编者按: 在人工智能算力军备竞赛愈演愈烈的今天,为什么 Google 会选择与主流 GPU 截然不同的技术路线,开发出架构独特的 TPU?这种专用芯片究竟凭借什么优势,能够支撑起 Gemini、Veo 等 AI 模型的训练与推理?
文章从单芯片架构出发,深入剖析了 TPU 的核心设计理念:首先解释了 TPU 如何通过脉动阵列和流水线技术优化矩阵运算,然后阐述了 XLA 编译器如何通过预先编译减少缓存依赖,大幅降低能耗。在多芯片层面,作者详细介绍了 TPU 从托盘、机架、Pod 到 Multi-Pod 的层级扩展架构,特别是 OCS 光交换技术如何实现灵活的拓扑重构和故障容错。文章还通过具体案例展示了不同拓扑结构对并行训练策略的影响,以及 Multi-Pod 架构如何支撑超大规模模型训练。
作者 | Henry Ko
编译 | 岳扬
最近我大量使用 TPU,发现它们与 GPU 的设计理念非常不同,感觉很有趣。
TPU 的主要优势在于其可扩展性。这是通过硬件层面(例如能效方面和模块化)与软件层面(例如 XLA compiler)的协同设计实现的。
01 背景信息
简单介绍一下 TPU,它是谷歌的专用集成电路(ASIC),其设计聚焦于两大要素:极高的矩阵运算(matmul)吞吐量和能源效率。
它们的起源可追溯到 2006 年的谷歌。当时,他们正在评估是采用 GPU、FPGA 还是定制的 ASIC。当时,只有少数应用需要使用专用硬件,他们判断通过从大型数据中心调配多余的 CPU 算力即可满足这些需求。但这一情况在 2013 年发生了变化,当时谷歌的语音搜索功能运行在神经网络上,而内部预测认为,如果该功能发展起来,将需要远超以往的算力。
时至今日,TPU 已为谷歌的大多数人工智能服务提供算力支撑。当然,也包括 Gemini 或 Veo 的训练和推理,也包括他们的推荐模型。
让我们从底层开始,深入了解一下 TPU 的内部构造。
02 单个 TPU 芯片内部的架构层级
下文图示均以 TPUv4 为例,但其整体布局基本也适用于最新一代 TPU(如 TPUv6p "Trillium"。TPUv7 "Ironwood" 的细节截至 2025 年 6 月尚未公布)。
单颗 TPUv4 芯片的结构如下:
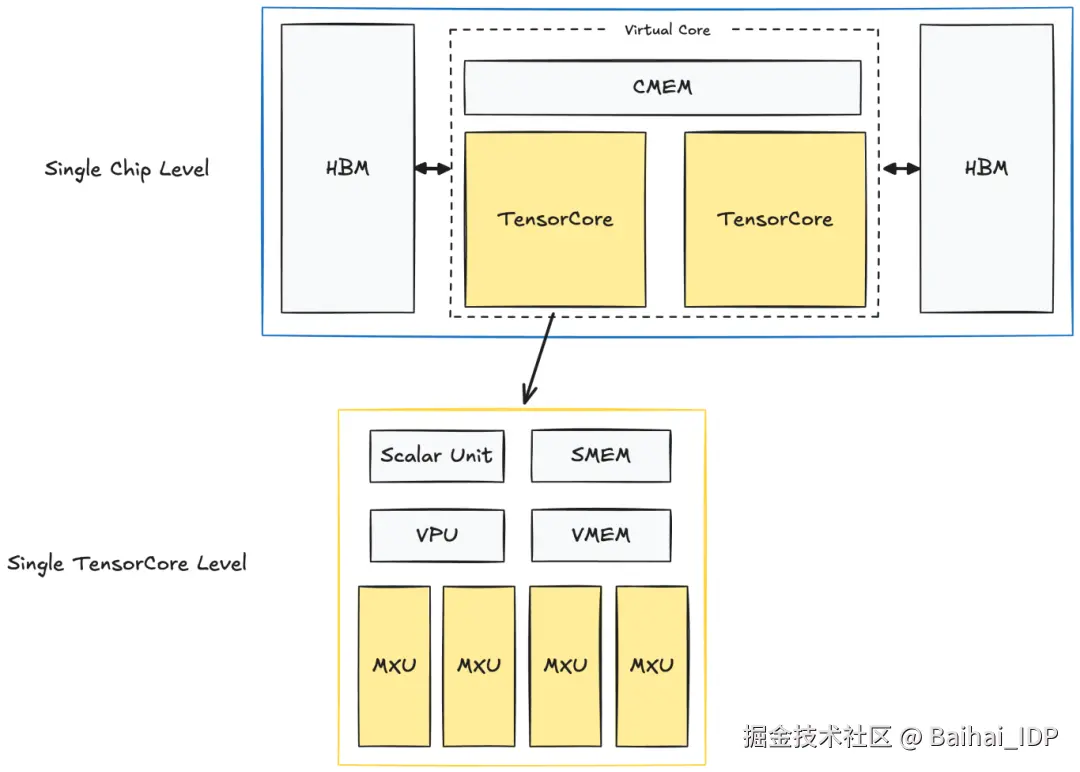
TPU Single Chip + TensorCore
每颗芯片内含两个 TPU TensorCore,负责所有计算。(注:面向推理的专用 TPU 仅有一个 TensorCore)。两个 TensorCore 共享同一份内存:CMEM(128 MiB)和 HBM(32 GiB)。
而在每个 TensorCore 内部,都有计算单元和较小的内存缓冲区:
1)矩阵乘法单元 (MXU)
- 这是 TensorCore 的核心部件,是一个 128x128 的脉动阵列(systolic array)。
脉动阵列的原理稍后说明。
2)向量单元(VPU)
- 负责执行通用的逐元素操作(例如 ReLU、点加/点乘、归约操作)
3)向量内存(VMEM;32 MiB)
- 内存缓冲区。HBM 中的数据需先复制到 VMEM,TensorCore 才能开始计算。
4)标量单元 + 标量内存(SMEM;10 MiB)
- 用于调度 VPU 和 MXU 的执行指令。
- 负责管理控制流、标量运算和内存地址生成。
如果你使用的是英伟达(NVIDIA)GPU,那么一些初步观察结果可能会让你大吃一惊:
1)TPU 的片上内存单元(CMEM、VMEM、SMEM)远大于 GPU 的 L1/L2 缓存。
2)TPU 的 HBM 容量却远小于 GPU 的 HBM。
3)负责计算的"核心"(cores)数量明显更少。
这与 GPU 架构完全相反 ------ GPU 拥有较小的 L1/L2 缓存(以 H100 为例,分别为 256KB 和 50MB)、更大的 HBM(H100 为 80GB)以及数以万计的计算核心(cores)。
在我们进一步讨论之前,需明确的是,TPU 与 GPU 同样具备极高的吞吐量。单颗 TPU v5p 芯片可达 500 TFLOPs/sec,由 8960 颗芯片组成的完整 pod 集群可实现约 4.45 ExaFLOPs/sec。而最新的 "Ironwood" TPUv7 每个 pod(9216 颗芯片)据称可达 42.5 ExaFLOPS/sec。
要理解 TPU 如何实现这种性能,我们需要深入探究其设计理念。
03 TPU 的设计理念
TPU 通过两大技术支柱和一个核心前提实现了惊人的吞吐量与能源效率:systolic array(脉动阵列) + pipelining(流水线)、Ahead-of-Time (AoT) compilation(预先编译),以及假设绝大多数运算都可通过适配 systolic array(脉动阵列)的方式表达。幸运的是,在现代深度学习(DL)领域,计算的大部分都是矩阵运算,而这些运算都适合使用 systolic array(脉动阵列)。
3.1 TPU 设计选择之一:Systolic Array + Pipelining
问:什么是 Systolic Array?
