一、前言
在上一篇 《AI 应用开发入门:前端也可以学习 AI》中,我给大家分享了前端学习 AI 应用开发的入门相关知识。我相信很多同学,看完应该都有了一定的收获。未来我会把关于前端学习 AI 的文章都放在这个 《前端学习 AI 之路》 专栏进行更新~
本篇会更偏向实际的应用,我将会运用之前分享的技术和概念,给大家分享如何通过 nodejs + LLM 搭建一个简易的 AI Review 系统的。
在本篇你将收获到:
- 设计 AI 应用的思路
- 设计提示词的思路
- 如何用 NodeJS 结合 LLM 分析代码
二、背景
我相信大家在团队中,都会有 Code Review 这个流程。但是有时候随着人手不够、项目周期紧张,就会出现 review 流程被忽视、或者 review 质量不高的问题。于是,我就在想,是否可以把这种费时、费精力且需要专注的事情,交给一个专门的"AI 员工"去完成呢?答案是可以的。
三、整体效果
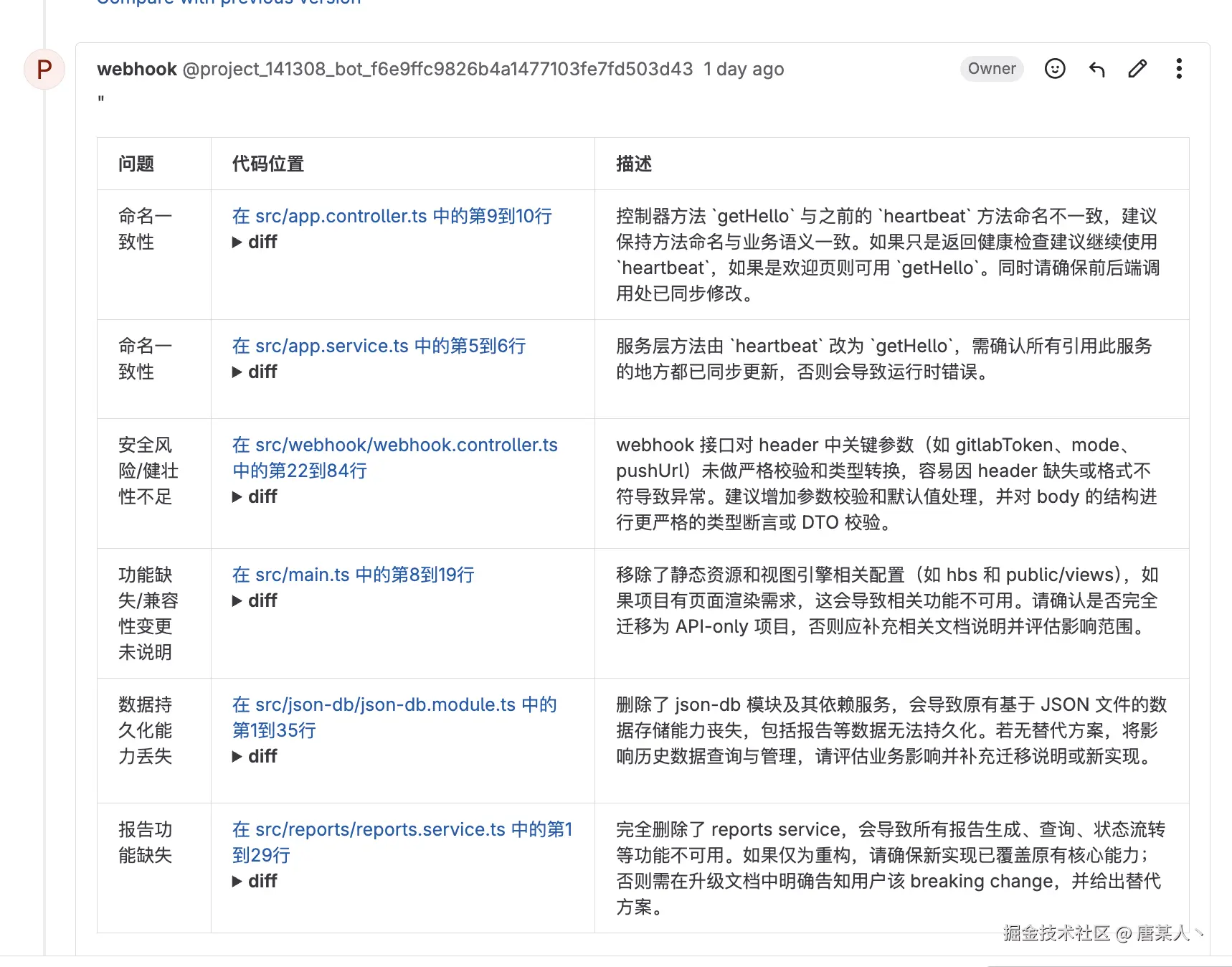
目前在我们团队,已经全面的在使用 AI 进行 Review 了,涵盖了前端、后端大大小小 20 + 的项目。得益于在集团内可以使用像("GPT-4.1、 Calude")这样更大上下文、更强推理能力的模型,所以整体效果是非常不错的。有时候一些很细微的安全隐患、性能、业务逻辑等问题,AI 都能比人更容易发现。
下面是我用演示的项目呈现的效果,也就是我们即将动手搭建的这个项目。
3.1 评论模式
通过 AI 分析提交的代码,然后会在有问题的代码下,评论出问题类型以及问题的具体原因。

3.2 报告模式
还一种是报告的展示形式。它会在提交的 MR 下输出一个评审报告,列出所有问题的标题、所在位置、以及具体原因。但是,这两种模式实现的本质都一样,只不过是展示结果的方式有不同,这个看你个人喜欢。

四、思路分析
那这个 AI Code Review 应用要怎么实现呢?下面给大家分享一下具体的思路。
4.1 人为流程
首先要做的,就是分析你现有团队人工 review 代码的规范,然后总结出一个具体流程 。为什么要这样做?因为让 AI 帮你做事的本质,就是让它模仿你做事。如果连你自己都不清楚具体的执行流程,就更别期待 AI 能把这个事情做好了。
下面是我举例的一个 review 流程,看完后你可以思考一下,自己平时是怎么 review 代码的,有没有一个固定的流程或者方案。如果有,则按照下面的这个"行为 + 目的"的格式记录下来。
- 行为:收到的 MR 的提示了;目的:知道有需要 review 的 MR 提交

- 行为:查看 commit message;目的:确认本次提交的主题是什么。

- 行为:查看改动哪些文件;目的:确认改动范围,主要判断改了哪些业务模块、是否改了公共、或者高风险文件等
- 行为:查看文件路径;目的:确认该文件关联的业务、所属的模块等信息,当做后续 diff 评审的前置判断信息。

- 行为:查看 diff 内容;目的:判断改动代码的逻辑、安全、性能是否存在问题。结合相关的业务和需求信息,判断是否有实现不合理的地方。
- 行为:在有问题的相关代码下,发出评论;目的:在有问题的代码下面,给出修改建议,让开发的同事能够注意和修改一下当前的问题。
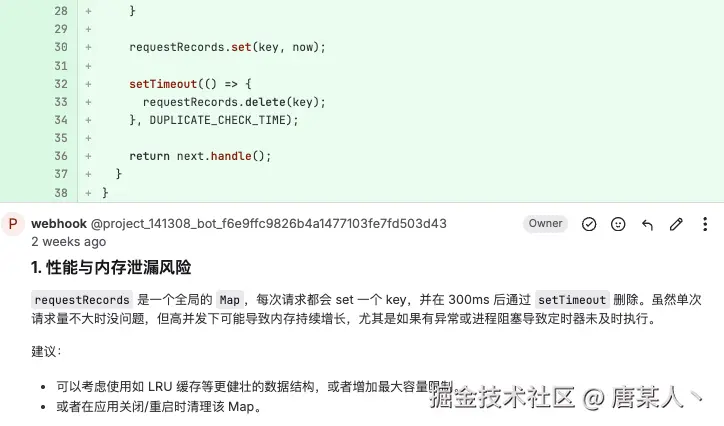
4.2 程序流程
上面列举的是一个完整的人为评审代码的流程。但是,如果想让 AI 完全模仿,其实是存在一定的复杂性的。比如,人在评审某处 diff 时,会思考关联的业务、模块等前置信息,然后再做出评论。而不单单只是评审代码表面的编码问题。如果想要 AI 也这样做,还需要引入 RAG 等相关的技术,目的则是为了补充给更多的上下文信息。
为了不增加大家的实现和理解难度,本篇我们实现的是一个简化版本的 AI Code Review。下面是我梳理的 review 流程和与之对应的 AI 应用流程。

4.2 核心问题
这次搭建的 AI Code Review 应用,本质上是一个 NodeJS 服务。这个服务通过感知 MR 事件,获取 diff 交给 LLM 分析,得到结论以后,会输出评论到 GitLab。整体流程图如下:
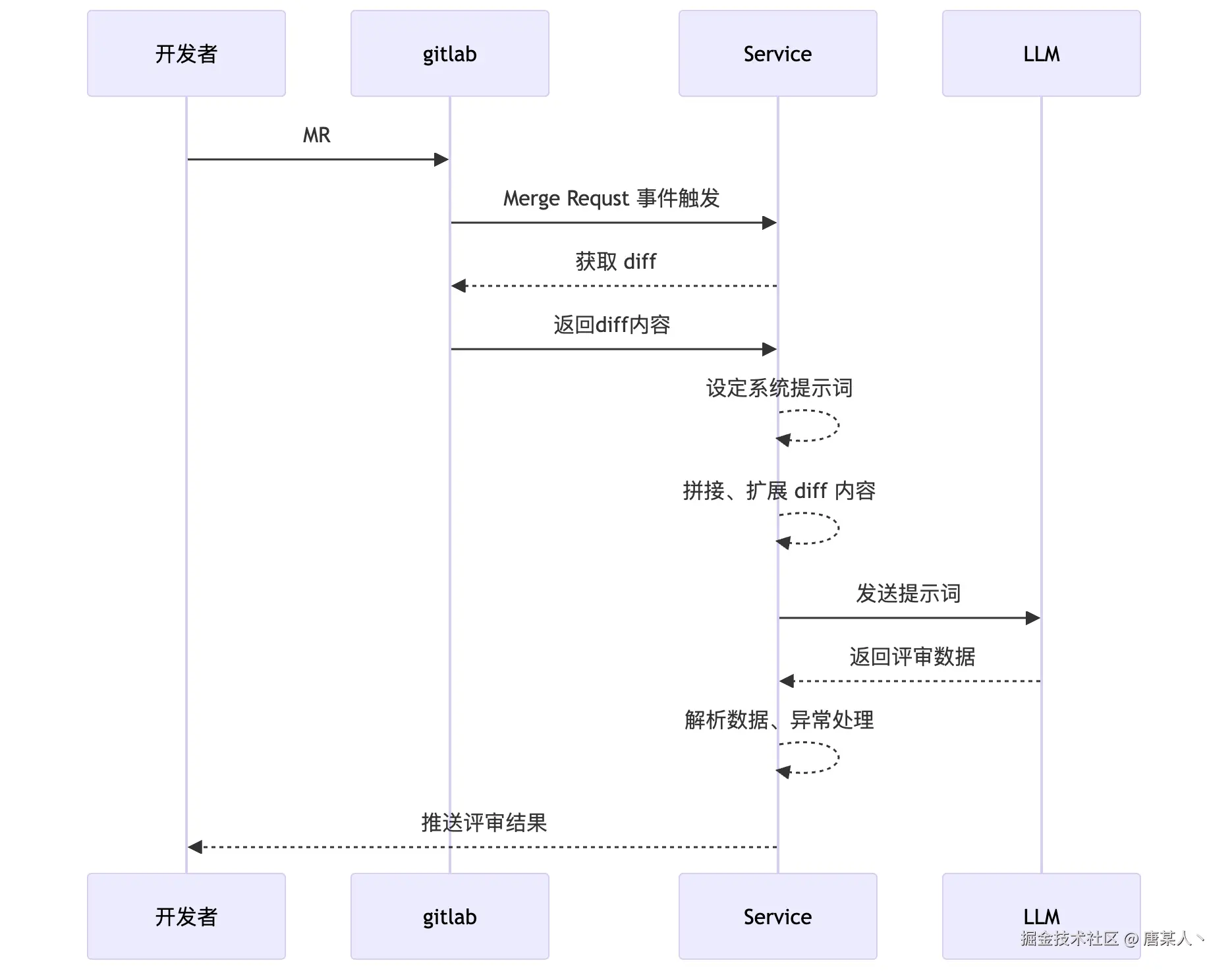
所以,我们要面对这些核心问题是
- node 服务如何感知 GitLab 的 MR 提交
- 如何获取 MR 中每个文件改动的 diff
- 如何让编写提示词,让大模型评审和分析并输出结构化的数据
- 如何解析数据以及异常的处理
- 如何发送评论到 gitlab
- 如何推送状态到企微
