文章目录
- [1. 初步理解线程](#1. 初步理解线程)
- 2.分页式存储管理
-
- [2.1 为什么要有虚拟地址](#2.1 为什么要有虚拟地址)
- [2.2 物理内存管理](#2.2 物理内存管理)
- [2.3 页表](#2.3 页表)
- [2.4 TLB](#2.4 TLB)
- [3. 进程与线程](#3. 进程与线程)
-
- [3.1 进程与线程的关系](#3.1 进程与线程的关系)
-
- [3.1.1 如何描述线程](#3.1.1 如何描述线程)
- [3.1.2 进程是如何分配资源到不同线程的](#3.1.2 进程是如何分配资源到不同线程的)
- [3.1.3 pid、tid、tgid](#3.1.3 pid、tid、tgid)
- [3.2 线程的优缺点](#3.2 线程的优缺点)
- [4. 线程控制](#4. 线程控制)
-
- [4.1 线程的创建](#4.1 线程的创建)
- [4.2 线程的终止](#4.2 线程的终止)
- [4.3 线程等待](#4.3 线程等待)
- [4.4 线程分离](#4.4 线程分离)
- [5. 深入理解线程](#5. 深入理解线程)
-
- [5.1 线程局部存储TLS](#5.1 线程局部存储TLS)
- [5.2 线程栈](#5.2 线程栈)
- [5.3 clone](#5.3 clone)
1. 初步理解线程
在之前的认知中,进程=内核数据结构+相应的代码和数据,而线程可以理解为进程内部的一个控制流。
从内核和资源的角度去理解,进程是操作系统分配资源的基本单位,而线程是CPU调度的基本单位。
一个进程中可以只有一个线程,也可以有多个线程。通俗地讲,一个进程是为一个任务而产生的,操作系统要为这个任务分配相应的资源,而在这个任务内部,又同时分为多个小任务来完成,而这些每个小任务就对应着整体资源中的一部分,进而作为被CPU调度的基本单位。
那么,Linux中是如何实现线程的呢,又是如何完成线程资源划分的呢,其它操作系统中,又是如何实现线程的呢?
这些问题,我们放到之后再讲。
2.分页式存储管理
现在,我们再来谈一谈进程的虚拟地址空间,准确来说是相应的页表结构。
从虚拟地址向物理地址的转换,借助了分页式存储管理,也就是页表,但实际上页表的结构并不仅仅是一张表。
2.1 为什么要有虚拟地址
如果没有虚拟地址,那么每一个进程都要对应一块连续的空间,而不同的进程间,所对应的连续空间是不同的,而当进程退出时,相应的空间才会被完全释放,因此如果没有虚拟地址到物理地址的转换, 而直接使用物理地址,很容易造成物理内存的碎片化。
而使用页表结构,通过虚拟地址到物理地址的映射,这样只要保证虚拟地址的连续性,物理地址不需要连续,两者之间通过页表进行解耦合,从而使得物理内存碎片化大大减少。