答:Systolic Array 是一种硬件设计架构,由相互连接的处理单元(PE)网格组成。每个 PE 执行少量运算(例如乘法和累加运算),并将结果传递给相邻 PE。
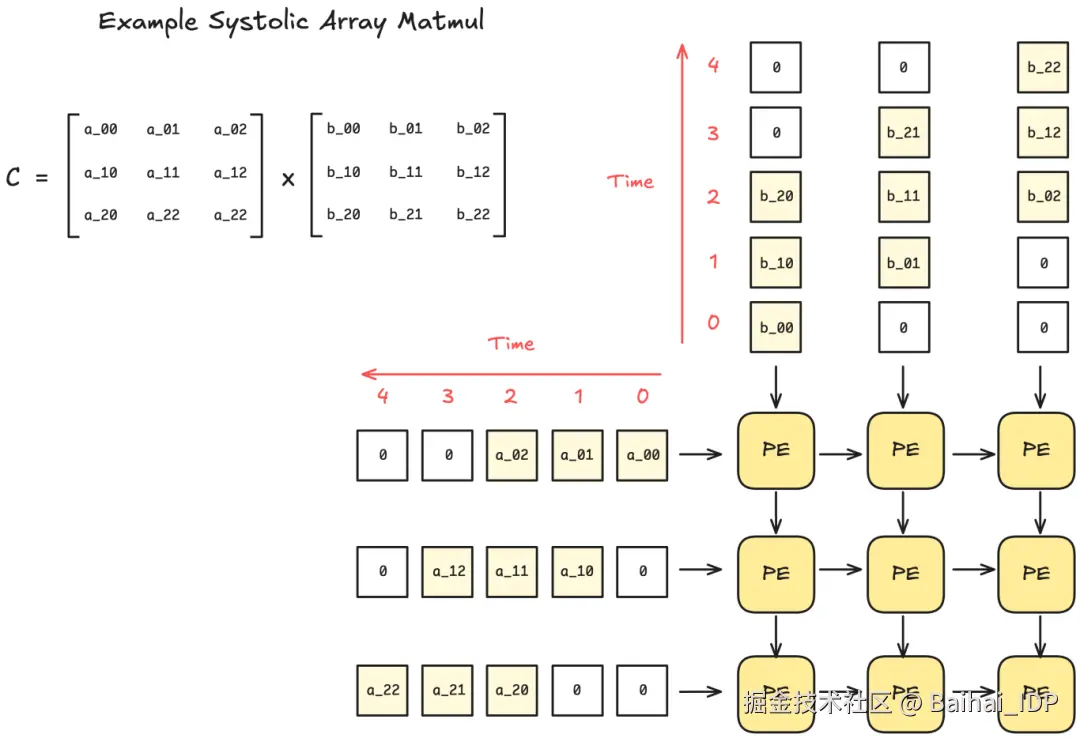
这种设计的好处是,数据一旦输入 systolic array(脉动阵列),便无需额外的控制逻辑来处理数据。此外,当脉动阵列的规模足够大时,除输入输出外再无内存读写操作。
由于脉动阵列的刚性结构设计(rigid organization),其仅能处理具有固定数据流模式的操作,但幸运的是,矩阵乘法和卷积运算(convolutions)恰好完美适配这种架构范式。
不仅如此,pipelining(流水线技术)显然有机会将计算与数据移动重叠执行。下图展示了 TPU 架构上 pipelined pointwise operation (通过流水线技术,加速 pointwise operation(逐点操作) 的执行过程。)的示意图。
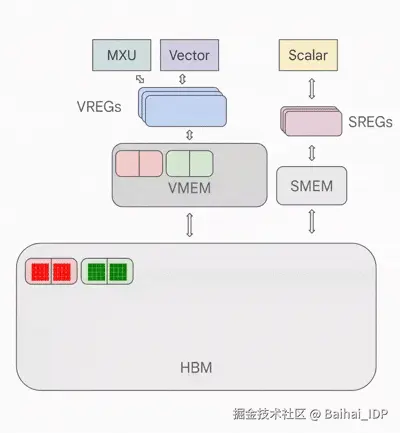
Pipelined Pointwise Operation (from "How to Scale Your Model" 4)
旁注:Systolic Arrays(脉动阵列)的局限性 ------ 稀疏性
我们可以看到,脉动阵列(systolic arrays)非常喜欢稠密矩阵(dense matrices)(即每个 PE 几乎每个时钟周期都处于活跃状态)。然而,其劣势是,相同规模的稀疏矩阵(sparse matrices)无法获得性能提升 ------ 即使对于零值元素(zero-valued elements),PE 仍需执行相同数量的计算周期(cycles),导致资源浪费。
如若深度学习(DL)领域更倾向于采用更不规则的稀疏性(例如 MoE 架构),应对脉动阵列的这一系统性局限将变得愈发重要。
3.2 TPU 设计选择之二:预先(AoT)编译 + 减少对缓存的依赖
本节将回答 TPU 如何通过软硬件协同设计(TPU + XLA 编译器)来避免使用缓存,从而实现高能效。
首先,请记住传统缓存是为了处理不可预测的内存访问模式而设计的。一个应用程序的内存访问模式(memory access patterns),可能与另一个应用程序大相径庭。从本质上讲,缓存允许硬件灵活地适应各种应用场景。这也是 GPU(相较于 TPU)灵活性极高的一个重要原因。
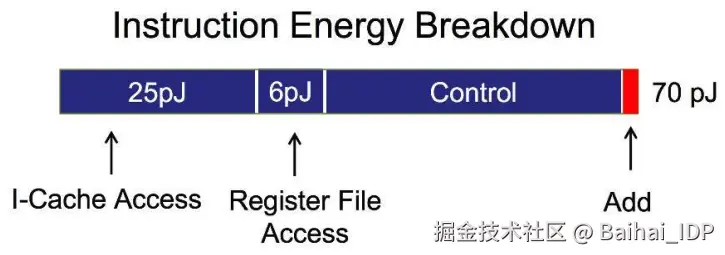
然而,缓存访问(以及一般意义上的内存访问)会消耗大量能源。下面是对芯片(45纳米,0.9V;18)上各类操作的能耗粗略估计。这里的主要启示是,内存的访问和控制占用了大部分的能耗,而算术操作本身的能耗占比则小得多。
但是,如果你的应用非常特殊,而且其计算和内存访问模式具有很高的可预测性呢?
