CLIP Contrastive language image pre-training ICML OpenAI 2021
论文:https://arxiv.org/pdf/2103.00020
代码:https://github.com/openai/CLIP
动机:在NLP领域,利用大规模数据预训练模型,用与下游任务无关的训练方式取得革命性的成功。将NLP的成功复制到其它领域中,如视觉领域。限定类别计算机视觉任务,简化了任务,同时也限制了模型的泛化能力,识别新类别。
LLM:随着transformer和自监督兴起,NLP encoder,利用1.大规模数据预训练模型2.采用具有上下文语义环境的学习方式(deep contextual representation learning),如bert的完型填空,可以利用无穷尽的文本监督信号,其与下游任务无关。如,Bert,GPT,T5。
一句话:预训练阶段,通过对比学习,利用文本提示监督,训练预训练大模型,去做zero shot的迁移学习,大规模数据和大模型的双重加持下,效果与baseline持平。
最大贡献 :打破了固定种类标签的范式,让下游任务的推理变得灵活,高效可扩展,在zero-shot的情况下,效果不错。
关键词 :视觉+NLP+多模态+无监督学习
优点:处理数据更方面,训练模型更方便,推理时更方便,甚至可以zero-shot
1.CLIP结构
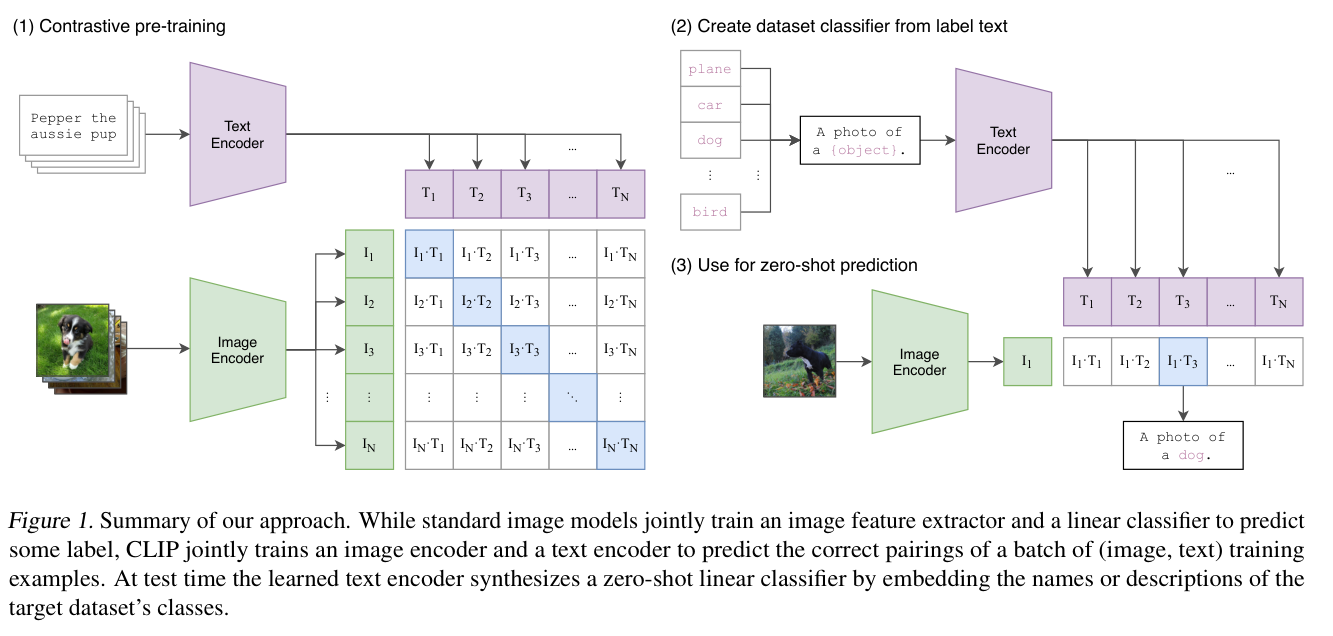
CLIP模型的输入是一个图像和文字的配对(文本描述图像),通过文本编码器text encoder和图像编码器image encoder抽取各自文本和图像特征,二者做对比学习,判断文本描述和图像特征的相似度。
CLIP通过大量训练数据,利用自然语言的监督信号训练比较好的视觉模型,无监督学习。视觉语义和文字语义联系到一起,学习到的特征语义性很强,多模态特征,迁移效果也非常好。收集数据集或训练模型时不需要提前定义类别,搜集图文配对,无监督学习,预测相似性。
正样本和负样本相似度计算(对比学习),对角线位置配对正样本n个,其它位置负样本配对nxn-n个。
2.zero-shot推理
(1) zero shot transfer 零样本迁移,CLIP的核心所在
以往通过自监督或无监督方法,主要研究的是特征学习的能力,目标是学一种泛化性比较好的特征,但是下游任务仍然需要有label的数据去微调。
CLIP训练和下游任务无关,在进行下游任务时,不必进行任务输出头设计或数据集的特殊处理。
(2)怎么做zero-shot transfer?给入图像,看有没有感兴趣的类别
liner probe :抽取特征层冻结,加入分类头fc,CLIP直接就可以兼容下游任务。
输入图像与提前设置好的prompt的文本,进行cosine similarity,筛选相似度最高prompt即可得到label。
ImageNet没有三轮车label,设置为车,但是prompt中输入三轮车label,ImageNet可能可以判断出是三轮车
文本计算特征的时候,不是顺序进行的,是批次进行的,所以CLIP推理高效
3.prompt engineering and ensemble
prompt:提示,文本的引导作用,设计prompt template
3.1prompt engineering
(1)多义性(ploysemy),同个单词在不同语境中意思不同,所以设置prompt句子描述语境