2.2 物理内存管理
关于物理内存,操作系统又进行了额外的管理。
前面学过,操作系统与磁盘间进行I/O 的基本单位是4KB,也就是八个扇区,与之相对应的,在操作系统看来,物理内存也是以4KB为单位进行划分的。
在操作系统中,有一个结构体struct page用来描述相应的物理内存,每一个struct page对应一个4KB的物理内存。
所以,对于一个32位的操作系统而言,总共有4GB的物理内存,每一个4KB的物理内存用一个struct page来描述,所有的物理内存就对应有1024*1024 ,大约也就是100万左右个struct page,当然这么多的struct page,操作系统肯定要将这些struct page管理起来,不过在此处管理方法就不介绍了。
一个struct page结构体,在设计的时候,就不会设计得很大,因为数量很多,其中最常见的成员就是引用计数以及相应的状态标志位flag 。假设一个struct page在40个字节左右,那么所有的struct page也不过是40MB左右,4GB的物理内存存储40MB的内容,是完全没问题的。
所以,在操作系统层面,申请物理地址并进行分配的时候,就是一个struct page,以4KB为单位进行分配的,同时引入虚拟地址以及页表的结构,这样就解决了物理内存碎片化的问题。
2.3 页表
讲了为什么有虚拟地址,和物理内存的管理方式,接下来我们就来了解实际的页表结构。
在32位的操作系统中,一个物理页(也称页框或页帧)对应的是4KB,而一个64位的操作系统中,一个物理页对应的是8KB。
接下来关于页表的介绍,以32位的操作系统为例。
首先,我们这样思考。
如果没有物理页这样的结构,也就是虚拟地址到物理地址间以字节为单位 进行映射,那么这样页表花费的空间是巨大的,一个虚拟地址,要对应到一个物理地址。两个地址,在32位的操作系统中,一共是8个字节,而4GB的内存空间,对应有2^32个地址 ,也就是有32GB的内存空间来存储一个页表,那么这样显然是不现实的。而如果页表中只保存相应的物理地址,那么也需要16GB,是不可能的。
所以,引入struct page的结构后,物理内存以8KB为单位。那么页表中的每一项对应一个4KB的物理内存的起始地址,也就是4字节,而总共需要2^20个页表项,也就是需要4MB的内存空间,来存储一张页表。
这样还是太大了。因为一个进程,对应一张页表结构,而进程数目很多,一张页表就占了4MB的大小,所占内存还是太大。而实际上,对于一个进程而言,所使用的内存空间是不可能完全占用4GB的,因此有一些页表项是没有意义的。
因此,在Linux操作系统中,引入多级页表的结构。
要想映射满4GB的内存空间,需要1024*1024个地址,而我们将1024个地址放入一张页表结构中,再构建一个页目录表,其中有1024个地址,分别指向1024张页表。
