伙伴匹配系统(手机版) - 01
项目地址:
- Github:github.com/China-Rainb...
- Gitee:gitee.com/Rainbow--Se...
@toc
需求分析
- 用户去添加标签,标签的分类(要有哪些标签、怎么把标签进行分类)学习方向 java/c++,工作/大学
- 主动搜索:允许用户根据标签去搜索其他用户
- Redis 缓存
- 组队
- 创建队伍
- 加入队伍
- 根据标签查询队伍
- 邀请其他人
- 允许用户去修改标签
- 推荐
- 相似度计算算法+本地实时计算
技术栈
前端:
1.Vue 3 开发框架 (提高页面开发的效率)
- Vant UI (基于 Vue 的移动端组件库)(React 版 Zent)
3.Vite 2(打包工具,快!)181862491
4.Nginx来单机部署
后端:
- Java 编程语言+ SpringBoot 框架
- SpringMVC+ MyBatis + MyBatis Plus (提高开发效率)
- MySQL 数据库
- Redis 缓存
- Swagger + Knife4j 接口文档
前端项目初始化
脚手架初始化项目:
- Vue CLl: cli.vuejs.org/zh/ 或者是 : cn.vitejs.dev/guide/
- Vite 脚手架:vitejs.cn/guide/#scaf... (推荐)
shell
$ yarn create vite
shell
npm install # 安装相关依赖Vant : vant-ui.github.io/vant/v3/#/z...

shell
npm init vite@latest


shell
npm install # 安装相关依赖,注意需要在一个我们创建生成的一个目录位置下,就是我们当前这个项目名下。
执行该代码。
shell
npm run dev # 启动该项目
打开浏览器访问:测试
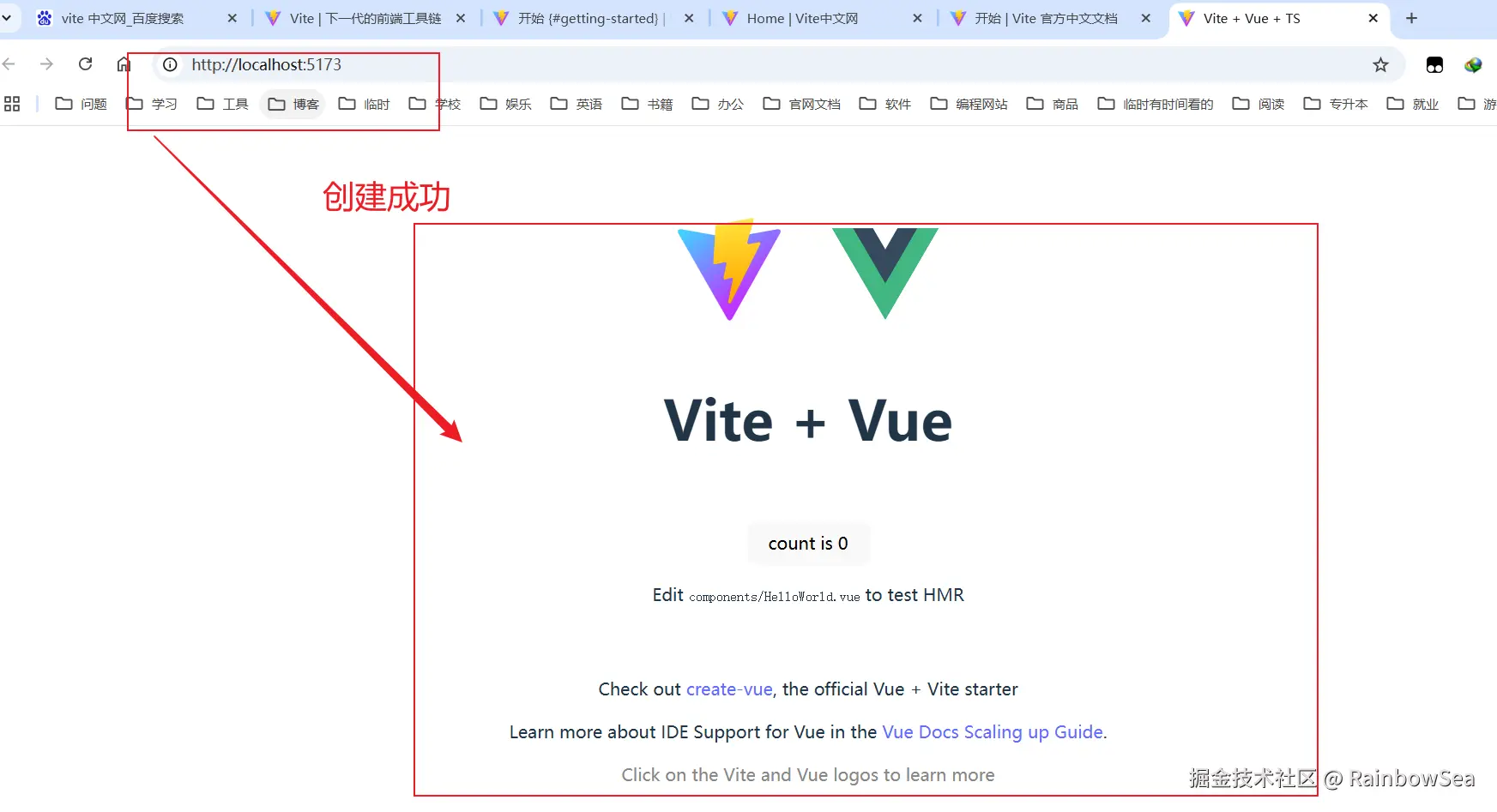

整合组件库:Vant:
- 安装 Vant
- 配置按需引入:
npm i vite-plugin-style-import@1.4.1 -D
shell
npm i vite-plugin-style-import@1.4.1 -D # 配置按需引入
- Vant3 官方地址:vant-ui.github.io/vant/v3/#/z...
- 或者是: www.w3cschool.cn/vant3/quick...
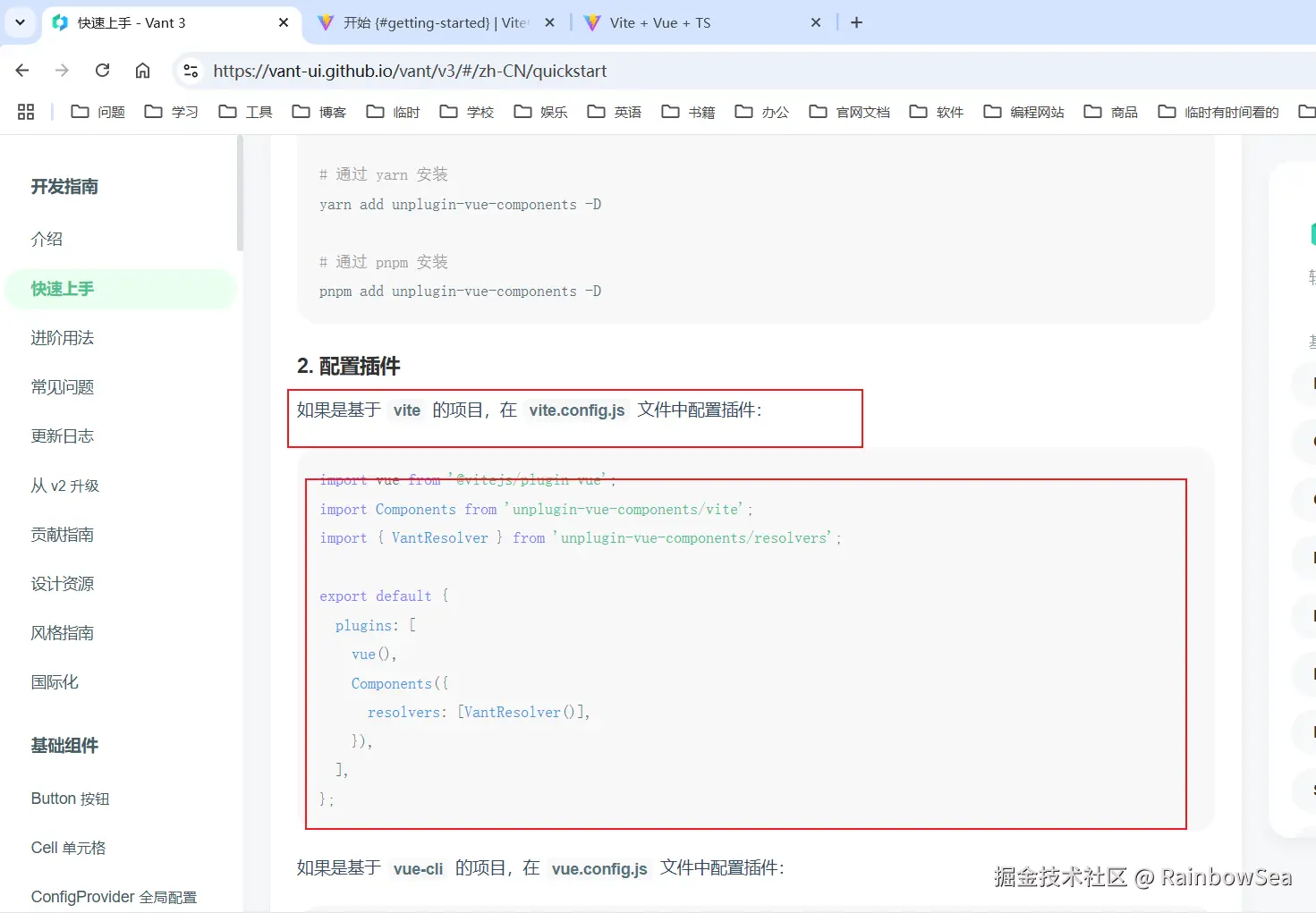
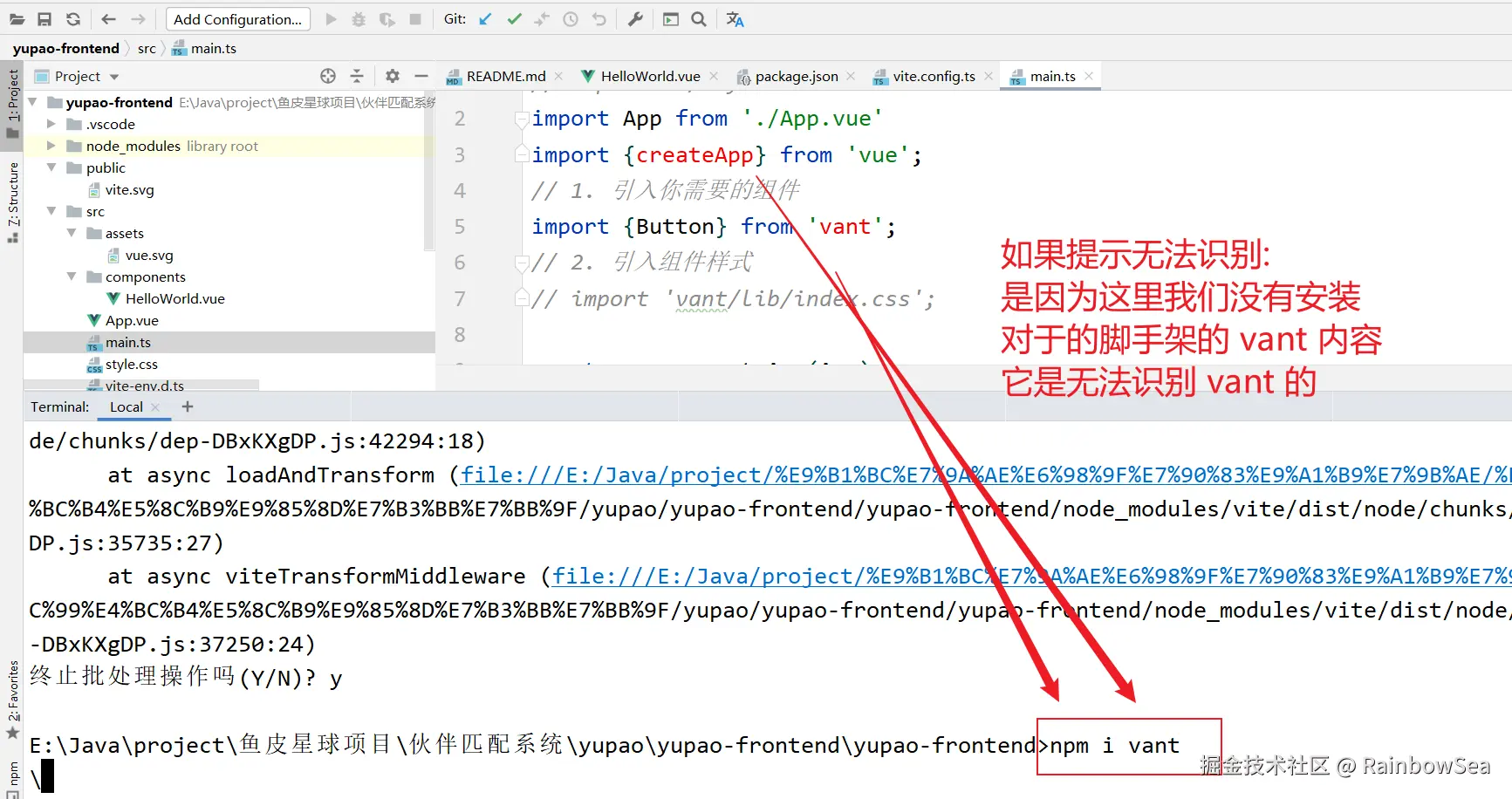
安装 Vant 插件
shell
npm i vant # 未安装 vant 是无法识别到 vant 的样式,组件内容的。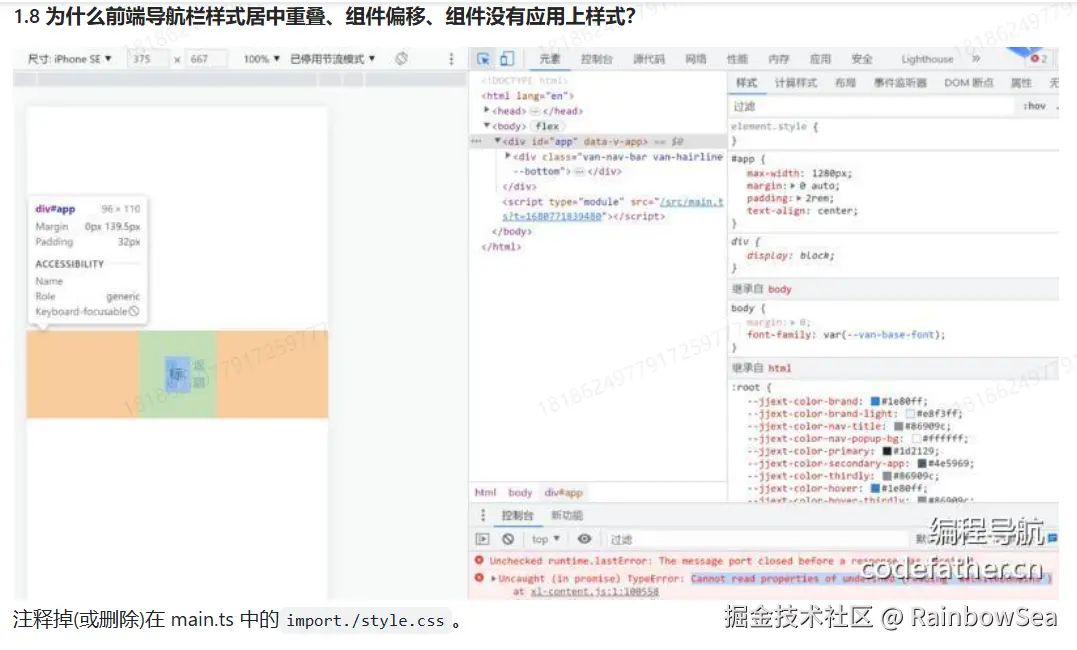
开发页面经验:
- 多参考
- 从整体到局部
