
背景
在传统呼叫中心场景中,基于按键导航是一种经典的用户交互方式。然而,随着导航场景的增加、分类的扩展以及层级的增多,按键流程设计变得越来越复杂,用户体验也因此受到影响。为了提供更加流畅的用户体验,半开放式语音导航应运而生。在这种模式下,终端用户只需说出相应的关键词,即可获得下一步指引。
📢限时插播:无需管理基础设施,利用亚马逊技术与生态,快速集成与部署生成式AI模型能力。
✨ 精心设计,旨在引导您深入探索Amazon Bedrock的模型选择与调用、模型自动化评估以及安全围栏(Guardrail)等重要功能。
⏩快快点击进入《多模一站通 ------ Amazon Bedrock 上的基础模型初体验》实验
构建无限, 探索启程!
目前,市面上常见的解决方案是基于自动语音识别(ASR)技术将语音转换为文本,然后利用算法进行关键词匹配,或者直接基于音素进行匹配。本文将探讨如何利用 Amazon Bedrock,尤其是 Nova 模型来实现关键词匹配。在后续文章中,我们还将讨论新兴的 Voice to Voice 模型(如 Amazon Nova Sonic)如何优化该场景的用户体验。
解决方案介绍
如背景介绍,本文将探索基于 Amazon Transcribe 进行语音转文本,然后利用 Amazon Bedrock 中模型的文字能力,尤其是文字发音相关的理解能力进行关键词匹配。在该方案中存在着几个方面的难点:
1、ASR 语音转文本的准确性挑战
- 不同上下文语境下的文本转录差异
- 多样化发音与口音导致的转录变化
2、大语言模型关键词匹配能力评估
- 短句中的关键词精准提取能力
- 基于语音相似度的关键词识别能力
- 对停顿、表达习惯等因素的适应能力
3、测试方法与数据集构建
- 针对客户特定场景的定制化测试集生成
- 全方位覆盖客户真实使用场景的测试策略
对于上述难点,尤其是 ASR 语音转文本准确性方面,在传统方案中,通常会让客户提供,或者基于算法生成对应短语/关键词的多个变体表达(发音)方式,如下所示:
rust
Tesla -> {"Desla", "Tesla"}
TIFFANY AND CO -> {"T AND CO, TIFFANY AND CO", "TIFFANY AND CO"}在本文中,我们会首先基于一个模拟的原始导航关键词词库,通过 Amazon Polly 基于不同口音(美国英语,印度英语等)生成对应的录音文件,然后通过 Amazon Transcribe 生成对应语音的文本,最后进行汇总,即利用了 ASR 的语音/语音关联性导致的转录"差异",完成了原始关键词词库的扩词,同时利用该扩词集合还可以作为后续的测试集。后续,我们会利用该扩词词库作为我们整个实验的一个基础,进行如下方面的探索:
- 基于用户给定的测试场景进行输入,然后匹配用户的输入和词库查看匹配效果。
- 探索大语言模型的语言理解能力,即直接用其生成扩展词库,然后对比原始词库查看差异性。