举个极端的例子,如果我们的编译器能提前确定所有需要的内存访问,那么硬件仅需一个暂存器作为缓冲区就足以满足需求,根本不需要缓存。
这正是 TPU 的设计理念所追求的,也是 TPU 使用 XLA 编译器设计以实现这一目标的根本原因。XLA 编译器通过提前分析计算图来生成优化过的程序。
问:但 JAX 在 TPU 上也运行良好,它们使用 @jit 吗?
TPU 上的 JAX+XLA 实际处于 JIT 与 AOT 的混合模式,因此容易产生混淆。当首次调用 JAX 中被 @jit 修饰的函数时,JAX 会进行代码追踪并生成静态计算图。然后将其传递给 XLA 编译器,在那里被转化为适用于 TPU 的完全静态二进制文件。在最后的转化阶段,编译器会实施针对 TPU 的优化(例如,最大限度地减少内存访问),使整个过程适合 TPU。
但有一点需要注意:当输入张量的形状(shape)发生变化时,已编译的 JIT 函数需重新编译并缓存。这就是为什么 JAX 在处理动态填充(dynamic padding)或长度随输入变化的 for 循环层时表现不佳。
当然,这种方案虽有优势,却也存在明显的局限。它缺乏灵活性,而对编译器的重度依赖犹如一把双刃剑。
那么,Google 为何仍要坚持这种设计理念?
TPU 及其能源效率(TPUv4)
前文的能耗示意图并不能精确反映 TPU 的实际情况,此处是 TPUv4 的能耗细目。注意,TPUv4 采用 7nm 工艺,表中 45nm 的数据仅用于对比(3, 16)。
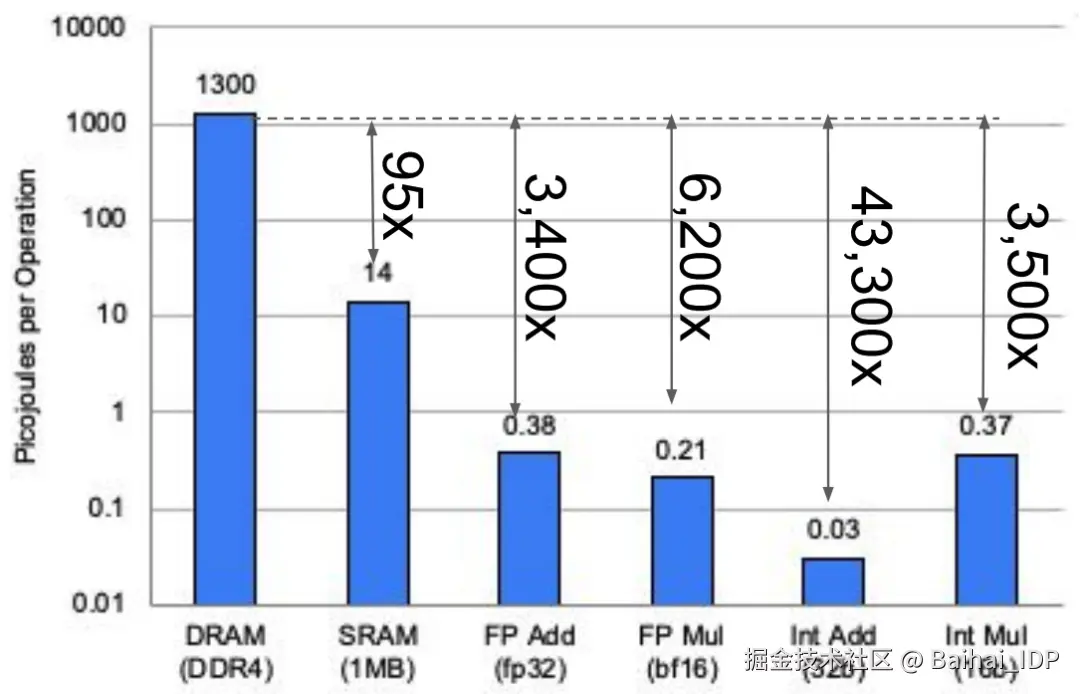
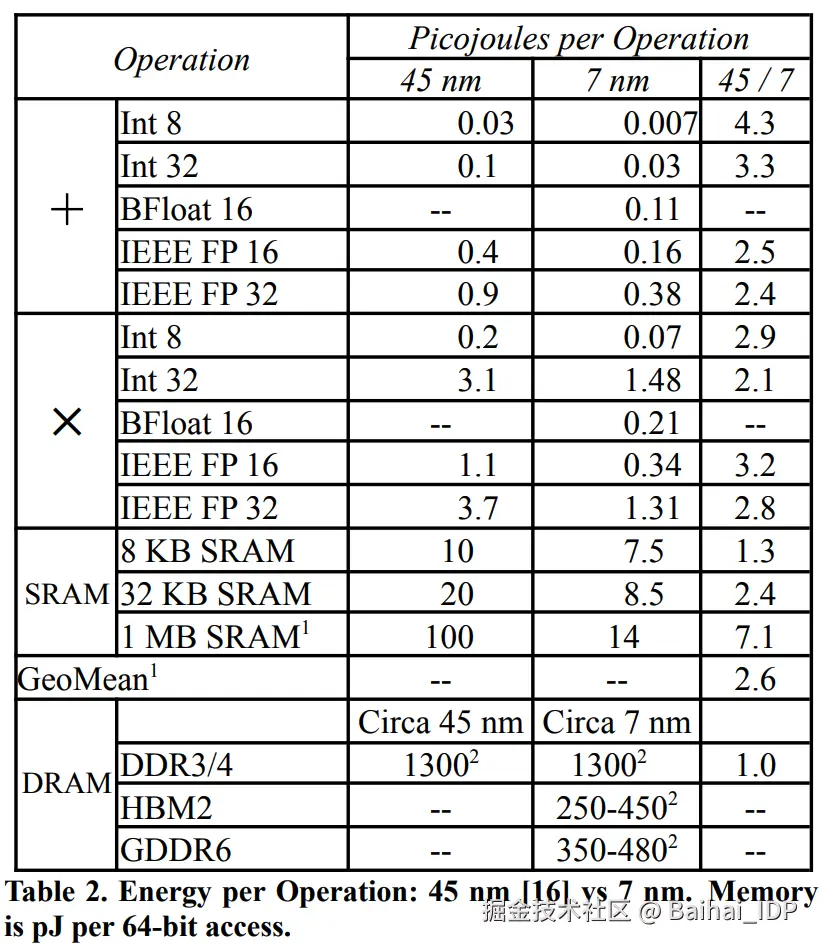
单次操作能耗对比(TPUv4, 7 nm)
