目录
[六、Hue 数据可视化实例](#六、Hue 数据可视化实例)
[1. Impala 查询](#1. Impala 查询)
[2. DB 查询](#2. DB 查询)
[3. 建立工作流](#3. 建立工作流)
六、Hue 数据可视化实例
本节先用 Impala、DB 查询示例说明 Hue 的数据查询和可视化功能,然后交互式地建立一个定期执行销售订单示例 ETL 任务的工作流,说明在 Hue 里是如何操作 Oozie 工作流引擎的。
1. Impala 查询
在 Impala OLAP 实例一节中执行了一些查询,现在在 Hue 里执行查询,直观看一下结果的图形化表示效果。
(1)登录 Hue,点击
(2)点击
(3)点击
(4)在 Impala 查询编辑页面,选择 olap 库,然后在编辑窗口输入下面的查询语句。
sql
-- 按产品分类查询销售量和销售额
select t2.product_category pro_category,
sum(order_quantity) sum_quantity,
sum(order_amount) sum_amount
from sales_order_fact t1, product_dim t2
where t1.product_sk = t2.product_sk
group by pro_category
order by pro_category;
-- 按产品查询销售量和销售额
select t2.product_name pro_name,
sum(order_quantity) sum_quantity,
sum(order_amount) sum_amount
from sales_order_fact t1, product_dim t2
where t1.product_sk = t2.product_sk
group by pro_name
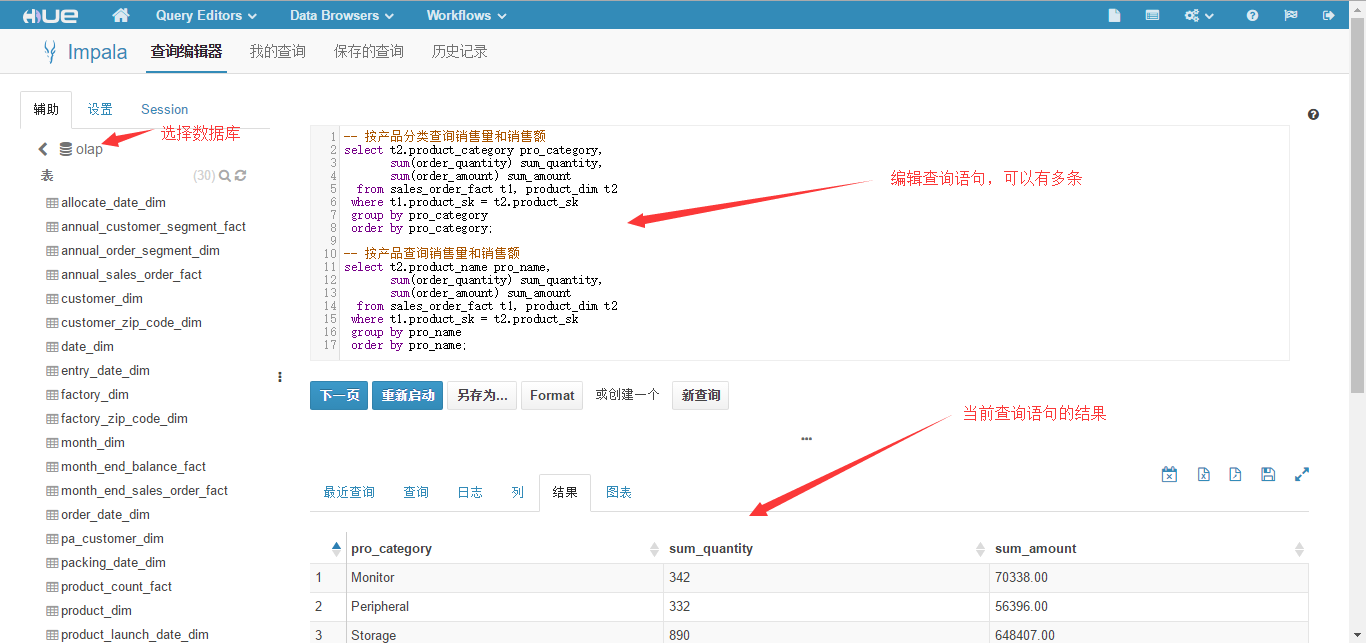
order by pro_name;点击"执行"按钮,结果显示按产品分类的销售统计,如下图所示。接着点击"下一页"按钮,结果会显示按产品的销售统计。