- 先想清楚页面要做成什么样子,再写代码。
- 设计,尽量从小的屏幕上看,这样换成大的屏幕了,没什么问题,而如果从大的屏幕开始的话,切换成小的话,小的屏幕可能会少东西。
前端主页
如果存在广告的话,就一定要预留广告位置。
设计:
从上到下依次为:
- 导航条:展示当前页面的名称
- 主页搜索框:点击跳转到搜索页 => 搜索结果页(标签筛选页)
- 内容展示
- tab 栏:
- 主页(推荐页+广告)
- 搜索框
- banner
- 推荐信息流
- 队伍页
- 用户页
- 主页(推荐页+广告)
开发:
很多页面复用组件/样式,重复写很麻烦,不利于维护,所以抽象一个通用的布局。可以定义在一个目录当中(layouts)
组件化
后端数据表设计
标签表(分类表)
建议用标签,不要用分类,更灵活
标签分类:这里暂定为 8 个标签
- 性别:男,女
- 方向:Java,C++,Go,前端
- 正在学:Spring
- 目标:考研,春招,秋招,社招,考公,竞赛(蓝桥杯),转行,跳槽
- 段位:初级,中级,高级,王者
- 身份:小学,初中,高中,大一,大二,大三,大四,学生,待业,已就业,研一,研二,研三
- 状态:乐观,有点丧,一般,单身,已婚,有对象
- 还可以支持用户自己定义标签
表设计:
id int 主键
标签名 varchar 非空 ( 必须唯一,唯一索引)
上传标签的用户 userId int (如果要根据 userId 查已上传的标签的话,最好加上,普通索引)
父标签 id,parentId,int(分类)
是否为父标签 isParent tinyint(0 不是父标签,1- 父标签),布尔类型,只有两个,可能不太够,这里用 tinyint 0-255 来替换。
创建时间 createTime,datetime
更新时间 updateTime datetime
是否删除:isDelete tinyint(0,1)
sql
create table tag
(
id bigint auto_increment comment 'id'
primary key,
tagName varchar(256) null comment '标签名称',
userId bigint null comment '用户id',
parenId bigint null comment '父标签 id',
isParent tinyint null comment '0 - 不是, 1- 父标签',
createTime datetime default CURRENT_TIMESTAMP null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP null comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除 0 1(逻辑删除)'
)
comment '标签';
-- 为 user 表,添加上一个新的 tags 字段
alter table user add column tags varchar(1024) null comment '标签列表';验证表设计,是否合理
