一、包和模块
在Python中,包和模块是代码组织和管理的重要概念。它们将代码分割成易于维护和复用的结构。
1. 模块
Module,模块
1.1 基本概念
-
定义:模块是一个Python文件,每个 .py 文件就是一个模块。
-
作用:用于组织代码,避免代码重复,提高复用性。
-
使用:通过 import 语句导入模块中的内容。
1.2 快速上手
1.2.1 定义模块
定义一个名为 math_utils.py 的模块:
def add(a, b):
return a + b
def subtract(a, b):
return a - b1.2.2 导入模块
- 语法
import 模块名 [as 模块新名字1]导入一个模块到当前程序
from 模块名 import 模块属性名 [as 属性新名]导入一个模块内部的部分属性到当前程序
from 模块名 import *导入一个模块内部的全部属性到当前程序
import math_utils
print(math_utils.add(3, 5)) # 输出: 8
print(math_utils.subtract(10, 4)) # 输出: 6也可以使用 from ... import 导入特定内容:
from math_utils import add
print(add(3, 5)) # 输出: 81.2.3 内部属性
__file__ 绑定模块的路径
__name__ 绑定模块的名称
如果是主模块(首先启动的模块)则绑定 '__main__'
如果不是主模块则 绑定 xxx.py 中的 xxx 这个模块名1.3 模块分类
Python 的模块可以分为系统模块、自定义模块和第三方模块
1.3.1 系统模块
Pytho内置的模块,安装Python时已包含,提供基础功能,比如数学运算、文件操作、网络通信等。
特点
-
即用即导入 :直接
import即可使用。 -
性能高效:通常使用 C 语言实现。
1.3.1.1 常见模块
| 模块 | 功能 | 官方文档 |
|---|---|---|
math |
数学运算 | math --- 数学函数 --- Python 3.12.10 文档 |
os |
操作系统接口 | os --- 多种操作系统接口 --- Python 3.13.5 文档 |
os.path |
路径相关 | os.path --- 常用的路径操作 --- Python 3.13.5 文档 |
datetime |
日期和时间 | datetime --- 基本日期和时间类型 --- Python 3.13.5 文档 |
random |
随机数生成 | random --- 生成伪随机数 --- Python 3.13.5 文档 |
time |
时间 | time --- 时间的访问和转换 --- Python 3.13.5 文档 |
1.3.1.2 方法示例
random模块:
import random
random.randint(1, 6) # random.randint(a,b) 生产 a~b的随机整数
random.randint(1, 6)
random.random() # random.random 生成包含0 但不包含1 的浮点数
random.choice("ABCD") # 从一个序列中,随机返回一个元素
random.choice("ABCD")
L = [1, 2, 3, 6, 9]
random.choice(L)
random.shuffle(L) # random.shuffer(x) # 把列表X 打乱
print(L)
随机生成密码:
import random
import time
## 生成 n 位的数字密码
def get_random_password(n):
r_str = ''
for _ in range(n):
r_str += str(random.randint(0, 9))
return r_str
## 生成 n 位的数字和字母组成的密码
charactors = '0123456789abcdefghijklmnopqrstwuxyz'
def get_random_password2(n):
r_str = ''
for _ in range(n):
r_str += random.choice(charactors)
return r_str
print(get_random_password(6))
print(get_random_password(6))
time.sleep(2)
print(get_random_password2(10))time模块:
import time
time.time() # 返回当前时间的时间戳
time.ctime() #返回当前的UTC 时间的字符串
t1 = time.localtime() # 返回当前的本地时间元组
time.sleep(3) # 让程序睡眠 n 秒
time.strftime("%Y-%m-%d", t1) # 格式化时间
time.strftime("%y-%m-%d", t1)
time.strftime('%Y-%m-%d %H:%M:%S', t1)os模块:
# 1. os.getcwd(): 获取当前工作目录
import os
current_directory = os.getcwd()
print("当前工作目录:", current_directory)
# 2. os.chdir(path): 改变当前工作目录
new_directory = "F:\\01.AI07.深度学习框架\\00.上课课件"
os.chdir(new_directory)
print("工作目录已更改为:", os.getcwd())
# 3. os.listdir(path='.'): 返回指定目录下的所有文件和目录列表
directory_path = "."