(5)点击 "全屏查看结果"按钮,会全屏显示查询结果。
产品统计结果如下图所示。
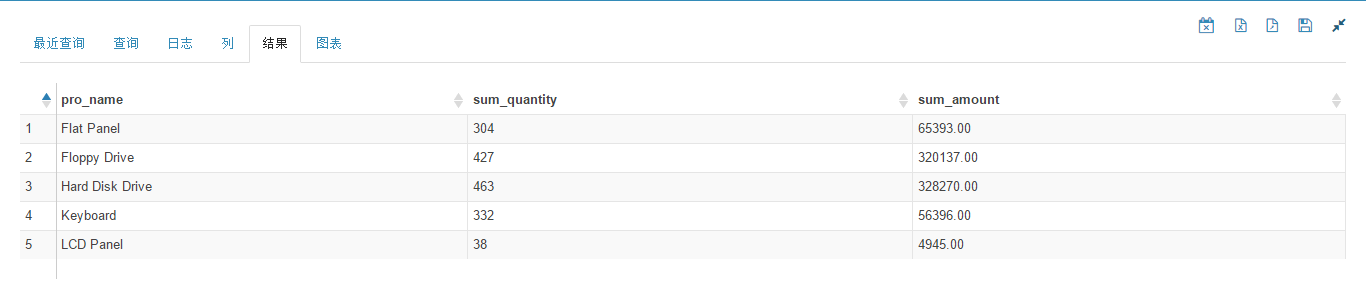
产品统计柱状图如下图所示。
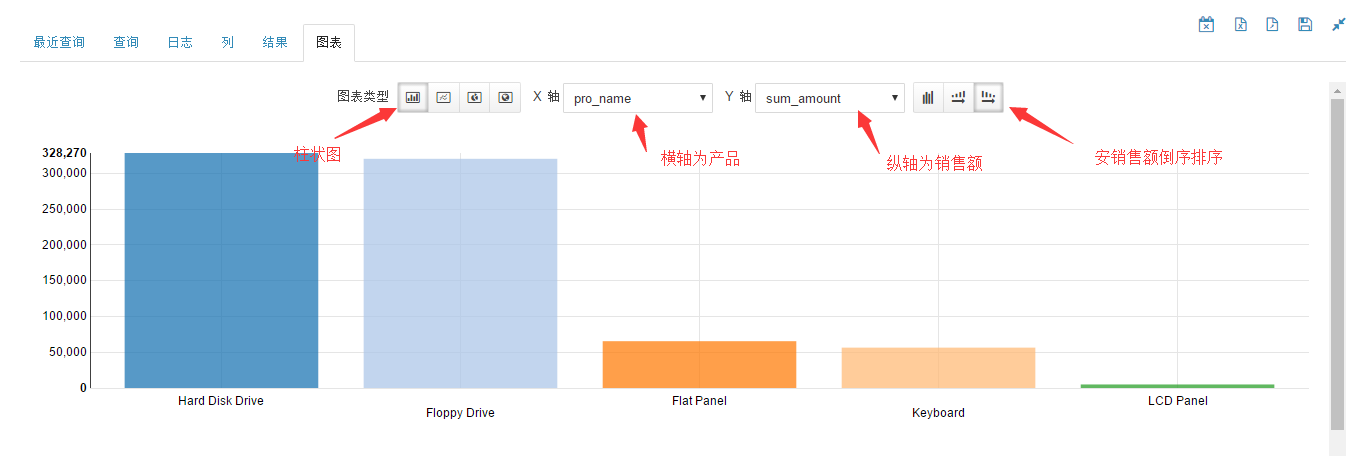
从图中可以看到,按销售额从大到小排序的产品依次为 Hard Disk Drive、Floppy Drive、Flat Panel、Keyboard 和 LCD Panel。
(6)回到查询编辑页,点击"另存为..."按钮,保存成名为"按产品统计"的查询。
(7)点击"新查询"按钮,按同样的方法再建立一个"按地区统计"的查询。SQL 语句如下。
sql
-- 按州查询销售量和销售额
select t3.state state,
count(distinct t2.customer_sk) sum_customer_num,
sum(order_amount) sum_order_amount
from sales_order_fact t1
inner join customer_dim t2 on t1.customer_sk = t2.customer_sk
inner join customer_zip_code_dim t3 on t1.customer_zip_code_sk = t3.zip_code_sk
group by state
order by state;
-- 按城市查询销售量和销售额
select t3.city city,
count(distinct t2.customer_sk) sum_customer_num,
sum(order_amount) sum_order_amount
from sales_order_fact t1
inner join customer_dim t2 on t1.customer_sk = t2.customer_sk
inner join customer_zip_code_dim t3 on t1.customer_zip_code_sk = t3.zip_code_sk
group by city
order by city;城市统计饼图如下图所示。