- 不进行任何扩词的操作,直接利用扩词词库作为输出,查看大语言模型直接匹配的能力。
- 最后我们会对比不同大语言模型在准确度,延迟以及成本方面的表现。
方案实现
基于以上的分析,我们将整个方案分为离线处理和在线推理两个部分,架构如下图所示:
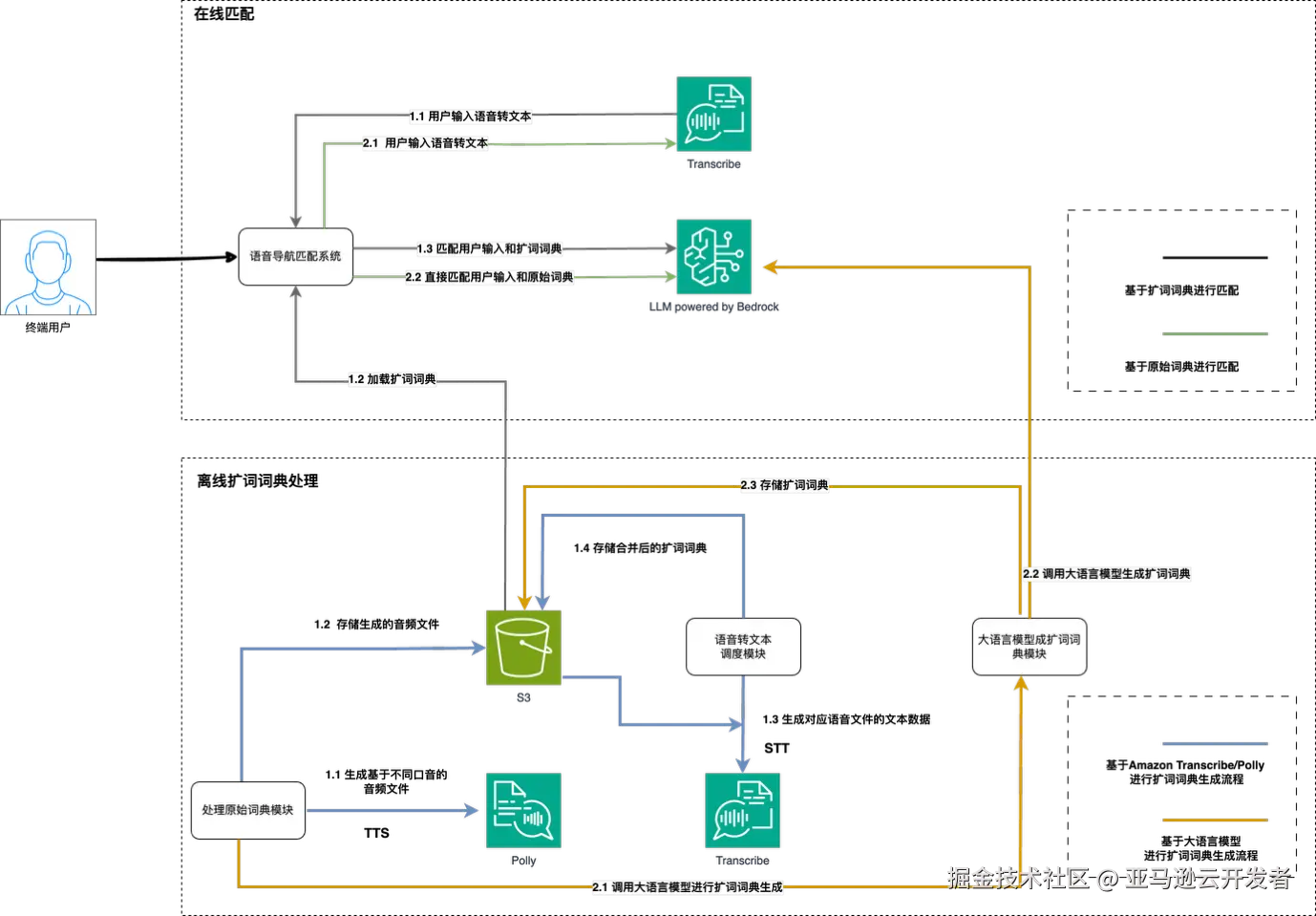
离线词库处理
通过 Amazon Transcribe/Polly 生成扩词词典:
- 使用 Amazon Polly 基于不同口音/性别/种族合成语音
- 将语音(mp3)文件存储到 Amazon S3
- 使用 Amazon Transcribe 将语音文件转写为文字
- 将整理后的扩展词词典存储回 S3
通过大语言模型(LLM)生成扩词词典:
- 输入原始词典,以及设置对应的 Prompt
- 调用大语言模型生成匹配词典
- 存储扩词词典回 S3
在线匹配
使用预生成词典进行匹配:
- 使用 Amazon Transcribe 将输入语音转写为词句
- 加载公司/客户预生成的词典到程序中
- 使用大语言模型(LLM)将用户输入与扩词词典匹配,并据此进行路由
无需预生成词典,直接匹配:
- 使用 Amazon Transcribe 将输入语音转写为词句
- 使用大语言模型(LLM)将用户输入与预定义指令直接匹配,并进行路由
实验步骤和结果
由于篇幅有限,本文重点在进行在线推理部分的介绍,对于离线数据处理的部分,有兴趣的读者可以参考该项目( https://github.com/jansony1/DialByName )。
部署
1、启动一个 EC2 实例:
- 选择 Amazon Linux 2 或 Ubuntu AMI
- 在"配置实例"步骤中,选择您创建的 IAM 角色(例如,"VoiceSyncEC2Role")
- 根据需要配置其他设置(安全组、密钥对等)
- 确保为实例启用 IMDSv2(这是新实例的默认设置)
2、通过 SSH 连接到您的 EC2 实例
3、在您的 EC2 实例上安装 Docker 和 Docker Compose:
bash
# 对于Amazon Linux 2
sudo yum update -y
sudo amazon-linux-extras install docker
sudo service docker start
sudo usermod -a -G docker ec2-user
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
# 对于Ubuntu
sudo apt-get update
sudo apt-get install -y ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
sudo systemctl start docker
sudo systemctl enable docker