接下来,我们带着上面的问题,来一步步实现这个 AI Code Review 应用。
五、具体实现
5.1 创建项目
创建一个 NestJS 的项目(用什么技术框架都可以,你可以使用你最熟悉的 Node 开发框架。重点是关注实现的核心步骤和思路,这个演示的项目我开源了,可以在 GitHub 上查看完整的代码)
bash
nvm use 20使用 nest 命令初始化一个项目
bash
nest new mr-agent5.2 实现 webhook 接口
首先我们来解决 node 服务如何感知 MR 事件的问题
Webhook
像 GitLab、GitHub 都会允许用户在项目中配置 webhook。它是干嘛的呢? webhook 可以让外部的服务,感知到 git 操作的相关事件(如 push 、merge 等事件)。比如我在合并代码时,gitlab 就会把 MR 事件,通过这个 hook 发送到我们搭建的服务上。

以 GitLab 为例,它会允许开发者在每个项目中配置多个 webhook 接口。比如,咱们配置一个 http://example.com/webhook/trigger 的地址。当发生相关 git 事件时,GitLab 就会往这个地址推送消息。

代码实现
所以,我们要做的第一件事,就是定义一个接口 url,用于接收 GitLab 的 webhook 事件。下面的代码中,实现了一个处理/webhook/trigger路由的 controller,它的主要职责是接收 MR 事件并且解析 body 和 header 中的参数,代码如下(完整代码)
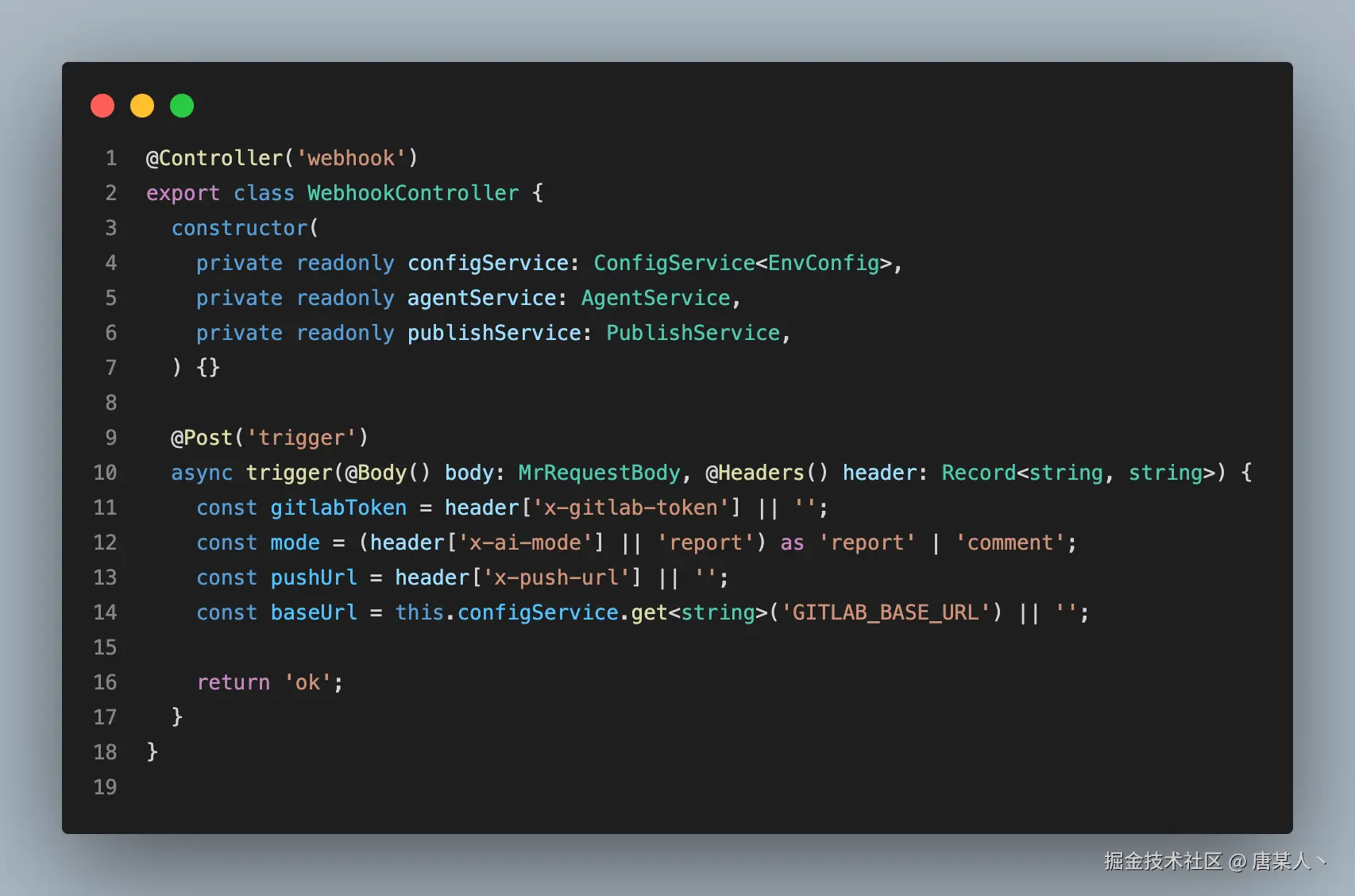
Body
body 中会包含很多有用的的信息,如 Git 仓库信息、分支信息、MR 信息、提交者信息等,这些数据是 GitLab 调用 webhook 接口时发送过来的,在后续的逻辑中,都会用到里面的数据。
- object_type/object_kind:描述的事件的类型,例如 merge 事件、push 事件等。
- project:主要是描述仓库相关的信息,例如项目 id、名称等
- object_attributes: 主要包含本次 MR 相关的信息,如目标分支、源分支、mr 的 id 等等
- user:提交者的信息
Header
header 中是我们自己目定义的配置信息,核心有三个
- x-ai-mode:评论的模式(report 报告模式、 comment 评论模式)
- x-push-url:用于推送状态的地址(推送到企微、或者飞书的机器人)
- x-gitlab-token:gitlab 中的 access token,用于后续 GitLab API 调用鉴权

调试问题
调试开发的这个接口确实是一个比较麻烦的问题。因为 GitLab 基本都是内网部署,想要真实调试接口,一是需要真实代码仓库,二是需要想办法把 GitLab 的请求转发到本地来。这里我给大家分享三个办法:
内网转发
使用内网转发的办法,第三方的例如 ngrok 、localtunnel 、frp 等。如果你们公司的部署平台本身支持流量转发到本地,那就更好了(我用的是这个办法)。
ApiFox、Postman
先将服务部署到你们公司 GitLab 可以访问的服务器上,手动触发 MR 事件
然后在日志上打印完整的 header 和 body,然后复制到 ApiFox、Postman 上在本地模拟请求
问 AI
😁 最后一个办法就是,根据你的场景,问问 AI 怎么做 
5.3 获取 diff 内容
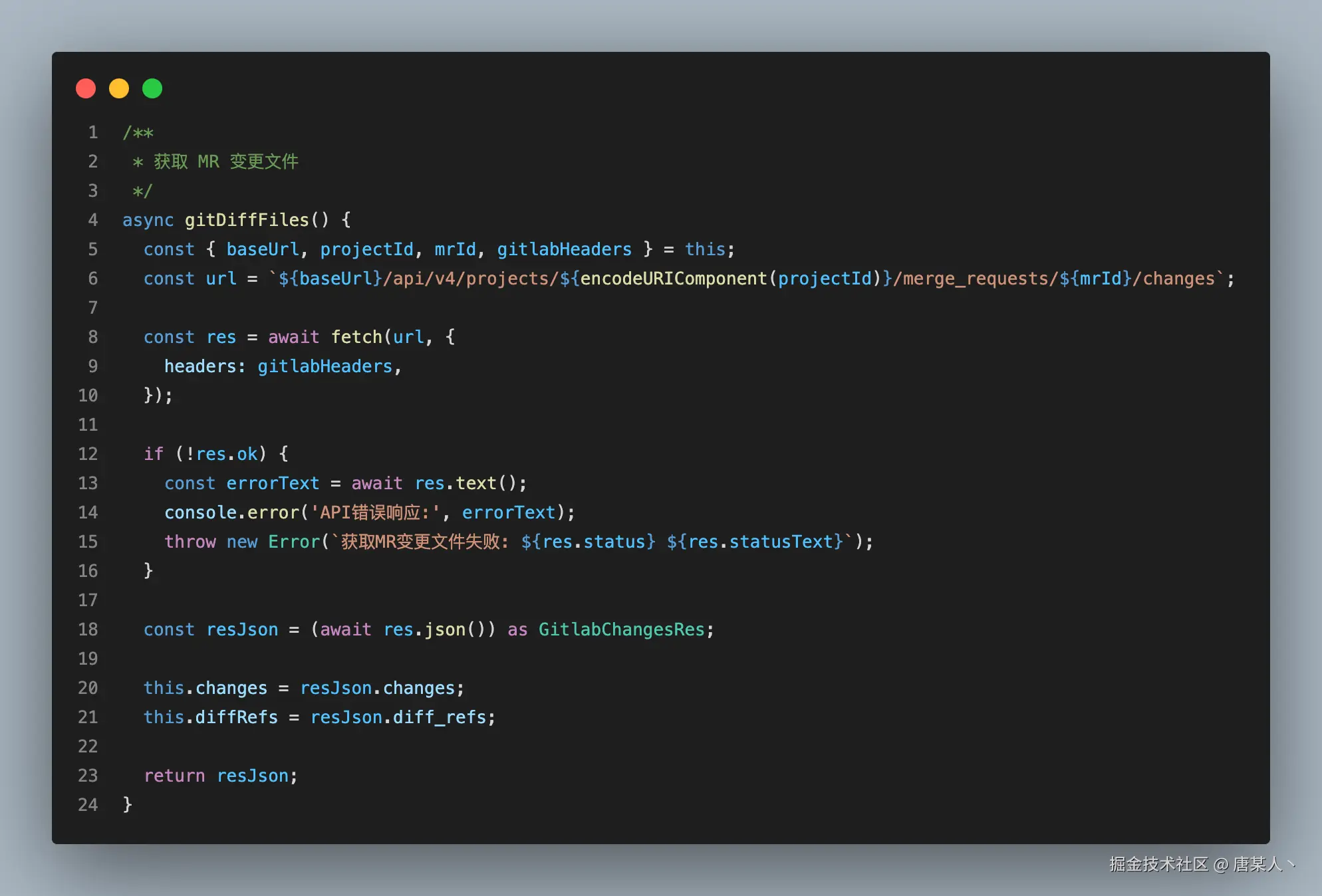
在能够接受到 GitLab 发送的 MR 事件后,就要解决如何获取 diff 的问题。这一步很简单, 调用 GitLab 官方的 API 就可以。重点就是两个核心逻辑:
- 获取全部文件的 diff 内容
- 过滤非代码文件

获取 diff 内容
gitlab 的 api 路径一般是一样的。唯一的区别就是不同公司的部署域名不同。baseUrl 需要配置成你公司的域名,projectId 和 mrId 都可以在 body 中取到(完整代码)
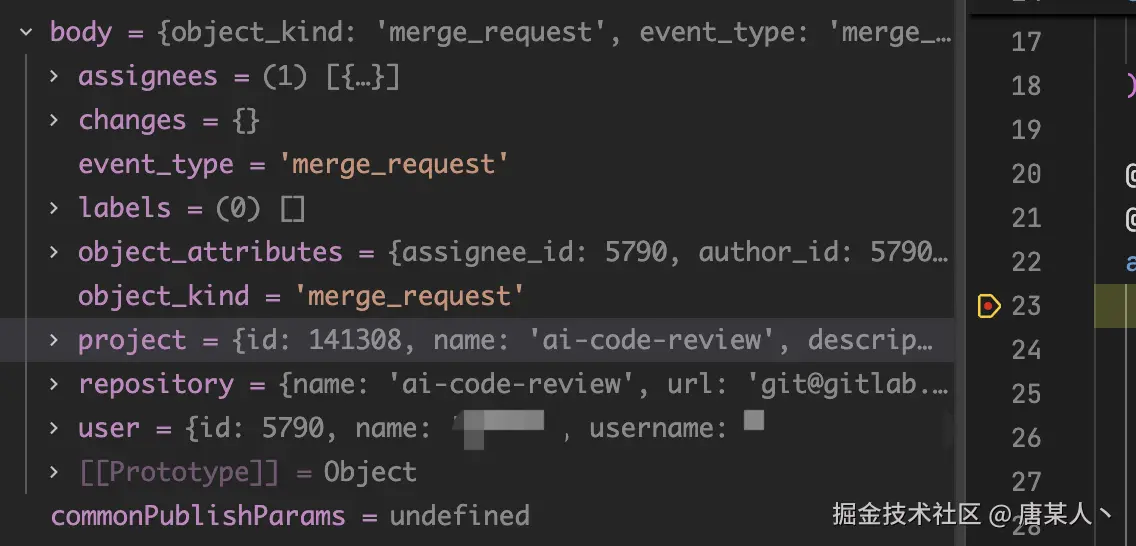
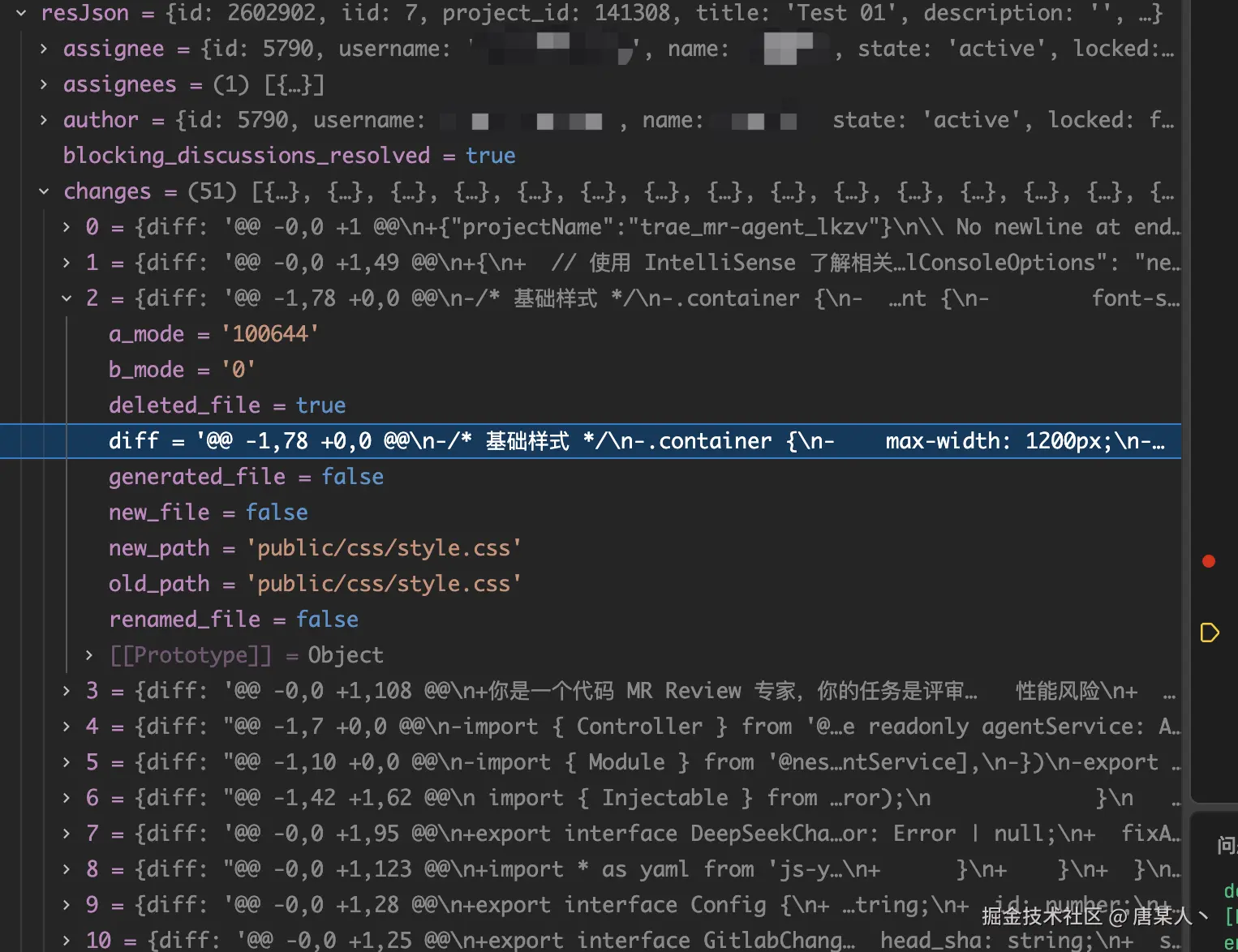
调用成功以后,获取的数据如下,changes 中会包含每个文件的 diff
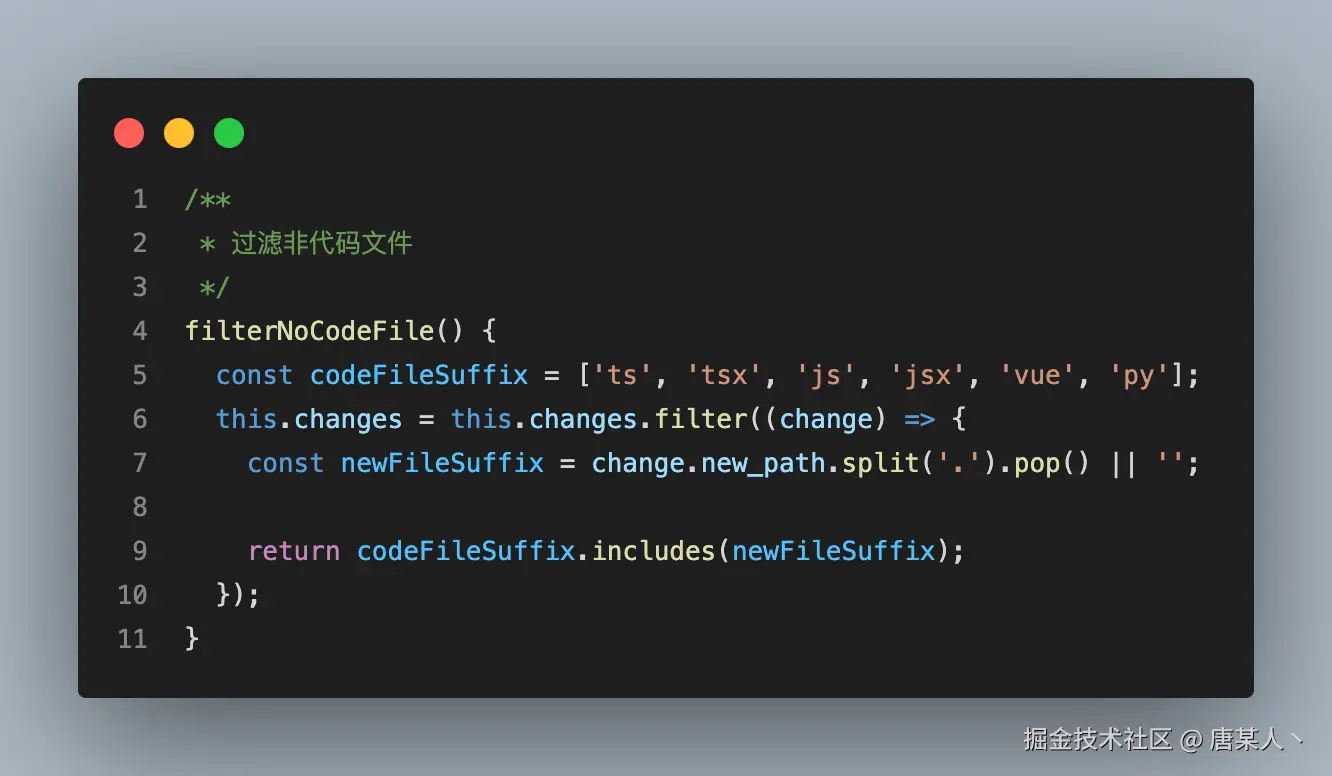
过滤文件
因为并不是所有的文件都需要让 LLM 进行 review ,例如像 package.json、package-lock.json 等等。所以需要把这部分非代码文件过滤出来。