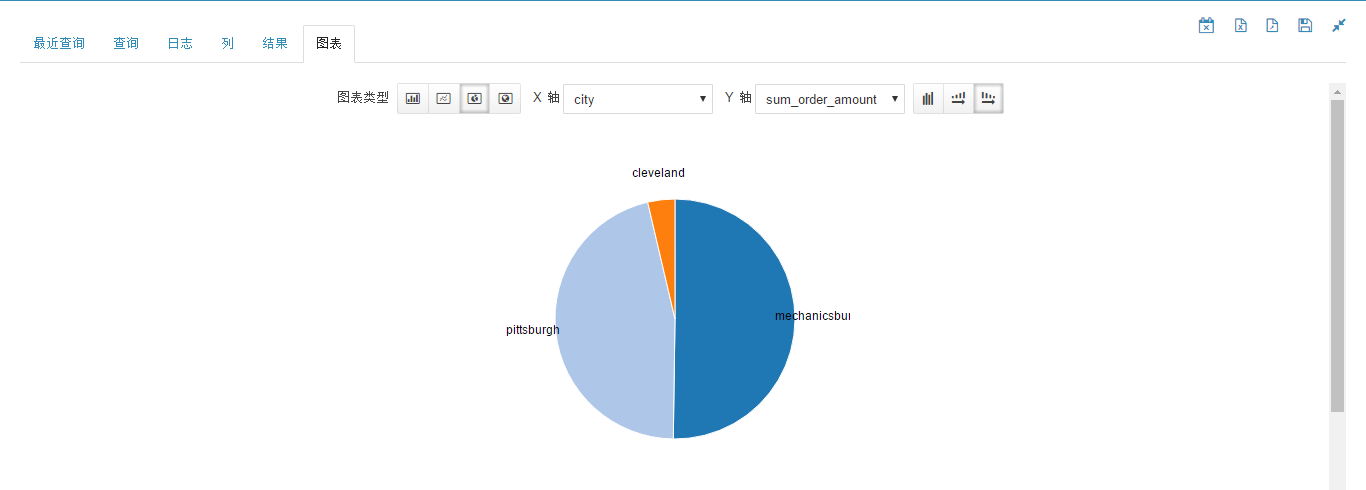
从图中可以看到,mechanicsburg 市的销售占整个销售额的一半。
(8)再建立一个"按年月统计"的查询,这次使用动态表单功能,运行时输入年份。SQL 语句如下。
sql
-- 按年月查询销售量和销售额
select t4.year*100 + t4.month ym,
sum(order_quantity) sum_quantity,
sum(order_amount) sum_amount
from sales_order_fact t1
inner join order_date_dim t4 on t1.order_date_sk = t4.date_sk
where (t4.year*100 + t4.month) between $ym1 and $ym2
group by ym
order by ym;注意 ym1 和 ym2 是动态参数,执行此查询,会出现输入框要求输入参数,如下图所示。
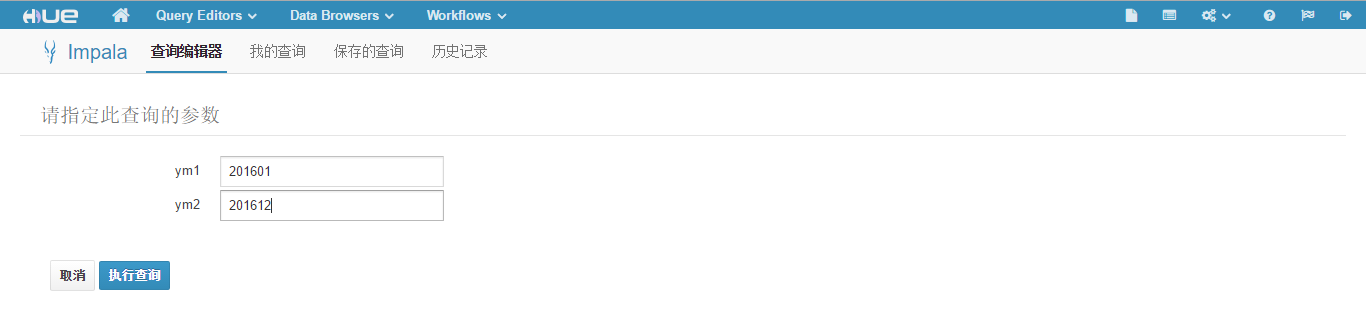
查询 2016 一年的销售情况,ym1 输入 201601,ym2 输入 201612,然后点击"执行查询",结果线形图如下图所示。
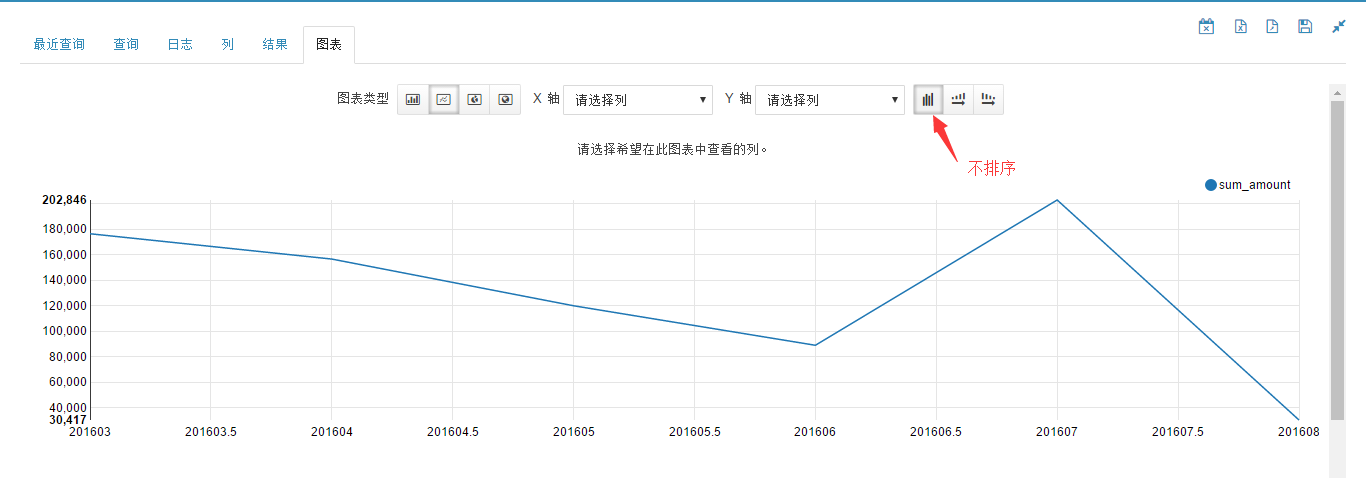
此结果按查询语句中的 order by 子句排序。
至此,我们定义了三个 Impala 查询,进入"我的文档"页面可以看到 default 项目中有三个文档,而"销售订单"项目中没有文档,如下图所示。
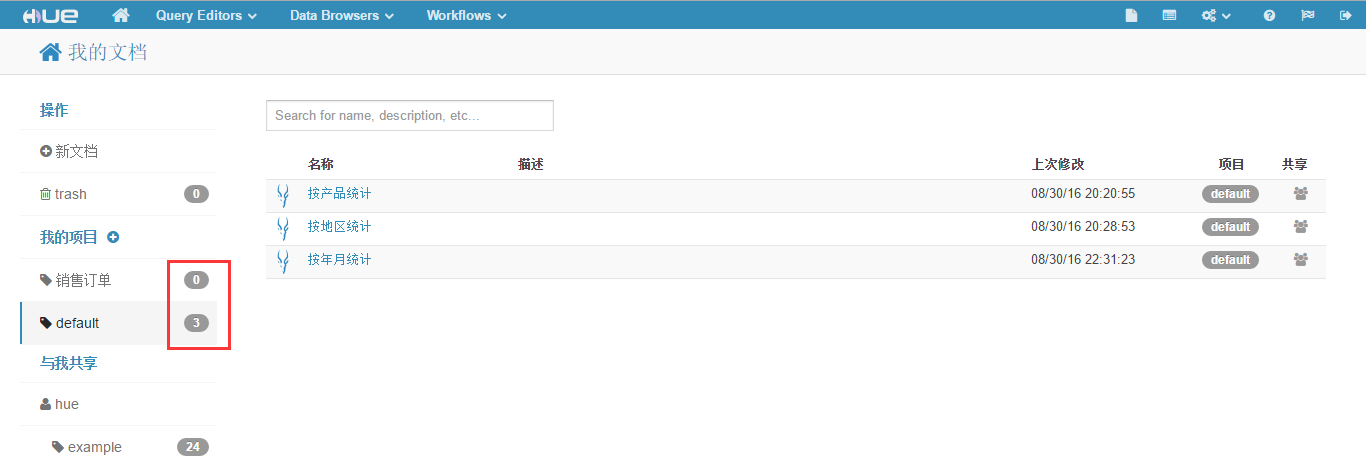
(9)把这三个文档移动到"销售订单"项目中。
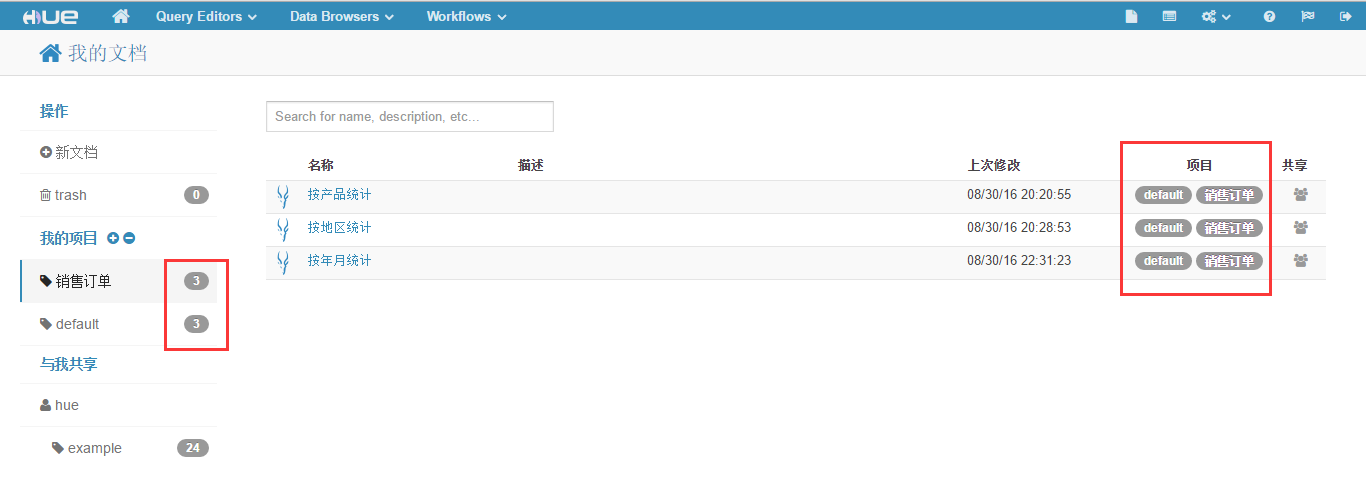
点击右面列表中的"default"按钮,会弹出"移动到某个项目"页面,点击"销售订单",如下图所示。

将三个查询文档都如此操作后,在"销售订单"项目中会出现此三个文档,如下图所示。