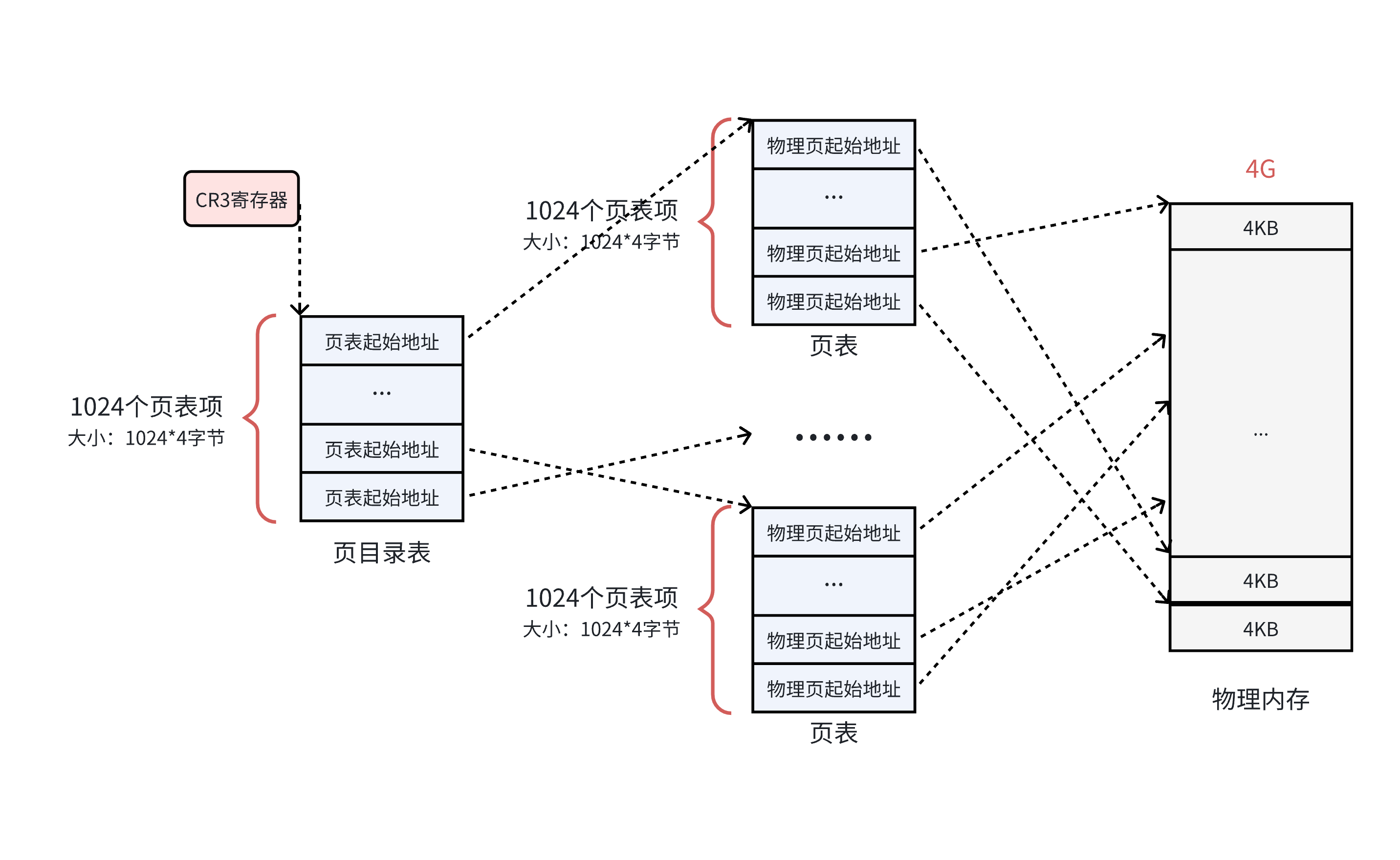
在这样的设计下,一个进程,只需要创建一张页目录表,页目录表中,保存实际页表的起始地址,而此时一个页表只占4KB的大小。
在这样的结构中,可以做到将4GB的物理内存空间全部映射满,但实际上一般不可能,也就是说,实际上不会创建1024张页表。比如一个10MB的程序,如果全部加载到内存中,除了一张页目录表,也就需要额外的三张页表(向上取整)即可,也就是在页表结构上,需要16KB的存储空间,此时就远小于4MB了。同时,在这样的分页存储结构下,根据程序的局部性原理,一时间内,不需要让所有的页表结构都常驻内存,而这样就使得页表所需的内存空间就更小了。
但这里会引申出一个问题,我们实际使用虚拟地址的时候,本质上都是按字节访问的,可是这里的页表结构都是对应到一个struct page,对应到一个4KB的单位,那这样是如何实现按字节访问的呢?
我们模拟一遍整个的虚拟地址到物理地址转换的过程。
- 在CPU中的CR3寄存器中,存储了当前进程的页目录表地址。
- 通过CR3寄存器,找到页目录表的地址后,就需要知道对应的是页目录表中的哪个页表。通过虚拟地址的高10位的大小,可以知道是第几个页表。
- 知道是第几个页表后,如何知道在这个页表的1024个对应的物理页中,是哪个物理页呢?通过虚拟地址的中间10位的大小,可以知道是第几个物理页。
- 那么定位到是哪个物理页后,也只能拿到具体的4KB,如何定位到字节呢?通过虚拟地址的低12位,也就是说,虚拟地址的低12位,也就是对应的页内偏移量,这样就可以定位到字节。
以上过程中,有几点需要注意:
- 由于页内偏移量是通过虚拟地址确定的,因此页表项(页表中的项)的32位数据中并不需要存储偏移量,而页表项中也不是存储实际的物理页地址,而是存储一个物理页帧号。
- 之前讲过,操作系统需要将所有的struct page管理起来,而操作系统中有这样的一个结构 void* struct page_memN,这就是一个数据,里面存储了1024*1024个指针,分别指向对应的struct page,完成从0~4GB的映射。因此在一个页表项中,一个32位的数据,我们只需要用其高20位的数据存储物理页帧号(左移12位即为相应的物理页起始地址),而低12位则可以存储一些标志位,用以记录相应的物理内存空间的权限等,如读写权限。
2.4 TLB
由于单级页表的大小为4MB,不仅空间大,而且对连续内存空间的要求高,所以引入多级页表进行解决,但多级页表由于进行了多级映射,效率会低于单级页表,因此引入一个在内存管理单元MMU中引入一个新的模块TLB进行常用虚拟地址到物理地址的转换。