对于自己设计的数据表,是否合理,可以通过,反向验证,反向思考。
主要思考该设计能不能满足业务操作诉求。
比如:这里:
- 怎么查询所有标签,并且把标签分好组
按父标签 Id 进行分组,能实现
- 根据父标签查询子标签?
根据 id 查询,能实现
用户表
思考: 怎么给用户表补充标签。
一定要根据自己的实际需求来
常见方案有 2 种:
- 直接在用户表补充 tags 字段,格式为
json 字符串,比如:"java","男"。注意:json 当中字符串,是使用双引号的。
优点: 查询方便,不用新建关联表,标签是用户的固有属性(除了该系统,其他系统可能要用到,标签是用户的固有属性) 节省开发成本。
缺点: 根据标签查用户时,只能用模糊查询,或者遍历用户列表,性能不高。
- 加一个关联表,记录用户和标签的关系
关联表的优点(适用场景):查询灵活,可以正查,反查
提示:企业大项目开发中尽量减少关联查询,因为关联查询很是影响扩展性(比如:新建一张表,记录关系),而且会影响查询性能。
第一种方式:如果慢了,可以用缓存。
优化:这里我们会经常对标签名。
- 标签名:必须唯一,唯一索引。
- 上传标签的用户(可以添加上一个普通索引)
- 父标签,本身就没多少个,这里就不加索引了。
sql
-- 用户
-- auto-generated definition
create table user
(
username varchar(256) null comment '用户昵称',
id bigint auto_increment comment 'id'
primary key,
userAccount varchar(256) null comment '账号',
avatarUrl varchar(1024) null comment '用户头像',
gender tinyint null comment '性别',
userPassword varchar(512) not null comment '密码',
phone varchar(128) null comment '电话',
email varchar(512) null comment '邮箱',
userStatus int default 0 not null comment '状态-0-正常',
createTime datetime default CURRENT_TIMESTAMP null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP null comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除 0 1(逻辑删除)',
userRole int default 0 not null comment '用户角色 0- 普通用户 1 - 管理员 2 - vip',
planetCode varchar(512) null comment '用户的编号',