(2)训练句子,推理单词,会出现distribution gap,准确率下降
基于上述原因,采用提示模板prompt template,如 a photo of a { label }
好的prompt template可以缩小解空间,提高准确率,如, a photo of a { label },a type of pet;OCR, a photo of a "dog",会识别文字,不是dog
3.2prompt ensemble
多个提示模板,综合多次推理结果,得到更好的结果。paper中使用了80个提示模板。
在微调或推理阶段使用prompt,不在预训练阶段,提升了ImageNet 1.3%
4.实验
4.1数据集
训练集:WIT数据集:自创,4亿个文本图像样本对,数据质量高。数据集和GPT2的WebText数据量差不多。
测试集:30+数据集不同视觉任务做zero-shot推理。 ImageNet 128w数据量
数据增强:rand crop
4.2预训练方法
OpenCV AI gpt-gpt3,image gpt,dall-e 都是基于GPT做的,维有CLIP因训练效率原因采用对比学习
采用对比学习,如果给定一张图像,预测文本描述输出caption,逐字预测比较困难,而判断caption和图像是不是一个配对,任务比较简单。
预测型目标函数loss换为对比型目标函数loss,训练效率提高4倍,各个单模态特征通过线性层映射到多模态空间(以往非线性效果好,在这里实验发现效果基本一致,任务以往非线性可能只是为了适配图像单模态学习)
4.3训练策略
image训练:
5个ResNet系列:ResNet50,ResNet101,ResNet变体:RN50x4,RN50x16,RN50x64,
3个vision transformer系列:ViT-B/32,ViT/B-16,ViT-L/14,32,16,14指patches大小
32个epoch,Adam优化器,batch size =3w+,
超参数grid search,random search和手动调整
对比学习temperature超参数,CLIP把temperature设置为可学习的标量,直接在模型训练过程中优化。超参数通过ResNet50训练1个epoch确定。
4.4工程优化
多机器分布式训练,混合精度训练,加速且节省内存
采用节省内存方式:gradient checkpointing,half-precision Adam statistics,half-precision stochastically rounded text encoder weights
相似度计算分配到不同的GPU上做
4.5 zero-shot推理
liner probe:冻结预训练模型,加上一个分类头fc
finetune:放开整个网络,更灵活,数据集较大时,finetune比liner probe效果好很多
linear probing性能上限<finetune task最佳性能
CLIP使用liner probe:
(1)研究与数据集无关的预训练方式,如果使用finetune方法无法验证预训练模型效果好不好
(2)liner probe只训练fc层与特征提取无关,可以验证
(3)只有fc层,无需调参,数据集比较大,一般用较大lr,较小则用小lr(稍一学习就过拟合了)
4.6效果
CLIP ,zero-shot ImageNet与resnet50效果持平
CLIP ViT Large效果堪比ResNet101
CLIP为什么效果好?
