一句话定义:
sparkMeasure 是一个轻量级的 Spark 插件/工具,用于收集 Spark 作业的执行指标,并以编程或命令行方式输出分析报告。 项目地址:sparkMeasure。
我的使用场景:
问题痛点:在搭建数仓过后,spark离线任务多,数据量大,依赖关系复杂。导致监控数据质量困难。
思路方案:使用spark-measure获取每次spark离线作业执行时读写的数据量大小,存储下来,随后每天对每个任务的每次执行的读写数据量进行自动分析,如果数据量出现较大波动即认为存在异常。推送告警。
项目文档推荐使用方案:
不在赘述,因为是通过sparkListener来实现的,所以和正常SparkListener使用流程一样,配置sparkConf


我的项目是spark2.4.5+Scala 2.11+华为云obs,在按照这个使用方式遇到的问题是,在把监测结果数据json字符串写到对象存储时,项目源码中使用的jackson版本和我项目中的冲突了,尝试解决几次后,确实无法兼容。遂产生了以下我的使用方案。(当然,修改源码后,使用方式还是上述配置)
我的使用方案:
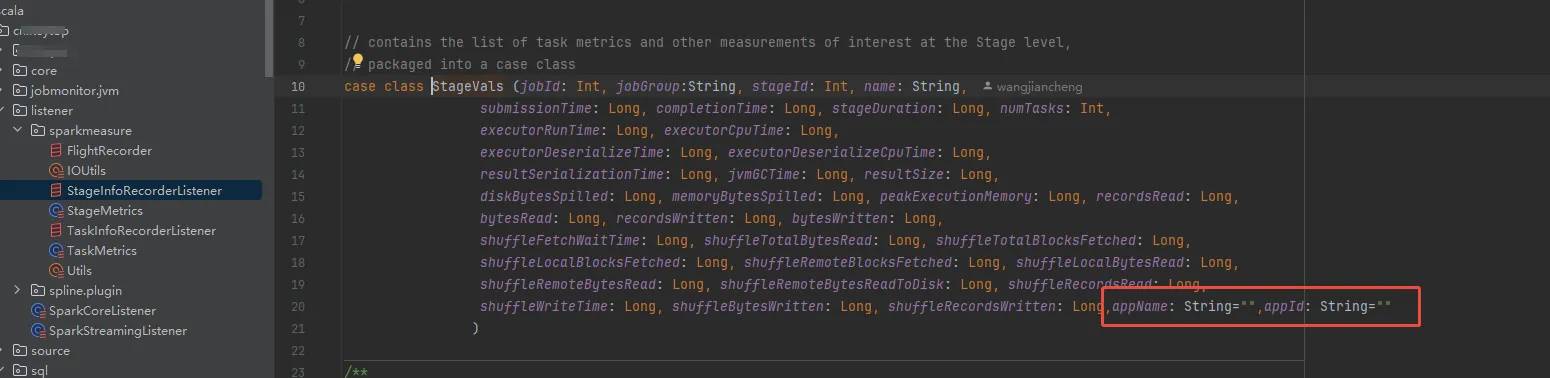