实际中,MMU查地址时,首先将虚拟地址,转换为虚拟页号,然后使用该虚拟页号到TLB中查看是否有对应的物理页号,如果有,就不需要到多级页表结构中去多次查找了,进而大大提高效率。如果没有,就将相应的PTE添加到TLB中,以方便下次可能的再次查找。
所以,TLB实际上就是用来缓存页表项,完成VPN到PFN,即虚拟页号,到物理页框号的转换,同时TLB有自己的一套较为复杂的缓存更新机制。
3. 进程与线程
3.1 进程与线程的关系
现在,我们来解决上面的两个问题。
3.1.1 如何描述线程
Linux中,是如何描述线程的?
实际上,根据先描述,再组织 的原理,在Linux中,应该要有一个结构体用来描述线程,然后再将这些结构体组织起来,并为组织起来的这个整体重新设计一套调度算法等。但是这样,操作系统代码的健壮性就太低了,既要维护进程,同时也要维护线程,在Linux中,并不是这样实现的。
在Linux 中,根据everything is a task 的指导思想,Linux中,进程与线程共用的是同一个结构task_struct,更准确地来说,在Linux系统中,进程与线程并不被严格区分,而是统一用一个轻量级进程的概念用以替代。
Linux操作系统中的一个task_struct就对应一个轻量级进程,Linux操作系统针对轻量级进程,也就设计了一套维护管理的机制。在CPU看来,每次调度的也就是一个轻量级进程,也就是一个线程。
平时,我们在初学阶段,最常创建的进程,内部只有一个线程,而多线程的进程实际上是非常常见的。Linux在task_struct中,有相应的struct list_head将同一进程中的线程联系在一起,进而在宏观层面上,就不需要一个额外的结构体再去描述进程。
3.1.2 进程是如何分配资源到不同线程的
前面说过,进程是分配资源的基本单位,而线程是CPU调度的基本单位,实际的任务,是由线程去完成的。
一个进程中,所有线程共用一个进程地址空间,但是不同的线程实际上执行的代码不同,进而也就拿到了不同的资源。
准确来说,一个进程的虚拟地址划分到了不同的线程中,不同的线程分别拥有不同的虚拟地址范围,进而执行不同的代码,从而达到进程的资源划分。
那么线程的资源共享又是什么回事?本质上,同一个进程中的线程是共享进程地址空间,也是共享页表的。资源划分,是虚拟地址的划分,也就是页表条目的划分;资源共享,本质就是虚拟地址的共享,也就是页表条目的共享。
接下来介绍一些,常见的线程共享和独立的资源。
共享:进程地址空间、页表、文件描述符表、信号的处理方法、进程级信号的pending表(非实时信号)等等
私有:信号屏蔽字、线程级信号的pending表(也就是实时信号,即可靠信号的pending表)
3.1.3 pid、tid、tgid
在task_struct中,有pid/tid/tgid这三个成员,如何区分呢?
