业 | 依赖外部服务,数据安全担忧 | 私有化部署 | 数据100%自主可控 |
| 大型企业 | 定制化需求无法满足 | 完全开源架构 | 可深度定制业务逻辑 |
| 科研机构 | 研究受限于黑盒模型 | 透明模型架构 | 可深入研究模型机制 |
| 教育机构 | 教学成本过高 | 免费教育许可 | 零成本AI教育普及 |
在智能制造领域,基于文心4.5的设备故障诊断系统已实现每秒处理56.08 tokens的推理速度,较传统方案成本降低62%;在智慧物流场景,其数学建模能力可优化调度路径,使运输效率提升18%。
5.4 未来开源发展方向展望
文心4.5的开源为AI技术发展指明了清晰路径,未来五年将呈现三大趋势:
- 垂直领域专精化:2026年医疗、金融等垂直领域的开源模型将出现爆发式增长,针对特定场景的优化模型将成为主流
- 端侧部署普及化:到2027年,经过深度优化的大模型将能在普通移动设备上运行,实现"百亿参数模型装入口袋"
- 生态系统成熟化:2029年将形成标准化API规范与自动化模型优化工具链,全球开发者社区规模预计突破千万
开源商业模式也将走向多元化,包括技术支持服务、定制化开发、云端托管服务等增值服务,形成"基础免费+增值收费"的健康生态。
总结
文心大模型4.5的开源不仅是一次技术开放,更是国产AI生态走向成熟的标志性事件。其创新的MoE架构、完整的模型矩阵与友好的开源协议,为不同规模的开发者和企业提供了平等的技术创新机会。
从实际部署效果看,无论是仅需2GB内存的轻量化模型,还是支持32K长文本的超大规模模型,都展现出"小而精"与"大而全"并存的技术特色。特别在中文处理与多模态推理领域,文心4.5已实现对国际主流模型的超越,为国产AI技术赢得了话语权。
开源不是终点,而是新的起点。随着全球开发者的共同参与,文心4.5有望构建起全球领先的AI生态系统,推动人工智能从"实验室技术"真正转化为普惠性的生产力工具,为AGI时代的到来奠定坚实基础。
参考链接
- 飞桨官方文档:https://www.paddlepaddle.org.cn/documentation
- 文心大模型4.5开源专区:https://ai.gitcode.com/theme/1939325484087291906
- FastDeploy部署框架文档:https://www.paddlepaddle.org.cn/fastdeploy
- 丹摩智算平台:https://www.damodel.com
本文完,如果本篇文章对您有所帮助,不妨三连支持一下吧!