sudo usermod -aG docker $USER
# 修改Hop配置
$ aws ec2 modify-instance-metadata-options --instance-id <Current_EC2_ID> --http-tokens required --http-endpoint enabled --http-put-response-hop-limit 24、将代码库克隆到 EC2 实例:
shell
Plaintext
$ git clone https://github.com/jansony1/voice_matching_test.git && cd voice_matching_test5、配置 ALB(应用负载均衡器):
- 如果您尚未创建,请在 AWS 控制台中创建 ALB
- 为 HTTPS(端口 443)添加侦听器规则
- 默认规则指向 EC2 部署的 8080 端口
- 设置新规则,将路径模式为/api/*的请求转发到后端服务(EC2 实例端口 8000)
- 确保 EC2 安全组(8080/8000)对 ALB 安全组开放
- 确保 ALB 安全组的端口 443 是开放的
- 使用 AWS Certificate Manager(ACM)为您的域名设置 SSL/TLS 证书,并将其与上述 443 端口关联
- 如果您使用 LLM 扩词生成功能,请将 ALB 超时调整为至少 10 分钟
6、创建带有后端 URL 的环境变量:
shell
# 创建.env文件
$ cat > .env << EOL
AWS_DEFAULT_REGION=us-west-2
# 使用您的ALB域名
BACKEND_URL=https://your-alb-address.com/api
EOL7、构建并启动服务:
shell
## 启动完整堆栈
$ docker compose up --build -d
## 清理堆栈
$ docker compose down8、检查密码
默认用户为 zxxm
arduino
$ docker logs -f <Backend_Container_ID>
Generated random password for username zxxm: {password}9、访问应用程序:在您的网络浏览器中打开 your-alb-address.com
在接下来的测试环节会展开说明
10、可通过如下命令查看对应调用的延迟
makefile
Plaintext
$ tail -f backend/execution_times.log
2024-12-04T05:27:47.788226,anthropic.claude-3-haiku-20240307-v1:0,0.6913
2024-12-04T05:43:12.861047,anthropic.claude-3-haiku-20240307-v1:0,0.9740