大概思路是:将项目源码copy一份到我的项目中,去除不需要的代码,一是更改json工具包。二是json字符串拆开存储而不是json数组字符串存储,修改为json逐行存储。三是结果信息中将appName和appId带上
项目中原json工具,Jackson
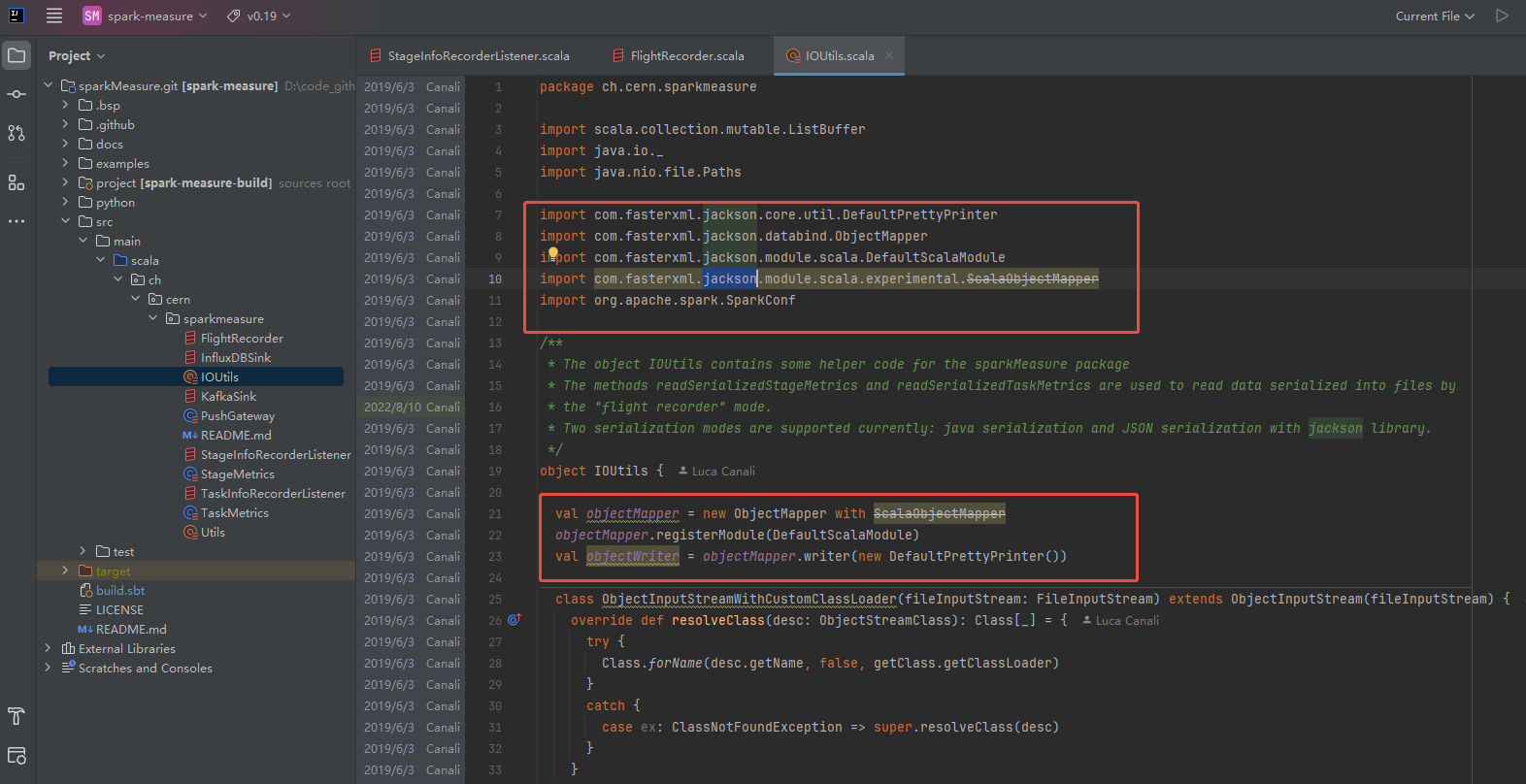
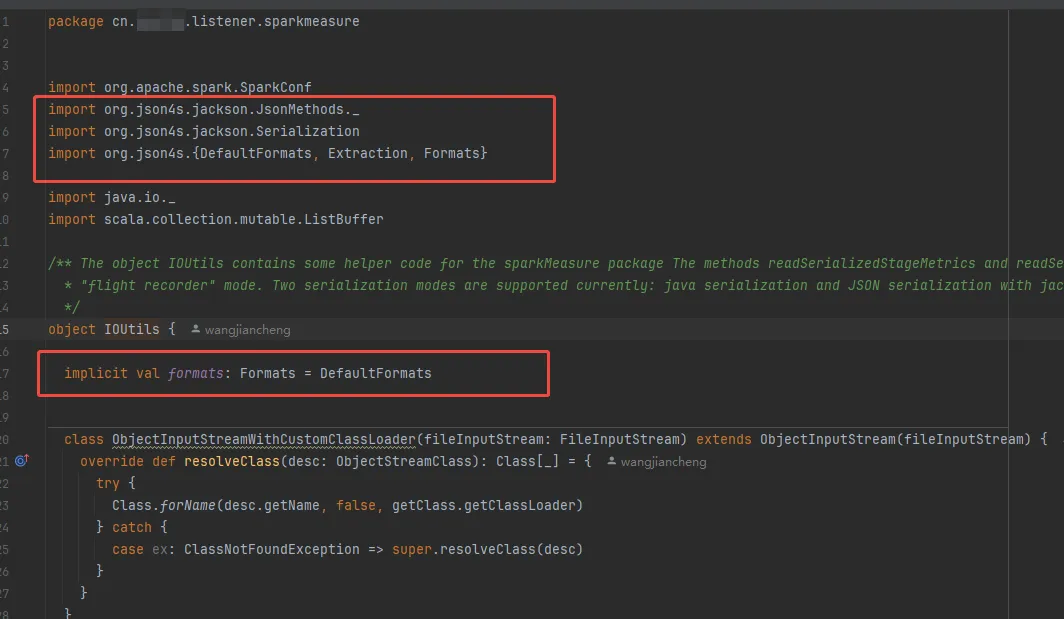
修改后使用json4s
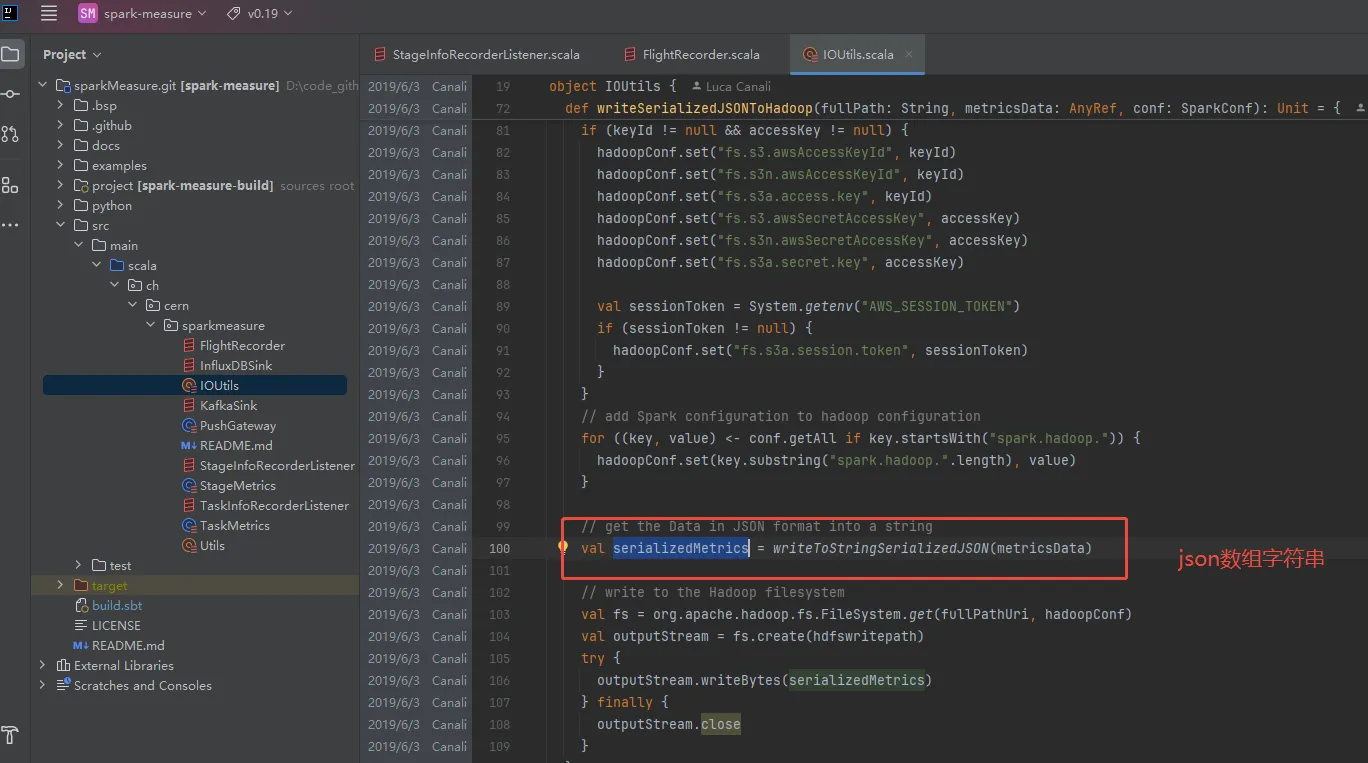
还有就是,我的方案是将监测结果json字符串存储在对象存储上的按天分区目录下的json文件中,然后使用hive外表的方式。