files_and_dirs = os.listdir(directory_path)
print("指定目录下的文件和目录列表:", files_and_dirs)
# 4. os.mkdir(path): 创建目录
new_directory = "new_folder"
os.mkdir(new_directory)
print(f"目录 '{new_directory}' 已创建")
# 5. os.rmdir(path): 删除目录
directory_to_remove = "new_folder"
os.rmdir(directory_to_remove)
print(f"目录 '{directory_to_remove}' 已删除")
# 6. os.remove(path): 删除文件
file_to_remove = "example.txt"
os.remove(file_to_remove)
print(f"文件 '{file_to_remove}' 已删除")1.3.2 第三方模块
由社区或公司开发,通过包管理工具(如pip )安装,用于实现更高级或更具体的功能,如数据科学、图像处理、网络爬虫等。
1.3.2.1 常见模块
那这可就太多了~这里随便举的例子
| 模块 | 功能 | 示例 |
|---|---|---|
numpy |
数值计算 | 科学运算、矩阵操作 |
pandas |
数据分析 | 数据清洗与处理 |
matplotlib |
数据可视化 | 绘制图表 |
requests |
HTTP请求处理 | 爬取网页内容,调用API |
flask |
Web应用框架 | 快速搭建Web服务 |
1.3.2.2 使用示例
-
安装模块:
pip install numpy pandas requests -
使用:
# numpy 模块 import numpy as np array = np.array([1, 2, 3]) print(array.mean()) # 输出: 平均值 2.0 # pandas 模块 import pandas as pd df = pd.DataFrame({"Name": ["Alice", "Bob"], "Age": [25, 30]}) print(df) # requests 模块 import requests response = requests.get("https://jsonplaceholder.typicode.com/posts/1") print(response.json())
1.3.3 自定义模块
-
用户自己编写的模块,用于复用代码。
-
文件名以 .py 结尾,存放自定义的函数、类等。
1.3.3.1 创建模块
创建一个utils.py文件:
# utils.py
def add(a, b):
return a + b
def greet(name):
return f"Hello, {name}!"1.3.3.2 使用模块
创建一个main.py文件,并导入自定义模块:
# main.py
import utils
print(utils.add(3, 5)) # 输出: 8
print(utils.greet("Alice")) # 输出: Hello, Alice!1.3.3.3 跨文件夹使用
假设目录结构如下:
project/
utils/
__init__.py
math_utils.py
main.py在main.py中:
from utils.math_utils import add
print(add(3, 5)) # 输出: 81.3.4 总结对比
| 分类 | 获取方式 | 使用场景 | 示例 |
|---|---|---|---|
| 系统模块 | 随Python自带 | 常用功能,性能高效 | math, os, random |
| 第三方模块 | pip 安装 | 高级功能,特定领域 | numpy, requests |
| 自定义模块 | 自己编写 | 项目特定需求,灵活控制 | utils.py |
2. 包
Package
2.1 基本概念
-
定义:
-
包是包含多个模块的目录。
-
包的本质是一个包含 __init__.py 文件的文件夹。
-
文件 __init__.py 可为空,也可以包含初始化代码。
-
-
作用:用于组织模块的集合,形成层次化的结构,便于管理大型项目。
-
结构:
my_package/ __init__.py module1.py module2.py subpackage/ __init__.py module3.py
2.2 导入包和子包
- 使用
