本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
你是否也遇到传统RAG系统最核心的结构性痛点:工具单一,缺乏判断。传统的RAG就像一个只配了一把锤子的工匠,看所有问题都像钉子,只会机械地敲打自己的向量数据库。
这导致了一个尴尬的局面:对于需要权威、专业知识的"深"问题,它表现优异;但对于需要实时性、广度的"新"问题,它却无能为力。
我们不得不手动切换工具,或者在提问时费心思考"它到底会用什么方式来回答?"------这无疑是智能助手走向真正"智能"路上的巨大绊脚石。
今天要深入剖析的 MCP(Model Context Protocol)驱动的智能体化RAG系统,正是为了根治这一痛点而生。它的革命性不在于增加了多少新工具,而在于赋予了AI一个"工具选择大脑"。这个系统让AI助手第一次拥有了"情境感知"能力,能够像一位经验丰富的专家一样,根据问题的性质,自动、智能地选择最合适的工具链。接下来,让我们一起看看它是如何实现的。
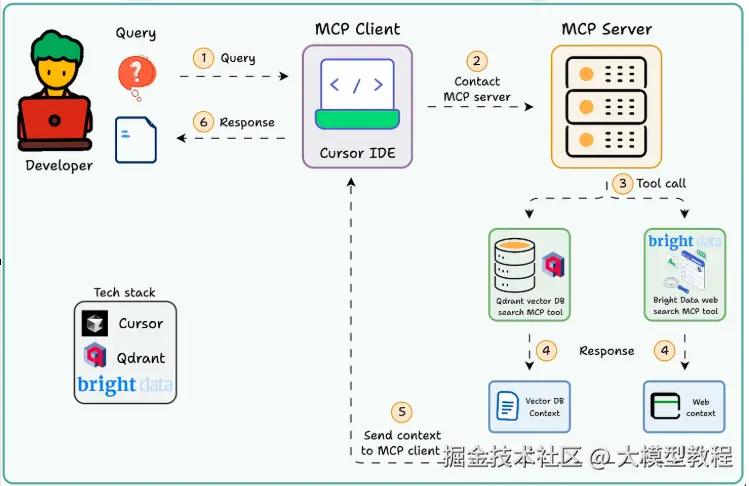
一、什么是智能体化RAG?
传统的RAG(检索增强生成)系统往往比较"呆板"------它只会从固定的知识库中检索信息。但是智能体化的RAG就不同了,它能够根据查询的性质,智能地选择最合适的工具:需要专业知识时查询向量数据库,需要最新信息时转向网络搜索。
想象一下,你问AI助手"机器学习中的过拟合是什么?",它会从专业的ML知识库中给你准确答案;但如果你问"今天的天气怎么样?",它会智能地切换到网络搜索模式。这就是智能体化RAG的魅力所在。
二、系统架构概览
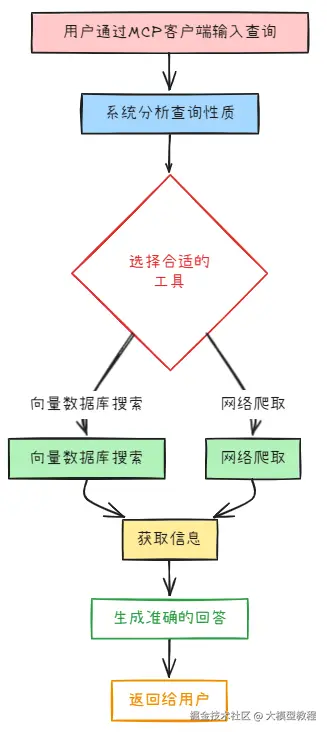
这个系统的工作流程相当优雅:
- 用户通过MCP客户端输入查询
- 系统分析查询性质,选择合适的工具
- 向量数据库搜索或网络爬取获取信息
- 生成准确的回答返回给用户
核心技术栈包括:
- Bright Data:处理大规模网络爬取
- Qdrant:高性能向量数据库
- Cursor:作为MCP客户端
三、动手实现:从零开始构建
让我们一步步实现这个系统。首先安装必要的依赖:
pip install fastmcp qdrant-client requests python-dotenv第一步:启动MCP服务器
python
import asyncio
import os
from dotenv import load_dotenv
from fastmcp import FastMCP
from qdrant_client import QdrantClient
from qdrant_client.http import models
import requests
import json
# 加载环境变量
load_dotenv()
# 初始化MCP服务器
mcp = FastMCP("Agentic RAG Server")
# 配置
QDRANT_HOST = "localhost"
QDRANT_PORT = 6333
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# 初始化Qdrant客户端
qdrant_client = QdrantClient(host=QDRANT_HOST, port=QDRANT_PORT)第二步:向量数据库MCP工具
这是系统的核心工具之一,用于查询机器学习相关的知识:
python
@mcp.tool()
def search_vector_db(query: str, limit: int = 5) -> str:
"""
在向量数据库中搜索与机器学习相关的内容。
Args:
query: 搜索查询文本
limit: 返回结果的最大数量
Returns:
格式化的搜索结果字符串
"""
try:
# 这里使用一个简化的示例,实际应用中你需要先将查询向量化
# 假设我们有一个预训练的向量化模型
# 模拟向量搜索结果(实际项目中需要真实的向量化过程)
ml_knowledge_base = {
"过拟合": "过拟合是指模型在训练数据上表现很好,但在新数据上表现差的现象。常见的解决方法包括正则化、dropout、early stopping等。",
"机器学习": "机器学习是人工智能的一个分支,通过算法让计算机从数据中学习规律,无需明确编程。",
"深度学习": "深度学习是机器学习的一个子集,使用多层神经网络来学习数据的复杂模式。",
"梯度下降": "梯度下降是一种优化算法,通过迭代地调整参数来最小化损失函数。"
}
results = []
query_lower = query.lower()
for topic, content in ml_knowledge_base.items():
