一、GaussDB调优核心逻辑:分布式架构下的性能挑战
GaussDB作为分布式HTAP数据库,性能瓶颈主要源于:
跨节点通信开销:分布式连接(如Gather Motion)与聚合操作导致网络延迟。
数据倾斜问题:分片不均引发热点节点,拖慢整体执行效率。
资源争用:并发场景下的锁竞争与I/O瓶颈(如缓冲区命中率<80%)。
案例:某金融系统跨节点JOIN查询延迟5秒,分析发现80%数据集中在单个分片,通过重分布策略优化后降至0.8秒。
二、执行计划分析:定位性能瓶颈的"诊断报告"
- 关键操作解读与优化方向
- 分布式索引管理策略
全局二级索引(GSI):分片键路由减少跨节点扫描
分区索引剪裁:避免全分区扫描(启用enable_partition_pruning)
css
-- 查看详细执行计划(含实际耗时)
EXPLAIN (ANALYZE, BUFFERS, VERBOSE)
SELECT * FROM orders WHERE date > '2025-01-01';
-- 监控活跃慢查询
SELECT pid, now()-query_start AS duration, query
FROM pg_stat_activity WHERE state != 'idle' ORDER BY duration DESC LIMIT 5; [3,4](@ref)三、索引优化:从精准设计到智能管理
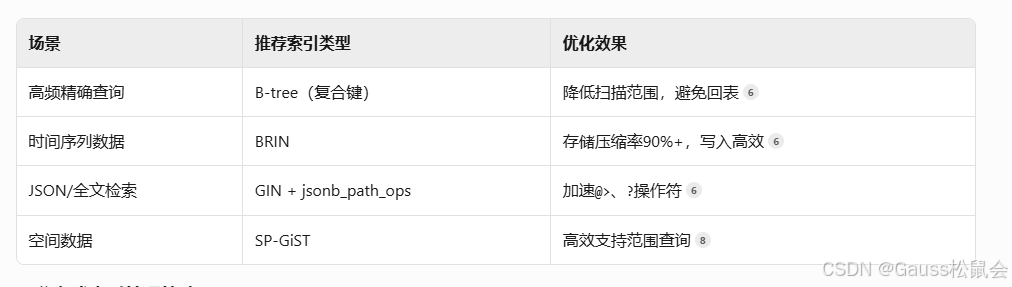
- 索引类型选型矩阵
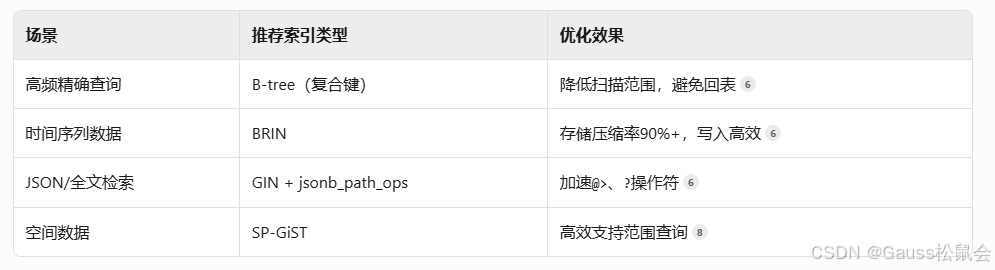
- 分布式索引管理策略
全局二级索引(GSI):分片键路由减少跨节点扫描
分区索引剪裁:避免全分区扫描(启用enable_partition_pruning)
css
-- 创建分区索引(按时间范围)
CREATE INDEX idx_sales_time ON sales(sale_date) PARTITION BY RANGE(sale_date); [7]- 索引生命周期自动化
css
-- 识别低效索引(30天未使用)
SELECT indexname FROM pg_stat_user_indexes WHERE idx_scan = 0; [6]
-- 在线重建碎片化索引(阈值>30%)
REINDEX INDEX CONCURRENTLY idx_orders_date; [6,8]四、参数调优:资源分配的"黄金公式"
核心参数配置逻辑
shared_buffers = 物理内存 × 25% -- 数据缓存池
work_mem = (总内存 - shared_buffers) / 并发连接数 × 0.8 -- 排序/哈希操作
effective_cache_size = 物理内存 × 75% -- 优化器估算缓存3,4
动态调整示例:
css
ALTER SYSTEM SET work_mem = '256MB'; -- 提升复杂排序性能
ALTER SYSTEM SET max_parallel_workers_per_gather = 8; -- 分布式并行计算[2,5]五、高级优化:AI驱动与架构升级
- AI增强调优
自动索引推荐:基于查询模式学习生成最优索引组合
css
SET enable_auto_index = ON;
SELECT * FROM system.auto_index_suggestions WHERE table_name = 'orders'; [7]智能参数调优:通过gaussdb_advisor生成配置包
- HTAP加速引擎
css
向量化执行:OLAP查询性能提升3倍+
SET enable_vectorized = ON; -- 启用列式计算引擎[1]
物化视图预计算:降低复杂聚合开销
CREATE MATERIALIZED VIEW mv_sales_daily AS
SELECT date, SUM(amount) FROM sales GROUP BY date;
REFRESH MATERIALIZED VIEW mv_sales_daily; [1,2]六、典型场景实战:从秒杀系统到实时数仓
场景1:高并发事务优化
问题:库存更新锁冲突(150次/分钟)
方案:
css
-- 乐观锁控制
UPDATE inventory SET quantity = quantity - 1, version = version + 1
WHERE product_id = 'P100' AND version = current_version; [2]
-- 事务拆分为批次提交
DO $$ DECLARE batch_size INT := 1000; ... END $$; [3,5]场景2:实时分析性能提升
问题:亿级表聚合查询超时
方案:
启用BRIN索引压缩时序数据
分布式聚合下推:SET enable_groupagg_distinct_pushdown = ON;
七、调优效果验证与持续监控
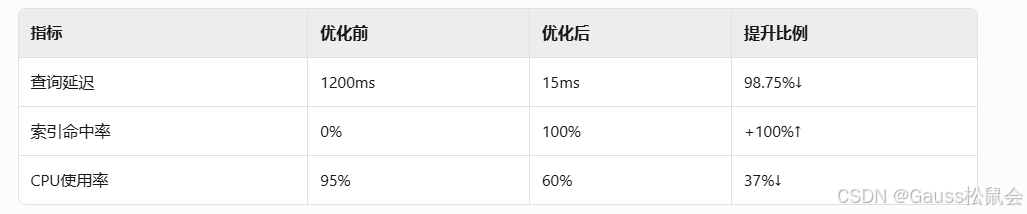
自动化监控体系:
css
-- 创建性能监控视图
CREATE VIEW perf_monitor AS SELECT pid, duration, state, query FROM pg_stat_activity;
-- 定期生成AWR报告
SELECT * FROM DBMS_SWRF_INTERNAL.awr_diff(1000, 2000); [3,4]结语:调优的本质是平衡的艺术
GaussDB的SQL优化需在数据分布合理性、资源分配精准性、架构适配度三者间动态平衡:
分布式优先:通过分片策略与本地化计算减少网络开销;
AI赋能:结合自动索引推荐与参数调优降低人工成本;
持续迭代:基于监控基线定期执行VACUUM ANALYZE与执行计划审查。