import关键字可以导入包和子包,以访问其中的模块和内容。
# 同模块的导入规则
import 包名 [as 包别名]
import 包名.模块名 [as 模块新名]
import 包名.子包名.模块名 [as 模块新名]
from 包名 import 模块名 [as 模块新名]
from 包名.子包名 import 模块名 [as 模块新名]
from 包名.子包名.模块名 import 属性名 [as 属性新名]
# 导入包内的所有子包和模块
from 包名 import *
from 包名.模块名 import *参考案例:
# 导入包中的模块
import matplotlib.pyplot as plt
# 导入子包中的模块
from sklearn.linear_model import LinearRegression2.4 __init__.py文件
__init__.py 的作用
-
标识包:
-
__init__.py文件的存在标志着该目录是一个 Python 包。 -
如果没有
__init__.py文件,Python 会将目录视为普通目录,无法通过包的方式导入其中的模块。
-
-
初始化包:
-
当包或包中的模块被导入时,
__init__.py文件中的代码会自动执行。 -
可以在这里编写包的初始化逻辑,例如设置包级别的变量、导入子模块或执行其他初始化操作。
-
-
定义包的接口:
-
可以在
__init__.py中定义__all__变量,明确指定通过from package import *导入时哪些模块或对象是公开的。 -
也可以在
__init__.py中导入包内的模块或子包,简化用户的导入方式。
-
-
命名空间管理:
__init__.py文件可以帮助管理包的命名空间,确保包内的模块和子包能够正确导入和使用。
__all__ 的作用
-
控制
from module import \*的行为:-
默认情况下,
from module import *会导入模块中所有不以_开头的对象。 -
如果定义了
__all__,则只有__all__中列出的对象会被导入。
-
-
明确公开接口:
-
通过
__all__,开发者可以明确告诉用户哪些对象是模块或包的公开接口,哪些是内部实现细节。 -
这是一种良好的编程实践,有助于提高代码的可维护性和可读性。
-
-
防止意外导入:
-
如果没有
__all__,from module import *可能会导入一些不希望暴露的内部对象。 -
通过
__all__,可以避免这种情况。
-
示例1 :在 __init__.py 中定义变量
可以在 __init__.py 中定义包级别的变量
version = "1.0.0"在其它模块使用时:
import my_package
print(my_package.version) # 输出: 1.0.0示例2 :在 __init__.py 中导入模块
可以在 __init__.py 中导入包内的模块,简化用户的导入方式
# __init__.py
from .module1 import func1
from .module2 import func2在其它模块使用时:
from my_package import func1, func2
func1()
func2()示例3:使用 __all__ 定义公开接口
可以在 __init__.py 中定义 __all__,明确指定通过 from package import * 导入时哪些对象是公开的
# __init__.py
__all__ = ["func1", "func2"]
from .module1 import func1
from .module2 import func2使用时:
from my_package import *
func1()
func2()3. 模块与包的区别
| 模块 | 包 |
|---|---|
| 一个Python文件 | 一个包含__init__.py的文件夹 |
| 提供基本功能单元 | 用于组织多个模块 |
文件名为.py |
目录名 |
二、Python文件操作
文件操作是Python中常见的任务之一,用于创建、读取、写入和管理文件。以下是一些常见的文件操作任务的思路、总结和示例代码:
1. 打开文件
要执行文件操作,首先需要打开文件。使用open()函数可以打开文件,指定文件名以及打开模式(读取、写入、追加等)。

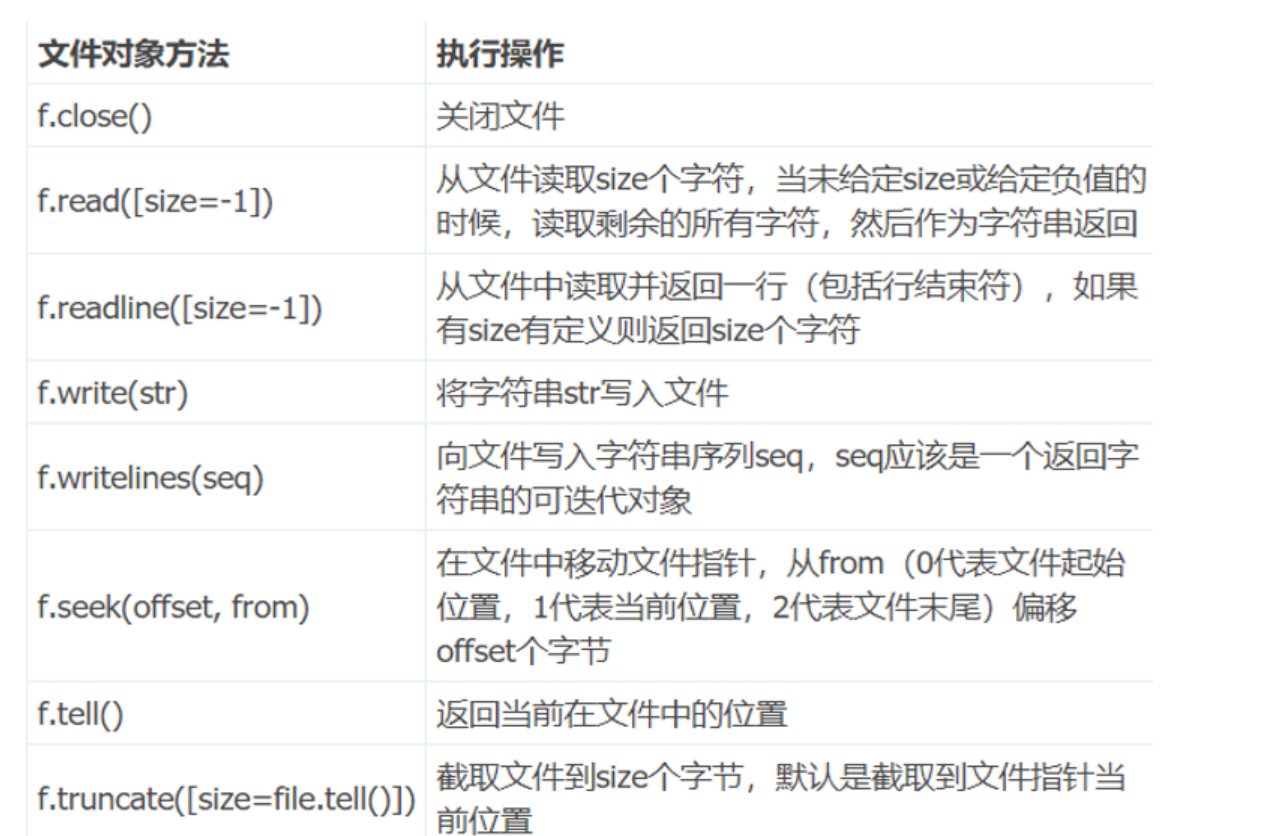
2. 读取文件
一旦文件被打开,可以使用不同的方法来读取文件内容。
# 打开一个文本文件以读取内容
file = open("example.txt", "r")