以上用销售订单的例子演示了一下 Hue 中的 Impala 查询及其图形化表示。严格地说,无论是 Hue 还是 Zeppelin,在数据可视化上与传统的 BI 产品相比还很初级,它们只是提供了几种常见的图表,还缺少基本的上卷、下钻、切块、切片、百分比等功能,如果只想用 Hadoop 生态圈里的数据可视化工具,也只能期待其逐步完善吧。
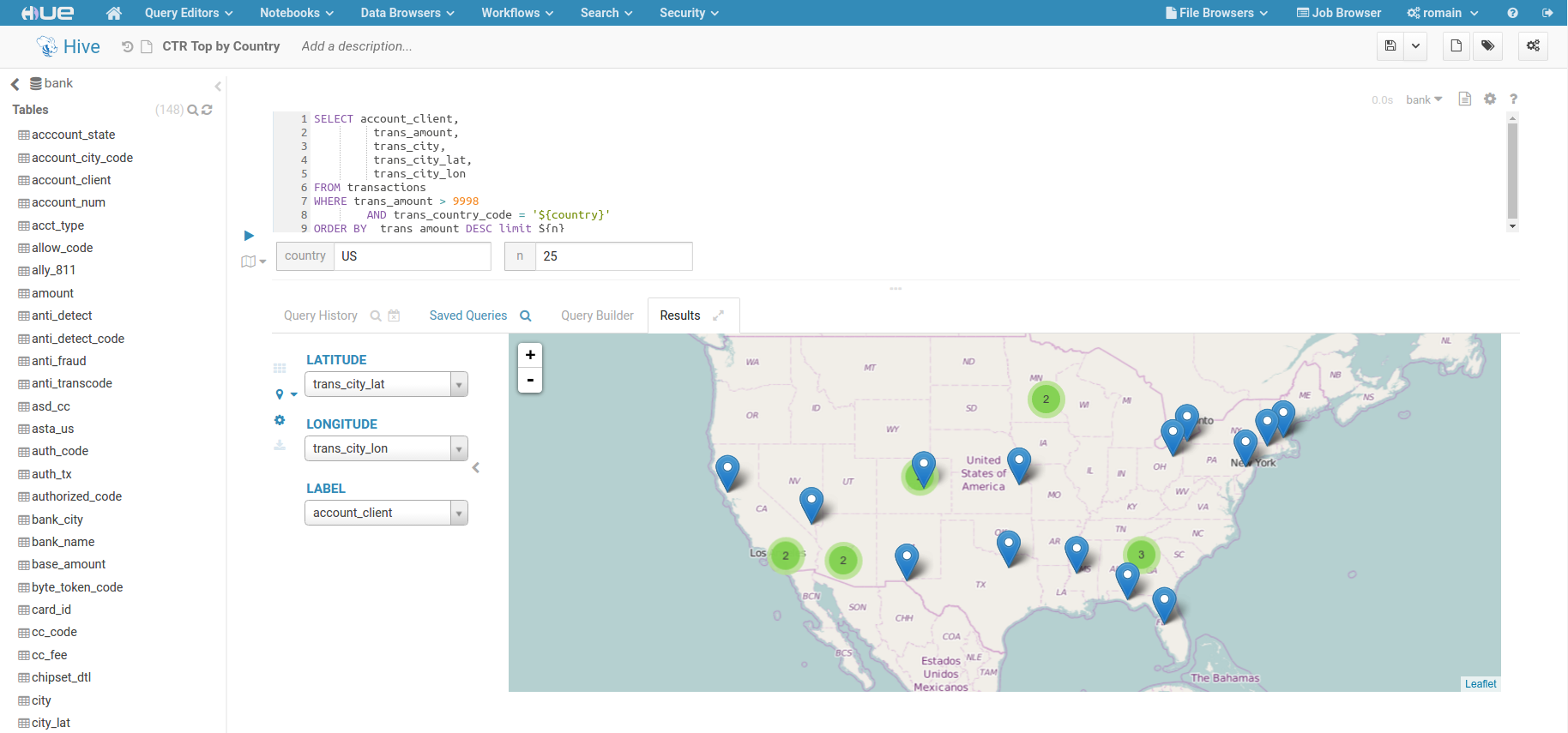
(10)最后提供一个 Hue 文档中通过经纬度进行地图定位的示例,其截图如下所示。
2. DB 查询
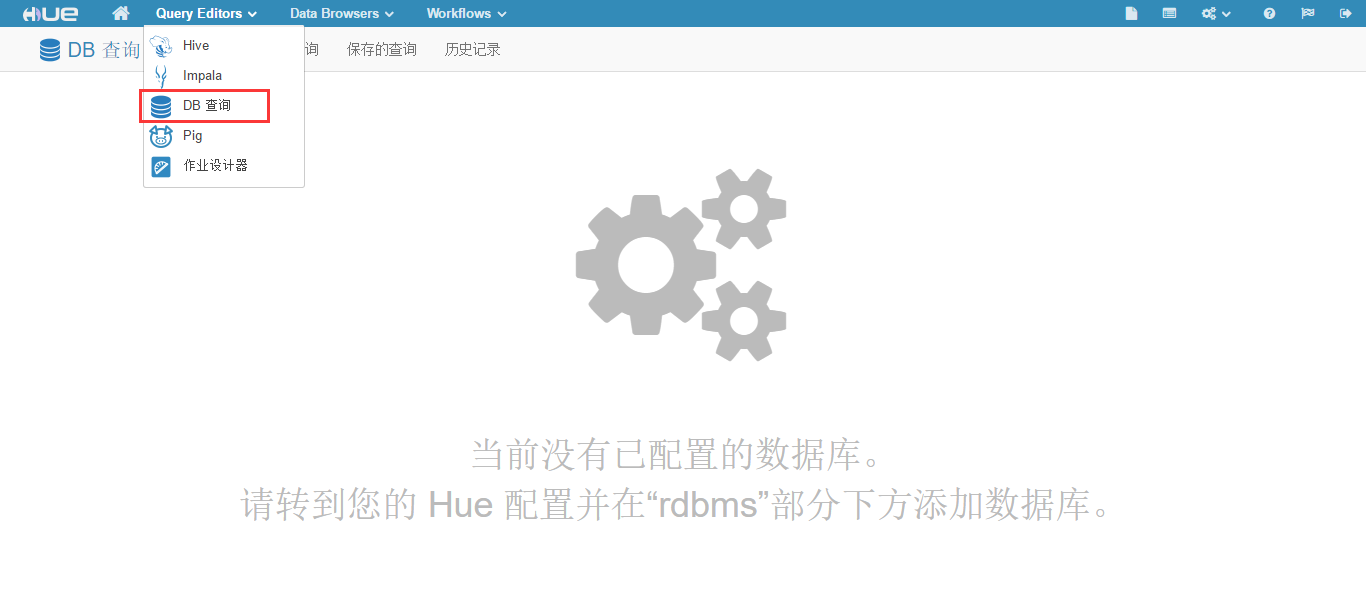
缺省情况下 Hue 没有启用 DB 查询,如果点击"Query Editors" -> "DB 查询",会提示"当前没有已配置的数据库。",如下图所示。
按如下方法配置 DB 查询。
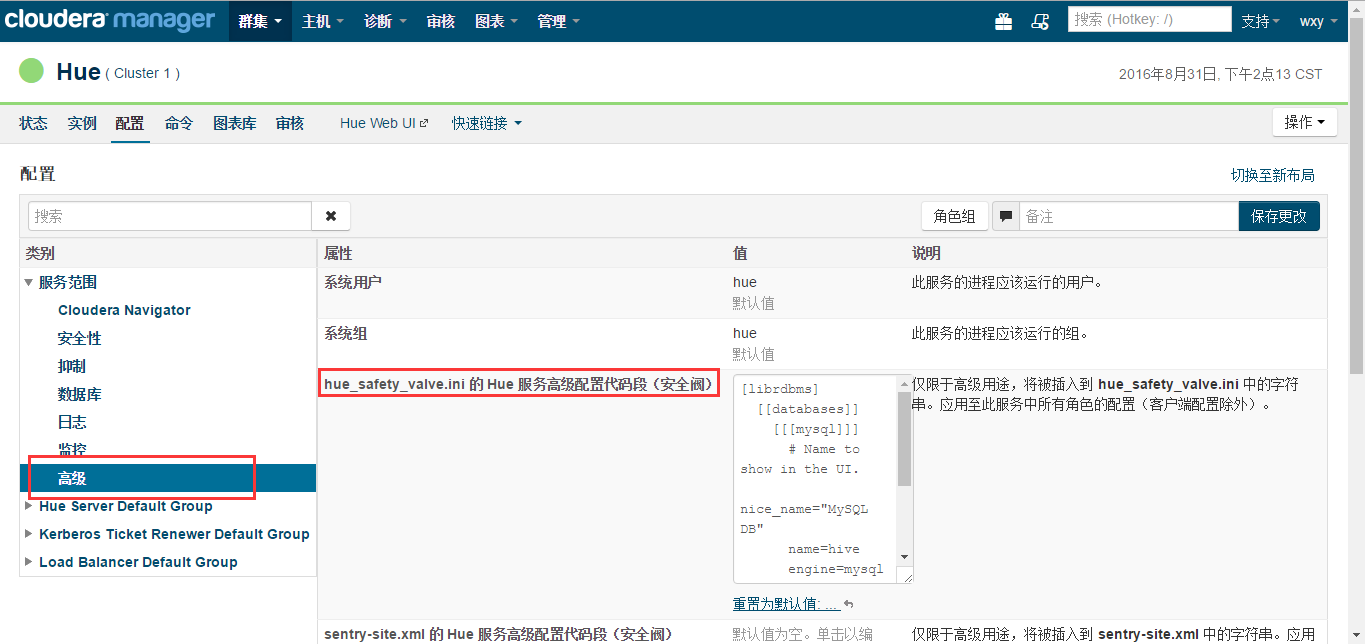
(1)进入CDH Manager的"Hue" -> "配置"页面,在"类别中选择"服务范围" -> "高级",然后编辑"hue_safety_valve.ini 的 Hue 服务高级配置代码段(安全阀)"配置项,填写类似如下内容:
bash
[librdbms]
[[databases]]
[[[mysql]]]
# Name to show in the UI.
nice_name="MySQL DB"
name=hive
engine=mysql
host=172.16.1.102
port=3306
user=root
password=mypassword这里配置的是一个 MySQL 数据库,如下图所示。
(2)点击"保存更改"按钮,然后点击"操作" -> "重启",重启 Hue 服务。
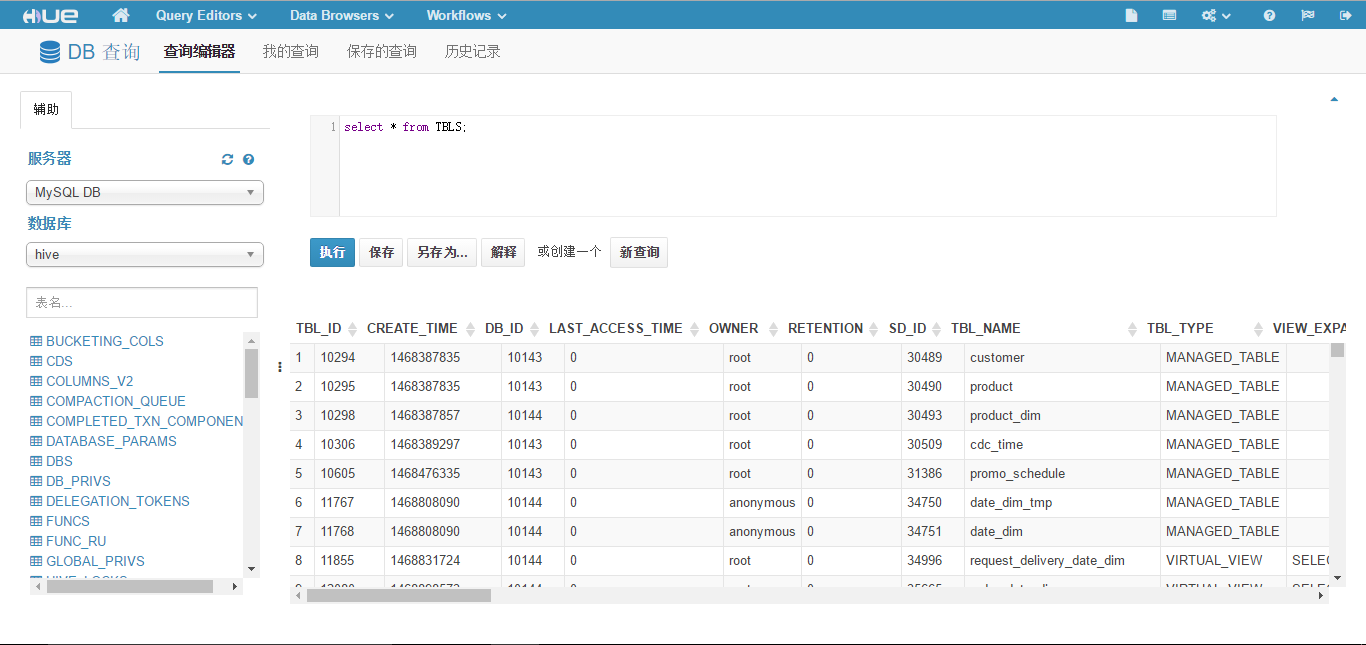
此时再次在 Hue 里点击"Query Editors" -> "DB 查询",则会出现 MySQL 中 hive 库表,此库存放的是 Hive 元数据。此时就可以输入 SQL 进行查询了,如下图所示。
3. 建立工作流
下面说明建立定期执行销售订单示例的 ETL 工作流的详细步骤。
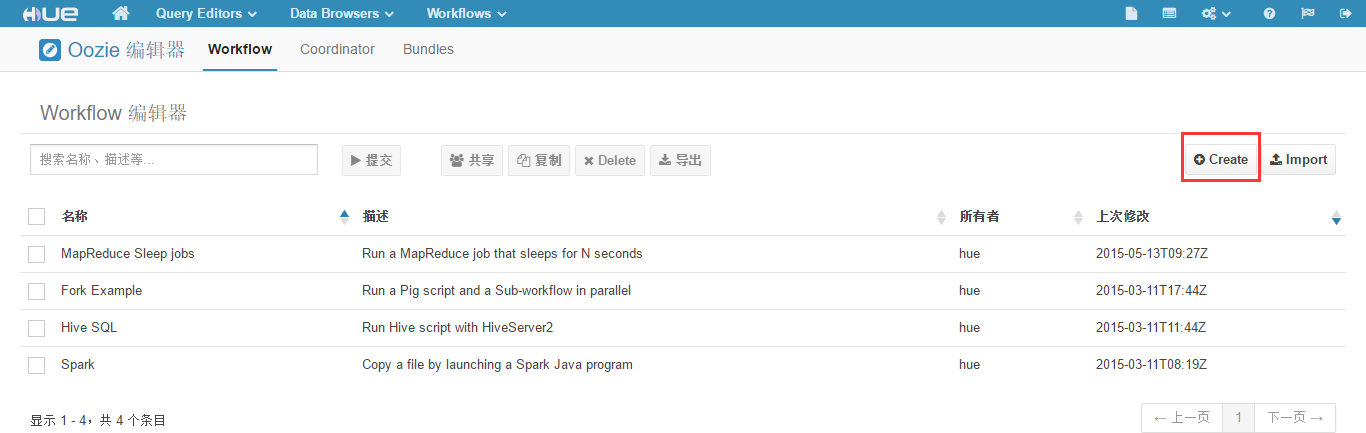