pid和tid本质上是同一个东西,都是线程的唯一id。我们可以使用gettid()这个接口,来得到。
tgid本质上是线程组id,也就是一个进程中第一个线程的pid,或者说tid。getpid()本质上是返回线程组id,也就是进程id,更准确地讲,是该进程中的第一个线程的id,并以此作为整个线程组的id。
3.2 线程的优缺点
线程的优点:
- 创建一个线程,要比创建一个进程的代价小很多。
- 在I/O密集型的任务中,多线程能够大大发挥处理器的并行优势,提高任务的运行效率
- 线程切换,相较于进程切换,代价小很多。进程切换要带来CR3寄存器中地址的切换,同时TLB中的缓存也要更新,以及CPU内部用于缓存内存数据的cache硬件也要更新,这样会导致接下来一段时间的内存访问都会很慢,代价比较大;而线程切换,不需要更新这些东西,因此代价很小。
当然,线程也有很多缺点。
线程的缺点:
- 缺乏访问控制。进程是访问控制的基本粒度,在线程中调用某些系统调用,可能会对整个进程造成影响,比如在线程中给线程自身发送一些终止信号,会使得整个进程终止。
- 多线程访问共享资源,如果缺少同步互斥机制的保护,那么多线程就是不安全的,代码的健壮性会降低。
- 在计算密集型任务中,多线程的并发往往会降低运行的效率。
- 多线程程序的调试要远远繁杂于单线程。
4. 线程控制
了解完线程的基本知识后,接下来来介绍线程的创建、终止、等待和分离。
需要特别注意的是,线程的相关系统调用都在线程库中,线程库严格来说不是C语言的库,而是一个外部库,但是它属于Linux原生库,在安装Linux系统时,默认会安装的原生库。
因此,在使用相关系统调用后,编译时需要加上-lpthread这个选项。
4.1 线程的创建

这个是用于创建线程的系统调用。
thread:该参数是用来在用户层面标识不同线程的,本质是一串数字,更准确来说是一个虚拟地址。
attr:这个参数是用来设置线程属性的,传空指针即可,表示默认属性。
start_routine:这个参数本质是一个函数指针,是用来传线程的入口函数的,也正是通过这个参数,实现了不同的线程执行不同的代码,进而访问不同的资源。
arg:这个参数代表的是start_routine中的形参,由用户传入,最终在系统调用中,在传给相应的start_routine这个入口函数。
关于返回值,如果创建线程成功,则返回0;否则,返回一个error number
4.2 线程的终止
线程有三种终止方式,两种是线程自身终止自身,另外一种则通常由主线程进行终止其它线程。
自身终止自身:
- 线程内部通过return返回。
- 线程内部调用pthread_eixt()函数。

这个函数用来使得自身线程退出,需要传入一个指向相应线程的返回值的参数,一定要是一个全局的变量,通常动态开辟在堆上,这个参数用来记录线程返回值。
主线程终止其它线程:

pthread_cancel:一般在主线程中使用,由主线程终止其它线程。
需要特别说明的是,除了主线程终止其它线程外,还可用于线程自身终止自身。但是,这个终止,仅为发送终止请求,实际是否终止,要看是否存在终止点------大部分的系统调用,读写函数,sleep之类的接口都属于终止点,在调用这些接口前,操作系统都会检测是否存在终止请求,如果存在终止请求,则会终止相应线程。
当然,除了上述终止点外,还可以用一个专门的接口来相应终止请求------pthread_testcancel(),这个接口可以用来专门相应终止请求。
4.3 线程等待
线程等待,类似于进程等待,退出的线程相应的资源不会立刻被释放,而是要由主线程等待接收相应的返回值之后,才会释放相应的资源。

这个函数用于等待回收相应的线程,等待的行为是阻塞等待。thread对应为相应线程,retval用于获得指向相应线程的返回值的指针。
4.4 线程分离
线程分离与上面的线程等待是息息相关的。
退出线程的不会立即释放相应资源,主要是用于主线程中进行线程等待获取相应的退出码,因此默认创建的新线程都是join状态的。
但是,有的线程,我们就想让其直接退出后就释放相应的线程级资源,而不想获得退出码,此时就可以使用线程分离,使得相应线程的状态为detach。

线程分离,可以是主线程对其它线程进行分离,也可以线程自身对自身进行分离,不过自身分离时,要使用到下面这个函数以获取自身的thread号。

需要注意的是,joinable和分离的状态是冲突的,一个线程只能是其中的一种状态。
另外就是,线程分离本质是将线程的状态由joinable设置为detach,所以线程结束与否并不重要,只要线程对应的线程级资源还未释放,都可以进行该操作。
5. 深入理解线程
现在,让我们来深入理解线程。

在操作系统层面,每一个线程都有唯一的pid或者说tid号唯一标识,之前讲过,在用户层面,用一个类型为pthread_t 的变量唯一标识线程,那么这到底是什么?