以往没有这么大的数据集、那么大的算力,那么大的模型,那么好的自监督训练方式
CLIP使用了4亿数据对, ViT Large模型,是ConVIRT的简化版本
4.7结论
单模态对比学习,如MOCO,单模态掩码学习,如MAE只能学习视觉特征,而无法与自然语言联系咋一起,很难去做zero-shot迁移。CLIP想法简单,实现高效,泛化稳健性不错
打破固定种类标签的范式,模型的输入输出类别自由度大,而不是确定类别label。摆脱了categorical label的限制,训练和推理的时候不需要提前定义好label
模型大小和迁移效果正相关,可以根据模型大小大概推测出迁移效果
5.与人类比较
CLIP zero shot > human zero-shot、one-shot、two-shot
与人对比,怎么再提高CLIP效果
6.CLIP应用
CLIP应用:分类、检测、分割、视频动作识别,检索、多模态、图像生成
6.1 图像生成
2021 StyleCLIP=CLIP+style GAN,通过文字引导图像生成:如改变发型,卸妆,改变颜色,眼睛变大,老虎皮毛变化为狮子,建筑风格改变
2021 CLIPDraw 不进行模型训练,直接gradient descent生成简笔画
6.2 检测
open vocabulary detector,开放类别检测,检测新类 open-vacabulary object detection via vision and knowledge distillation Google
利用自然语言,摆脱了基础类的限制,如,得到黄色color的鸭子duck
6.3 视频检索
contrastive lanauage-image forensic search
CILP视频检索:视频中有没有出现某个目标,如,a truck with the text '货拉拉'
7.Limitation
(1)CLIP VS baseline ResNet,不是state of the art
SOTA:EfficientNet noise student或Vision transformer 或MAE
在细分类数据集上效果不好,低于ResNet 50
CLIP扩大1000倍计算量 = SOTA,需提高计算和数据
(2)CLIP无法处理特征抽象的概念
如,数一数图像中的dog有多少只
(3)out of distribution,泛化会很差
如,数据集MINST OCR上效果88%,远低于一般99%。跟普通的深度学习模型一样,都非常的脆弱
(4)需提供prompt分类,无法自动化理解图像内容生成caption描述
还是需要给定类别,判断与图像是否相似
受限于计算资源,图像caption生成的基线网络无法训练
下一步:对比学习loss+生成式loss,二者优势结合,利用对比学习模型高效性和生成式模型的灵活性
(5)数据利用率低,需大量数据
解决方法:1.数据增强 2.自监督学习 3.伪标签,提高数据利用率
(6)ImageNet偏见引入
网络结构和超参数根据ImageNet设计,使其在ImageNet上效果最佳,无形之中引入了偏见。
27个数据集代表性不强,自创新测试集zero-shot更有说服力
(7)网上数据未经清洗,可能带有社会偏见
(8)CLIP zero shot> CLIP few shot
按照常理zero shot< few shot,结果相反,怎么进一步优化符合人类及理论