上方的柱状图展示了具体数值,但需注意,现代芯片采用的是 HBM3 内存,其能耗远低于本图表中显示的 DDR3/4 DRAM。尽管如此,该图仍表明内存操作的能耗仍高出计算操作数个数量级。
这恰与 scaling laws 形成呼应:我们非常乐意通过增加浮点运算量(FLOPS)来换取更少的内存操作。因此减少内存操作能带来双重优化收益------不仅提升程序运行速度,还可显著降低能耗。
04 TPU 的多芯片互联层级结构
现在升级到更高层级,观察 TPU 在多芯片环境中的运作方式。
4.1 托盘层级(即"板卡";含4个芯片)
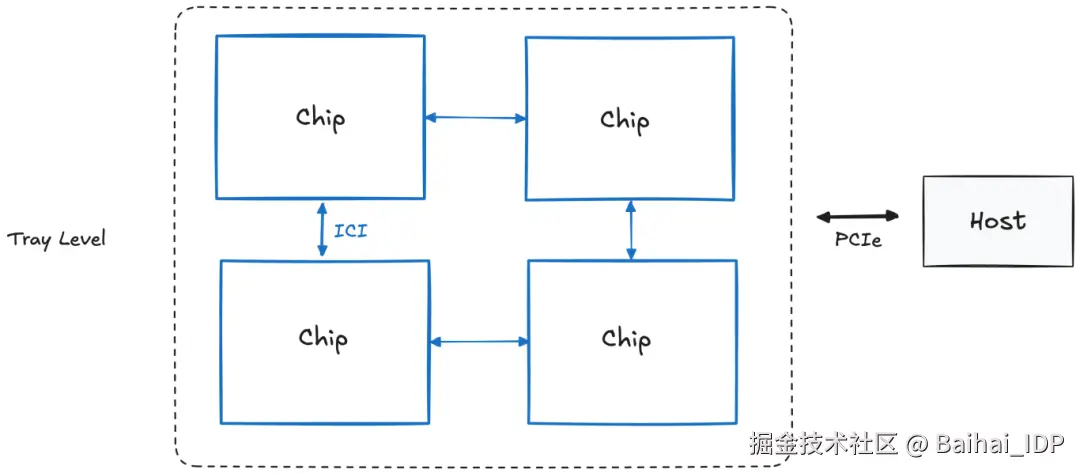
单块 TPU 托盘包含 4 个 TPU 芯片或 8 个 TensorCore(简称"核心")。每块托盘配备独立 CPU 主机(注:推理型 TPU 的每个主机可访问 2 块托盘,因其每芯片仅含 1 个核心)。
主机(Host) ⇔ 芯片(Chip)的连接采用 PCIe 接口,但芯片(Chip)⇔芯片(Chip)之间通过 Inter-Core Interconnect(ICI)连接,该接口具备更高带宽。
不过 ICI 连接还可进一步扩展至多块托盘。为此,我们需要继续提升到机架层级(Rack level)。
4.2 机架层级(4x4x4 芯片)
TPU 最令人兴奋的特性在于其可扩展性,这一点从机架层级开始显现。
一个 TPU 机架包含 64 个 TPU 芯片,通过 4x4x4 三维环面网络互联。如果您看过谷歌的 TPU 宣传资料(如下图),这张图展示的是 8 个 TPU 机架的集群。

8 个 TPU 机架(TPUv4)
但在深入讨论机架之前,我们需要澄清几个容易混淆的术语:机架(Rack)、Pod 和切片(Slice)的区别。
问:TPU 机架、TPU Pod 和 TPU 切片有何不同?