tags varchar(1024) null comment '标签列表 json'
)
comment '用户';开发后端接口:标签搜索用户功能
面试点:
按标签搜索用户:
- 允许用户传入多个标签,多个标签都存在才搜索出来 and 。方法执行 SQL 语句:like '%Java%' and like '%C++%'
- 允许用户传入多个标签,有任何一个标签存在就能搜索出来 or。like '%Java%' or like '%C++%'
2 种实现方式:
- SQL 查询:实现简单,可以通过拆分查询进一步优化。
- 内存查询:灵活,可以通过并发进一步优化。就是查询出来后,通过 steam 进行处理,过滤。
方案选择:
- 如果参数可以分析,根据用户的参数去选择查询方式,比如标签数。可以两种方式一起,根据参数,if 用 SQL else 用内存
- 如果参数不可分析,并且数据库连接足够,内存空间足够,可以并发同时查询(10 个并发处理),然后,谁先返回用谁。
- 还可以 SQL 查询与内存计算相结合,比如先用 SQL 过滤掉部分 tag 。
建议通过实际测试来分析,那种查询比较快,数据量大的时候验证效果更明显。
判断点:
- 谁返回快就用谁。
- 根据数据量去选择查询方式。
方式一:SQL 查询:实现简单,可以通过拆分查询进一步优化。
java
/**
* 根据标签搜索用户
*
* @param tagNameList 用户要拥有的标签
* @return List<User>
*/
@Override
public List<User> searchUserByTags(List<String> tagNameList) {
// 方式1: SQL 查询:实现简单,可以通过拆分查询进一步优化。
if (CollectionUtils.isEmpty(tagNameList)) {
throw new BusinessException(ErrorCode.PARAMS_ERROR);
}
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
//// 拼接 and 查询
//// like '%Java%' and like '%C++%'
for (String tagName : tagNameList) {
// // column 是数据表当中的字段名,不可以随便写
queryWrapper = queryWrapper.like("tags", tagName);
}
//
List<User> userList = userMapper.selectList(queryWrapper);
//
//// 使用 stream 进行过滤显示
return userList.stream().map(this::getSafetyUser).collect(Collectors.toList());
}方式二:内存查询:灵活,可以通过并发进一步优化。就是查询出来后,通过 steam 进行处理,过滤。
