一、前言
在 2023 年 10 月jina ai发布了一个具有8k上下文长度的开源嵌入模型,早期的或者小型的嵌入模型通常只有512tokens,和openai同类型的embedding模型对比如下:

该模型在分类平均、重排平均、检索平均和摘要平均方面均优于 OpenAI 的同类产品。
关于嵌入模型中长上下文的实用性一直存在争议。对于许多应用来说,将数千词的文档编码为单个嵌入表示并不理想。许多用例需要检索文本的较小部分,而基于密集向量的检索系统通常在处理较小文本段时表现更好,因为语义在嵌入向量中不太可能被"过度压缩"。
检索增强生成(RAG)是最著名的应用之一,它需要将文档分割成较小的文本块(比如在 512 个 token 以内)。这些文本块通常存储在向量数据库中,其向量表示由文本嵌入模型生成。在运行时,同样的嵌入模型将查询编码为向量表示,然后用于识别相关的存储文本块。这些文本块随后传递给大型语言模型(LLM),后者基于检索到的文本合成对查询的响应。下面是一个RAG的经典架构:
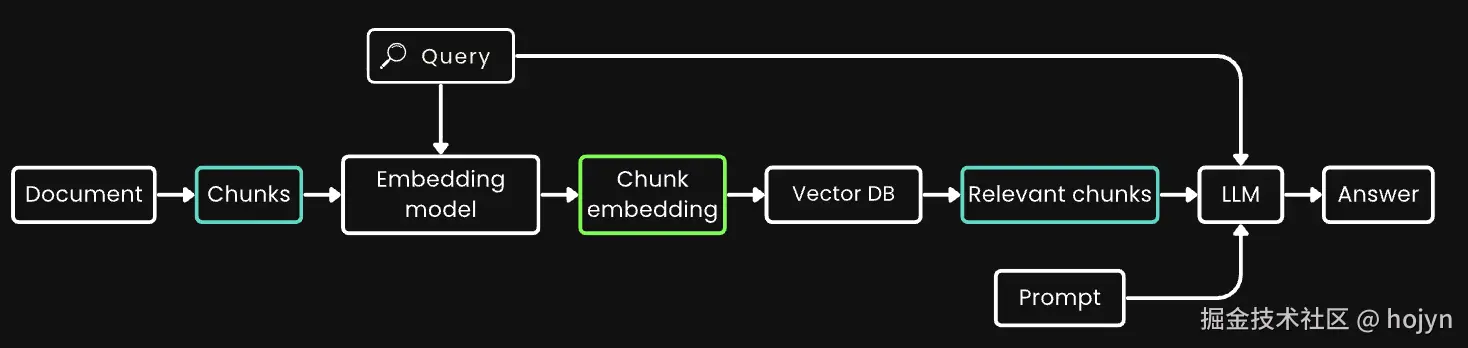
简而言之,嵌入较小的文本块似乎更可取,部分原因是下游 LLM 的输入大小限制,还因为**人们担心长上下文中的重要上下文信息在压缩成单个向量时可能会被稀释。**但如果行业只需要 512 上下文长度的嵌入模型,那训练 8192 上下文长度的嵌入模型又有什么意义呢?
二、背景:丢失上下文的问题
简单的分块-嵌入-检索-生成的 RAG 流程并非没有挑战。具体来说:这个过程可能会破坏远距离上下文依赖关系,主要原因是由于embedding模型在对分块生成向量表示时,每个分块丢失了上下文的信息。
在下图中,一篇维基百科文章被分成句子块。你可以看到像"its"和"the city"这样的短语都指代"Berlin",而"Berlin"只在第一句中出现。这使得嵌入模型更难将这些引用与正确的实体联系起来,从而产生较低质量的向量表示。

这意味着,如果我们像上面的例子那样将长文章分成句子长度的块,并分别获取每个块的向量表示时,embedding模型并不清楚第二、三个块中的"its"和"the city"和第一个块中的Berlin之间的关系。此时生成的向量表示一定会缺失该特征,而导致向量表示的不准确。
RAG 系统可能难以回答"柏林的人口是多少?"这样的查询。因为城市名称和人口数字从未在同一个文本块中一起出现,而且在没有更大文档上下文的情况下,LLM 在面对这些块时无法解析像"it"或"the city"这样的照应指代。
这个问题在长篇文章中会变的更为频繁出现。比如在这个文章中出现了关于2次关于天气的段落:"这个城市在冬天天气很冷"、"这个城市在冬天天气很温暖"。而在在生成向量表示时,这两个段落上方丢失两个上下文:"接下来我将介绍北京这座城市","接下来我将介绍昆明这座城市"。
如果问"北京冬天天气怎么样?",大概率会检索出来:"接下来我将介绍北京这座城市"、"这个城市在冬天天气很冷"、"这个城市在冬天天气很温暖"。此时大模型根本不清楚北京天气究竟是什么?