不同谷歌资料对这些术语的使用存在差异,有时甚至混用"TPU Pod"和"TPU Slice"。本文采用谷歌 TPU 论文和 GCP 官方文档的定义(379):
1)TPU 机架(Rack)
- 包含 64 块芯片的物理单元,也称为"立方体(cube)"。
2)TPU Pod
- 通过 ICI 和光纤连接的 TPU 最大单元。
- 又称"Superpod"或"Full Pod"。例如 TPUv4 的 TPU Pod 包含 4096 块芯片(或 64 个机架)。
3)TPU 切片(Slice)
- 介于 4 块芯片到 Superpod 规模之间的任何 TPU 配置组合。
主要区别在于,TPU 机架和 TPU Pod 是物理计量单位,而 TPU 切片是抽象计量单位。当然,TPU 切片的设置涉及重要的物理拓扑约束,但现阶段我们暂不展开讨论。
现在,我们将聚焦物理计量单位:TPU 机架和 TPU Pod。这是因为,理解 TPU 系统的物理连接方式,能更深入地掌握其设计哲学。
现在回到 TPUv4 机架的具体结构:
单个 TPU 机架通过 ICI 和 OCS(Optical Circuit Switching)技术连接 64 个芯片。实质上,我们通过组合多个托盘(trays)来构建一个 64 芯片的完整系统。这种"将小型单元组装成超级计算机"的设计理念将持续贯穿后续层级。
下图展示了 TPUv4 单个机架的拓扑结构。它采用 4x4x4 三维环面网络,其中每个节点都代表一块芯片,蓝色箭头表示 ICI 链路,而各个面上的连接线则代表 OCS(根据文献 7 重绘)。

使用 OCS 的 TPU 单机架架构
然而,这张图表引出了两个关键问题:为何 OCS 仅应用于环面结构的表面?换句话说 ------ 使用 OCS 的核心优势是什么?共有三大核心优势,我们将在后文再详述另外两点。
OCS 的优势 #1:环绕连接 (Wraparound)
通过环形拓扑优化节点间的通信效率。
OCS 还承担特定 TPU 配置的环绕连接功能。该设计将两节点间的跳数从最坏情况下 N-1 跳降至每轴 (N-1)/2 跳,因为每条轴均形成一个环形(一维环面拓扑)。
随着规模的进一步扩大,这种影响变得更加重要,因为降低芯片间的通信延迟对于高度并行化的实现至关重要。
附注:并非所有 TPU 都采用 3D 环面拓扑
注意,早期 TPU(如 TPUv2/v3)及推理专用 TPU(如 TPUv5e/v6e)使用 2D 环面拓扑而非下文所述的 3D 环面。不过 TPUv7"Ironwood" 虽定位为推理芯片,但其拓扑疑似 3D 环面(注:仅根据官方宣传材料推测)。
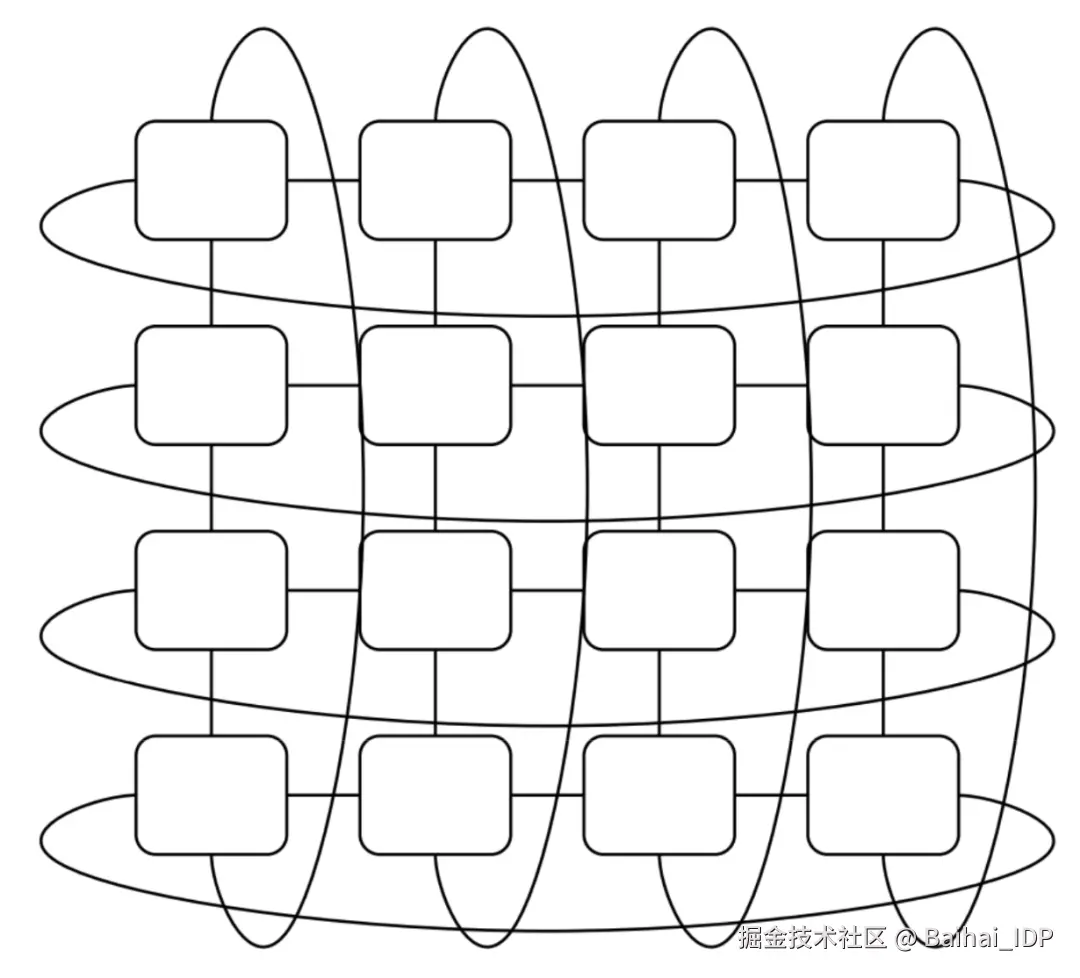
2D环面拓扑示意图
4.3 Full Pod 层级(又称 "Superpod";TPUv4 为 4096 块芯片)
