缓冲池的作用:缓存表数据与索引数据,把磁盘上的数据加载到缓冲池,避免每次访问都进行磁盘IO,起到加速访问的作用。
速度快,那为啥不把所有数据都放到缓冲池里?
凡事都具备两面性,抛开数据易失性不说,访问快速的反面是存储容量小:
因此,只能把"最热"的数据放到"最近"的地方,以"最大限度"的降低磁盘访问。
预读
磁盘读写,并不是按需读取,而是按页读取,一次至少读一页数据(一般是4K),如果未来要读取的数据就在页中,就能够省去后续的磁盘IO,提高效率。
预读的作用
数据访问,通常都遵循"集中读写"的原则,使用一些数据,大概率会使用附近的数据,这就是所谓的"局部性原理",它表明提前加载是有效的,确实能够减少磁盘IO。
LRU(Least recently used)算法
InnoDB是用LRU算法来管理这些缓冲页呢
LRU可以用Hash + 双向链表来实现:Hash存数据,链表来维持使用的情况(LeetCode有这个题目:https://leetcode.cn/problems/lru-cache/description/)。
这里又分两种情况:
- 页已经在缓冲池里,那就只做"移至"LRU头部的动作,而没有页被淘汰;
- 页不在缓冲池里,除了做"放入"LRU头部的动作,还要做"淘汰"LRU尾部页的动作;
LRU存在的问题
(1)预读失效:提前把页放入了缓冲池,但最终MySQL并没有从页中读取数据,称为预读失效
(2)缓冲池污染:当某一个SQL语句,要批量扫描大量数据时,可能导致把缓冲池的所有页都替换出去,导致大量热数据被换出,MySQL性能急剧下降
LRU优化
为了解决缓冲池污染问题,对LRU进行了优化,引入新生代和老生代。数据首次被放入缓冲池时,只放入老生代。
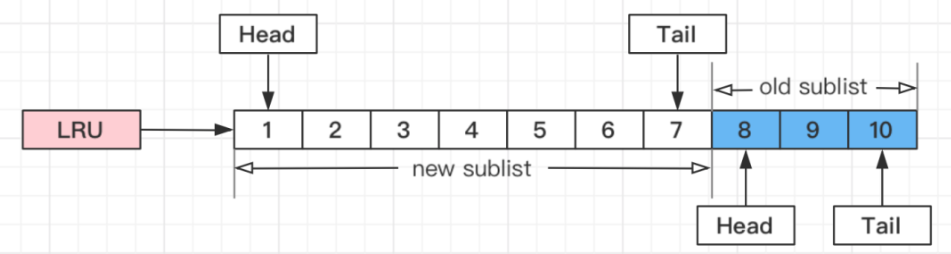
相关配置:
innodb_old_blocks_pct:老生代占整个LRU链长度的比例,默认是37,即整个LRU中新生代与老生代长度比例是63:37。
如果把这个参数设为100,就退化为普通LRU了。
innodb_old_blocks_time:老生代停留时间窗口,单位是毫秒,默认是1000,即同时满足"被访问"与"在老生代停留时间超过1秒"两个条件,才会被插入到新生代头部。
总结
(1)缓冲池(buffer pool)是一种常见的降低磁盘访问的机制;
(2)缓冲池通常以页(page)为单位缓存数据;
(3)缓冲池的常见管理算法是LRU,memcache,OS,InnoDB都使用了这种算法;
(4)InnoDB对普通LRU进行了优化:
将缓冲池分为老生代和新生代,入缓冲池的页,优先进入老生代,页被访问,才进入新生代,以解决预读失效的问题
页被访问,且在老生代停留时间超过配置阈值的,才进入新生代,以解决批量数据访问,大量热数据淘汰的问题