一、实验信息
1. 实验环境
- CentOS7
- Java21
| 虚拟机名称 | feilink1 | feilink2 | feilink3 |
|---|---|---|---|
| 虚拟机IP | 192.168.10.101 | 192.168.10.102 | 192.168.10.103 |
2. Hadoop服务配置
| 节点 | 服务 |
|---|---|
| feilink1 | NameNode、DataNode、SecondaryNameNode、ResourceManager、NodeManager、ProxyServe、JobHistoryServer |
| feilink2 | DataNode、NodeManager |
| feilink3 | DateNode、NodeManager |
3. 文中没特意说的就是在feilink1节点上执行
二、创建Hadoop用户并配置免密登录
1. 创建用户
三台一起执行
bash
useradd hadoop2. 修改密码
三台一起执行
如果密码太简单了就输入两次,死犟死犟的一天
bash
passwd hadoop3. 切换用户
三台一起执行
bash
su hadoop4. 配置ssh免密登录
三台一起执行
bash
# 连着三个回车
ssh-keygen
ssh-copy-id feilink1
ssh-copy-id feilink2
ssh-copy-id feilink3三、下载压缩包
1. 官网地址
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.4.2/hadoop-3.4.2.tar.gz
我这里用的是之前的老版本3.3.4,hadoop-3.3.4.tar.gz
2. 再次确认
请确认已经完成前置准备中的服务器创建、固定IP、防火墙关闭、Hadoop用户创建、SSH免密、JDK部署等操作
3. 上传压缩包到feilink1节点中
先切换回root用户
三台一起执行
bash
su root上传压缩包到feilink1节点中的/export/server路径中
四、安装Hadoop
1. 解压文件
bash
tar -zxvf hadoop-3.3.4.tar.gz2. 删除压缩包
bash
rm -rf hadoop-3.3.4.tar.gz3. 目录重命名
bash
mv hadoop-3.3.4/ hadoop五、修改配置文件
1. workers
bash
vim /export/server/hadoop/etc/hadoop/workers
bash
# 修改为以下内容,粘贴完别忘了把这行删掉
feilink1
feilink2
feilink32. hadoop-env.sh
bash
vim /export/server/hadoop/etc/hadoop/hadoop-env.sh
bash
# 新增以下内容
# Hadoop
# jdk路径
export JAVA_HOME=/export/server/jdk
# hadoop路径
export HADOOP_HOME=/export/server/hadoop
# hadoop配置文件路径
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# hadoop日志路径
export HADOOP_LOG_DIR=$HADOOP_HOME/logs3. core-site.xml
bash
vim /export/server/hadoop/etc/hadoop/core-site.xml