正如我们通过互联多个芯片构建 TPU 机架,我们也可连接多个机架组成大型 Superpod。
Superpod 特指仅通过 ICI 和 OCS 互联的最大 TPU 集群规模。虽然存在 multi-pod 层级,但这种层级需依赖更慢速的连接方式,后续将展开说明。
芯片数量会因版本不同而变化,但 TPUv4 的芯片数量为 4096(即 64 个 4x4x4 芯片的机架)。最新的 TPUv7 "Ironwood" 则高达 9216 块芯片。
下图展示了 TPUv4 的一个 Superpod:
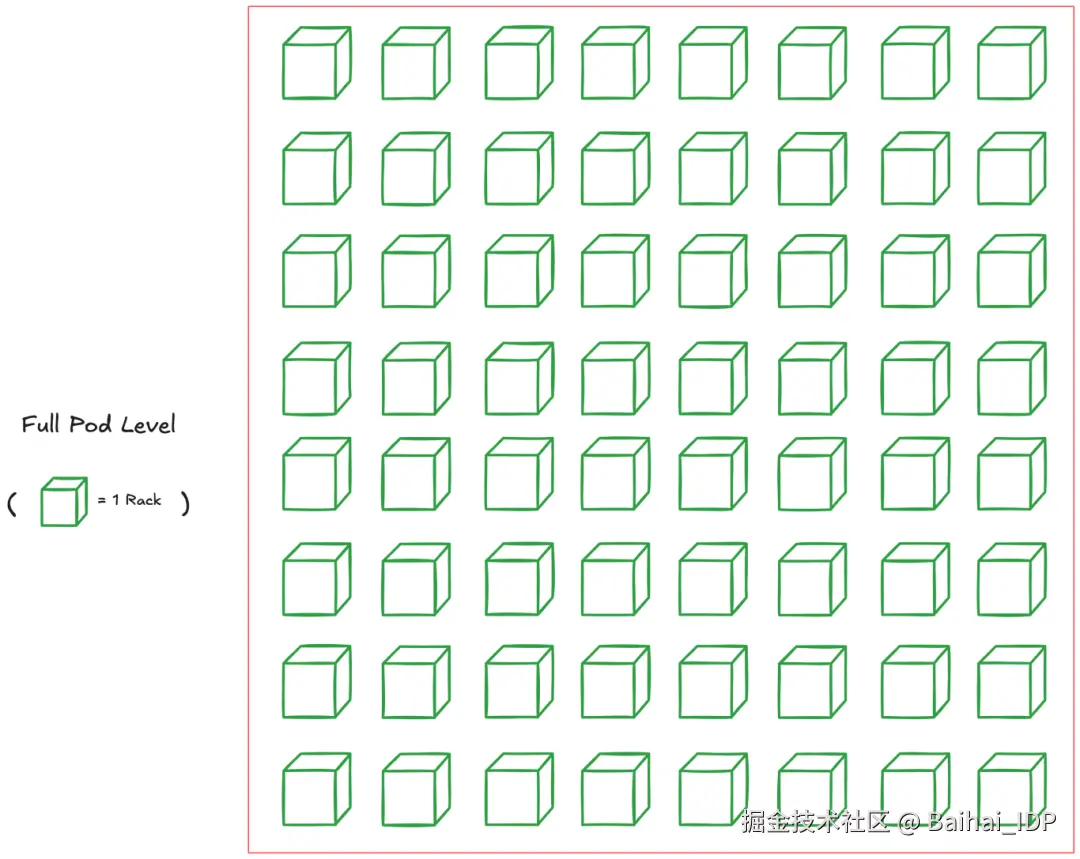
TPUv4 Superpod 架构(64 个机架)
请注意,每个立方体(即 TPU 机架)是如何通过 OCS 相互连接的,这种设计也支持在 Pod 内灵活划分 TPU 切片。
采用 OCS 的 TPU 切片
我们可在 Pod 内申请 TPU 子集,即 TPU 切片。但即使所需芯片数(N)相同,也存在多种拓扑结构可供选择。
例如,若总共需要 512 块芯片,可选择立方体(8x8x8)、条状拓扑(4x4x32)或矩形拓扑(4x8x16)。选择切片的拓扑结构本身就是一个超参数。
所选拓扑结构直接影响节点间通信带宽,进而影响各类并行策略的性能表现。
以立方体结构(如8x8x8)为例,它特别适合需要全连接通信的并行计算模式,比如数据并行或张量并行,因为这种拓扑结构能提供最高的二分带宽(bisection bandwidth)。而条状结构(如4x4x32)则更适用于流水线计算,这种布局可以让顺序排列的计算层之间实现更快速的数据传输(前提是单个计算层能够适配 4x4 芯片的子切片配置)。

典型 TPU 拓扑示例
当然,最优拓扑取决于具体模型结构,其寻优过程本身即是一门学问。TPUv4 论文9实测表明,拓扑优化可大大提升吞吐量(注:我不确定第一行指的是哪种 LLM 架构,因为没有具体说明)。
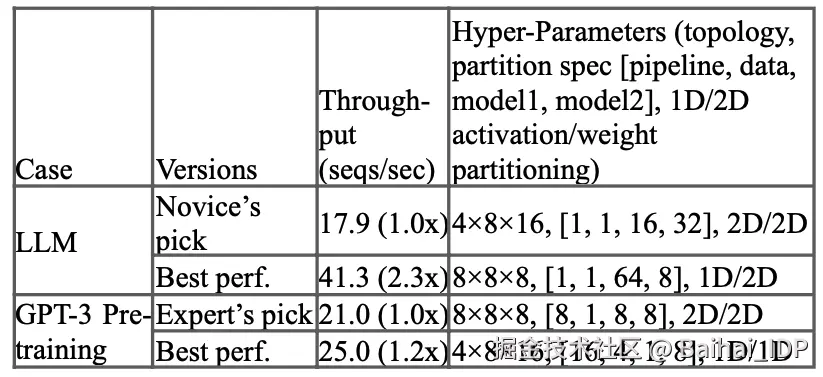
不同拓扑结构的吞吐量优化对比
前文阐述了 TPU 切片,但另有一项重要的特性有助于提高 TPU 的运行稳定性。
借助 OCS 技术,这些切片无需占据物理连续的机架空间。这正是 OCS 的第二大优势 ------ 可能也是其最大优势,但我们此前尚未展开讨论。
OCS 的优势 #2:可重新配置的非连续多节点切片
需注意,这不同于将多个节点硬连在一起来模拟非连续切片。由于 OCS 采用光交换技术而非硬连线架构,跨节点间的物理线缆数量大幅减少,从而支持更大规模的集群扩展(即可构建超大规模 TPU Pod)。
这样就可以进行灵活的节点规模配置。例如,假设我们想在单个 Pod 上运行三个任务。虽然传统的调度方式不允许这样做,但 OCS 连接允许我们抽象出节点的物理位置,使整个 Pod 可视为一个"节点资源池"(根据参考文献6重绘)。
