一、实验环境
1. 节点IP
| 主机名 | IP |
|---|---|
| feilink1 | 192.168.10.101 |
| feilink2 | 192.168.10.102 |
| feilink3 | 192.168.10.103 |
2. 依赖组件
- Hadoop
- MySQL
3. 没有特殊说明的都是在feilink1节点上的操作
4. MySQL配置
-
用户:root
-
密码:123456
5. 各组件版本
组件 版本 CentOS 7 Hadoop 3.3.4 MySQL 8.0.29 6. 用户密码
- root(123456)
- hadoop(hadoop)
二、配置Hadoop
bash
vim /export/server/hadoop/etc/hadoop/core-site.xml添加以下内容
xml
<property>
<!-- Hive用到的代理 -->
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>分发文件
bash
scp /export/server/hadoop/etc/hadoop/core-site.xml feilink2:/export/server/hadoop/etc/hadoop/core-site.xml
scp /export/server/hadoop/etc/hadoop/core-site.xml feilink3:/export/server/hadoop/etc/hadoop/core-site.xml三、下载Hive压缩包
下载地址:http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
四、安装Hive
1. 上传压缩包
上传到/export/server目录下
bash
tar -zxvf apache-hive-3.1.3-bin.tar.gz删除压缩包
bash
rm -rf apache-hive-3.1.3-bin.tar.gz修改目录名
bash
mv apache-hive-3.1.3-bin/ hive2. 下载MySQL驱动包
下载地址:https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.29/mysql-connector-java-8.0.29.jar
将下载好的jar包放到hive文件夹的/lib目录下
3. 配置Hive
bash
vim /export/server/hive/conf/hive-env.sh
bash
export HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
bash
vim /export/server/hive/conf/hive-site.xml
xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://feilink1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>feilink1</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://feilink1:9083</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>五、初始化元数据库
在mysql中执行
bash
CREATE DATABASE hive CHARSET UTF8;
GRANT ALL PRIVILEGES ON hive.* TO 'root'@'%';
FLUSH PRIVILEGES;执行元数据库初始化命令
bash
cd /export/server/hive/
bin/schematool -initSchema -dbType mysql -verbos初始化成功
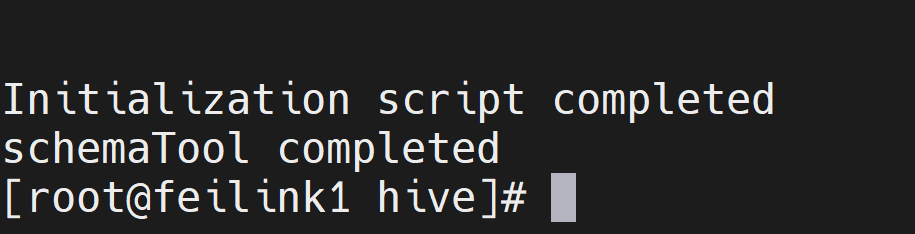
初始化成功后,会在MySQL的hive库中新建74张元数据管理的表
sql
use hive;
show tables;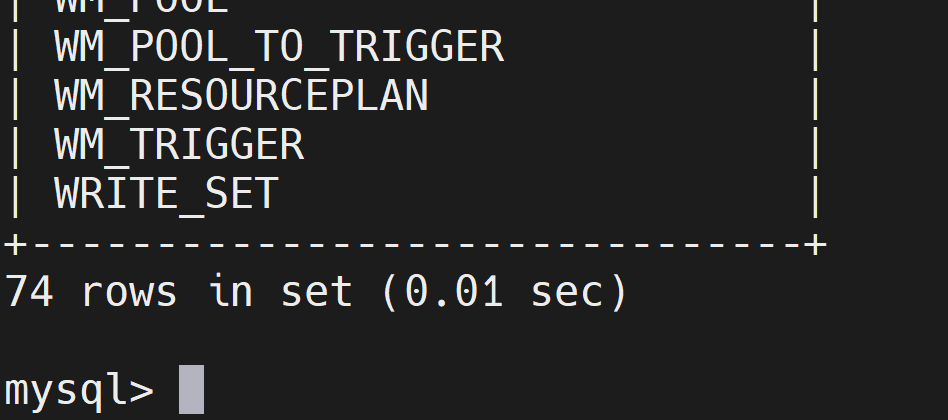
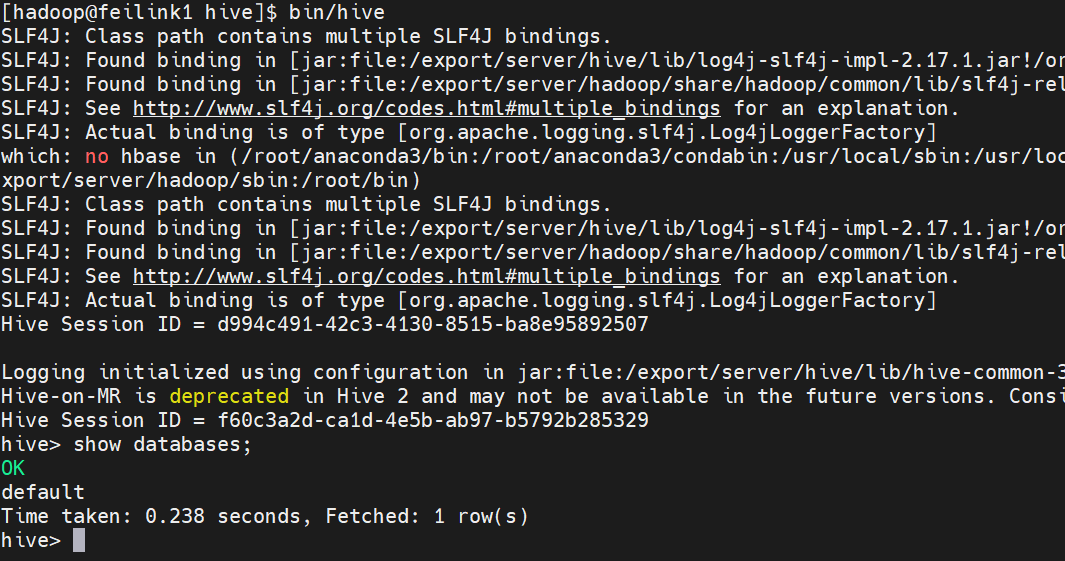
六、启动Hive
1. 权限配置
创建日志文件夹
bash
mkdir /export/server/hive/logs修改权限
bash
chown -R hadoop:hadoop /export/server/hive切换用户
bash
su hadoop2. 启动Hadoop
bash
start-all.sh3. 启动元数据服务(二选一)
前台启动
bash
bin/hive --service metastore后台启动
bash
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &4. 启动客户端(二选一)
Hive Shell方式(可以直接写SQL)
bash
bin/hiveHive ThriftServer方式(不能直接写SQL,需要配合外部客户端使用)
bash
bin/hive --service hiveserver2
# 后台启动
nohup bin/hiveserver2 > /export/logs/hiveserver2.log 2>&1 &5. 启动成功