# 读取整个文件内容
content = file.read()
# 逐行读取文件内容
for line in file: #直接遍历文件对象,每次读取一行。这种方式更内存友好,因为不需要将所有行读入内存。
print(line)with open('example.txt', 'r') as file:
lines = file.readlines() # 读取文件的所有行,并将其作为一个列表返回。
for line in lines:
print(line, end='') 代码和file = open("example.txt", "r")for line in file:
print(line) 代码的区别3. 写入文件
要写入文件,需要打开文件以写入模式('w'),然后使用write()方法。
# 打开文件以写入内容
file = open("example.txt", "w")
# 写入内容
file.write("这是一个示例文本。")4. 关闭文件
完成文件操作后,应该关闭文件,以释放资源和确保文件的完整性。
file.close()5. 使用with
更安全的方法是使用with语句,它会自动关闭文件。
with open("example.txt", "r") as file:
content = file.read()
# 文件自动关闭6. 检查是否存在
可以使用os.path.exists()来检查文件是否存在。
import os
if os.path.exists("example.txt"):
print("文件存在")三、正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。re模块使Python拥有正则表达式功能。
1. 字符匹配
正则表达式在网络爬虫、数据分析中有着广泛使用,掌握正则表达式能够达到事半功倍的效果。
1.1 方法和功能
| 方法 | 功能 |
|---|---|
| match() | 判断一个正则表达式是否从开始处匹配一个字符串 |
| search() | 遍历字符串,找到正则表达式匹配的第一个位置,返回匹配对象 |
| findall() | 遍历字符串,找到正则表达式匹配的所有位置,并以列表的形式返回。如果给出的正则表达式中包含子组,就会把子组的内容单独返回,如果有多个子组就会以元组的形式返回。 |
| finditer() | 遍历字符串,找到正则表达式匹配的所有位置,并以迭代器的形式返回 |
- hqyj匹配文本中的hqyj
import re
text="hqyj牛皮6666,hqyj有个老师也牛皮666"
data=re.findall("hqyj",text)
print(data)#['hqyj', 'hqyj']- hqyj匹配h或者q或者y或者j字符
import re
text="hqyj牛皮6666,hqyj有个老师也牛皮666"
data=re.findall("[hqyj]",text)
print(data)#['h', 'q', 'y', 'j', 'h', 'q', 'y', 'j']import re
text="hqyj牛皮6666,hqyj有个老师也牛皮666"
data=re.findall("[hqyj]牛",text)
print(data)#['j牛']- \^hqyj匹配除了hqyj以外的其他字符
import re
text="hqyj牛皮6666,hqyj有个老师也牛皮666"
data=re.findall("[^hqyj]",text)
print(data)#['牛', '皮', '6', '6', '6', '6', ',', '有', '个', '老', '师', '也', '牛', '皮', '6', '6', '6']
- a-z匹配a~z的任意字符(0-9也可以)
import re
text = "hqyj牛皮6666,hqyj有个老师abchqyj也牛皮666"
data = re.findall("[a-z]hqyj", text)
print(data) # ['chqyj']- .匹配除了换行符以外的任意字符
import re
text="hqyj牛皮6666,hqyj有个老师abchqyj也牛皮666"
data=re.findall(".hqyj",text)
print(data)#[',hqyj', 'chqyj']import re
text="hqyj牛皮6666,hqyj有个老师abchqyj也牛皮666"
data=re.findall(".+hqyj",text) #贪婪匹配(匹配最长的)