有一些启发式方法可以缓解这个问题,比如使用滑动窗口重新采样、使用父子文档,以及执行多次文档扫描等。然而,像所有启发式方法一样,这些方法也是可能有效可能无效的;它们在某些情况下可能有用,但没有理论保证其有效性。
三、解决方案:Late Chunking
传统编码方法涉及使用句子、段落或最大长度限制来预先分割文本。之后,嵌入模型重复应用于这些生成的文本块。为了为每个块生成单个嵌入,许多嵌入模型使用平均池化处理这些 token 级别的嵌入,以输出单个嵌入向量。
 embedding模型处理的过程是:
embedding模型处理的过程是:
- 将文本转换成词元(token)列表
- 将词元列表输入到模型中,模型会输出每个词元的向量表示,此时会得到N个向量
- 使用平均池化将N个向量合并成一个向量(通过向量空间的语义叠加,即向量求和;再对结果规范化,避免词元列表长度干扰,即求平均)
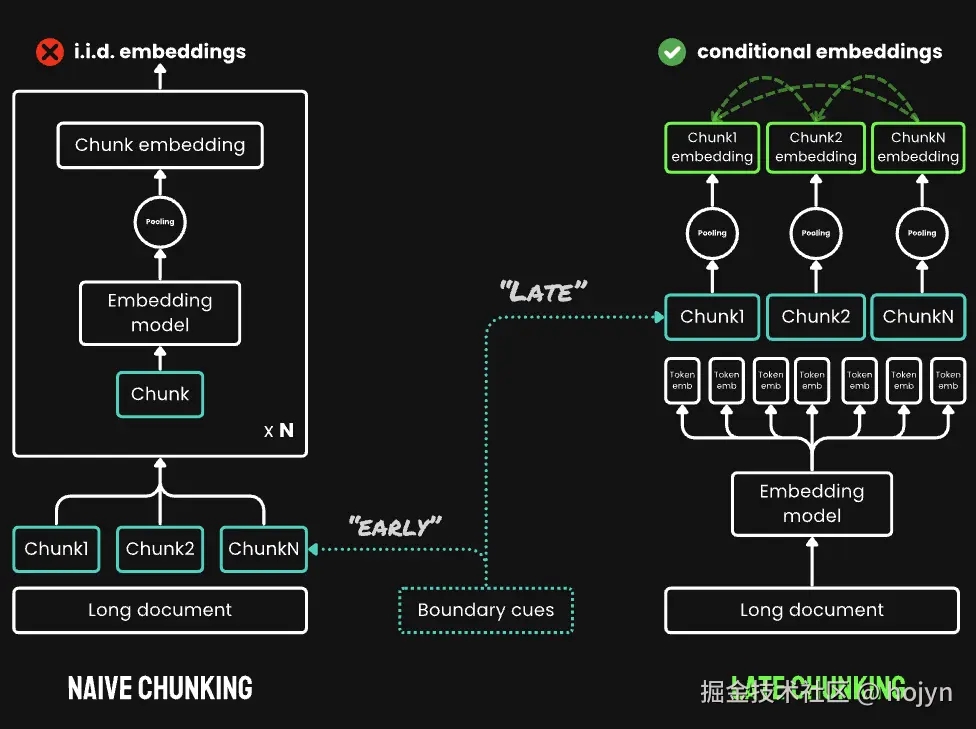
相比之下,Late Chunking做法是:先嵌入,再分块
-
将整个文本输入到embedding模型中,此时嵌入模型的 transformer 层将应用于整个文本或尽可能多的文本,这会为每个 token 生成一个包含整个文本信息的向量表示序列。
-
按照原先的分块逻辑,生成各个分块
-
使用嵌入模型的词表,将各个分块转换成词元列表,此时会得到每个分块词元开始索引和结束索引
假设有一篇文章会切成三个分块,使用嵌入模型转换词元列表时会得到:1, 1、2, 2、3, 3。
每个分块的开始索引(左开右闭):
- start:0,end:2
- start:2,end:3
- start:3,end:4
-
按照每个分块索引,将嵌入模型返回的每个词元的向量表示,切割成三个分块对应的向量表示。
-
对每个分块的向量表示进行平均池化,生成每个分块的唯一向量表示
与传统的先分块再嵌入的模式不同,Late Chunking创建了一组块嵌入,其中每个嵌入都"以"前面的嵌入为条件,从而为每个块编码更多的上下文信息,然后再进行分块,这就是其名称中"Late"的由来。