(1)登录 Hue 的 Web 主页,点击"Workflows" -> "编辑器" -> "Workflow",打开"Workflow 编辑器"页面,如下图所示。
(2)点击"Create"按钮,新建一个工作流,页面如下图所示。
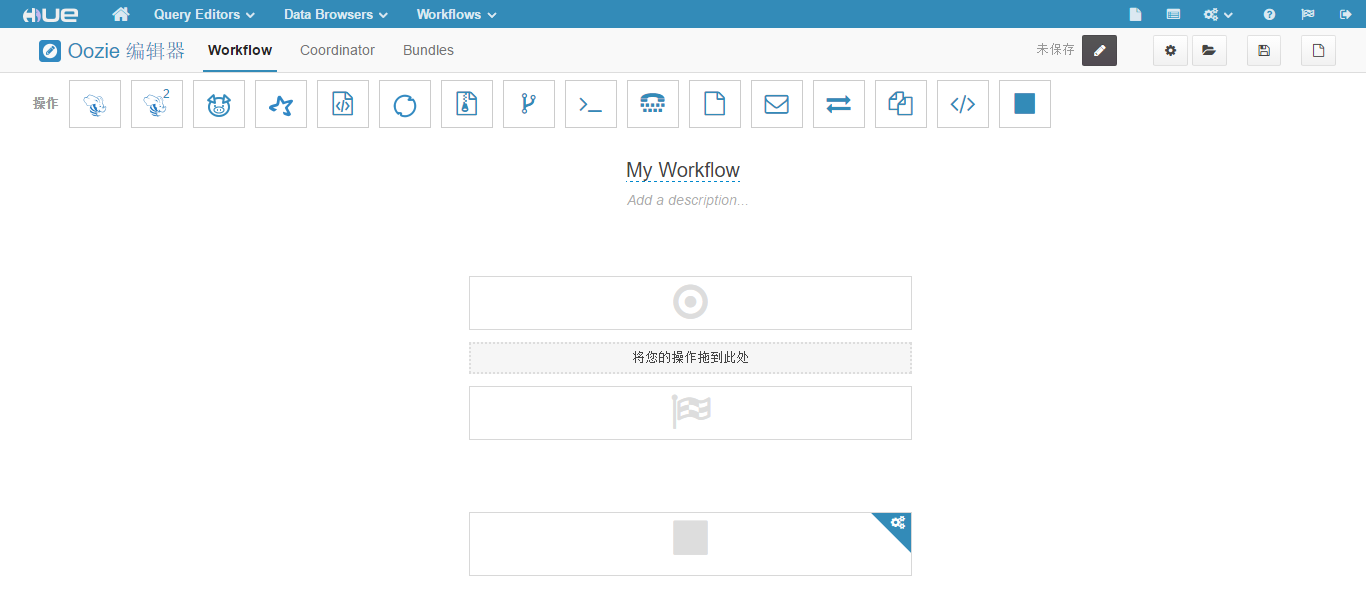
从图中看到,工作流预定义了 16 种操作,而且 Start、End、Kill 节点已经存在,不需要(也不能)自己定义。
(3)点击
(4)点击
(5)执行下面的命令,将相关依赖文件拷贝至工作区目录。
bash
hdfs dfs -put -f /root/mysql-connector-java-5.1.38/mysql-connector-java-5.1.38-bin.jar /user/hue/oozie/workspaces/hue-oozie-1472779112.59
hdfs dfs -put -f /etc/hive/conf.cloudera.hive/hive-site.xml /user/hue/oozie/workspaces/hue-oozie-1472779112.59
hdfs dfs -put -f /root/regular_etl.sql /user/hue/oozie/workspaces/hue-oozie-1472779112.59
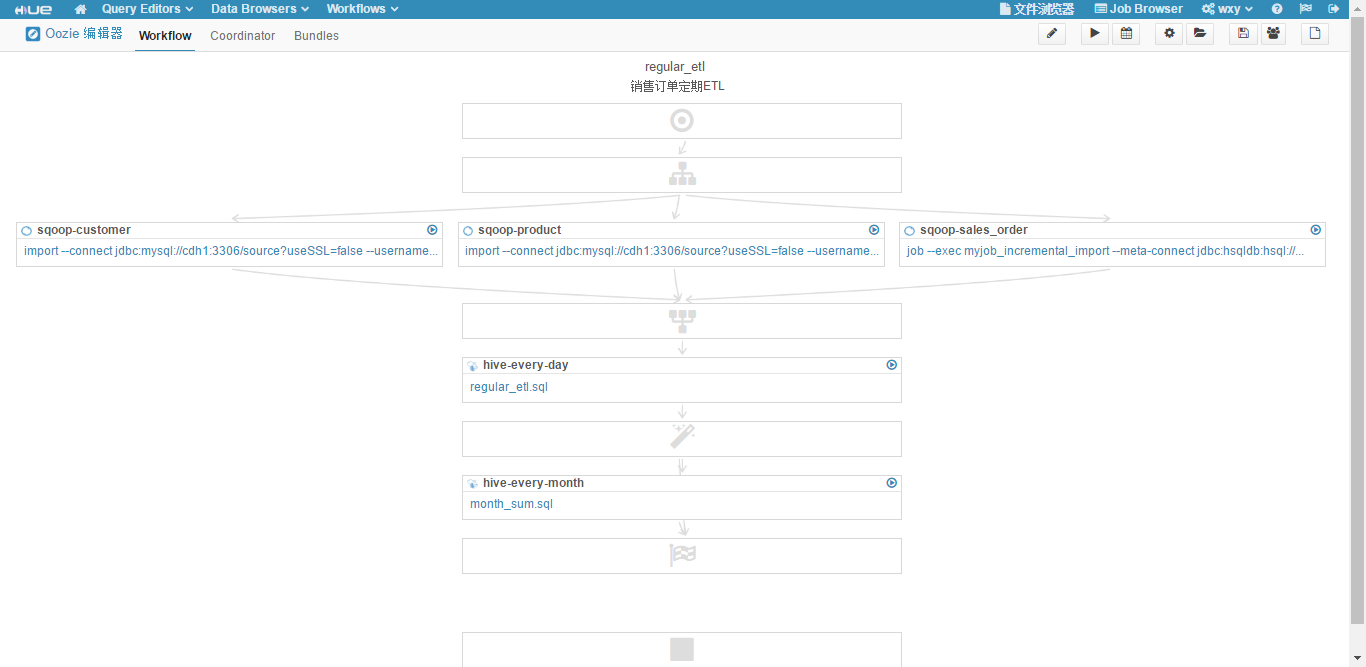
hdfs dfs -put -f /root/month_sum.sql /user/hue/oozie/workspaces/hue-oozie-1472779112.59(6)回到"Workflow 编辑器"页面,拖拽添加三个"Sqoop 1"操作,如下图所示。
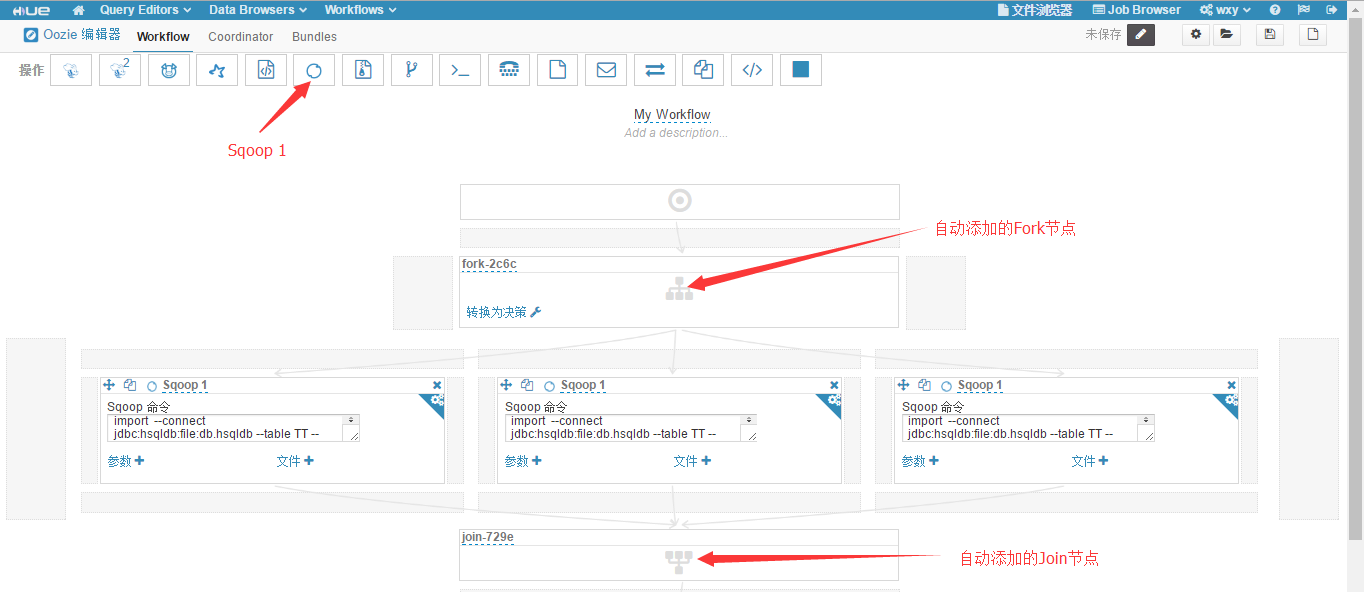
可以看到,因为三个 Sqoop 并行处理,所以工作流中自动添加了 fork 节点和 join 节点。
(7)编辑三个"Sqoop 1"操作。
第一个"Sqoop 1"操作改名为"sqoop-customer"