2024-12-04T05:44:53.981923,anthropic.claude-3-5-haiku-20241022-v1:0,1.4702重点配置说明
1、后端 URL 配置
- 通过 .env 文件中的 BACKEND_URL 环境变量设置
- 应包含
/api前缀
2、亚马逊云科技区域配置
- AWS_DEFAULT_REGION:部署服务所在的 AWS 区域(默认值:us-west-2)
3、后端 API 前缀
- 所有后端 API 路由都以
/api为前缀 - 例如,获取 EC2 角色的接口为
/api/get_ec2_role
测试界面展示
使用在部署阶段第 9 步 得到的的 ALB 地址在浏览器中打开,输入部署步骤第 8 步得到的用户/密码,进入到如下界面:
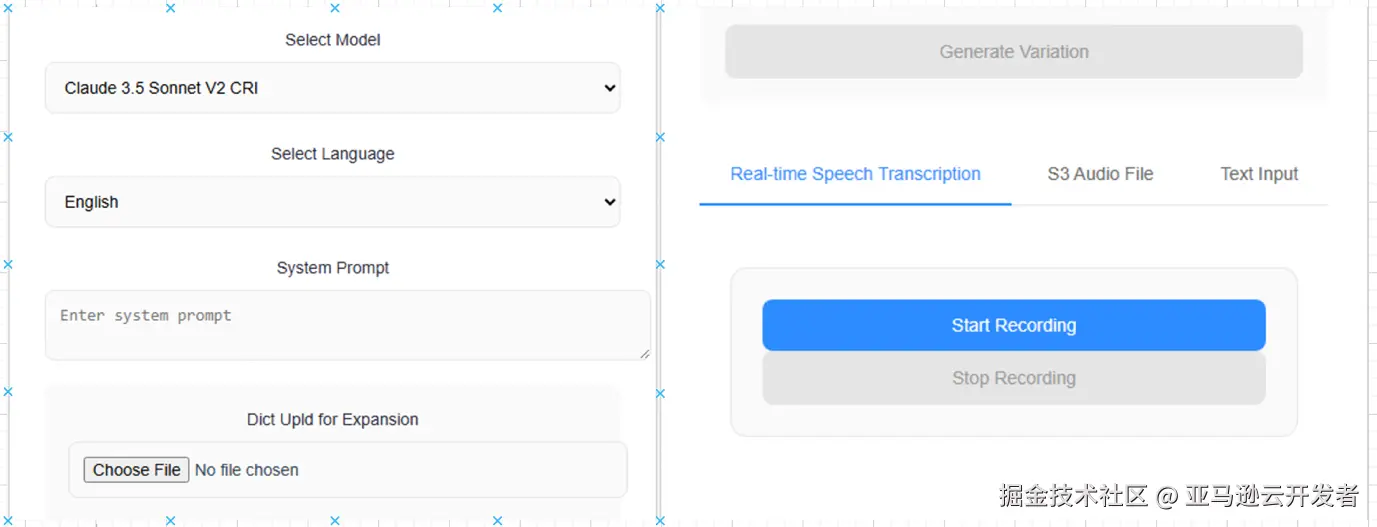
左侧界面解释:
- Select Model:提供了多模型测试的接口
- Select Language:动态传入语言属性,修改 system prompt,使其具有当前语言的背景
- System Prompt:本场景下的系统提示词部分,用户可以根据自身的场景,修改 dictionary 部分
完整提示词见:github.com/jansony1/vo...
- Dict upload for expansion:支持用户上传原始词典,然后基于大语言模型进行扩词
完整提示词见:github.com/jansony1/vo...
右侧界面解释:
- Real-time Speech:支持用户输入实时语音进行测试
- S3 Audio File:基于语音文件进行匹配,方便用户进行测试
- Text Input:支持直接进行文字匹配,可以帮助客户定位 Bad Case 是由于 ASR 还是模型匹配侧导致的
实验部分
实验流程介绍
基于以上的分析,我们需要覆盖的测试方案如下:
- 方案 1:基于完整原始词典(共 86 个条目),使用 TTS(Amazon Polly)+STT(Amazon Transcribe)解决方案生成的扩词词典进行推理匹配。
- 方案 2:基于由 Bedrock 上大语言模型(Claude,Nova)生成的扩词词典进行测试。
- 方案 3:不使用预先生成的词典,直接基于完整原始词典进行测试。
样例扩词词典如下所示:
json
"RAY_BAN": [
"Re about.",
"Reba.",
"Rayan.",
"Ray Ban.",
"Rebound."
],
"NORDSTROM": [
"Norstan.",
"Nordstrom.",
"Nord."
],
"ANTHRO": [
"Andre.",
"And throw.",
"And through.",
"Anthro.",
"And drown."
],
"BOURBON_STEAK": [
"Bourbon steak.",
"Bourbon speak.",
"Bourbon Stake."