print(data)#['hqyj牛皮6666,hqyj有个老师abchqyj']import re
text="hqyj牛皮6666,hqyj有个老师abchqyj也牛皮666"
data=re.findall(".?hqyj",text)
print(data)#['hqyj', ',hqyj', 'chqyj']1.2 特殊字符
| 特殊字符 | 含义 |
|---|---|
| \d | 匹配任何十进制数字;相当于类 0-9 |
| \D | 与 \d 相反,匹配任何非十进制数字的字符;相当于类 0-9 |
| \s | 匹配任何空白字符(包含空格、换行符、制表符等);相当于类 \\t\\n\\r\\f\\v |
| \S | 与 \s 相反,匹配任何非空白字符;相当于类 \t\n\r\f\v |
| \w | 匹配任意一个文字字符,包括大小写字母、数字、下划线,等价于表达式a-zA-Z0-9_ |
| \W | 于 \w 相反 (注:re.ASCII 标志使得 \w 只能匹配 ASCII 字符) |
| \b | 匹配单词的开始或结束 |
| \B | 与 \b 相反 |
- \w 匹配字母数字下划线(汉字)
import re
text = "华清_远见abc 华清hqyj远见 华清牛皮远见"
data = re.findall(r"华清\w+远见", text)
print(data) # ['华清_远见', '华清hqyj远见', '华清牛皮远见']- \d匹配数字
import re
text = "hqyj66d6 a1h43d3fd43s43d4 "
data = re.findall(r"d\d", text) # 只匹配一个数字
print(data) # ['d6', 'd3', 'd4', 'd4']import re
text = "hqyj66d6 a1h43d3fd43s43d4 "
data = re.findall(r"d\d+", text)
print(data) # ['d6', 'd3', 'd43', 'd4']- \s匹配任意空白符 包括空格,制表符等等
import re
text = "hqyj666 jack karen 666"
data = re.findall(r"\sj\w+\s", text)
print(data) # [' jack ']2. 数量控制
控制匹配规则的重复次数~
2.1 *重复0次或多次
import re
text="华清远见 华清666远见"
data=re.findall("华清6*远见",text)
print(data)#['华清远见', '华清666远见']2.2 +重复1次或多次
import re
text="华清远见 华清666远见 华清6远见"
data=re.findall("华清6+远见",text)
print(data)#['华清666远见', '华清6远见']2.3 ?重复1次或0次
import re
text="华清远见 华清666远见 华清6远见"
data=re.findall("华清6?远见",text)
print(data)#['华清远见', '华清6远见']2.4 {n}重复n次
import re
text="华清远见 华清666远见 华清6远见"
data=re.findall("华清6{3}远见",text)
print(data)#['华清666远见']2.5 {n,}重复n次或多次
import re
text="华清远见 华清666远见 华清6远见 华清66远见"
data=re.findall("华清6{2,}远见",text)
print(data)#['华清666远见', '华清66远见']2.6 {n,m}重复n到m次
import re
text="华清远见 华清666远见 华清6远见 华清66远见"
data=re.findall("华清6{0,2}远见",text)
print(data)#['华清远见', '华清6远见', '华清66远见']3. 分组
- ()提取兴趣区域
import re
text = "谢帝谢帝,我要迪士尼,我的电话号码18282832341,qq号码1817696843"
data = re.findall(r"号码(\d{10,})", text)
print(data) # ['18282832341', '1817696843']import re
text = "谢帝谢帝,我要迪士尼,我的电话号码18282832341,qq号码1817696843"
data = re.findall(r"(\w{2}号码(\d{10,}))", text)
print(data) # ['18282832341', '1817696843']- (|)提取兴趣区域(| = or)