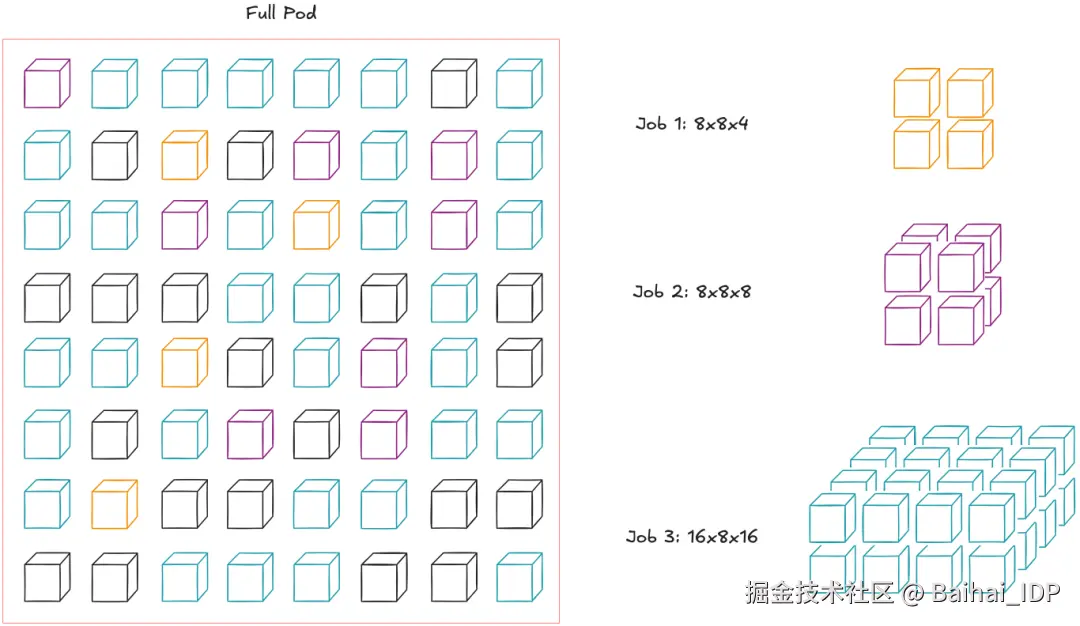
单任务可将 Pod 内机架视为"节点资源池"
此举不仅提高了 Pod 的利用率,而且能在节点出现故障的情况下简化维护流程。谷歌将其描述为"故障节点的影响范围很小"。但尚不确定其液冷系统在部分节点停机时如何运作。
最后,这种灵活的 OCS 还有项延伸应用:我们还可以改变 TPU 切片的拓扑结构(例如将规则环面调整为扭曲环面)。
OCS 的优势 #3:扭曲环面拓扑
此前我们通过改变固定芯片数量下的 (x,y,z) 维度来实现不同的 TPU 切片拓扑结构。本节则聚焦固定维度配置,通过改变布线方式构造新型拓扑。
典型案例如下:将常规条状环面改造为扭曲条状环面。

常规环面 vs 扭曲环面(来源:TPUv4论文9)
扭曲环面拓扑结构能加速扭曲二维平面上的芯片之间的通信,该特性对提升全局通信效率尤其有用。
下文将深入分析其具体应用场景。
使用扭曲环面加速训练
理论上,扭曲环面对张量并行(TP)的加速效益最大,因为每层涉及多次 all-gather 和 reduce-scatter 操作。对数据并行(DP)也有适度提升,因为每个训练步需执行 all-reduce 操作,但发生频率较低。
想象一下,假设我们训练一个标准的仅解码器架构的 Transformer 模型,并采用多种并行策略来加速训练。下面我们将看到两种场景:
场景 #1:4x4x16 拓扑结构(TP+PP;共 256 块芯片)
设定 z 轴为流水线(PP)维度,二维 TP 维度为 4x4。本质上,假设第 k 层位于 z=k 平面,且每层分片至 16 块芯片。若未明确绘制,默认采用 OCS 最近邻连接。
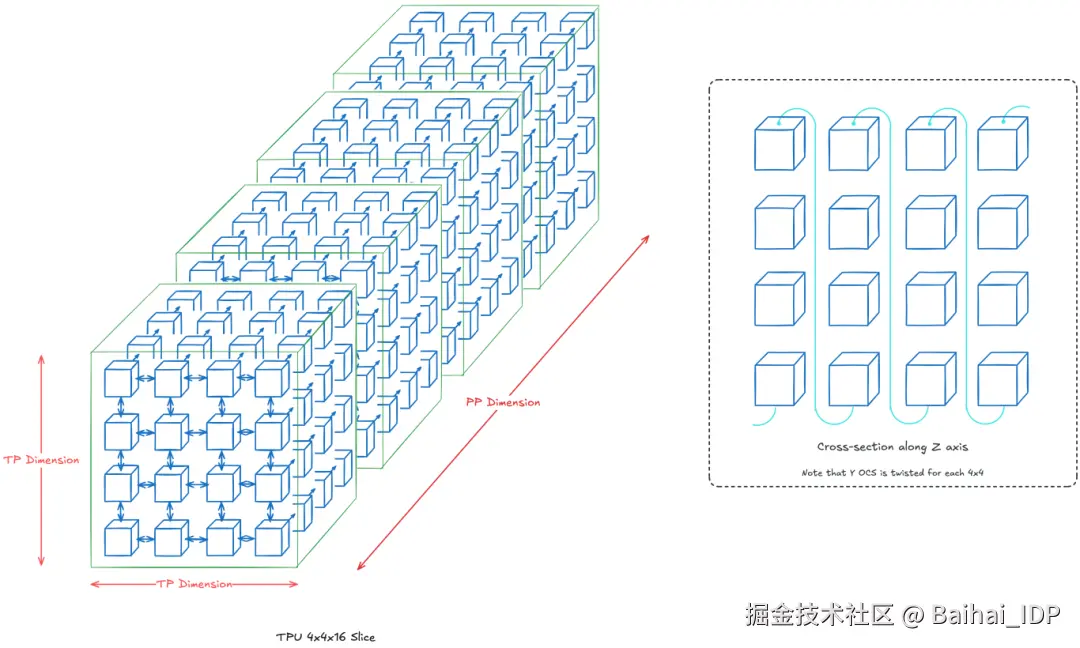
TP+PP 的 4x4x16 拓扑架构
通过在每个 z=k 平面实施 2D 环面扭曲,可加速 TP 层内芯片通信。由于 PP 层主要依靠点对点通信,因此没有必要沿 PP 层扭曲。
注:实际应用中,扭曲环面在芯片数>4x4 时效益显著。本示例使用 4x4 仅出于可视化的目的。
场景 #2:16x4x16 拓扑(DP+TP+PP;共 1024 块芯片)
作为延伸方案,我们在前一场景基础上增加 DP 维度(x 轴 4 个实例),即沿 x 轴部署 4 组场景 #1 的模型。

DP+TP+PP 的 16x4x16 拓扑架构
请注意,扭曲环面仅应用于每个 DP 模型内的每个 TP 维度(即对每个 z=k 平面实施 4x4 二维扭曲,k 取值 1...16)。DP 维度仅维持基础的环绕连接,使每行构成长度为 16 的水平环。
你可能已经发现还有一种拓扑结构方案(如 8x8x16,即 2x2 DP 维度),但这会混合 DP 与 TP 维度 ------ 这就变得更加复杂了。具体来说,我们还不清楚如何在 y 轴构建 OCS 环绕连接的同时兼容各 TP 维度的扭曲环面?