java
package com.rainbowsea.yupao.service.impl;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.google.gson.Gson;
import com.google.gson.reflect.TypeToken;
import com.rainbowsea.yupao.common.ErrorCode;
import com.rainbowsea.yupao.exception.BusinessException;
import com.rainbowsea.yupao.model.User;
import com.rainbowsea.yupao.service.UserService;
import com.rainbowsea.yupao.mapper.UserMapper;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.stereotype.Service;
import org.springframework.util.CollectionUtils;
import org.springframework.util.DigestUtils;
import javax.annotation.Resource;
import javax.servlet.http.HttpServletRequest;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
import static com.rainbowsea.yupao.contant.UserConstant.USER_LOGIN_STATE;
/**
* @author huo
* @description 针对表【user(用户)】的数据库操作Service实现
* @createDate 2025-04-14 16:03:21
*/
@Service
@Slf4j
public class UserServiceImpl extends ServiceImpl<UserMapper, User>
implements UserService {
@Resource
private UserMapper userMapper;
/**
* 根据标签搜索用户
*
* @param tagNameList 用户要拥有的标签
* @return List<User>
*/
@Override
public List<User> searchUserByTags(List<String> tagNameList) {
// 方式1: SQL 查询:实现简单,可以通过拆分查询进一步优化。
if (CollectionUtils.isEmpty(tagNameList)) {
throw new BusinessException(ErrorCode.PARAMS_ERROR);
}