],对于上述的测试案例,客户提供的测试场景如下:
场景 1:来自词典的完全匹配单词能力
- 例如:Tesla -> Tesla
场景 2:非单一词汇的匹配能力
- 例如:Go to Tesla -> Tesla
场景 3:发音相近词汇的匹配能力(测试数据以方案 1 数据为 ground truth)
- 例如:Desla -> Tesla
具体测试流程
如上面分析所示,实验中,需要对 3 场景 * 3 方案的组合进行多种测试。在笔者的测试中,为了力求还原真实场景,采用了如下的测试方式:
- 实时语音输入进行测试
- 根据客户提供的 Bad Case 出现最多的 10 组词汇进行测试
- 对于场景 2,使用大语言模型进行短语的生成,对于场景 3,随机挑取 5 个方案 1 生成的扩词进行测试
需要声明的是笔者的测试集有限,其测试结果仅具有参考意义。
测试结果
本文由于篇幅问题并没有展开扩词的具体流程,但下面是使用 TTS/STT 工具生成扩词(Polly 生成至多 25 个语音文件)和直接使用 LLM 进行扩词后的结果对比:
- "LLM_Gen":"平均而言,每个原始词汇大约会生成12-13种可能的扩词"
- "TTS/STT_Gen":"平均而言,每个原始词汇大约有5种可能的原始词汇"
- "unique_to_LLM_Gen":"平均而言,每个条目大约有8种扩词是LLM_Gen独有的"
- "unique_to_TTS/STT_Gen":"平均而言,每个条目大约有1-2种扩词是TTS/STT_Gen独有的"
- "common":"平均而言,每个条目大约有3-4种变化是两个文件共有的"