显然,要有效地应用 Late Chunking,我们需要一个能支持最多 8192 个 token(大约十个标准页面的文本)的长上下文嵌入模型。这种长度的文本段不太可能有需要更长上下文才能解决的上下文依赖关系。在保留上下文信息的同时对长文档进行分块是一项挑战,Late Chunking利用长上下文嵌入模型生成上下文化的分块嵌入,以实现更好的检索应用。
四、效果评估
当对上述维基百科示例应用延迟分块时,你可以立即看到语义相似度的提升。例如,在维基百科文章中"这座城市"和"柏林"的情况下,表示"这座城市"的向量现在包含了将其链接到之前提到的"柏林"的信息,这使得它在涉及该城市名称的查询中能获得更好的匹配效果。
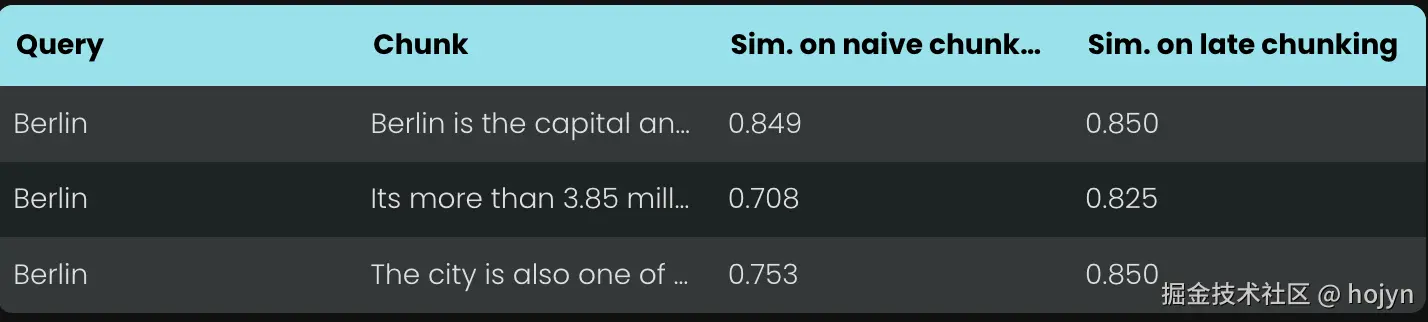 对于上面第二个例子,如果问"北京冬天天气怎么样?",使用late chunk后会检索出来:"接下来我将介绍北京这座城市"、"这个城市在冬天天气很冷",解决了上下文丢失导致检索不准确的问题。
对于上面第二个例子,如果问"北京冬天天气怎么样?",使用late chunk后会检索出来:"接下来我将介绍北京这座城市"、"这个城市在冬天天气很冷",解决了上下文丢失导致检索不准确的问题。
为了验证延迟分块有效性,使用BeIR的检索基准进行测试,这些检索任务包括一个查询集、一个文本文档语料库和一个QRels(查询相关性判断)文件,该文件存储了与每个查询相关的文档 ID 信息。
为了识别与查询相关的文档
- 将文档分块,使用了一个正则表达式,将文本分割成大约 256 个令牌长度的字符串。
- 使用embedding模型生成嵌入索引
- 使用 k-近邻(kNN)为每个查询嵌入确定最相似的块,得到块的排名
- 通过块的排名得到块所属文档的排名,用该文档排名就可以和真实的排名进行比较,并计算检索指标(nDCG@10)
最终在各种 BeIR 数据集上进行了这项评估,比较了传统分块方法与late chunking方法,如下所示:
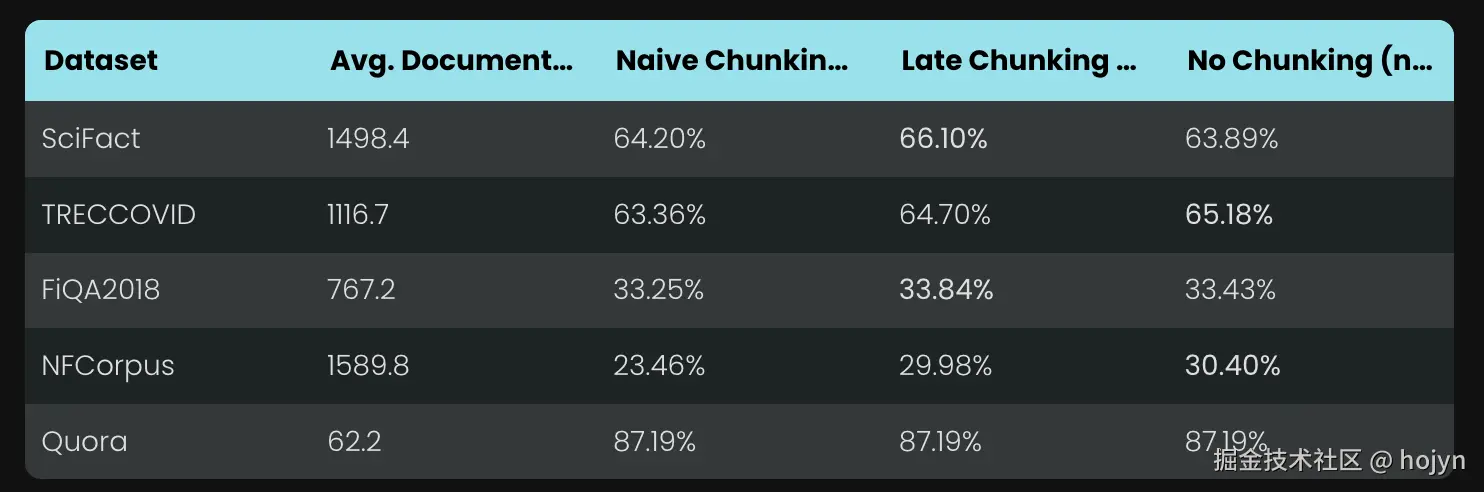
- 第一列和第二列分别是数据集以及数据集中文档的平均长度
- 第三列到第五列比较了传统分块、late chunking与不分块情况下的检索指标