// 方式2: 内存查询:灵活,可以通过并发进一步优化。就是查询出来后,通过 steam 进行处理,过滤。
// 1. 先查询所有用户
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
List<User> userList = userMapper.selectList(queryWrapper);
Gson gson = new Gson();
// 2. 在内存中判断是否包含要求的标签
return userList.stream().filter(user -> {
String tagsStr = user.getTags();
if(StringUtils.isBlank(tagsStr)) {
return false;
}
// 将 set 集合对象转换为 JSON 字符串
Set<String> tempTagNameSet = gson.fromJson(tagsStr,new TypeToken<Set<String>>(){}.getType());
for (String tagName : tagNameList) {
// 判断 set 集合当中是否含有该 tagName 标签,不含有该标签就返回 false 过滤掉
if(!tempTagNameSet.contains(tagName)) {
return false;
}
}
return true;
}).map(this::getSafetyUser).collect(Collectors.toList());
}
}
java
package com.rainbowsea.yupao.service.impl;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.google.gson.Gson;
import com.google.gson.reflect.TypeToken;
import com.rainbowsea.yupao.common.ErrorCode;
import com.rainbowsea.yupao.exception.BusinessException;
import com.rainbowsea.yupao.model.User;
import com.rainbowsea.yupao.service.UserService;
import com.rainbowsea.yupao.mapper.UserMapper;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.stereotype.Service;
import org.springframework.util.CollectionUtils;
import org.springframework.util.DigestUtils;
import javax.annotation.Resource;