xml
<configuration>
<property>
<!-- HDFS的NameNode通讯地址 -->
<name>fs.defaultFS</name>
<value>hdfs://feilink1:8020</value>
</property>
<property>
<!-- IO操作文件缓冲区大小 -->
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>4. hdfs-site.xml
bash
vim /export/server/hadoop/etc/hadoop/hdfs-site.xml
xml
<configuration>
<property>
<!-- HDFS文件系统默认创建的文件权限设置 -->
<!-- 700 就是rwx...... -->
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<!-- NameNode元数据的存储位置 -->
<!-- 在NameNode节点的/data/nn目录下 -->
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<!-- NameNode允许哪几个节点的DataNode连接 -->
<name>dfs.namenode.hosts</name>
<value>feilink1,feilink2,feilink3</value>
</property>
<property>
<!-- HDFS默认块大小 -->
<!-- 256MB -->
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<!-- NameNode处理的并发线程数 -->
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<!-- DataNode的数据存储目录 -->
<!-- 数据存放在DataNode的/data/dn目录下 -->
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>5. mapred-env.sh
bash
vim /export/server/hadoop/etc/hadoop/mapred-env.sh
bash
# JDK路径
export JAVA_HOME=/export/server/jdk
# 设置JobHistoryServer进程内存为1G
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
# 设置日志级别为INFO
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
# java9以上的bug
export HADOOP_OPTS="$HADOOP_OPTS --add-opens java.base/java.lang=ALL-UNNAMED"6. mapred-site.xml
xml
vim /export/server/hadoop/etc/hadoop/mapred-site.xml
xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>MapReduce的运行框架设置为YARN</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>feilink1:10020</value>