通过以上,我们可以看到,通过 LLM 生成的扩词词典可以覆盖大部分原始词汇以及其发音可能性。下面展示最终的测试结果如下:
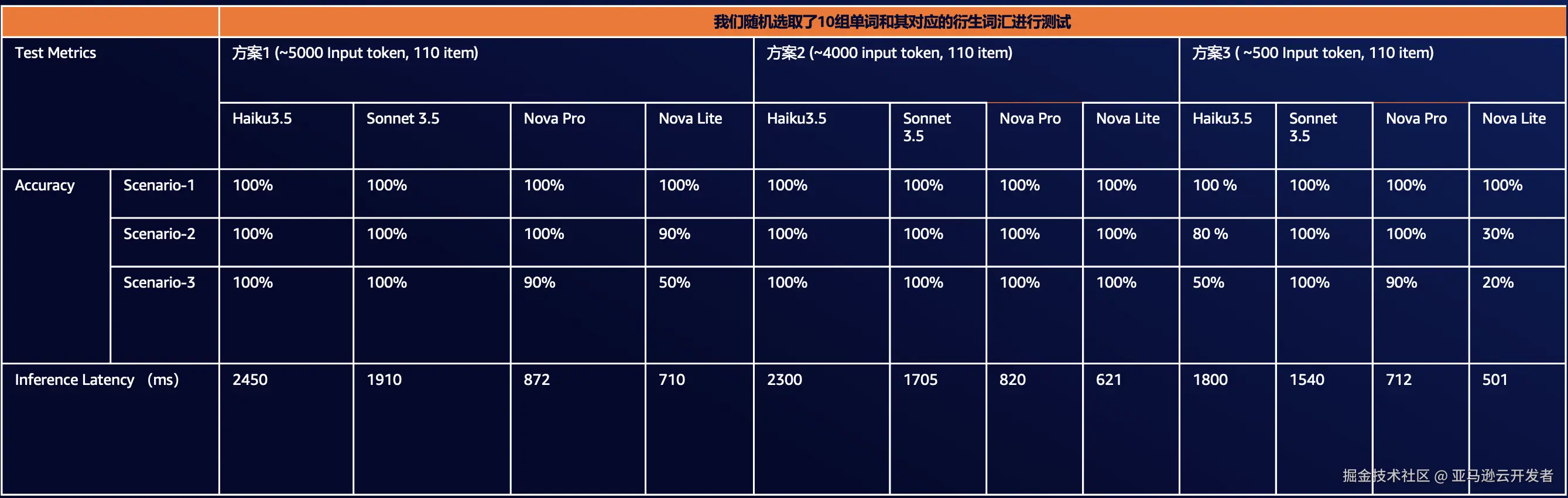
通过分析上图,我们可以得出以下结论:
- 准确率角度:Sonnet 3.5 > Nova Pro >= Haiku 3.5 > Nova Lite
- 延迟角度(仅考虑推理部分):Nova Lite < Nova Pro < Haiku 3.5 < Sonnet 3.5
另外在成本方面,我们分为离线部分和在线部分进行成本分析:
离线处理部分
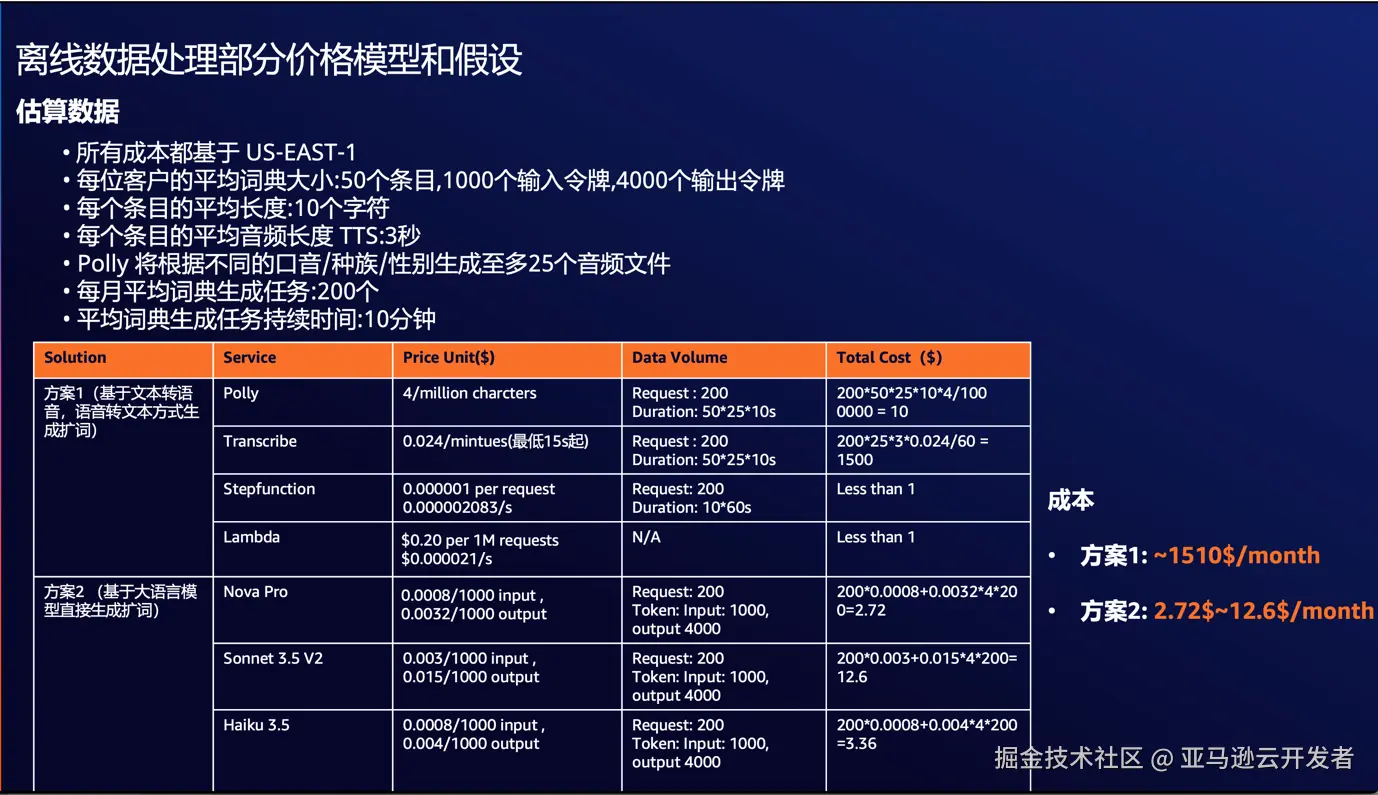
在线推理部分
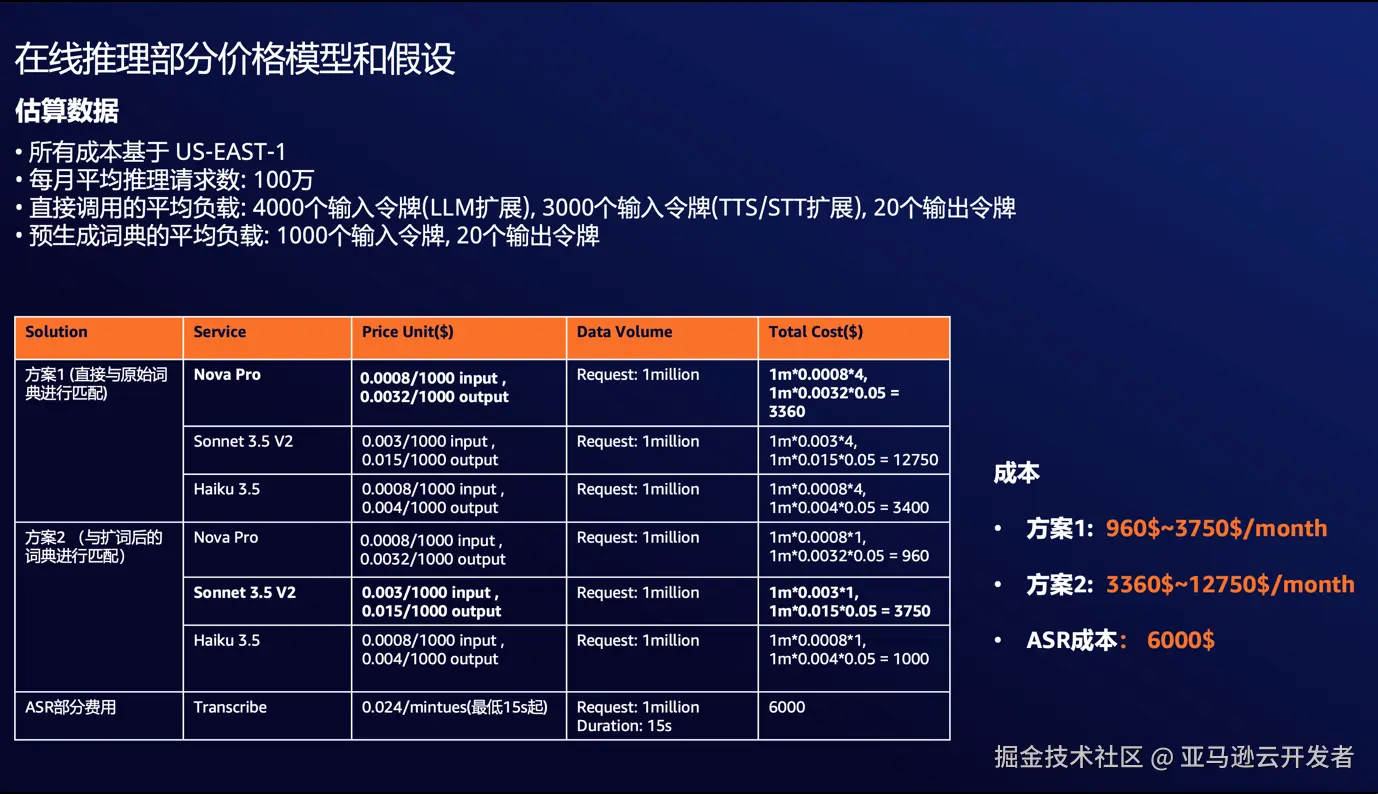
方案对比
最后,基于延迟,成本以及准确性三个维度,笔者认为以下两种方案组合最为可行:
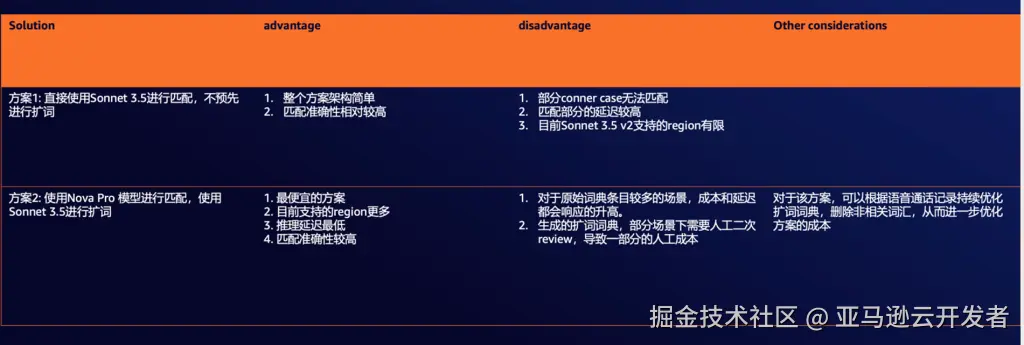
方案总结和未来展望
方案总结
从测试结果看,Amazon Nova 对于语言语音的理解有较强的能力,结合其较高的性价比,在与本文类似的场景中可以进行尝试。另外对于处理多语言任务,在传统的基于文字的客服场景中,经常使用一套英文 prompt 来应对主流语言的场景,截稿到目前为止的测试下,亦可以采用本方法,并且通过如下的系统提示词设定能够一定程度改善:
vbnet
You are an AI assistant for efficient text matching. Your task is to quickly match given text with words from a predefined dictionary. Follow these guidelines:
## Input Format:
<lang>Spanish</lang>
<text>A word or short phrase from speech transcription.</text>
<dictionary>A list of keywords with possible variations.</dictionary>
***
## Instructions:
***
- Take the input language type into matching consideration但是应注意一些专有名词的翻译问题(如采用专有名词词典进行翻译匹配)。最后对于缺乏测试数据集的用户来说,可以利用 Amazon Polly 的发音变种和 Amazon Transcribe 生成对应的基础测试集。
未来展望
最近几个月来,Speech to Speech 模型也层出不穷,笔者也进行了包括 Amazon Nova Sonic 等模型的尝试。如果场景是类似本文中文字匹配,输入和系统提示词没有超过模型上下文,既可以讲对应词典写在提示词侧,Speech to Speech 类的模型,能够在相应流畅度,延迟和准确度的层面较好地进行满足。但是如果是类似于问答的场景,并且需要结合企业数据库(RAG),我们应该知道即使对于 Speech to Speech 模型,其也是有一个类似于 ASR 的流程,然后基于文字进行匹配,那么其延迟势必也会进行增加。同时考虑到 Speech to Speech 模型价格往往数倍于基座模型,我们应该结合自身的场景和需求,因地制宜的选择方案。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者

本期最新实验《多模一站通 ------ Amazon Bedrock 上的基础模型初体验》
✨ 精心设计,旨在引导您深入探索Amazon Bedrock的模型选择与调用、模型自动化评估以及安全围栏(Guardrail)等重要功能。无需管理基础设施,利用亚马逊技术与生态,快速集成与部署生成式AI模型能力。
⏩️[点击进入实验](https://link.juejin.cn?target=https%3A%2F%2Fdev.amazoncloud.cn%2Fexperience%2Fcloudlab%3Fid%3D6695e4c5e1432f239fae485f%26visitfrom%3D3P_Juejintail_0415%26sc_medium%3Downed%26sc_campaign%3Dcloudlab%26sc_channel%3D3P_Juejintail_0415 "https://dev.amazoncloud.cn/experience/cloudlab?id=6695e4c5e1432f239fae485f&visitfrom=3P_Juejintail_0415&sc_medium=owned&sc_campaign=cloudlab&sc_channel=3P_Juejintail_0415") 即刻开启 AI 开发之旅
构建无限, 探索启程!