import javax.servlet.http.HttpServletRequest;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
import static com.rainbowsea.yupao.contant.UserConstant.USER_LOGIN_STATE;
/**
* @author huo
* @description 针对表【user(用户)】的数据库操作Service实现
* @createDate 2025-04-14 16:03:21
*/
@Service
@Slf4j
public class UserServiceImpl extends ServiceImpl<UserMapper, User>
implements UserService {
@Resource
private UserMapper userMapper;
/**
* 根据标签搜索用户
*
* @param tagNameList 用户要拥有的标签
* @return List<User>
*/
@Override
public List<User> searchUserByTags(List<String> tagNameList) {
// 方式1: SQL 查询:实现简单,可以通过拆分查询进一步优化。
if (CollectionUtils.isEmpty(tagNameList)) {
throw new BusinessException(ErrorCode.PARAMS_ERROR);
}
//QueryWrapper<User> queryWrapper = new QueryWrapper<>();
//// 拼接 and 查询
//// like '%Java%' and like '%C++%'
//for (String tagName : tagNameList) {
// // column 是数据表当中的字段名,不可以随便写
// queryWrapper = queryWrapper.like("tags", tagName);
//
//}
//
//List<User> userList = userMapper.selectList(queryWrapper);
//
//// 使用 stream 进行过滤显示
//return userList.stream().map(this::getSafetyUser).collect(Collectors.toList());
// 方式2: 内存查询:灵活,可以通过并发进一步优化。就是查询出来后,通过 steam 进行处理,过滤。
// 1. 先查询所有用户
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
List<User> userList = userMapper.selectList(queryWrapper);
Gson gson = new Gson();
// 2. 在内存中判断是否包含要求的标签