<description>历史服务器通讯端口为feilink1:10020</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>feilink1:19888</value>
<description>历史服务器web端口为feilink1:19888</description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mr-history/tmp</value>
<description>历史信息在HDFS的记录临时路径</description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
<description>历史信息在HDFS的记录路径</description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MapReduce HOME 设置为HADOOP_HOME</description>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MapReduce HOME设置为HADOOP_HOME</description>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MapReduce HOME设置为HADOOP_HOME</description>
</property>
</configuration>7. yarn-env.sh
bash
vim /export/server/hadoop/etc/hadoop/yarn-env.sh
bash
# 增加内容
# 设置JDK 环境变量
JAVA_HOME=/export/server/jdk
# HADOOP_HOME环境变量
export HADOOP_HOME=/export/server/hadoop
# 配置文件路径的环境变量
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# 设置日志文件路径的环境变量
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
# java9以上的bug
export HADOOP_OPTS="$HADOOP_OPTS --add-opens java.base/java.lang=ALL-UNNAMED"8. yarn-site.xml
bash
vim /export/server/hadoop/etc/hadoop/yarn-site.xml
xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>feilink1</value>
<description>ResourceManager设置在node1节点</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
<description>NodeManager中间数据本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
<description>NodeManager数据日志本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>为MapReduce程序开启Shuffle服务</description>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://feilink1:19888/jobhistory/logs</value>