实质上,这个类型就是一个无符号长整型,更深入讲,其数值本质上会是一个地址,但为什么要用一个地址来唯一标识线程呢?
我们这就要讲Linux中NPTL,即原生线程库中的设计了。在系统层面,并没有一个专门描述线程的结构体,而原生线程库,为了更好地操作管理线程,自身在用户层面设计了一个专门用于线程的结构体------struct thread
这个结构体实质就是对内核中的task_struct的进一步封装,有很多相同的东西,但是也有很多新的专门为用户层面线程所设计的东西。
所以,之前所讲的pthread_t pthread所代表的地址,实际上就是相应线程在用户层面所对应的struct pthread的地址。
那么这个用户层面的struct pthread,具体是存放在进程地址空间的什么位置呢?
Linux原生线程库,是一个动态库,进行链接时重定向,这个动态库会映射到进程地址空间的共享区,而这个共享区正是struct pthread被创建并且维护的区域。
所以,返回的地址,是struct pthread在共享区中的地址。
struct pthread这个结构体中维护了很多东西,不过需要特别说明的有两个:一个是线程局部存储,即TLS;还有一个是线程栈。
5.1 线程局部存储TLS
在多线程中,多线程的高并发访问公共资源,是很容易出BUG的。因此,原生线程库中设计一种线程局部存储的解决方法------将一个公共变量用一个thread_local关键字进行声明,在多线程中,任何一个线程对用thread_local声明的公共变量进行访问,本质都是对自己私有的一个相同的拷贝变量进行访问。
所以,通过线程局部存储,对于原本一份公共资源,每个线程实际都是在访问自己的私有资源,也就不会出现多线程的并发访问问题了。
另外,需要特别说明的是,thread_local关键字声明TLS,是C++11之后才引入的,使用起来非常方便;而对于POISIX C标准中,实现线程局部存储会使用pthread_key_t这个类型,需要通过相应接口手动维护,比较不方便。
最后,再来讲一讲线程局部存储的原理。由于thread_local用来声明公共资源,而公共资源往往定义在全局,因此thread_local声明后的变量,同样具有全局作用域,只不过每个线程都有一个自己对应的副本,存储在自身线程对应的TLS存储空间中。
5.2 线程栈
除了主线程,其余的线程也都有自己的入口函数,而函数调用执行的过程与函数栈帧密不可分,因此NPTL也会为每一个线程开辟一块独立空间用以维护线程栈空间。 这个栈空间与主线程的栈空间类似,一般都是固定大小为8MB,通过保护页机制进行内存保护。
5.3 clone
之前我们都是使用pthread_create来创建多线程,但实际上,这个接口底层是使用专门的系统调用clone来创建多线程。
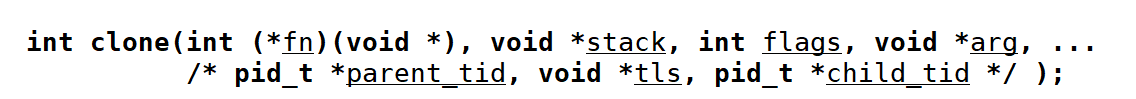
这个系统调用使用的是可变参数,为我们使用者提供了很大的自主性,可以通过参数的传入来控制新线程的很多属性。
例如,fn就是相应的入口函数指针,stack即对应线程栈的起始地址(可以指定),arg即入口函数相应的传入参数等等。