return userList.stream().filter(user -> {
String tagsStr = user.getTags();
if(StringUtils.isBlank(tagsStr)) {
return false;
}
// 将 set 集合对象转换为 JSON 字符串
Set<String> tempTagNameSet = gson.fromJson(tagsStr,new TypeToken<Set<String>>(){}.getType());
for (String tagName : tagNameList) {
// 判断 set 集合当中是否含有该 tagName 标签,不含有该标签就返回 false 过滤掉
if(!tempTagNameSet.contains(tagName)) {
return false;
}
}
return false;
}).map(this::getSafetyUser).collect(Collectors.toList());
}
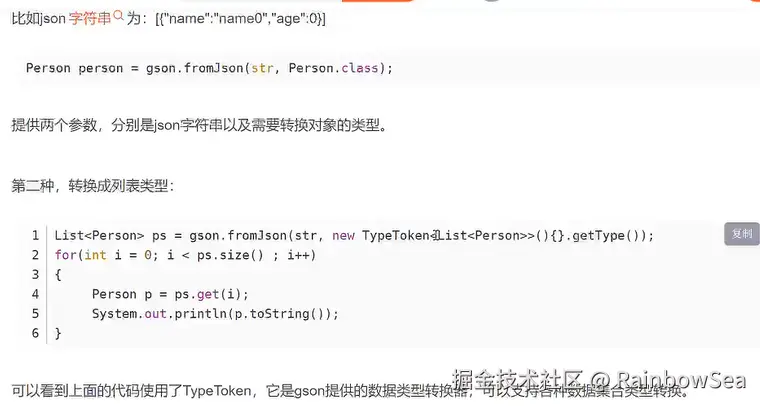
}小技巧:解析 JSON 字符串
序列化:Java 对象转成 JSON
反序列化:把 JSON 转为 Java 对象
Java json 序列化库有很多:
- gson (google 的,推荐)
- fastjson alibaba(阿里出品,快,但是漏洞太多)
- jackson
- kryo (性能极高的序列化库)
xml
<!-- Gson: Java to Json conversion JSON 转换-->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.5</version>
</dependency>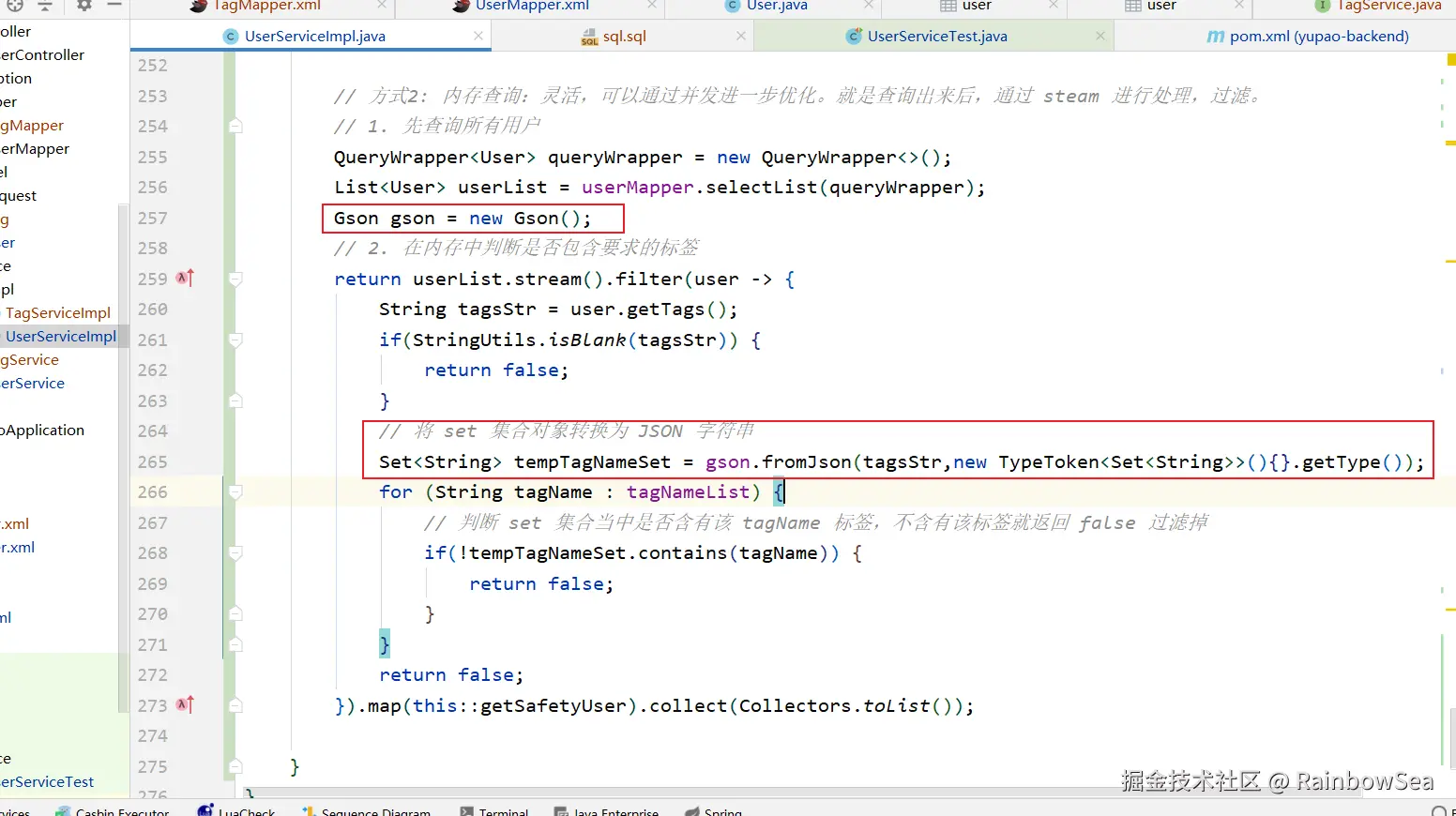
公共线程池,可能会存在问题,就是:当如果你的一个查询数据库的时候,都是耗光了这个公共线程池的话,那么就会存在问题:eg:Java 8 中的 ParalleStream 的坑
Java 8 特性:
- stream / parallelStream 流式处理
- Optional 可选类
前端整合路由
Vue-Router: router.vuejs.org/zh/guide/#h...
Vue-Router: 其实就是帮助你根据不同的 url 来展示不同的页面(组件),不用自己写 if / else
路由配置影响整个项目,所以建议单独用 config 目录,单独的配置文件去集中定义和管理。
有些组件库可能自带了和 Vue-Router 的整合,所以尽量先看组件文档,节省时间。
前端页面开发:标签搜索用户功能
最后:
"在这个最后的篇章中,我要表达我对每一位读者的感激之情。你们的关注和回复是我创作的动力源泉,我从你们身上吸取了无尽的灵感与勇气。我会将你们的鼓励留在心底,继续在其他的领域奋斗。感谢你们,我们总会在某个时刻再次相遇。"