if topic in query_lower or any(word in content.lower() for word in query_lower.split()):
results.append(f"主题: {topic}\n内容: {content}")
if not results:
return "在机器学习知识库中没有找到相关内容。建议使用网络搜索工具获取更广泛的信息。"
return "\n\n".join(results[:limit])
except Exception as e:
return f"向量数据库搜索出错: {str(e)}"第三步:网络搜索MCP工具
当向量数据库无法提供答案时,我们需要这个回退机制:
python
@mcp.tool()
def web_search_bright_data(query: str, num_results: int = 3) -> str:
"""
使用Bright Data进行网络搜索,获取最新信息。
Args:
query: 搜索查询
num_results: 返回结果数量
Returns:
格式化的搜索结果
"""
if not BRIGHT_DATA_API_KEY:
return "错误:未配置Bright Data API密钥"
try:
# Bright Data SERP API endpoint
url = "https://api.brightdata.com/serp/search"
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
payload = {
"query": query,
"country": "CN",
"language": "zh",
"num": num_results
}
# 发起API请求
response = requests.post(url, headers=headers, json=payload, timeout=30)
if response.status_code == 200:
data = response.json()
results = []
for item in data.get("organic", []):
title = item.get("title", "无标题")
snippet = item.get("snippet", "无摘要")
url = item.get("url", "")
results.append(f"标题: {title}\n摘要: {snippet}\n链接: {url}")
if results:
return "\n\n".join(results)
else:
return "网络搜索未找到相关结果"
else:
return f"网络搜索失败,状态码: {response.status_code}"
except requests.exceptions.RequestException as e:
return f"网络请求错误: {str(e)}"
except Exception as e:
return f"网络搜索出错: {str(e)}"第四步:智能工具选择器
这个函数帮助系统决定使用哪个工具:
python
@mcp.tool()
def smart_search(query: str) -> str:
"""
智能搜索工具,根据查询内容自动选择合适的搜索方式。
Args:
query: 用户查询
Returns:
搜索结果
"""
# 机器学习相关关键词
ml_keywords = [
"机器学习", "深度学习", "神经网络", "算法", "模型",
"过拟合", "欠拟合", "梯度下降", "反向传播", "卷积",
"RNN", "LSTM", "Transformer", "监督学习", "无监督学习",
"强化学习", "特征工程", "数据预处理", "正则化"
]
query_lower = query.lower()
is_ml_related = any(keyword in query_lower for keyword in ml_keywords)
if is_ml_related:
print(f"检测到机器学习相关查询,使用向量数据库搜索")
result = search_vector_db(query)
return f"【向量数据库搜索结果】\n\n{result}"
else:
print(f"检测到通用查询,使用网络搜索")
result = web_search_bright_data(query)
return f"【网络搜索结果】\n\n{result}"第五步:启动服务器
python
async def main():
"""启动MCP服务器"""
print("正在启动MCP智能体化RAG服务器...")