import re
text = "第一名张三 第一名物理149分 第一名数学150分 第一名英语148分 第一名总分740分"
data = re.findall(r"第一名(\w{2,}|\w{2,}\d{2,}分)", text)
print(data) # ['张三', '物理149分', '数学150分', '英语148分', '总分740分']4. 开始和结束
- ^开始
import re
text = "hqyj66abc hqyj123"
data = re.findall(r"^hqyj\d+", text)
print(data) # ['hqyj66']- $结尾
import re
text = "hqyj66abc hqyj123"
data = re.findall(r"hqyj\d+$", text)
print(data) # ['hqyj123']5. 特殊字符
由于正则表达式中* . \ {} () 等等符号具有特殊含义,如果你指定的字符正好就是这些符号,需要用\进行转义
import re
text = "数学中集合的写法是{2}"
data = re.findall(r"\{2\}", text)
print(data) # ['{2}']6. 常用方法
6.1 re.findall
获取匹配到的所有数据
import re
text="hqyj66d6 a1h43d3fd43s43d4 "
data=re.findall("d\d+",text)
print(data)#['d6', 'd3', 'd43', 'd4']6.2 re.match
从字符串的起始位置匹配,成功返回一个对象否则返回none。
匹配成功返回对象,对象的方法:
| 方法 | 功能 |
|---|---|
| group() | 返回匹配的字符串 |
| start() | 返回匹配的开始位置 |
| end() | 返回匹配的结束位置 |
| span() | 返回一个元组表示匹配位置(开始,结束) |
import re
# 在起始位置匹配,并返回一个包含匹配 (开始,结束) 的位置的元组
print(re.match('www', "www.python.com").span()) # (0, 3)
print(re.match('www', "www.python.com").start()) # 0
print(re.match('www', "www.python.com").end()) # 3
# 不在起始位置匹配
print(re.match('com', "www.python.com")) # None6.3 re.search
扫描整个字符串并返回第一个成功匹配的字符串。成功返回一个对象否则返回none
import re
# 在起始位置匹配
print(re.search('www', 'www.hqyj.com').span()) # (0, 3)
# 不在起始位置匹配
print(re.search('com', 'www.hqyj.com').span()) # (9, 12)6.4 re.sub
替换匹配成功的字符
类似与字符串的replace函数
import re
text = "以前华清远见在四川大学旁边,现在华清远见在西南交大旁边"
data = re.sub("华清远见", "北京华清远见科技集团成都中心", text)
print(data) # 以前北京华清远见科技集团成都中心在四川大学旁边,现在北京华清远见科技集团成都中心在西南交大旁边6.5 re.split
根据匹配成功的位置对字符串进行分割
import re
text = "python is very easy"
data = re.split(r"\s{1,}", text)
print(data) # ['python', 'is', 'very', 'easy']dd6.6 re.finditer
类似findall 但是不会全部返回出来 而是返回迭代器(比如匹配成功了10万个 全部返回就很吃内存了)
import re
text = "python is very easy"
data = re.findall(r"\w+", text)
print(data) # ['python', 'is', 'very', 'easy']import re
text = "python is very easy"
data = re.finditer(r"\w+", text)
print(data)
for el in data:
print(el.group())