在所有情况下,late chunking相比传统方法都提高了分数。在某些情况下,它甚至优于将整个文档编码为单个嵌入的方法。(由于大模型上下文的限制,不分块在RAG系统中非常少见)。同时还发现:文档越长,late chunking策略的效果就越好。
作者还测试了三种不同大小的嵌入模型,虽然late chunking策略会提高分时,但是没有任何一个使用 late chunking 的较弱模型能够超越不使用它的较强模型。也就是说:嵌入模型本身仍然是性能最重要的因素。
除此之外,实验还发现一些有趣的现象:应用于固定 token 边界的 late chunking 的表现优于具有语义边界提示的传统分块。这意味着虽然late chunking策略并非解决"如何寻找更好分块边界?"的问题,但是在使用较差的分块边界具有韧性。需要注意的是,对不良边界具有弹性并不意味着我们可以忽视它们------它们对人类和 LLM 的可读性仍然很重要。
五、总结
什么是后置分块?后置分块是一种使用长文本 embedding 模型生成块级 embeddings 的直接方法。它速度快、对边界提示具有弹性且非常有效。它不是一种启发式方法或过度工程------而是基于对 transformer 机制深入理解的精心设计。
作为模型用户,在评估新的嵌入模型或 API 时,你可以按照以下步骤检查它是否可能支持迟分技术:
- 单一输出:模型/API 是否仅为每个句子生成一个最终的 embedding 而不是词级别的 embeddings?如果是,那它可能就不支持后置分块(尤其是那些网络 API)。
- 长文本支持:模型/API 是否能处理至少 8192 个 tokens 的上下文?如果不能,后置分块就不适用------或者更准确地说,为短上下文模型采用后置分块是没有意义的。如果支持,请确保它在处理长文本时真的表现良好,而不仅仅是声称支持。你通常可以在模型的技术报告中找到这些信息,比如在 LongMTEB 或其他长文本基准测试上的评估结果。
- 平均池化:对于可自托管的模型或提供池化前词级 embeddings 的 API,检查默认的池化方法是否为平均池化。使用 CLS 或最大池化的模型与后置分块不兼容。