a. Sqoop 命令填写如下命令,用 import 全量装载客户表。
bash
import --connect jdbc:mysql://cdh1:3306/source?useSSL=false --username root --password mypassword --table customer --hive-import --hive-table rds.customer --hive-overwriteb. 点击"文件",在"选择文件"页面点击"工作区",选择 hive-site.xml 文件。
c. 再次点击"文件",在"选择文件"页面点击"工作区",选择 mysql-connector-java-5.1.38-bin.jar 文件。
第二个"Sqoop 1"操作改名为"sqoop-product"
a. Sqoop 命令填写如下命令,用 import 全量装载产品表。
bash
import --connect jdbc:mysql://cdh1:3306/source?useSSL=false --username root --password mypassword --table product --hive-import --hive-table rds.product --hive-overwriteb. 点击"文件",在"选择文件"页面点击"工作区",选择 hive-site.xml 文件。
c. 再次点击"文件",在"选择文件"页面点击"工作区",选择 mysql-connector-java-5.1.38-bin.jar 文件。
第三个"Sqoop 1"操作改名为"sqoop-sales_order"
a. Sqoop 命令填写如下命令,用 job 增量装载销售订单表。
bash
job --exec myjob_incremental_import --meta-connect jdbc:hsqldb:hsql://cdh2:16000/sqoopb. 点击"文件",在"选择文件"页面点击"工作区",选择 hive-site.xml 文件。
c. 再次点击"文件",在"选择文件"页面点击"工作区",选择 mysql-connector-java-5.1.38-bin.jar 文件。