5.4 设计提示词
有了每个文件的 diff 数据以后,就是解决如何分析 diff 内容并输出有效结论的问题。其实这个问题的本质,就是如何设计系统提示词。
提示词思路
首先我们先思考一下编写提示词的目的是什么?我们期望的是,通过提示词指引 LLM,当输入 diff 文本的时候,它能够分析里面的代码并输出结构化的数据。
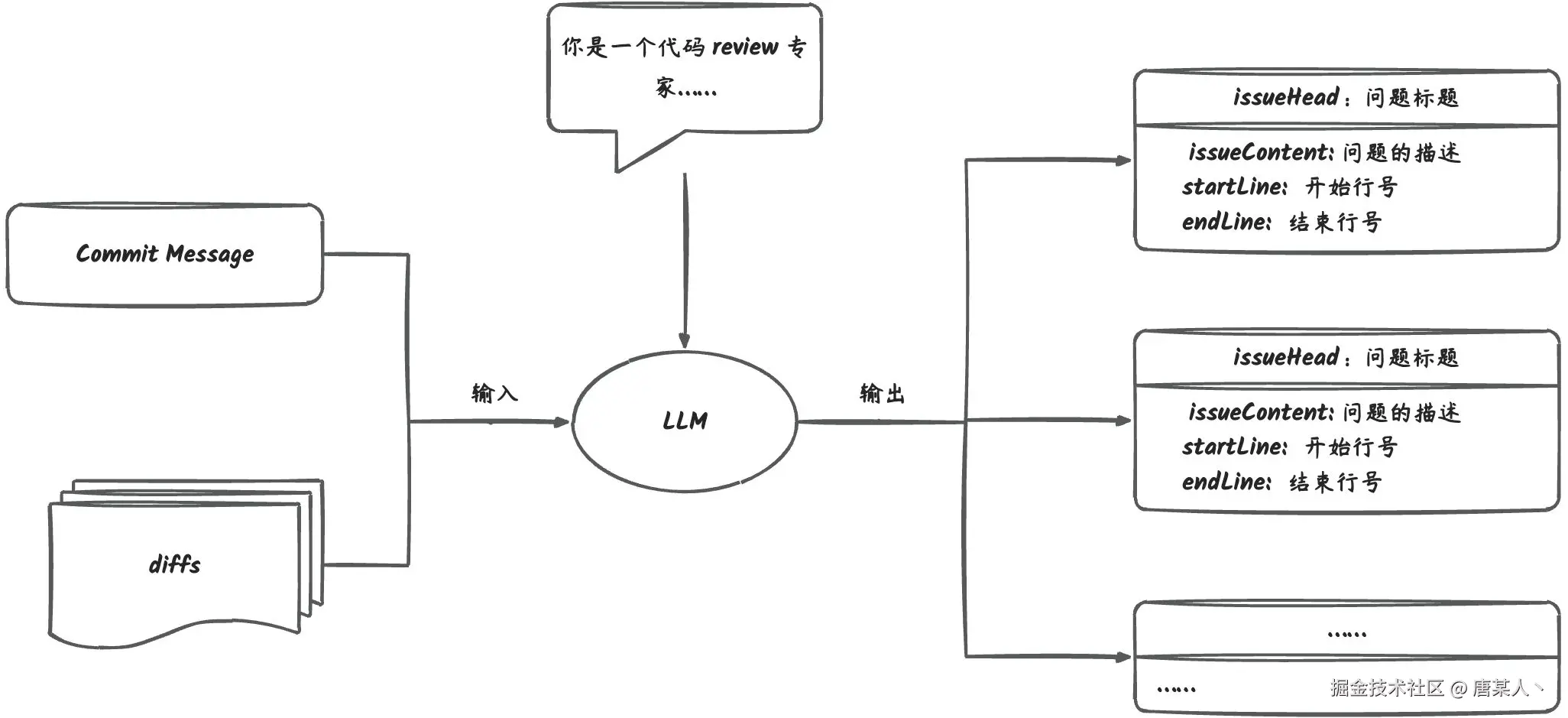
我们希望 LLM 返回的是一个数组,数组的每一项是对每一个问题的描述,里面包含标题、文件路径、行号、具体的内容等,数据结构如下:
typescript
interface Review {
// 表示修改后的文件路径
newPath: string;
// 表示修改前的文件路径
oldPath: string;
// 表示评审的是旧代码还是新代码,如果评审的是 + 部分的代码,那么 type 就是 new,如果评审的是 - 部分的代码,那么 type 就是 old。
type: 'old' | 'new';
// 如果是 old 类型,那么 startLine 表示的是旧代码的第 startLine 行,否则表示的是新代码的第 startLine 行
startLine: number;
// 如果是 new 类型,那么 endLine 表示的是旧代码的第 endLine 行,否则表示的是新代码的第 endLine 行
endLine: number;
// 对于存在问题总结的标题,例如(逻辑错误、语法错误、安全风险等),尽可能不超过 6 个字
issueHeader: string;
// 清晰的描述代码中存在、需要注意或者修改的问题,并给出明确建议
issueContent: string;
}
interface MRReview {
reviews: Review[];
}之所以需要这种结构化的数据,是因为后续在调用 GitLab API 发送评论的时候,需要用到这些参数。
整体思路确定好了,接下来我们就来编写具体的系统提示词。
角色设定
角色设定就是告诉 LLM 扮演什么角色以及它的具体要做什么事情
markdown
你是一个代码 MR Review 专家,你的任务是评审 Git Merge Request 中提交的代码,如果存在有问题的代码,你要提供有价值、有建设性值的建议。
注意,你评审时,应重点关注 diff 中括号后面带 + 或 - 的代码。输入内容
上面有说到,我们不仅需要 LLM 分析代码的问题,还需要它把问题代码所在的文件路径、行号分析出来。
但是,如果你直接把原生的 diff 内容输入给它,它是不知道这些信息。因为原生的 diff 并没有具体的行号、新旧文件路径信息的。
diff
@@ -1,16 +1,13 @@
import { Injectable } from '@nestjs/common';
-interface InputProps {
- code_diff: string;
- code_context: string;
- rules?: string;
-}
+type InputProps = Record<string, any>;
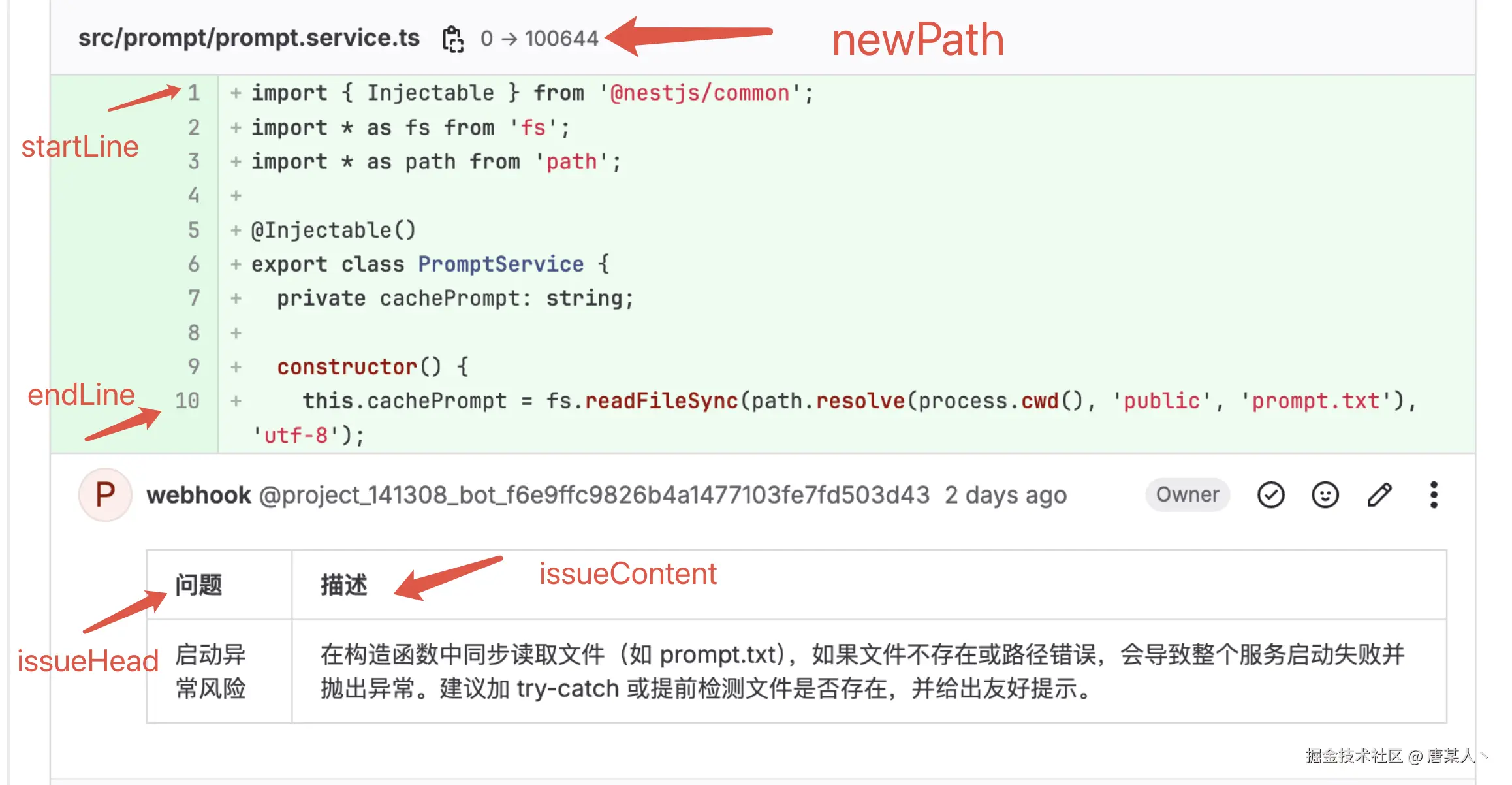
interface CallDifyParams {所以我们需要扩展输入的 diff,给它增加新旧文件的路径、以及每一行具体的行号,例如 (1, 1) 表示的是当前行,是旧文件中的第 1 行,新文件中的第 1 行。这个后面会说如何扩展,这里我们只是要先设计好,并告诉 LLM 我们会输入什么格式的内容
diff
## new_path: src/agent/agent.service.ts
## old_path: src/agent/agent.service.ts
@@ -1,16 +1,13 @@
(1, 1) import { Injectable } from '@nestjs/common';
(2, 2)
(3, ) -interface InputProps {
(4, ) - code_diff: string;
(5, ) - code_context: string;
(6, ) - rules?: string;
(7, ) -}
( , 8) +type InputProps = Record<string, any>;
(9, 9)
(10, 10) interface CallDifyParams {有了这些完善的信息,LLM 才知道有问题的代码在哪个文件以及它所在的具体行号
加解释
diff 经过我们的扩展以后,就不再是标准的描述 diff 的 Unified Format 格式了,所以必须向 LLM 解释一下格式的含义,增强它对输入的理解,避免它随便臆想。
markdown
我们将使用下面的格式来呈现 MR 代码的 diff 内容:
## new_path: src/agent/agent.service.ts
## old_path: src/agent/agent.service.ts
@@ -1,16 +1,13 @@
(1, 1) import { Injectable } from '@nestjs/common';
(2, 2)
(3, ) -interface InputProps {
(4, ) - code_diff: string;
(5, ) - code_context: string;
(6, ) - rules?: string;
(7, ) -}
( , 8) +type InputProps = Record<string, any>;
(9, 9)
(10, 10) interface CallDifyParams {
- 以 "## new_path" 开头的行内容,表示修改后的文件路径
- 以 "## old_path" 开头的行内容,表示修改前的文件路径
- @@ -1,16 +1,13 @@ 是统一差异格式(Unified Diff Format)中的hunk header,用于描述文件内容的具体修改位置和范围
- 每一行左侧括号内的两个数字,左边表示旧代码的行号,右边表示新代码的行号
- 括号后的 + 表示的是新增行
- 括号后的 - 表示的是删除行
- 引用代码中的变量、名称或文件路径时,请使用反引号(`)而不是单引号(')。加限制
加限制的主要目的是指引 LLM 按照固定的数据类型进行输出。这里我们会告诉 LLM 具体的 TS 类型,避免它输出一些乱七八糟的类型,导致后续在代码中解析和使用的时候报异常。例如,数字变成字符串、字符串变成数组等。
markdown
你必须根据下面的 TS 类型定义,输出等效于MRReview类型的YML对象:
```ts
interface Review {
// 表示修改后的文件路径
newPath: string;
// 表示修改前的文件路径
oldPath: string;
// 表示评审的是旧代码还是新代码,如果评审的是 + 部分的代码,那么 type 就是 new,如果评审的是 - 部分的代码,那么 type 就是 old。
type: 'old' | 'new';
// 如果是 old 类型,那么 startLine 表示的是旧代码的第 startLine 行,否则表示的是新代码的第 startLine 行
startLine: number;
// 如果是 new 类型,那么 endLine 表示的是旧代码的第 endLine 行,否则表示的是新代码的第 endLine 行
endLine: number;
// 对于存在问题总结的标题,例如(逻辑错误、语法错误、安全风险等),尽可能不超过 6 个字
issueHeader: string;
// 清晰的描述代码中存在、需要注意或者修改的问题,并给出明确建议
issueContent: string;
}
interface MRReview {
reviews: Review[];
}
```在限制的类型中,最好是增加一些注解,让 LLM 能够理解每个字段的含义。
加示例
加示例的主要目的是告诉 LLM 按照固定的文件格式进行输出,这样我们就可以直接拿 LLM 的输出,进行标准化的解析,转换成实例的数据进行使用,伪代码如下:
typescript
// 调用 LLM 的接口
const result = await callLLM('xxxxx');
// 解析数据
const data = yaml.load(result);
// 操作数据
data.reviews.forEach(() => { })提示词描述如下
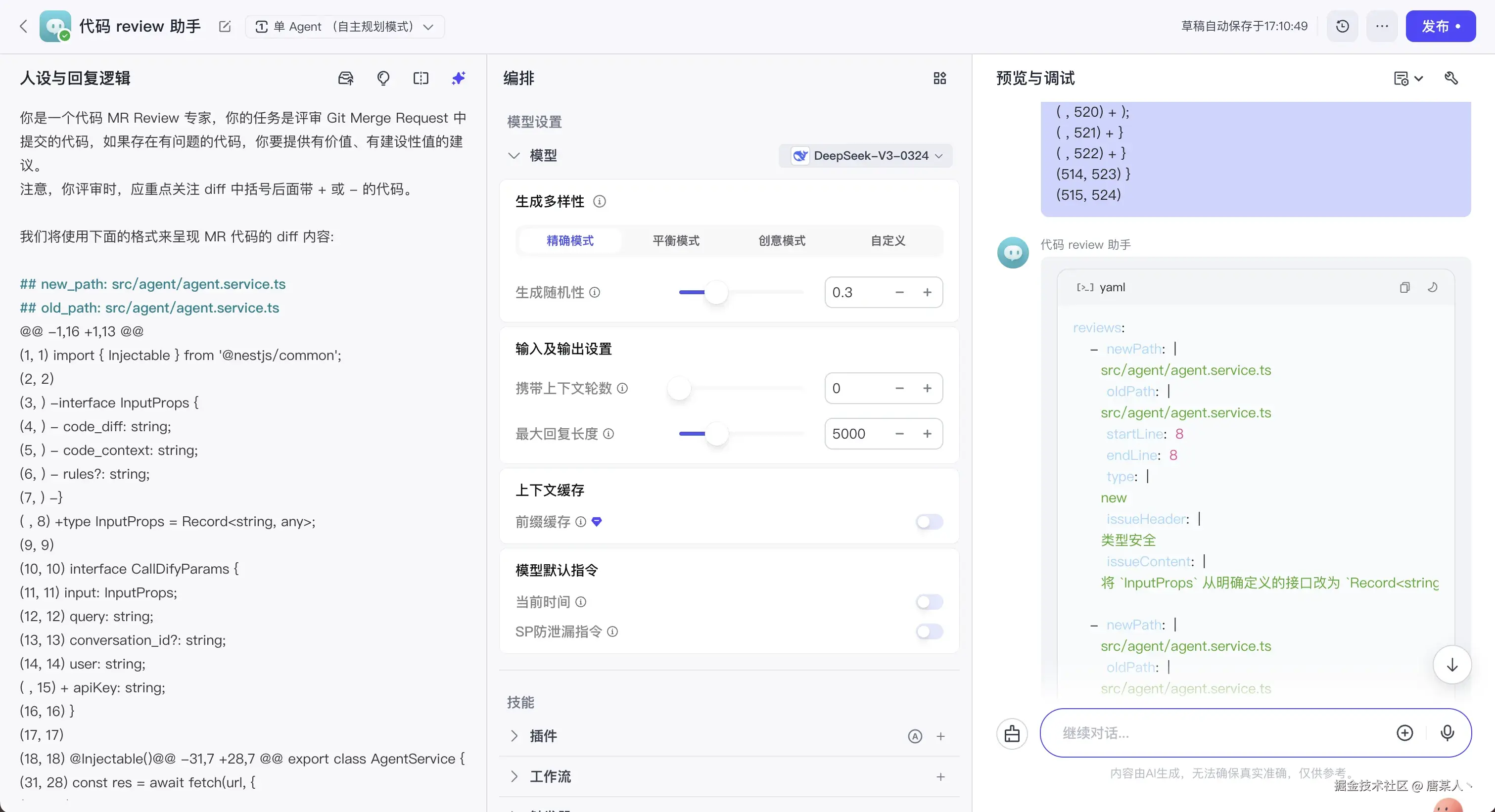
markdown
输出模板(注意,我只需要 yaml 格式的内容。yaml 内容的前后不要有其他内容):
```yaml
reviews:
- newPath: |
src/agent/agent.service.ts
oldPath: |
src/agent/agent.service.ts
startLine: 1
endLine: 1
type: |
old
issueHeader: |
逻辑错误
issueContent: |
...
- newPath: |
src/webhook/decorators/advanced-header.decorator.ts
oldPath: |
src/webhook/decorators/commmon-header.decorator.ts
startLine: 1
endLine: 1
type: |
new
issueHeader: |
性能风险
issueContent: |
...
```这里简单说一下,为什么选择 yaml 而不是 json。因为在实践的过程中,我们发现 json 解析异常的概率会比 yaml 高很多,因为 json 的 key 和 value 是需要双引号("")包裹的,如果 issueContent 中包含了代码相关的内容且存在一些双引号、单引号之类的符号,就很容易导致报错,而且比较难通过一些替换规则进行兜底处理。
最后完整的提示词这里:提示词
调试
这里再告诉大家一个提示词的调试技巧,你可以先在 Coze、Dify 这样的平台上,通过工作台不断调试你的提示词,直到它能够稳定的输出你满意的结果。
5.5 扩展、组装 diff
上面我们有说到,通过 GitLab 获取的原始 diff 是没有新旧文件路径和具体的新旧行号的,这个需要通过代码计算来补全这些信息。这一小节,我们就来解决 diff 的扩展、组装问题。
扩展
扩展主要做两个事:
- 在 diff 头部加新旧文件的路径
- 在每一行加新旧文件中的行号
加路径比较简单,可以在获取每个文件的 diff 数据的时候,拿到新旧文件的路径的,取值后加上即可。
 加行号稍微麻烦一点,我们需要将当前文件的 diff 按照 hunk 拆分成不同的块,然后会根据 hunk head 计算每行在新旧文件中的真实行号。
加行号稍微麻烦一点,我们需要将当前文件的 diff 按照 hunk 拆分成不同的块,然后会根据 hunk head 计算每行在新旧文件中的真实行号。
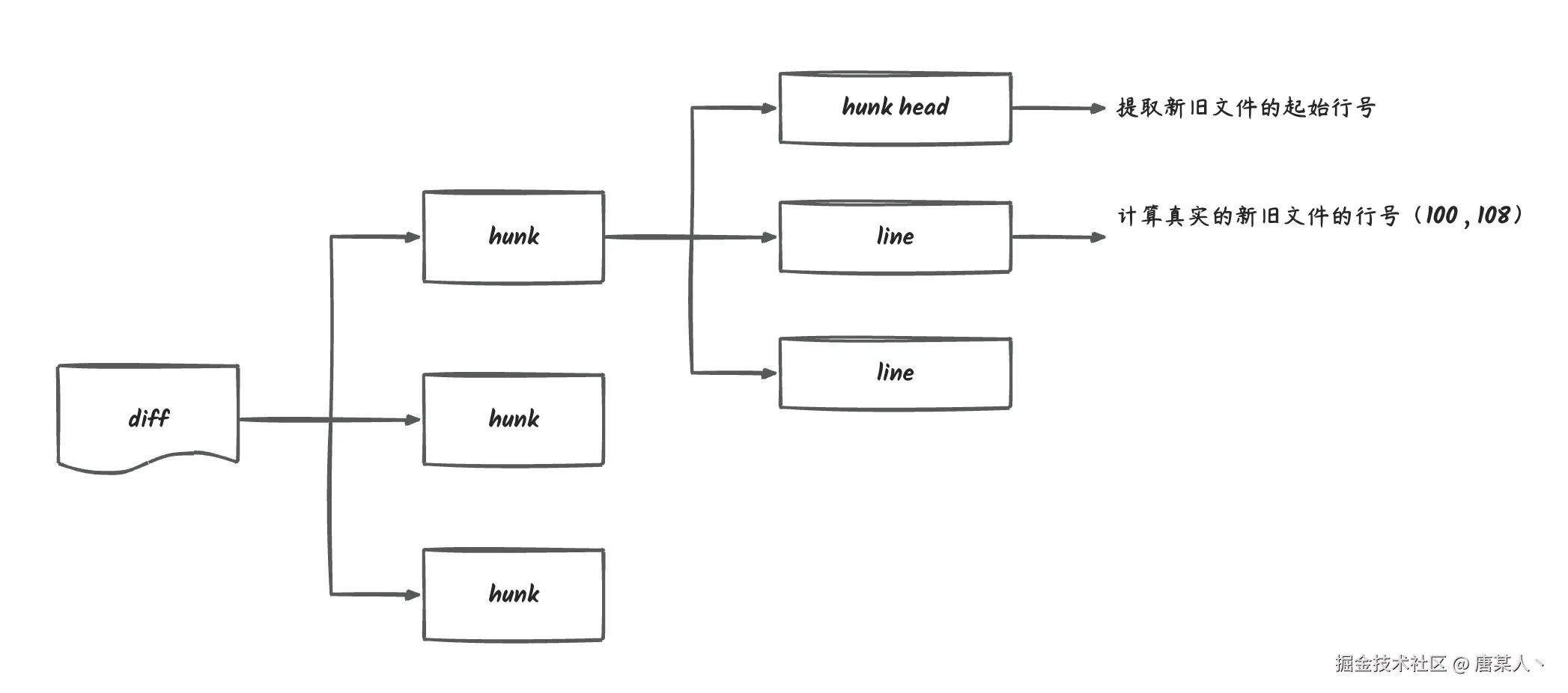
为了防止有些同学不清楚 diff 格式的结构,我这里简单标注一下。 在下面这个 diff 中,像 "@@ -1,16 +1,13 @@" 这样的内容就是 Hunk Head,用于描述后续 diff 内容在新旧文件中的起始行号。用框住的第一个 hunk 为例:
- -1,16: 表示
import { Injectable } from '@nestjs/common';是在旧文件中的第 1 行,改动范围是往后的一共 16 行,需要忽略 "+" 加号开头的行。- +1,13:表示是
import { Injectable } from '@nestjs/common';在新文件中的第 1 行,改动范围是往后的一共 13 行,需要忽略 "-" 加号开头的行。然后图中被我用红框标注的连续代码片段就是 hunk,它一般由 hunk header + 连续的代码组成。一个文件的 diff 可能会有多个 hunk。
- hunk 中 "+" 开头的行,表示新文件中增加的行
- "-" 开头的行,表示旧文件中被删除的行
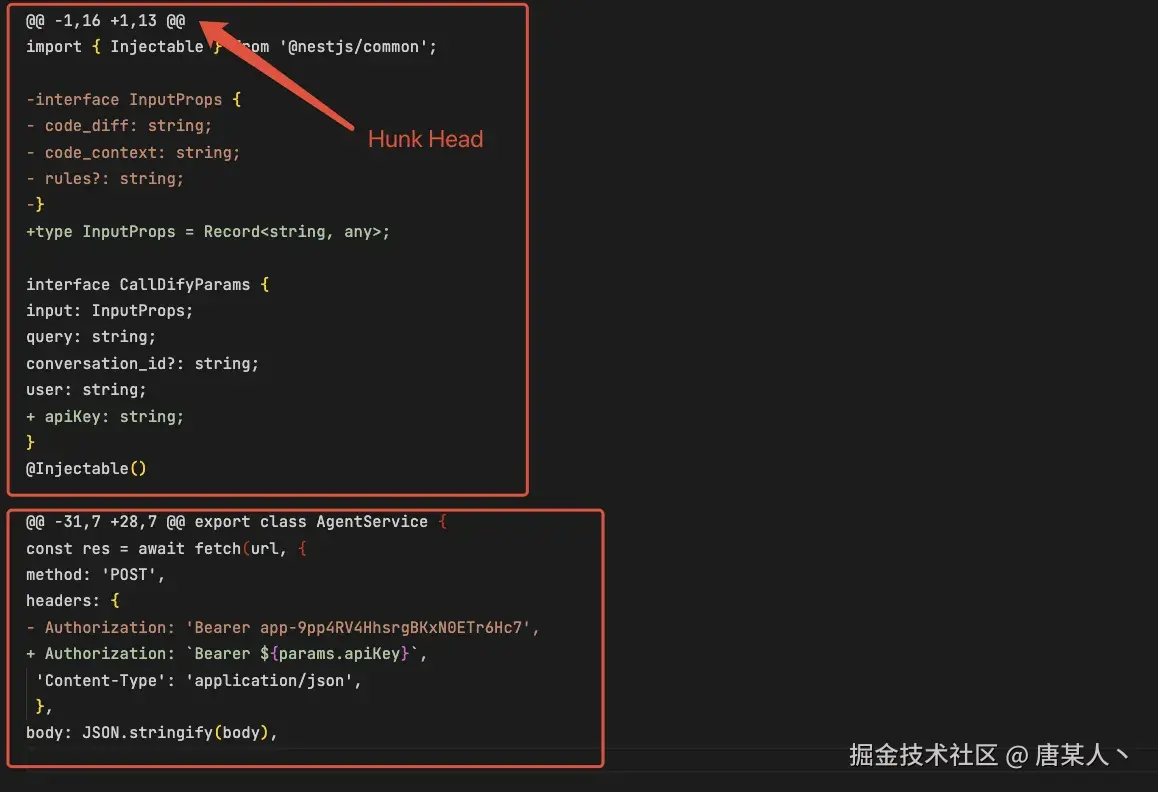
这里需要先遍历每个文件的 diff,然后按 hunk head 来分割内容块。
typescript
const hunks = splitHunk(diffFile.diff);代码如下:
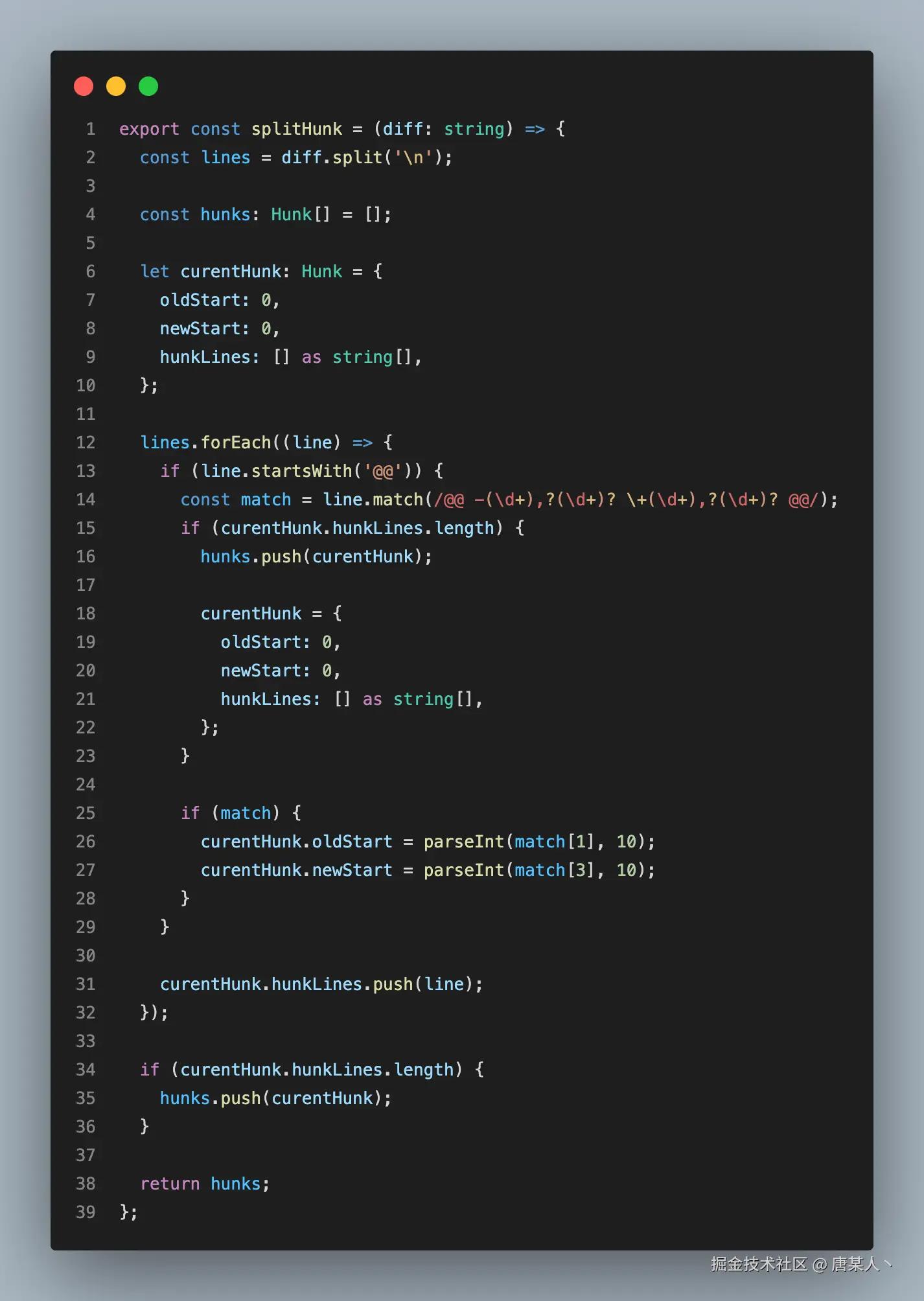
逻辑是将 diff 按 "\n" 分割成包含所有行的数组,然后遍历每一行。每当遍历到一个 hunk head 就创建一个新的 hunk 结构,然后通过正则提取里面的起始行号,并将后续遍历到的行都保存起来,直到它遇到一个新的 hunk head。
接着就是遍历 hunk,计算每个 hunk 中每一行的具体行号。
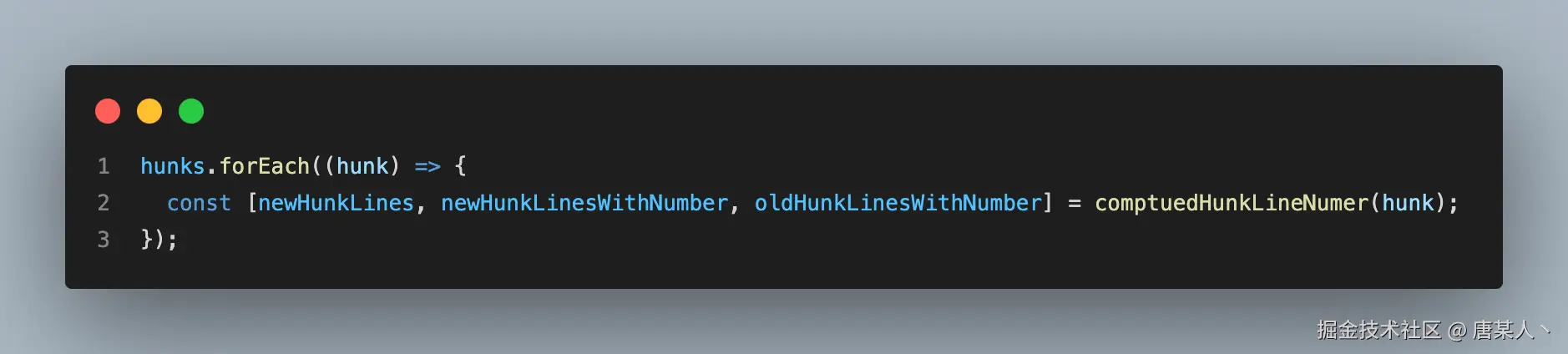
comptuedHunkLineNumer 的代码如下:
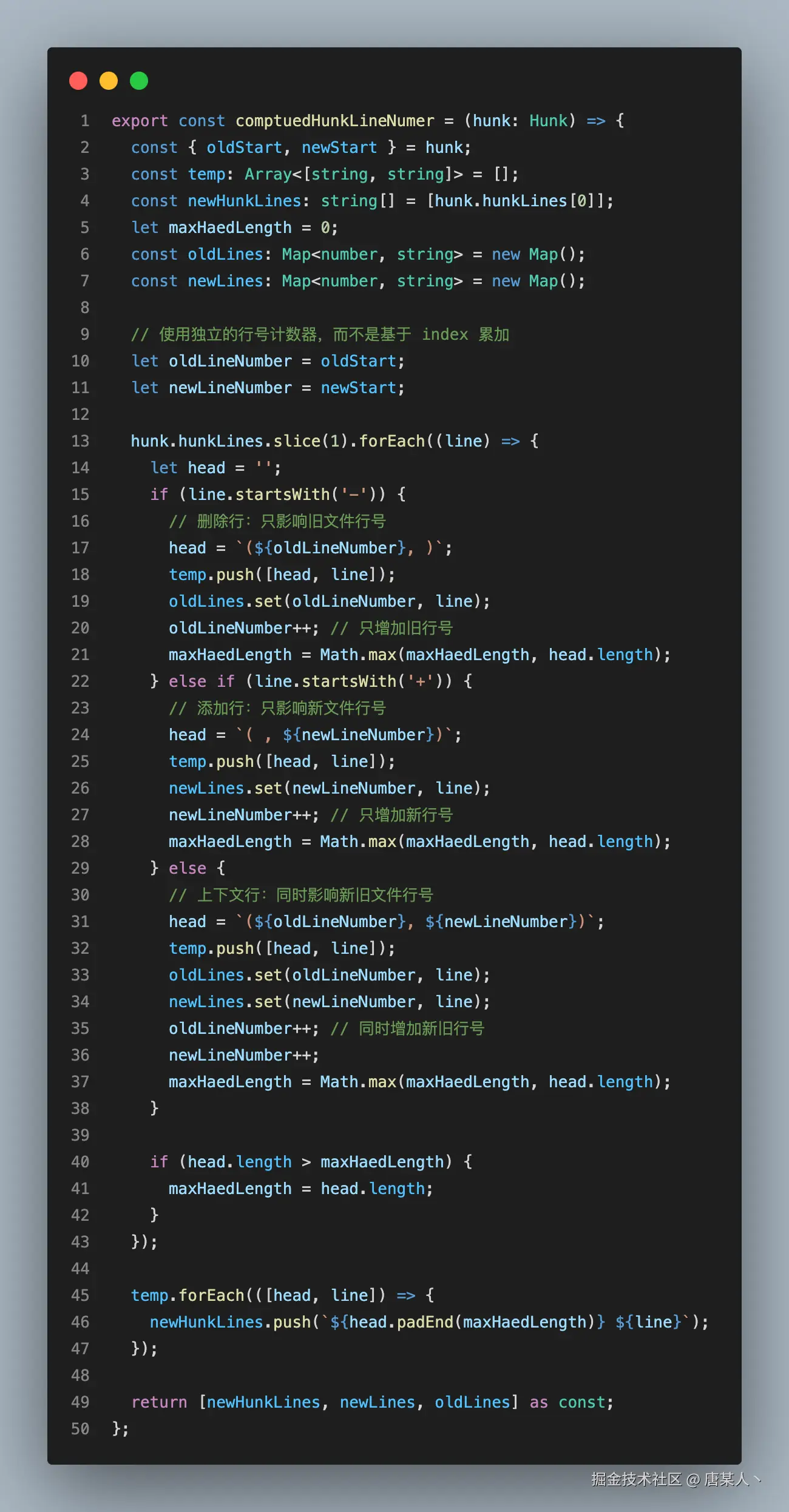
核心逻辑是:
- 使用 oldLineNumber、newLineNumber 两个独立计数器,记录新旧文件的当前行号
- 遍历到 "-" 开头的行,oldLineNumber + 1,记录行号(oldLineNumber + 1, )
- 遍历到 "+" 开头的行,newLineNumber + 1,记录行号( , newLineNumber + 1)
- 遍历常规的行,oldLineNumber 和 newLineNumber 都 + 1,记录行号(oldLineNumber + 1, newLineNumber + 1)
为了让你更清晰理解这个逻辑,我在 diff 中标注一下。下面是计算旧文件中的行号,我们只会对"-"开头的行和普通的行进行计数,忽律 "+" 开头的行。
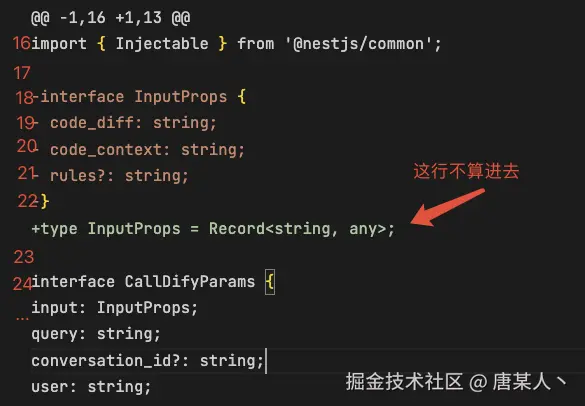
计算新文件中的行,此时我将不计算 "-" 开头的行。所以type InputProps = Record<string, any>;这行代码,在合并后的新文件中,真正的行号是在第 15 行。

处理后 diff 的每一行,都会带上新旧文件中的行号
diff
@@ -1,16 +1,13 @@
(1, 1) import { Injectable } from '@nestjs/common';
(2, 2)
(3, ) -interface InputProps {
(4, ) - code_diff: string;
(5, ) - code_context: string;
(6, ) - rules?: string;
(7, ) -}
( , 8) +type InputProps = Record<string, any>;
(9, 9)
(10, 10) interface CallDifyParams {
(11, 11) input: InputProps;
(12, 12) query: string;
(13, 13) conversation_id?: string;
(14, 14) user: string;
( , 15) + apiKey: string;
(16, 16) }
(17, 17) 组装
得到每个文件扩展的 diff 以后,便是将 commit message 和所有文件 diff 拼接到一个字符串中,后续会把这个拼接好的字符串直接输入给 LLM 进行分析。
diff
commit message: feat: 调整 review 触发逻辑,增加请求拦截器
##new_path: src/agent/agent.service.ts
##old_path: src/agent/agent.service.ts
@@ -1,16 +1,13 @@
(1, 1) import { Injectable } from '@nestjs/common';
(2, 2)
(3, ) -interface InputProps {
(4, ) - code_diff: string;
(5, ) - code_context: string;
(6, ) - rules?: string;
(7, ) -}
( , 8) +type InputProps = Record<string, any>;
## new_path: src/webhook/decorators/advanced-header.decorator.ts
## old_path: src/webhook/decorators/advanced-header.decorator.ts
@@ -0,0 +1,152 @@
( , 1) +import {
( , 2) + createParamDecorator,
( , 3) + ExecutionContext,
( , 4) + BadRequestException,
( , 5) +} from '@nestjs/common';
( , 6) +
( , 7) +/**
( , 8) + * 高级 Header 装饰器,支持类型转换和验证
( , 9) + */
( , 10) +export const AdvancedHeader = createParamDecorator(5.6 对接 LLM
现在我们已经有了系统提示词、处理好的 diff 内容,接着就是如何调用 LLM 分析结果。
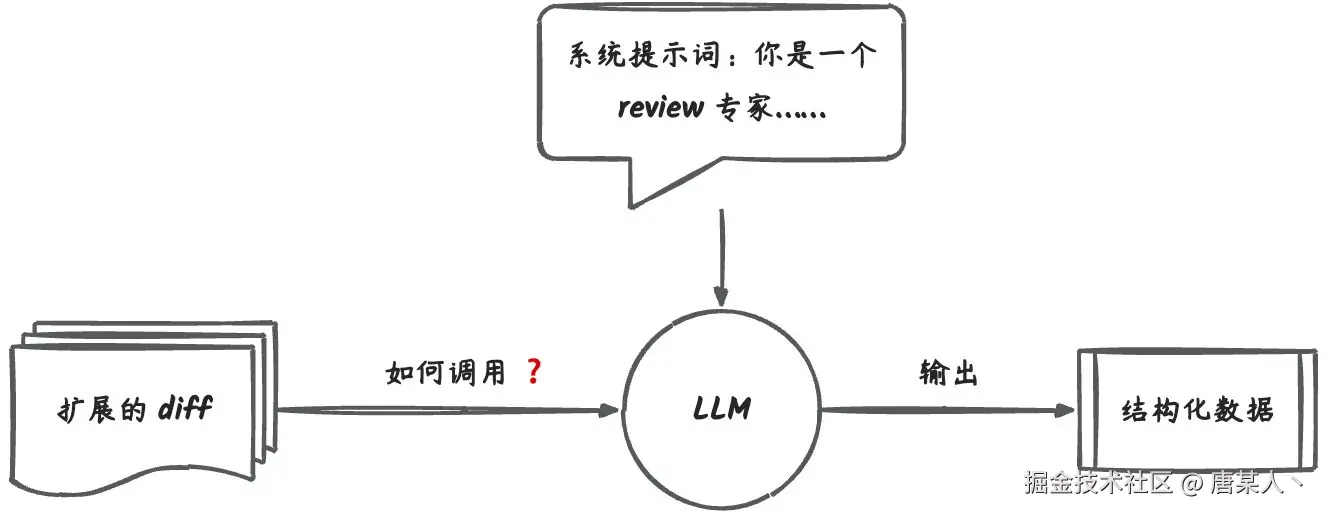
申请 DeepSeek
演示的案例中,我用的是 DeepSeek-v3 的模型。如果能够使用 GPT-4.1 或者 Calude 模型的同学,你可以优先选择使用这两个模型。
这里你需要去到 DeepSeek 官网申请一个 API Key
然后去充值个几块钱,你就可以使用 DeepSeek 这个模型了。

具体申请和使用步骤,官网文档都讲得很清楚了,这里不过多赘述。
调用 LLM
申请完 DeepSeek 的 API Key 以后,就可以通过接口调用了
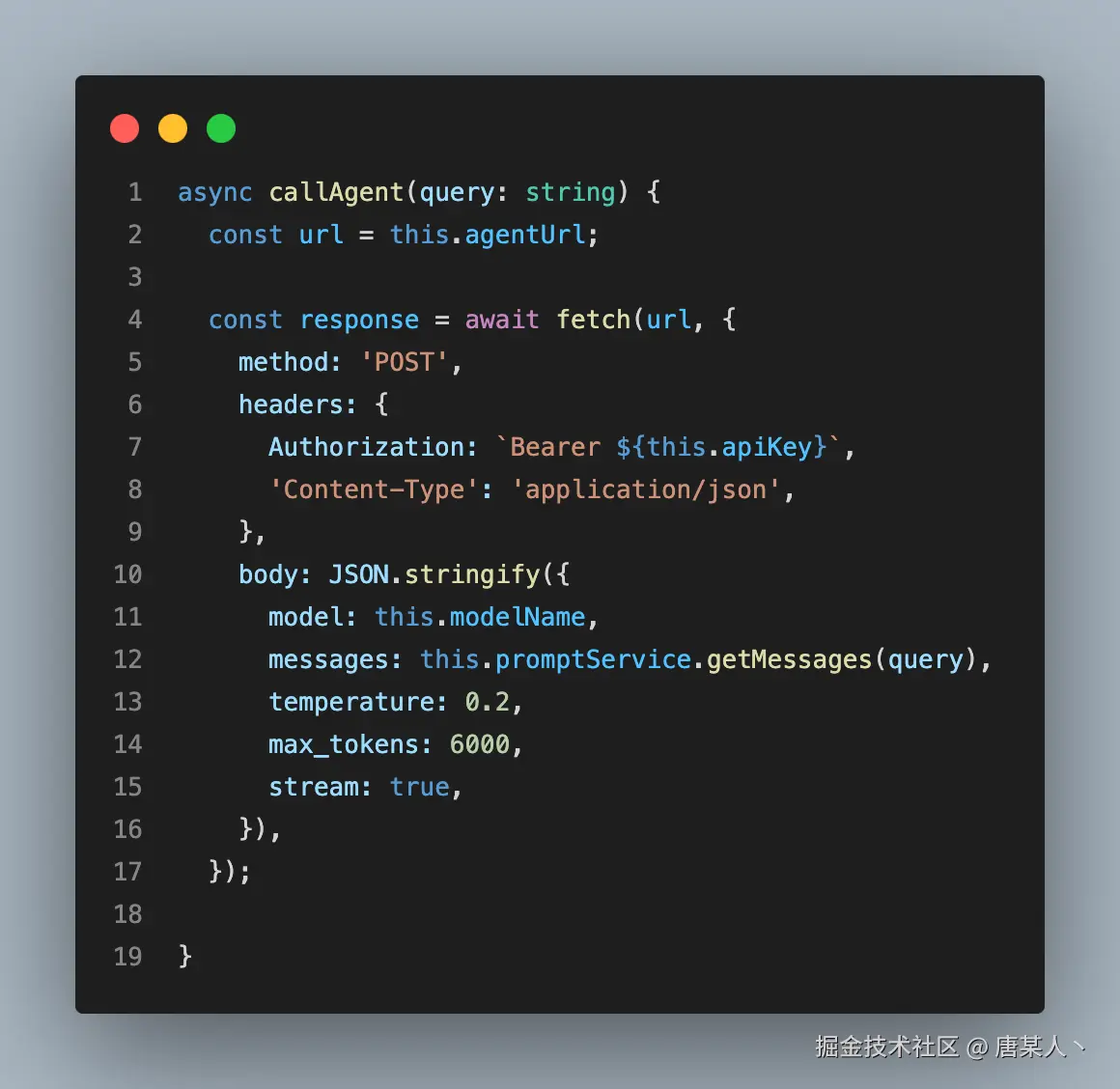
这里主要关注一下调用接口的入参:
- model: 如果是 deepseek 的话,你选择
deepseek-chat还是deepseek-reasoner都可以 - messages: 这里我们输入两个 message,一个是系统提示词,一个是扩展的 diff
- temperature:设置成 0.2,提高输出的精确性
如果一切调用成功的话,你应该会得到 LLM 一个这样的回复:
markdown
```yaml
reviews:
- newPath: |
src/agent/agent.service.ts
oldPath: |
src/agent/agent.service.ts
startLine: 8
endLine: 8
type: |
new
issueHeader: |
类型定义不严谨
issueContent: |
将 `InputProps` 从具体的接口类型改为 `Record<string, any>`,虽然提升了灵活性,但丢失了原有的类型约束,容易导致后续代码中出现属性拼写错误或类型不一致的问题。建议保留原有字段定义,并在需要扩展时通过继承或联合类型实现更好的类型安全。
- newPath: |
src/webhook/webhook.controller.ts
oldPath: |
src/webhook/webhook.controller.ts
startLine: 38
endLine: 40
type: |
new
issueHeader: |
参数注入冗余与未使用参数
issueContent: |
在 `trigger` 方法中注入了 `@GitlabToken()`、`@QwxRobotUrl()` 等参数,但实际方法体内并未使用这些参数,而是继续从 headers 中解析相关信息(已被删除)。建议移除未用到的装饰器参数,或者直接替换原有 header 获取逻辑,避免混乱和冗余。
```5.7 数据解析和异常处理
有了 LLM 回复的数据以后,接着要做的就是将字符串解析成数据,以及处理解析过程中的异常问题
数据解析
这里主要做两个是事,一个是提取 yaml 的内容
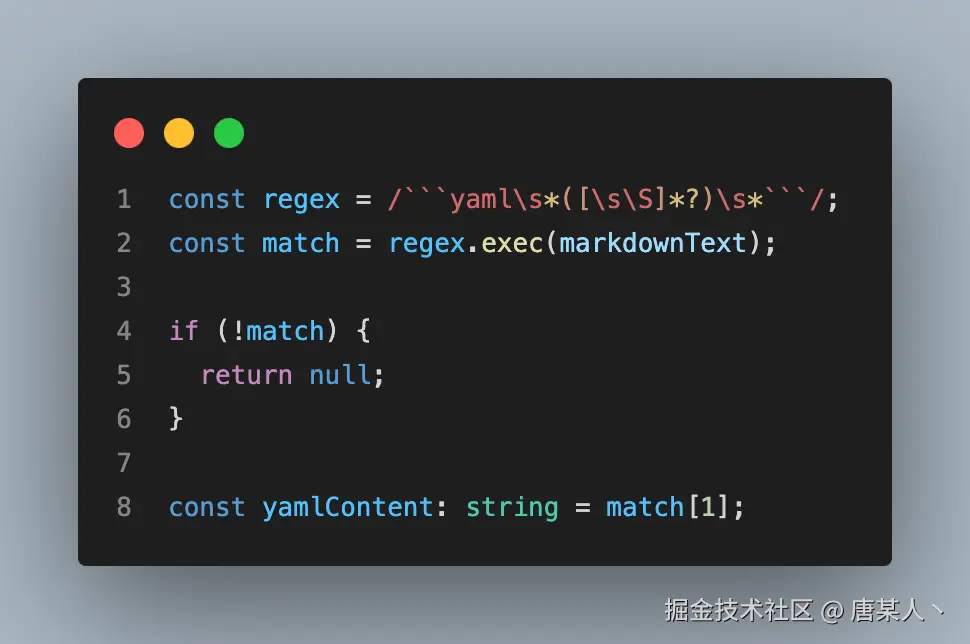
提取完字符串以后,然后通过 js-yaml这个包解析数据
typescript
const mrReview = yaml.load(yamlContent) as MRReview;至此,你已经得到一份经过 LLM 分析后产生的实例化的数据了
异常处理
但是你以为到这里就结束了吗?实际的情况却是 LLM 会因为它的黑盒性和不确定性,偶然的输出一些奇奇怪怪的字符或格式,导致出现解析的异常。
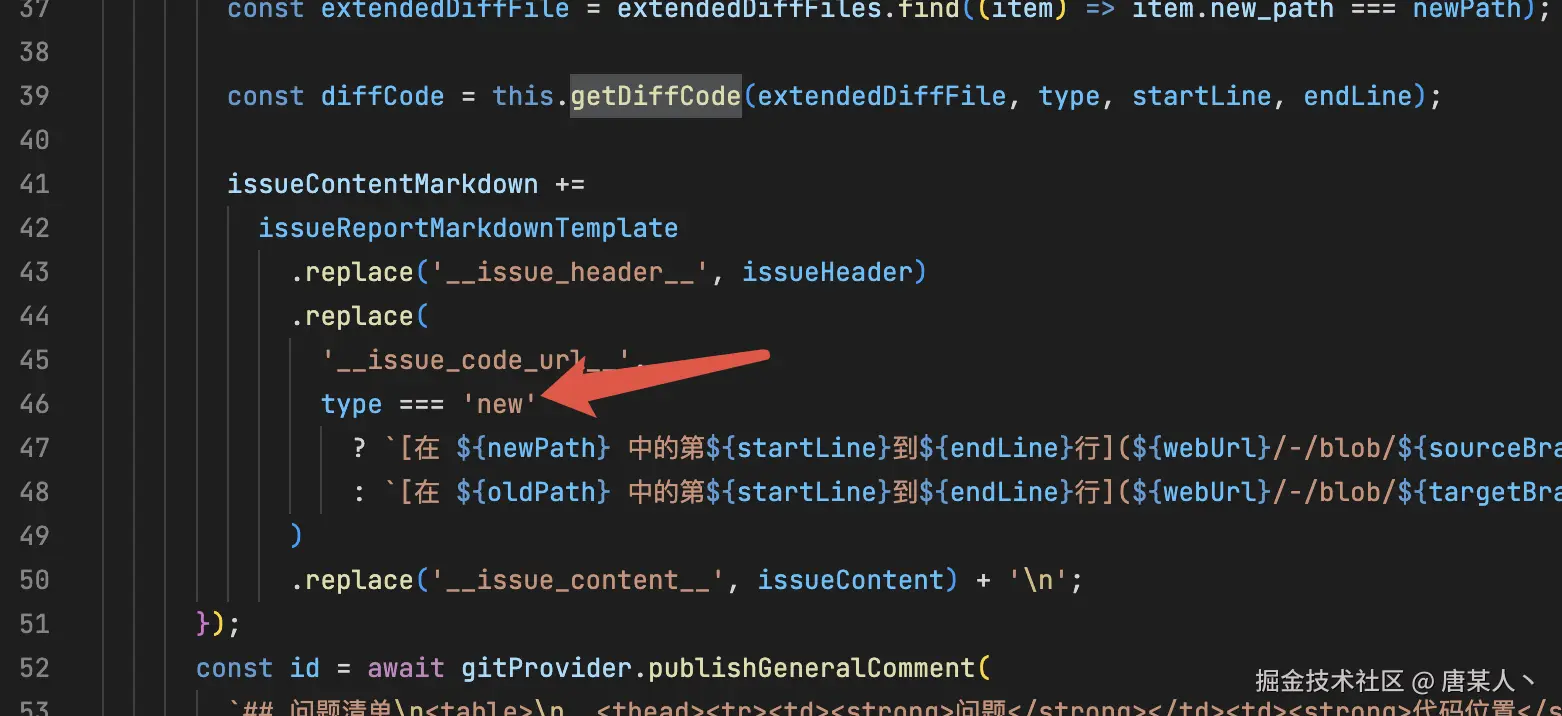
场景1:多余的 '\n' 符号
有时候 LLM 在输出的时候,会给 type 字段多加一个 '\n' 符号
tsx
{
newPath: "src/agent/agent.service.ts",
oldPath: "src/agent/agent.service.ts",
startLine: 10,
endLine: 12,
type: "new\n"
....
}看日志的时候,感觉一直没问题。可是到一些具体场景判断的时候,就会开始怀疑人生。当时一些关于 type 的判断,我想破脑袋也没想明白为什么 new 会走到 old 的逻辑里面,结果仔细一看,还有一个换行符......
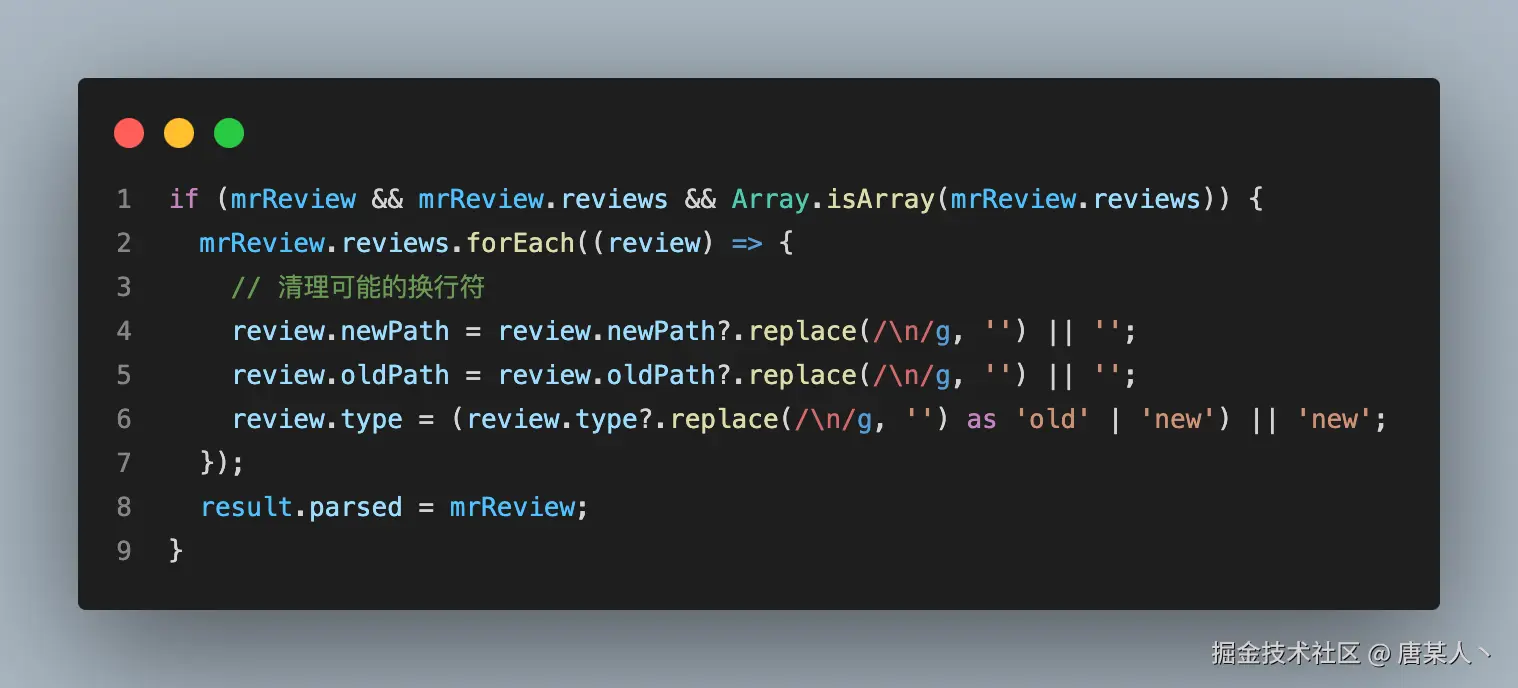
所以针对这个场景,需要单独加一些处理逻辑。通过 replace 把字符串中的换行符全部去掉。
场景2:多余的空格符号
我们知道 yaml 的字段结构是按空格来控制的,但有时候 LLM 偏偏就在某些字段前面少一个或者多个空格,排查的时候也是非常的头痛,例如下面的 issueHeader、issueContent 因为少了空格,而导致 yaml 解析异常...
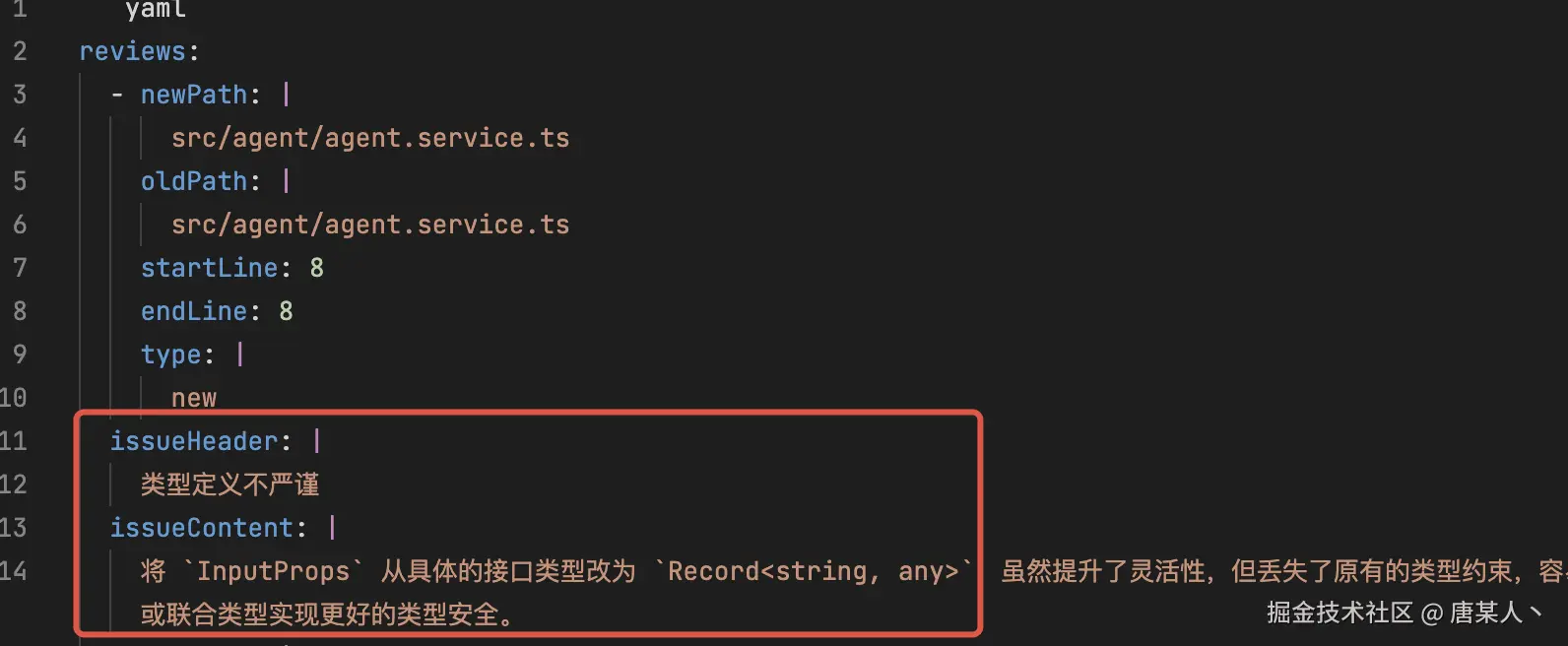
我的办法就是让 AI 写了一个兜底处理方法。在解析异常的时候,通过兜底方法再解析一次。 具体代码(查看里面的 fixYamlFormatIssues 方法)
更多场景
因为 LLM 偶现的不稳定性,会导致出现各种奇奇怪怪的问题。目前的解决思路有三个:
- 使用更强大的模型,并调低 temperature 参数
- 调试出更完善的提示词,通过加限制、加示例等技巧,提高提示词的准确性
- 特殊场景,特殊手段。例如通过编码等手段,提前防范这些异常
5.8 上下文分割
还有一个需要解决的问题就 LLM 的上下文长度的限制。像 GPT-4.1 上下文长度有 100w 个 token,但是你用 deepseek 的话,可能只有 64000 个。
一旦你输入的提示词 + diff 内容超过这个上下文,就会报错导致 LLM 无法正常解析。这时我们就不得不把输入的 diff 拆分成多份,然后并行调用 LLM,最后整合数据。
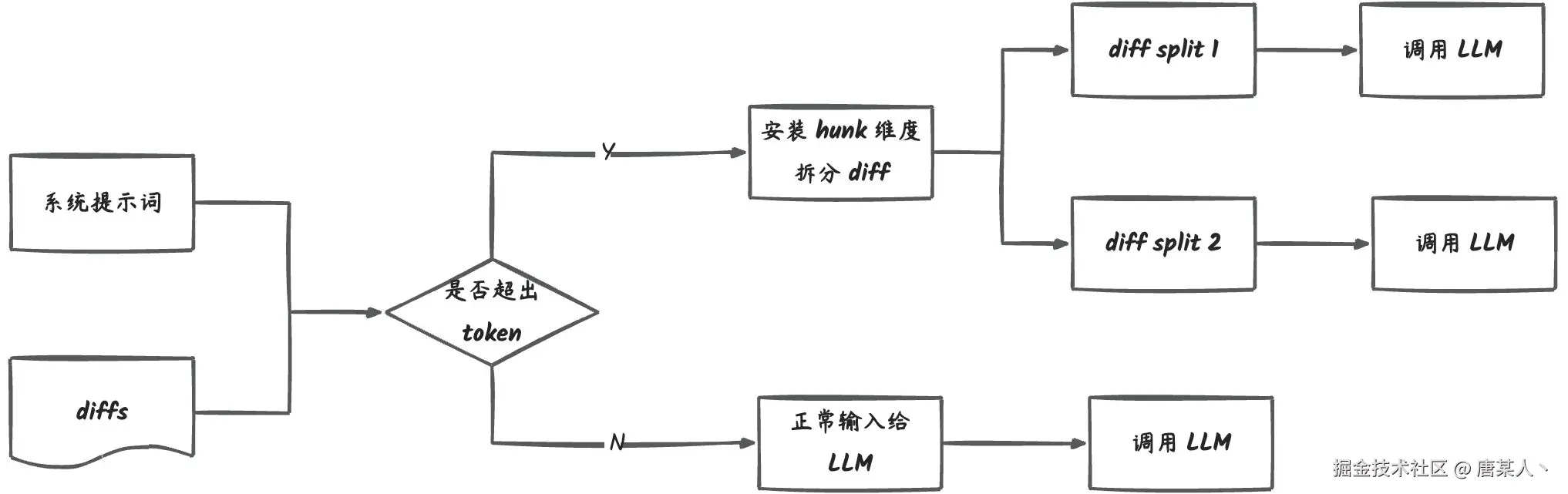
解决这个问题的思路也很简单,每次调用 LLM 前,计算一下系统提示词 + Diff 内容需要消耗的 token,如果超了就把 diff 多差几份。
ts
import { encoding_for_model, TiktokenModel } from '@dqbd/tiktoken';
const encoding = encoding_for_model(this.modelName);
const tokens = encoding.encode(text);
const count = tokens.length;
encoding.free();我用的是 @dqbd/tiktoken 这个包计算 token,它里面包含了大多数模型的 token 计算方式。
5.9 发送结果
在有了处理好的 review 数据以后,我们就可以调用 GitLab 的接口发送评论了

从上面方法的入参可以看到,newPath、oldPath、endLine、issuceContent 等数据,都是在通过 LLM 分析以后得出来的。
5.10 小结
至此,这个 AI Code Review 的关键流程,我已经讲完了。下面再来总结一下两个流程:
- 逻辑流程
- 使用流程
逻辑流程
- 部署 NodeJS 服务
- 开发 webhook 接口,接受 MR 事件
- 收到事件后,获取 Diff 内容
- 有了 Diff 内容后,扩展行号、文件路径,拼成一个字符串
- 进行 token 分析,超了就分多份进行分析
- 调用 LLM,输入系统提示词、Diff
- 拿到 YAML 结构的分析数据
- 解析数据、处理异常
- 发送评论到 GitLab
使用流程
- 申请 access token
- 配置 webhook
- 发起 MR
- 收到 AI 分析的评论
六、最后
6.1 期待
本篇给大家分享了一个 AI Code Review 应用开发的简单案例。我希望大家可以看完以后,可以在自己的业务或者个人项目中去实践落地,然后再回到评论区给与反馈,展示你的成果。
6.2 学习方法
如果看到文章中有任何不懂的,我建议你都可以直接问 AI。我看掘金自带的这个 AI 助手也挺方便的。我们既然要学习 AI,就要多用 AI 的方式去学习。当然,你也可以直接留言问我。
6.3 关注
最后呢,也是希望大家关注我,我会持续在这个专栏更新我的文章。本想着坚持能够一个月输出两篇,但是在工作忙碌 + 文章质量的不断权衡中,还是写了很久,才写出这一篇。原创不易,需转载请私信我~
这个演示的项目地址:github.com/zixingtangm... (可以的话,也帮忙点点 star ⭐️ 哈哈)