print(f"服务器将在 localhost:8000 上运行")
print("可用工具:")
print("- search_vector_db: 搜索机器学习知识库")
print("- web_search_bright_data: 网络搜索")
print("- smart_search: 智能搜索(自动选择工具)")
# 启动服务器
await mcp.run(port=8000)
if __name__ == "__main__":
asyncio.run(main())四、Cursor集成配置
要在Cursor中使用这个MCP服务器,需要在设置中添加MCP配置。创建一个 .cursor-mcp-config.json 文件:
json
{
"mcp_servers": {
"agentic-rag": {
"command": "python",
"args": ["path/to/your/mcp_server.py"],
"env": {
"BRIGHT_DATA_API_KEY": "your-api-key-here"
}
}
}
}然后在Cursor的设置中:
- 打开 设置 → MCP
- 点击"添加新的全局MCP服务器"
- 粘贴上述配置
五、实际使用效果
配置完成后,你可以在Cursor中这样使用:
查询机器学习问题:
- 用户:"什么是过拟合?"
- 系统:自动调用向量数据库工具,返回专业解答
查询一般信息:
- 用户:"今天北京的天气如何?"
- 系统:智能切换到网络搜索,获取实时信息
六、解决智能体执行中的挑战
在实际部署中,智能体经常遇到各种技术障碍:
1. IP封禁问题
普通的网络爬取很容易被目标网站识别并封禁。Bright Data通过其庞大的IP池和智能轮换机制完美解决了这个问题。
2. 反爬机制应对
现代网站都有复杂的反爬策略。系统内置的浏览器工具可以模拟真实用户行为,绕过这些检测。
3. 验证码处理
自动化的验证码识别和处理,确保数据获取的连续性。
七、环境配置文件
创建 .env 文件来管理配置:
ini
# .env 文件
BRIGHT_DATA_API_KEY=your_bright_data_api_key_here
QDRANT_HOST=localhost
QDRANT_PORT=6333
MCP_SERVER_PORT=8000八、进阶优化建议
1. 缓存机制
python
from functools import lru_cache
import time
@lru_cache(maxsize=100)
def cached_search(query: str, timestamp: int) -> str:
"""带缓存的搜索,timestamp用于缓存失效"""
return search_vector_db(query)
# 使用时
current_time = int(time.time() / 3600) # 每小时失效
result = cached_search(query, current_time)2. 异步处理
python
import asyncio
async def async_smart_search(query: str) -> str:
"""异步版本的智能搜索"""
loop = asyncio.get_event_loop()
# 并行执行多个搜索任务
tasks = [
loop.run_in_executor(None, search_vector_db, query),
loop.run_in_executor(None, web_search_bright_data, query)
]
results = await asyncio.gather(*tasks, return_exceptions=True)
# 根据结果质量选择最佳答案
return select_best_result(results)3. 结果质量评估
python
def evaluate_result_quality(result: str, query: str) -> float:
"""评估搜索结果质量"""
if not result or "错误" in result:
return 0.0
query_words = set(query.lower().split())
result_words = set(result.lower().split())
# 计算相关性得分
overlap = len(query_words.intersection(result_words))
relevance_score = overlap / len(query_words) if query_words else 0
return relevance_score九、总结
MCP驱动的智能体化RAG系统真正实现了AI助手的"智能化"------不再是简单的问答,而是能够根据不同场景智能选择最合适的信息源。结合Bright Data的强大爬取能力和Qdrant的高效向量搜索,这个系统为构建下一代智能助手提供了完整的解决方案。
通过这个实践项目,你可以深入理解现代AI系统的架构设计思路,也为后续开发更复杂的智能体应用打下坚实基础。
记住,技术的价值在于解决实际问题。这套系统的核心优势就在于它能够让AI助手在面对不同类型查询时,都能给出最准确、最及时的回答。这正是我们在AI时代所追求的------让机器真正理解我们的需求,并提供最合适的帮助。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。