(8)修改工作流的名称为"regular_etl",添加工作流的描述为"销售订单定期ETL",fork 节点的名称为"fork-node",join节点的名称为"join-node"。现在的工作流如下图所示。
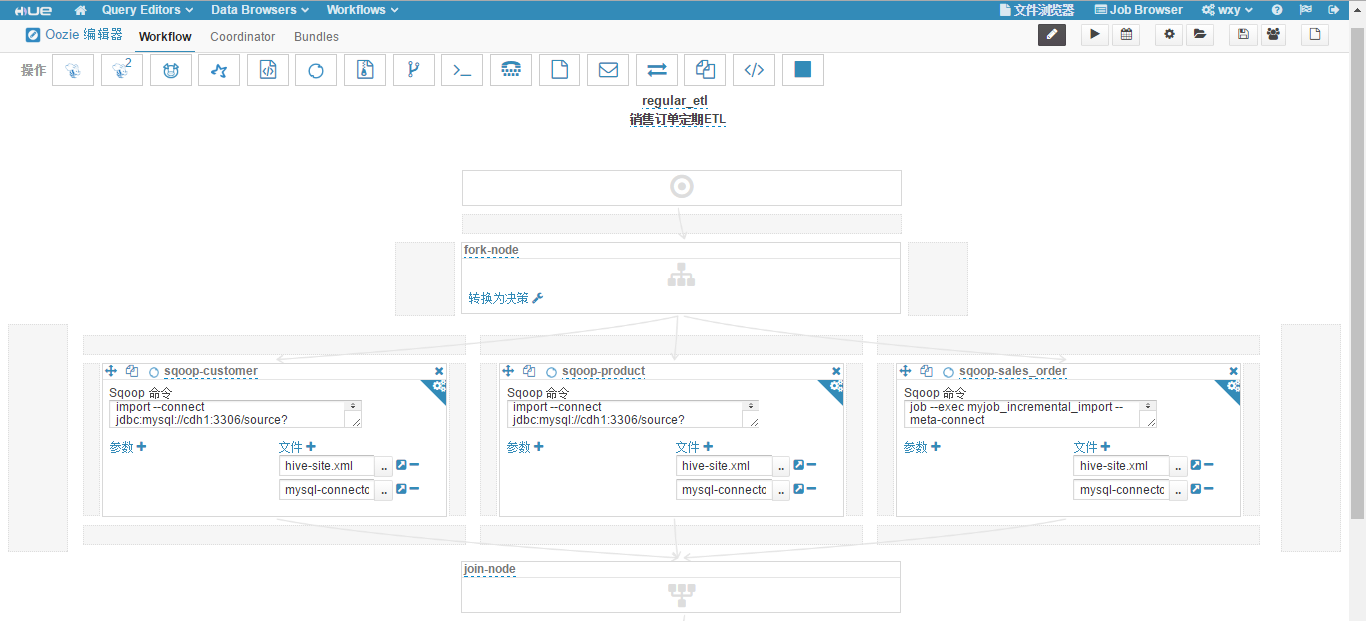
(9)在"join-node"节点下,拖拽添加一个"Hive 脚本"操作,"脚本"选择工作区目录下的 regular_etl.sql 文件,"Hive XML"选择工作区目录下的 hive-site.xml 文件。修改操作名称为"hive-every-day"。此操作每天执行 ETL 主流程。
(10)在"hive-every-day"操作下,拖拽添加一个"Hive 脚本"操作,"脚本"选择工作区目录下的 month_sum.sql 文件,"Hive XML"选择工作区目录下的 hive-site.xml 文件。修改操作名称为"hive-every-month"。此操作每个月执行一次,生成上月汇总数据快照。现在的工作流如下图所示("join-node"及其以下部分)。
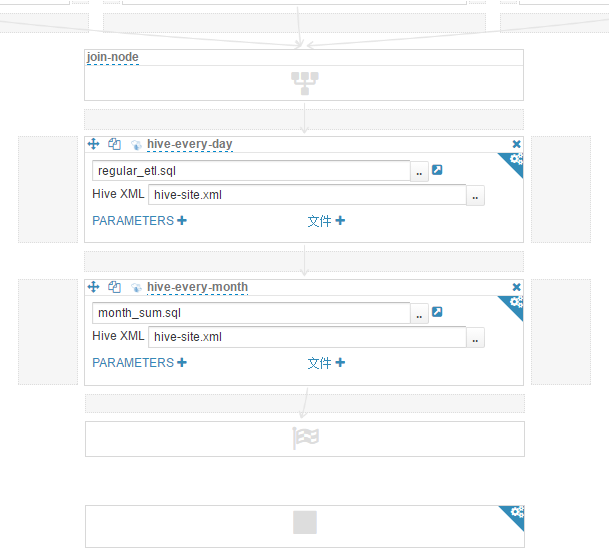
(11)这步要使用一个小技巧。hive-every-month 是每个月执行一次,我们是用天做判断,比如每月 1 日执行此操作,需要一个 decision 节点完成 date eq 1 的判断。在 Hue 的工作流编辑里,decision 节点是由 fork 节点转换来的,而 fork 节点是碰到并发操作时自动添加的。因此需要添加一个和"hive-every-month"操作并发的操作来自动添加 fork 节点。这里选择
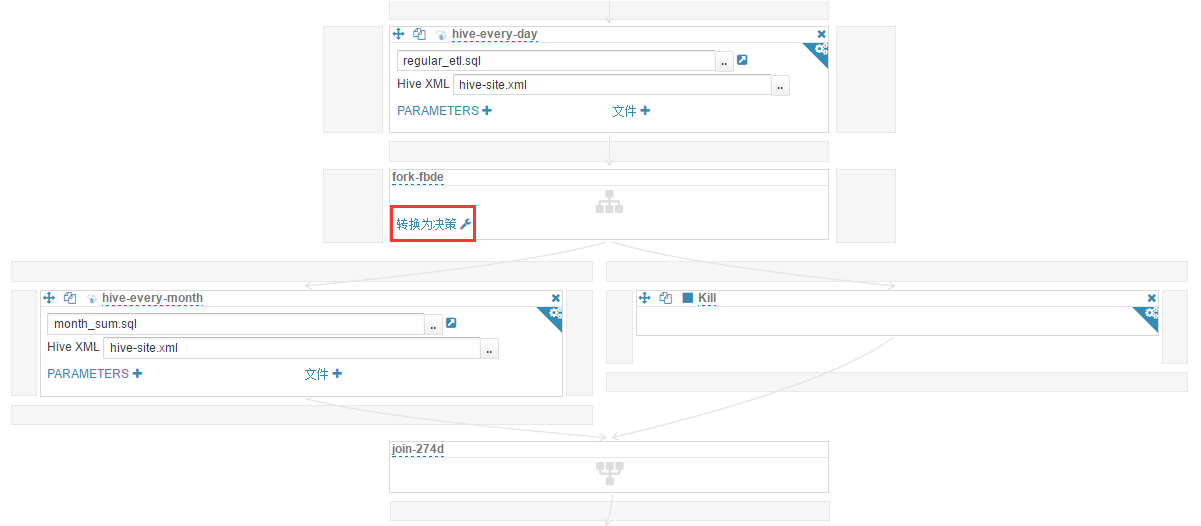
(12)点击"转换为决策",条件是如果 ${date eq 1} 转至"hive-every-month",否则转至"End"。因为不是 1 号时会转至缺省的"End"节点,所以此时已经不再需要刚才添加的"停止"操作,将其删除。现在的工作流如下图所示("hive-every-day"及其以下部分)。