4.4 Multi-Pod 层级(即"Multislice";TPUv4 支持 4096+ 块芯片)

TPU 层次结构的最终层级是 Multi-pod 架构。此时可将多个 Pod 视为一台大型机器,但 Pod 之间的通信需通过数据中心网络(DCN) 进行 ------ 其带宽低于 ICI。

通过 DCN 互联的双 Pod 架构 1
PaLM 模型即采用此方案进行训练。在 6144 个 TPUv4 芯片(2 个 Pod)上耗时 56 天完成。下图是 6 个 Pod 中的 TPU 任务分配情况:绿色为 PaLM 任务,红色为空闲状态,其余为其他任务。注意每个方格代表一个 4x4x4 的 TPU 芯片立方体。
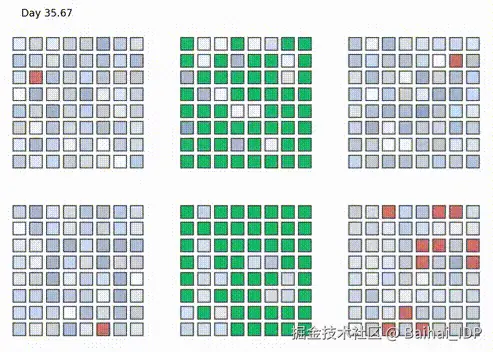
PaLM 训练过程中的 TPU Pod 利用率 6
实现这一架构已属不易,但更关键的是开发者体验设计,具体来说,就是要关注:如何实现模型扩展过程中系统/硬件层面的最大程度抽象化?
谷歌的解决方案是:由 XLA 编译器在大规模计算场景下协调芯片间的通信。研究人员只需配置相关参数(如 DP、FSDP、TP 等并行维度及切片数量),XLA 编译器即会根据当前 TPU 拓扑结构自动插入分层集合通信操作(Xu et al, 2021: GSPMD 2)。我们的目标是在尽可能少修改代码的情况下实现大规模训练。
例如,谷歌博客1展示了跨多 TPU 切片的 all-reduce 操作分解流程:

XLA 实现的跨 Pod All-Reduce 规约操作
这表明 XLA 编译器可以同时处理切片内与切片间的集合通信操作。
举个具体例子,在训练模型时,TPU 的拓扑结构可能如下所示。激活值的通信在切片内通过 ICI 进行,而梯度的通信则需跨切片通过 DCN 完成(即在 DCN 的 DP 维度上)1。

05 实物图示对照解析
结合硬件实拍图理解架构图会更直观,以下为综合解析。
若看过谷歌 TPU 宣传资料,可能见过下图:
8 个 TPU 机架(TPUv4)
此图为 8 个 TPU Pods 的集群,每个单元即前述的 4x4x4 三维环面架构。一个 Pod 中的每一行有 2 个托盘,这意味着每一行有 8 个 TPU 芯片。
单块 TPUv4 托盘实拍图:

请注意,图中简化为只有一个 PCIe 端口,但实际托盘上有 4 个 PCIe 端口(在左侧) ------ 每个 TPU 一个。
单芯片结构图:

TPUv4 芯片:中央是 ASIC + 4 组 HBM 内存堆栈
中央区域为 ASIC 芯片,周围 4 个区块为 HBM 内存堆栈。因 TPUv4 内含 2 个 TensorCore,故配置 4 组 HBM 内存堆栈。
未找到 TPUv4 芯片平面图,此处展示结构近似的 TPUv4i(推理芯片),其仅含 1 个TensorCore3:

可见 CMEM(芯片内存)在 TPUv4i 的布局中占据了相当大的空间。
06 致谢
感谢 Google TPU Research Cloud(TRC)提供的 TPU 资源支持!
References
1 Google Blog: TPU Multi-Slice Training(cloud.google.com/blog/produc...
2 Xu, et al. "GSPMD: General and Scalable Parallelizaton for ML Computation Graphs"(arxiv.org/pdf/2105.04...
3 Jouppi et al. "Ten Lessons From Three Generations Shaped Google's TPUv4i"(gwern.net/doc/ai/scal...
4 How to Scale Your Model - TPUs(jax-ml.github.io/scaling-boo...
5 Domain Specific Architectures for AI Inference - TPUs(fleetwood.dev/posts/domai...
6 HotChips 2023: TPUv4(hc2023.hotchips.org/assets/prog...
7 Google Cloud Docs: TPUv4(cloud.google.com/tpu/docs/v4...
8 Jouppi et al. "In-Datacenter Performance Analysis of a Tensor Processing Unit" -- TPU origins paper(arxiv.org/abs/1704.04...
9 Jouppi et al. "TPU v4"-- TPUv4 paper(arxiv.org/abs/2304.01...
10 PaLM training video(www.youtube.com/watch?v=0yP...
11 HotChips 2021: "Challenges in large scale training of Giant Transformers on Google TPU machines"(hc33.hotchips.org/assets/prog...
12 HotChips 2020: "Exploring Limits of ML Training on Google TPUs"(hc32.hotchips.org/assets/prog...
13 Google Blog: Ironwood(blog.google/products/go...
14 HotChips 2019: "Cloud TPU: Codesigning Architecture and Infrastructure"(old.hotchips.org/hc31/HC31_T...
15 ETH Zurich's Comp Arch Lecture 28: Systolic Array Architectures(www.youtube.com/watch?v=Xkg...
16 Patterson presentation: "A Decade of Machine Learning Accelerators: Lessons Learned and Carbon Footprint"(www.cs.ucla.edu/wp-content/...
17 Camara et al. "Twisted Torus Topologies for Enhanced Interconnection Networks."(personales.unican.es/vallejoe/Pu...
18 Horowitz article: "Computing's Energy Problem(and what we can do about it)"(gwern.net/doc/cs/hard...
END
本期互动内容 🍻
❓您更倾向 TPU 的专用化路线(牺牲灵活性换取能效),还是 GPU 的通用化路线(保留灵活性但能耗较高)?请结合您的应用场景说明理由。
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接: