论文阅读笔记:Clip:Learning Transferable Visual Models From Natural Language Supervision
日期: 2025-10-22
状态: 🟢 已精读
1. 元数据 (Metadata)
| 条目 | 内容 |
|---|---|
| 年份 | 2021 |
| 论文链接 | https://arxiv.org/abs/2103.00020 |
| 代码链接 | https://github.com/OpenAI/CLIP (官方实现) |
| 我的标签 | 大语言模型 计算机视觉 多模态 |
2. 摘要与核心问题 (Abstract & Core Problem)
用你自己的话简要复述,不要直接复制摘要。
-
论文要解决什么问题?
目前视觉领域已有方法,只能预测模型训练时给定的特定物体类别,即训练时只有猫和狗两种类别,即使马的图片看起来与猫或狗有些相似,模型也无法识别它是马,因为它并没有接触过马的图像或学习过马的特征。
-
核心主张或贡献是什么?
该论文提出了一种新的方法,通过图像和原始文本的配对学习来解决这个问题。模型不再局限于预先定义的类别,而是通过学习图像与其对应的自然语言描述,来实现零样本的学习和预测。这样,模型能够通过文本描述来理解和识别任何新的物体类别,甚至是它从未见过的图像。
3. 背景知识 (Background)
相关工作局限性
在传统视觉模型研究中存在多个关键局限性:首先,监督信号严重受限 ,大多数方法依赖固定类别标签(如ImageNet的1000个类别),无法灵活扩展到新概念;其次,零样本性能表现较差 ,如Visual N-Grams在ImageNet上的准确率仅为11.5%,远低于监督模型;再者,模型灵活性不足 ,受限于静态分类器架构,缺乏根据自然语言描述动态调整预测目标的能力;此外,训练效率低下 ,早期基于图像标题生成的方法计算成本高昂,难以实现大规模扩展;最后,数据集规模有限,主要依赖MS-COCO、Visual Genome等小型高质量数据集,未能充分利用互联网上的海量图像-文本对资源。
本文动机
构建了包含4亿图像-文本对的大规模数据集WIT ,通过系统化的搜索查询策略确保了视觉概念的广泛覆盖;其次,提出了基于对比学习的高效预训练方法CLIP ,通过简化模型结构和优化训练目标,实现了比传统生成式方法显著提升的训练效率;第三,实现了真正的零样本迁移能力 ,在超过30个下游数据集上无需任何训练即可达到与监督模型相竞争的性能,并通过自然语言提示机制实现了灵活的任务适应
4. 方法/模型 (Methodology/Model)
-
核心思想:
(1)当图像模型使用图像特征提取器 和线性分类器 来预测某些标签时,CLIP结合图像编码器和文本编码器来预测一批(图像、文本)训练示例的正确配对 。在测试时,(2,3)经过训练的文本编码器通过嵌入目标数据集类的名称或描述来合成零样本线性分类器。
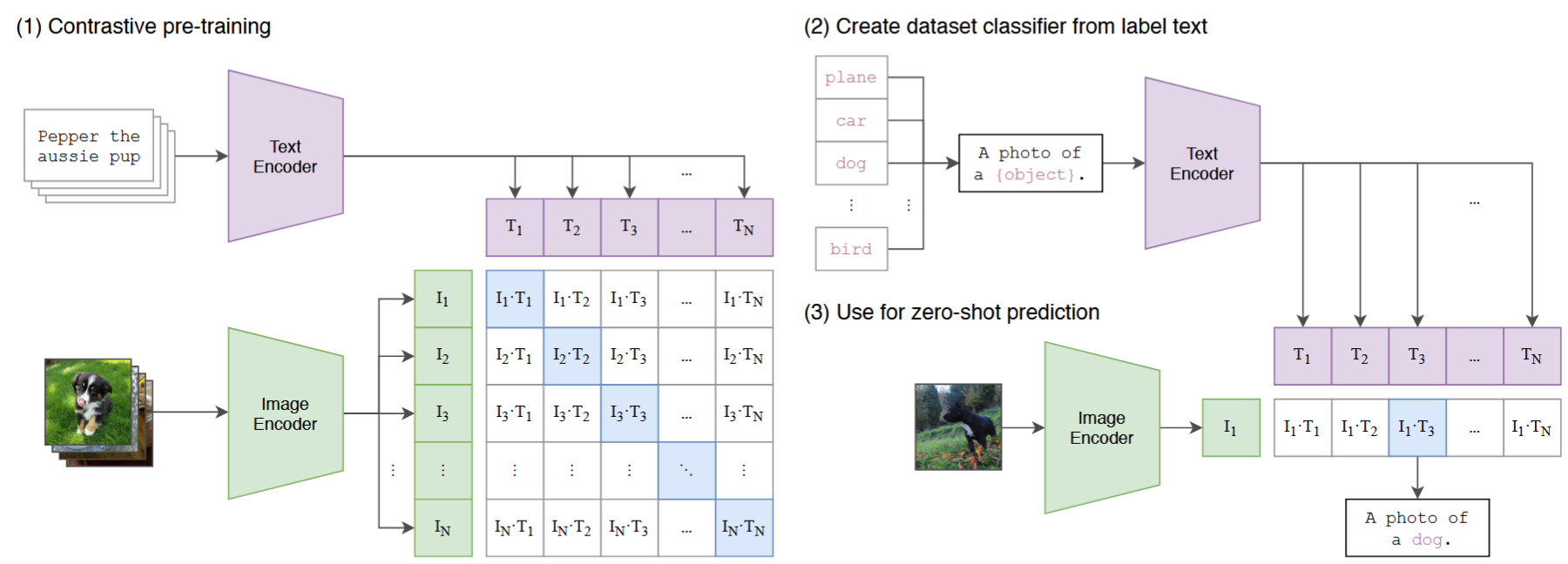
-
模型/方法框图:
CLIP 模型训练配置详情
📊 模型架构
图像编码器
| 类型 | 具体模型 | 说明 |
|---|---|---|
| ResNet系列 | RN50, RN101 | 基础模型 |
| RN50x4, RN50x16, RN50x64 | 采用EfficientNet式缩放 | |