<description>历史服务器URL</description>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>feilink1:8089</value>
<description>代理服务器主机和端口</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>开启日志聚合</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>程序日志HDFS的存储路径</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>选择公平调度器</description>
</property>
</configuration>六、分发文件
bash
cd /export/server
scp -r hadoop feilink2:`pwd`/
scp -r hadoop feilink3:`pwd`/七、集群配置
1. 创建存储目录
三台一起执行
bash
su root
bash
mkdir -p /data/nn
mkdir -p /data/dn2. 修改环境变量
三台一起执行
bash
vim /etc/profile
bash
# 新增以下内容
# Hadoop
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
bash
source /etc/profile3. hadoop用户授权
三台一起执行
bash
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
chown -R hadoop:hadoop /tmp4. 格式化HDFS
在feilink1上执行
要以hadoop用户执行
bash
# 切换用户
su hadoop
# 格式化namenode
hadoop namenode -format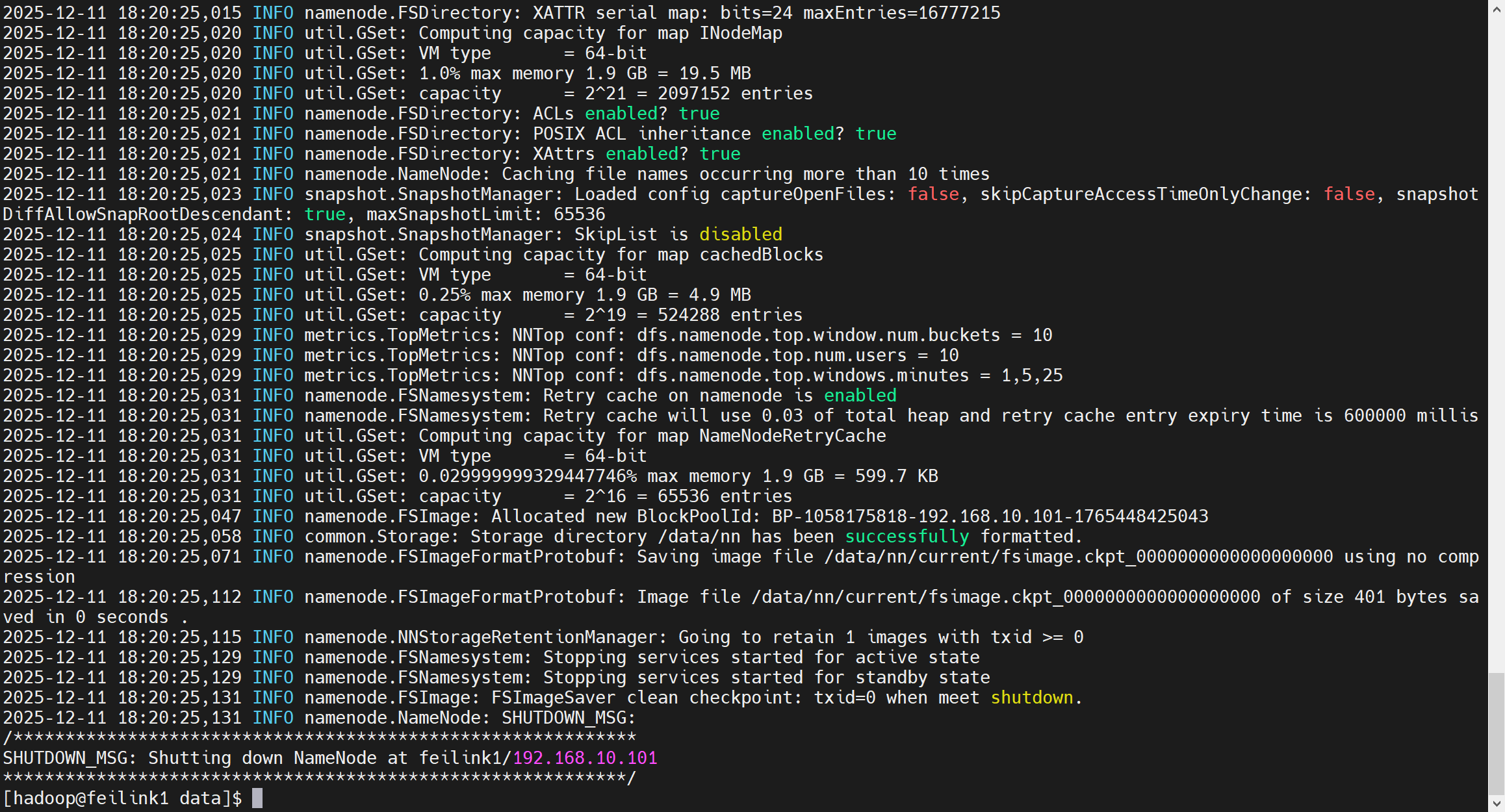
八、启动Hadoop
1. HDFS
一键启动HDFS集群
bash
start-dfs.sh一键关闭HDFS集群
bash
stop-dfs.sh单独控制服务启停
bash
hdfs --daemon (start|status|stop) (namenode|secondarynamenode|datanode)2. YARN
一键启动YARN集群
bash
start-yarn.sh一键关闭YARN集群
bash
stop-yarn.sh当前机器单独启停进程
bash
$HADOOP_HOME/bin/yarn --daemon start|stop resourcemanager|nodemanager|proxyserver3. MapReduce
历史服务器启动和停止
bash
$HADOOP_HOME/bin/mapred --daemon start|stop historyserver4. 一键启停除history以外所有服务
bash
start-all.sh
bash
stop-all.sh九、安装成功
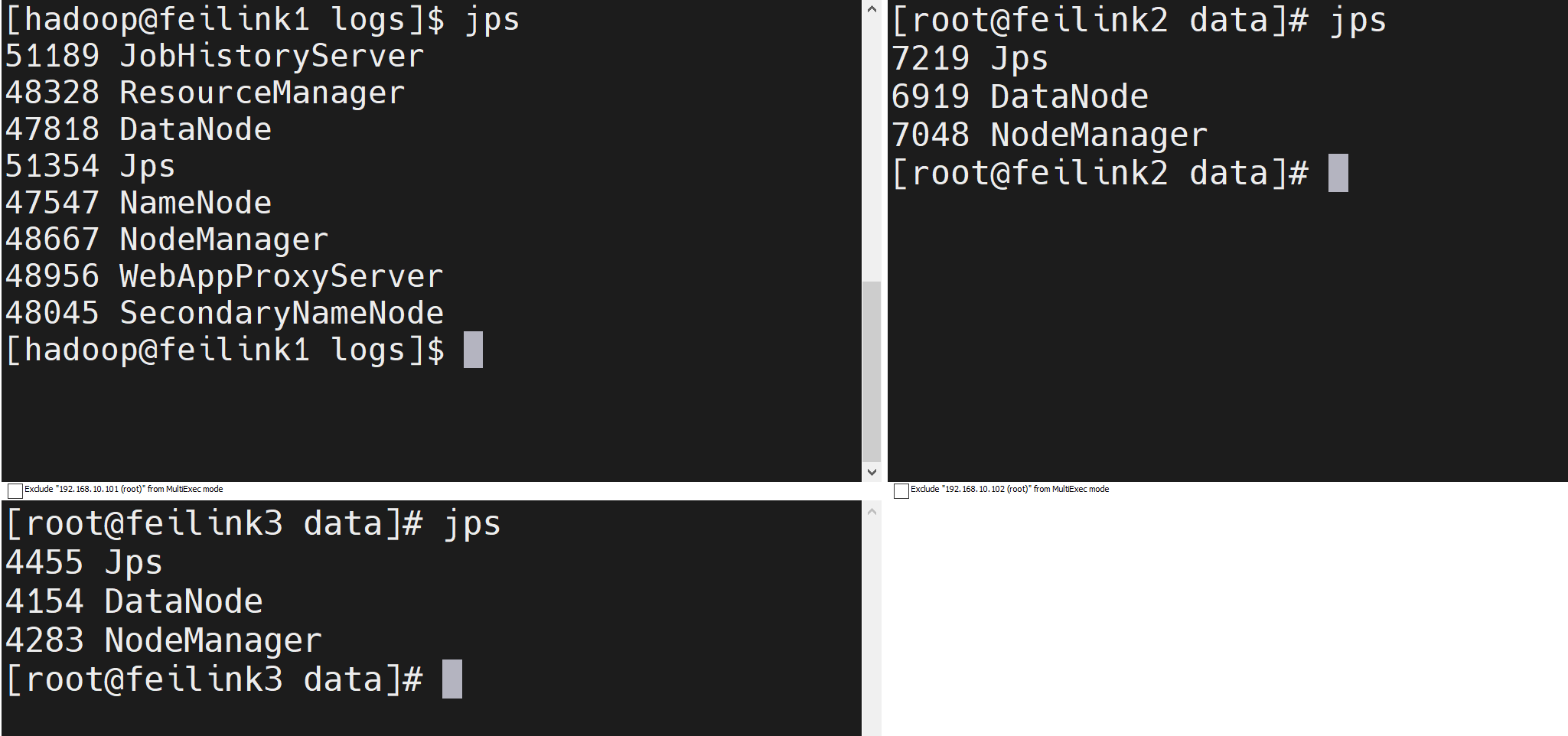
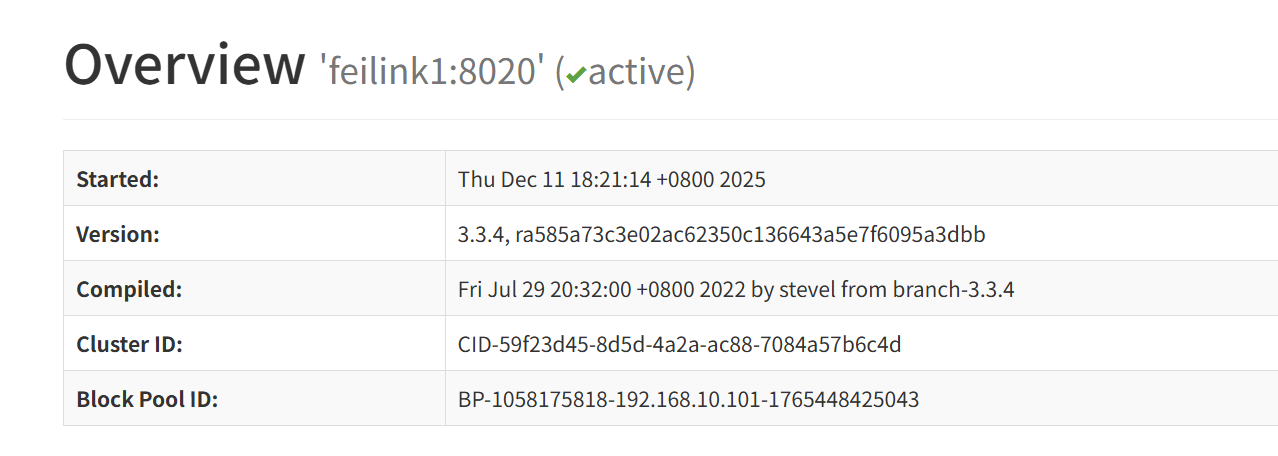
十、Web页面
1. HDFS
2. YARN