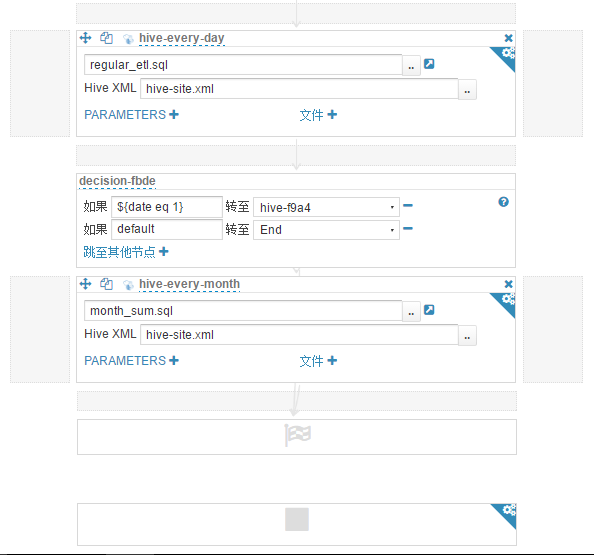
至此我们的 regular_etl 工作流已经定义完成,点击
(13)点击
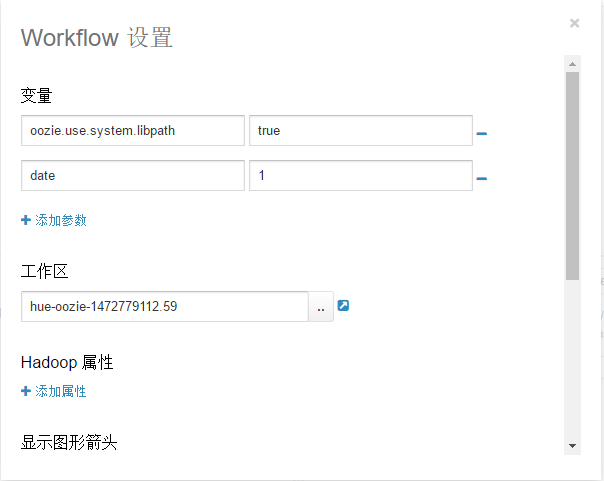
(14)关闭"Workflow 设置"页面,点击
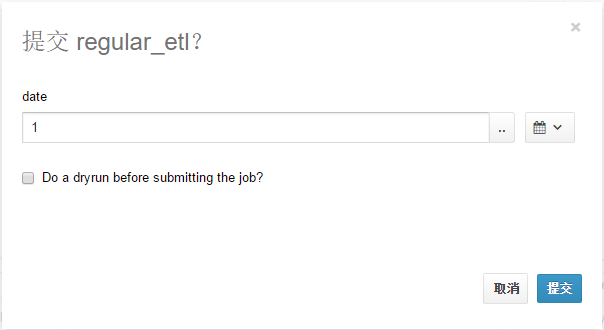
(15)点击"提交"按钮,工作流执行,执行成功结果如下图所示。
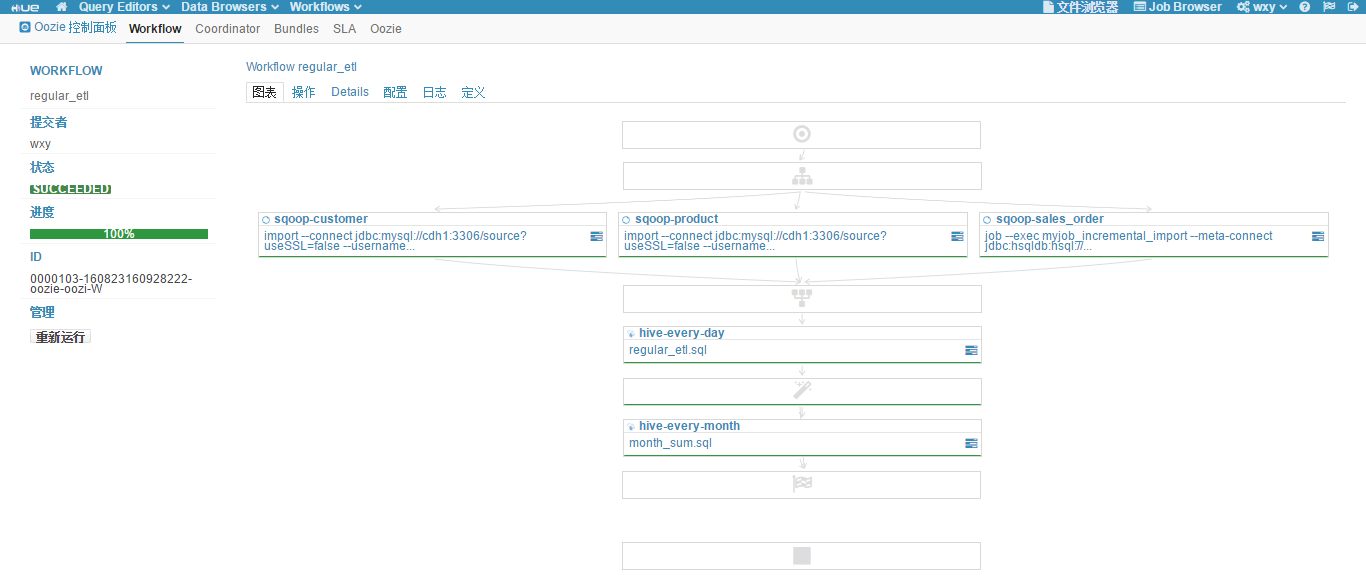
前面的步骤定义了 Workflow 工作流,要让它定时执行还要定义 Coordinator 工作流。
(16)点击"Workflows" -> "编辑器" -> "Workflow",打开"Coordinator 编辑器"页面,如下图所示。
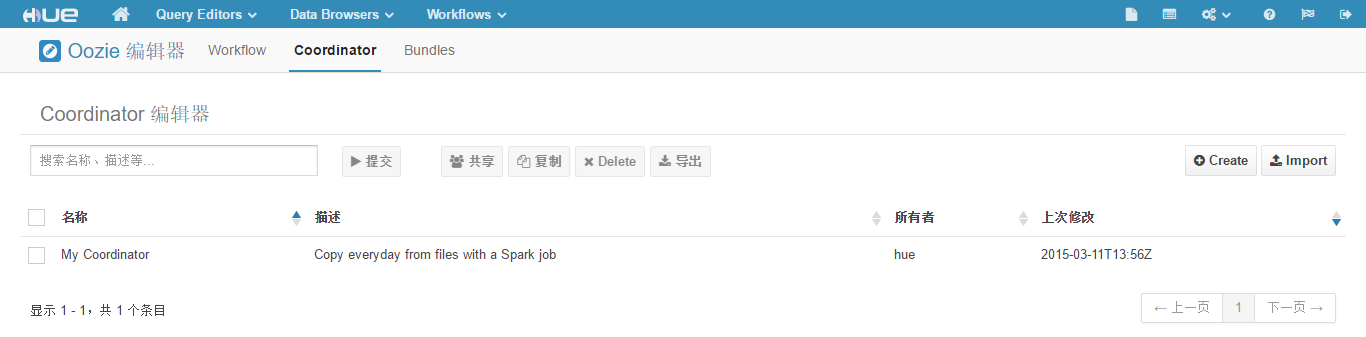
(17)点击"Create"按钮,新建一个工作流,页面如下图所示。
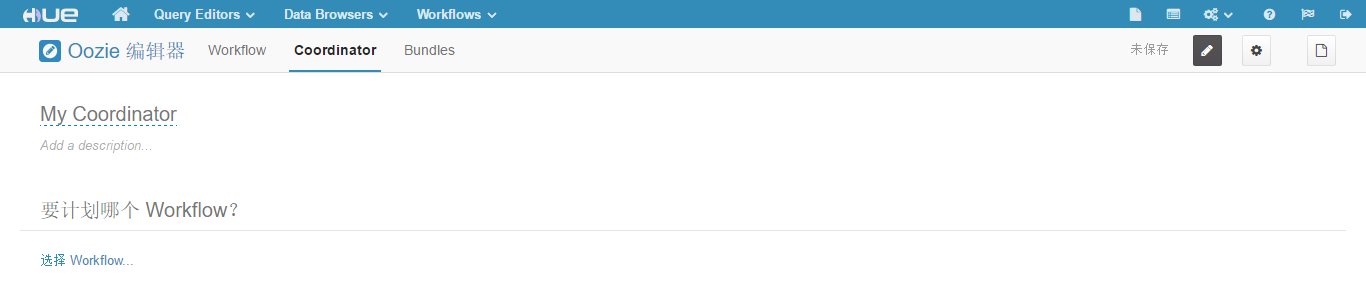
(18)点击"选择 Workflow"链接,在弹出的页面中选择"regular_etl",如下图所示。
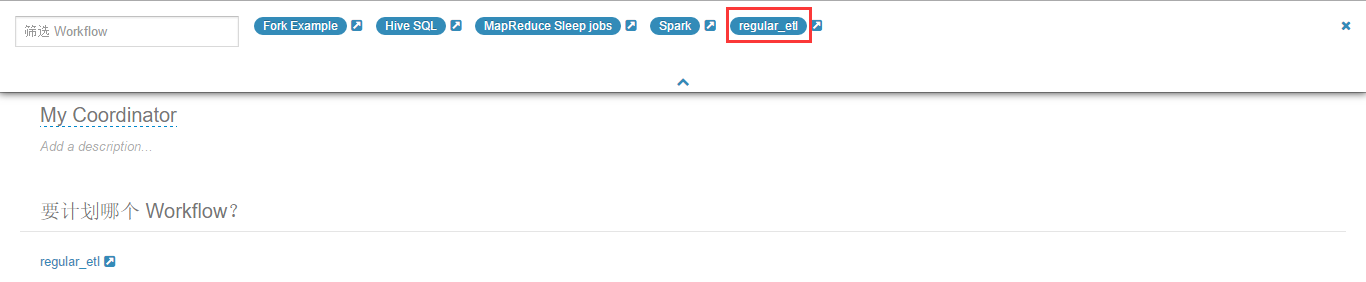
(19)"频率"配置不变,保持缺省的每天一次。
(20)点击"添加参数"链接,将 ${coord:formatTime(coord:actualTime(), 'd')} 作为 regular_etl 里变量 date 的值,传递给 Workflow。
(21)修改 Coordinator 工作流的名称为"regular_etl-coord",点击
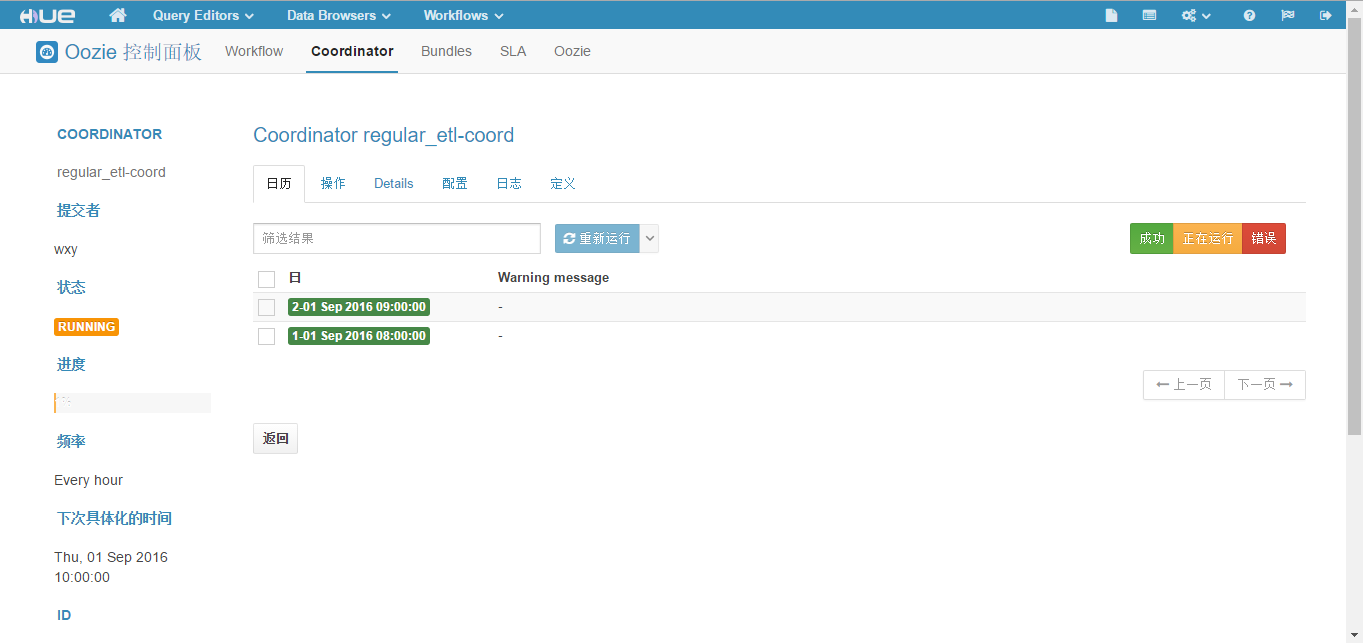
至此我们的 Coordinator 工作流已经定义完成,现在的工作流在非编辑模式下如下图所示。
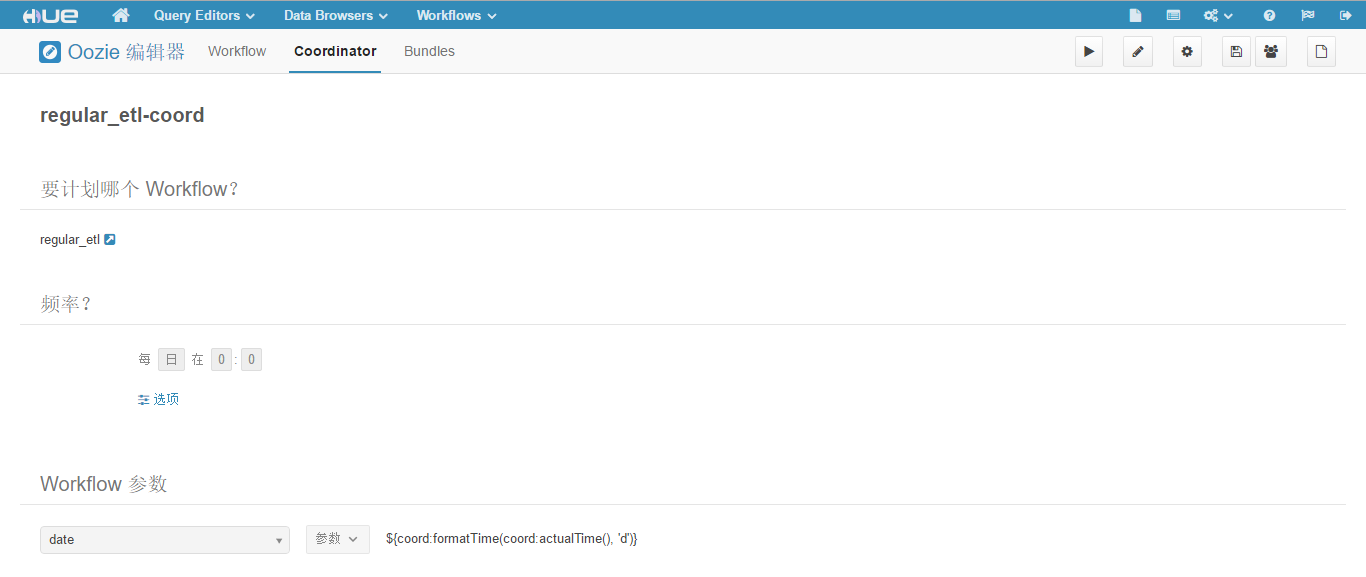
(22)点击 "提交",等待 Coordinator 工作流执行,执行成功结果如下图所示。