| Vision Transformer系列 | ViT-B/32, ViT-B/16 | 基础ViT模型 |
| ViT-L/14 | 大型ViT模型 |
⚙️ 训练基础配置
| 参数项 | 配置值 |
|---|---|
| 训练周期 | 32 epochs |
| 优化器 | Adam |
| 正则化 | 解耦权重衰减 |
| 学习率调度 | 余弦调度 |
🎛️ 超参数策略
初始化策略
- 方法: 网格搜索 + 随机搜索 + 手动调优
- 基准: 在ResNet-50上训练1个epoch确定初始值
- 缩放: 对大模型采用启发式调整(受计算资源限制)
温度参数 (τ)
- 初始值: 0.07
- 优化: 梯度裁剪(限制缩放因子 ≤ 100)
- 目的: 防止训练不稳定
💻 工程优化技术
| 优化技术 | 具体实现 | 作用 |
|---|---|---|
| 批量大小 | 32,768 | 超大批次训练 |
| 计算精度 | 混合精度训练 | 加速训练,节省显存 |
| 内存优化 | 梯度检查点 | 减少显存占用 |
| 半精度Adam统计量 | 节省显存 | |
| 半精度随机取整文本编码器权重 | 节省显存 | |
| 分布式计算 | 嵌入相似度计算分片 | 每个GPU计算本地批次相似度 |
⏱️ 训练资源消耗
| 模型 | 硬件配置 | 训练时间 |
|---|---|---|
| RN50x64 (最大ResNet) | 592 × V100 GPU | 18天 |
| ViT-L/14 (最大ViT) | 256 × V100 GPU | 12天 |
🚀 性能增强策略
高分辨率微调
- 模型: ViT-L/14
- 分辨率: 336px
- 额外训练: 1个epoch
- 标识: ViT-L/14@336px
最佳模型选择
- 主要结果: 全部使用 ViT-L/14@336px
- 性能: 论文中表现最佳的模型
5. 实验与结果 (Experiments & Results)
5.1 Zero-Shot Transfer
在表1中,本文比较Visual N-Grams与CLIP。最好的CLIP模型将ImageNet的精度从概念验证的11.5%提高到76.2%,并与原始ResNet-50的性能相匹配,尽管没有使用该数据集可用的128万个人群标记训练示例中的任何一个。此外,CLIP模型的前5个精度明显高于其前1个精度,并且该模型的前五个精度为95%,与Inception-V4精度相当。在零样本任务中表现强大、完全监督基线的性能的能力。

-
数据集:
(列出论文使用的数据集,若有公开数据集,提供链接)
- 数据集 1:链接
- 数据集 2:链接
-
实验设置:
(简要介绍实验设置,包括超参数、训练细节等)
-
实验结果:
(展示结果,并通过表格或图表比较不同方法的性能)
-
评估指标: 如准确率、F1分数、精确度、召回率等
-
对比表格:
模型 准确率 F1分数 其他指标 模型A 85.2% 0.82 0.75 模型B 88.5% 0.85 0.78 模型C 90.1% 0.87 0.80
-
-
实验图表:
(通过折线图、柱状图等可视化实验结果,比较不同方法之间的差异)
示例图:
图 1:不同模型在各项指标上的表现对比。
6. 结论 (Conclusion)
- 主要贡献:
总结论文的贡献,回顾模型创新和实验结果。 - 局限性:
(论文中提到的模型或方法的局限性) - 未来工作:
(论文中提到的可能的改进方向或未来研究的重点)