但是项目源码中是一个json数组字符串,这样子的话hive无法解析数据。修改源码让其逐行存储
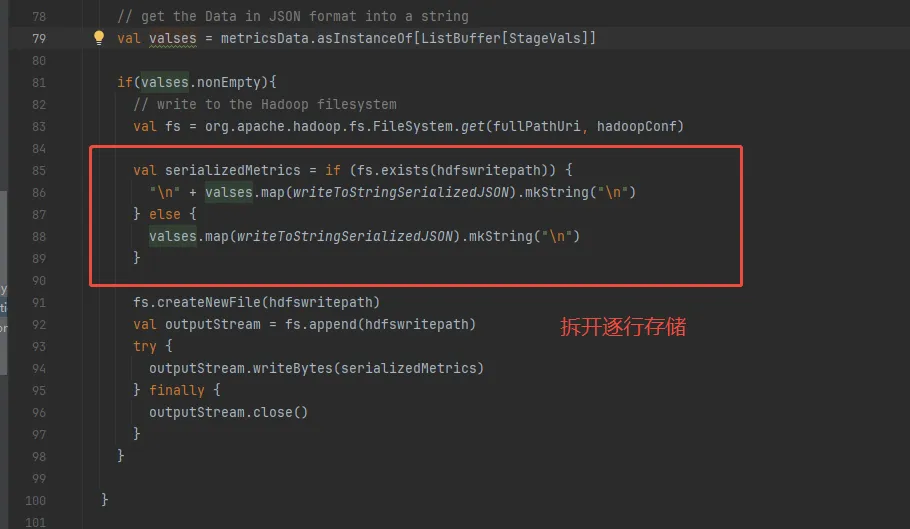
结果信息中将appName和appId带上
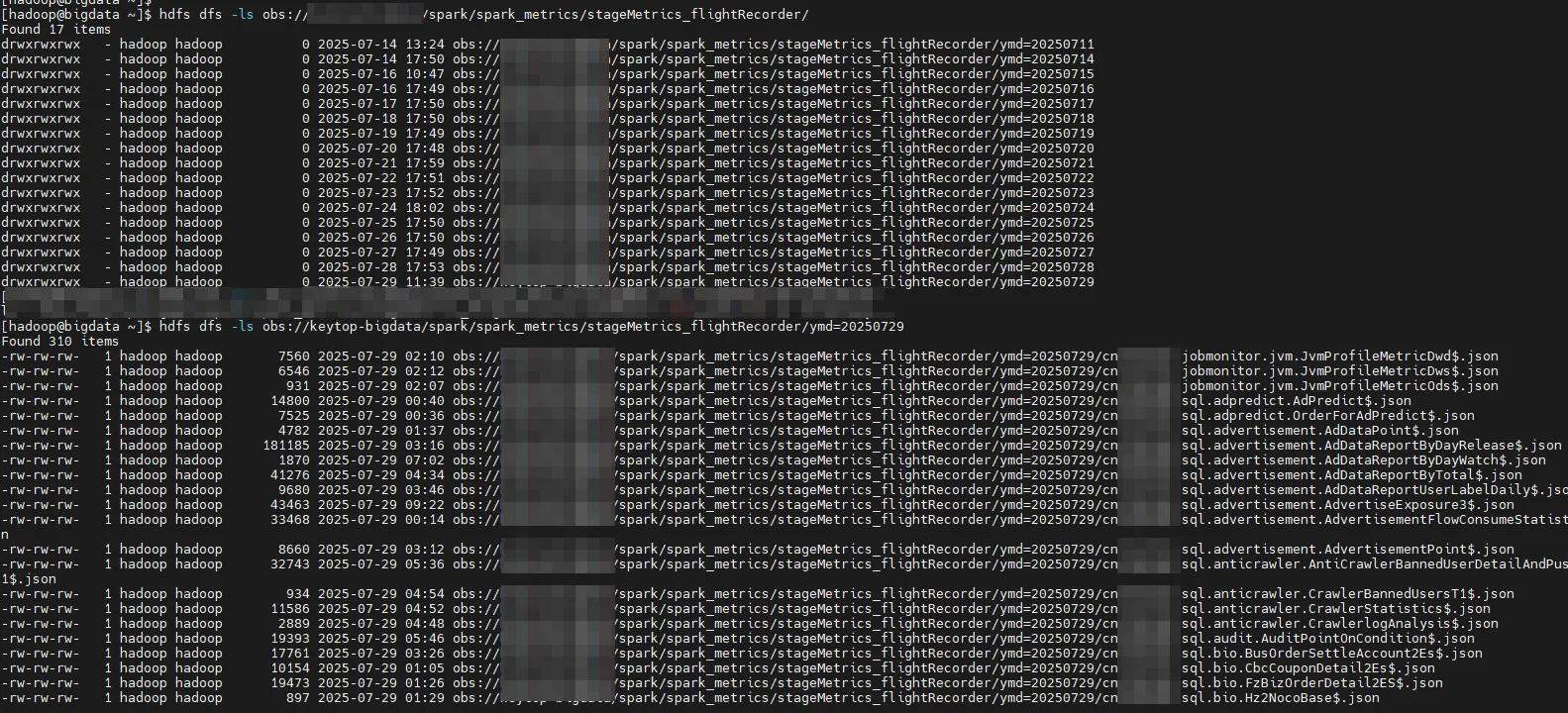
最后数据存储在对象存储上:
hive表建表语句
sql
CREATE EXTERNAL TABLE IF NOT EXISTS ods.ods_spark_stage_metrics (
-- Job 指标
jobId BIGINT COMMENT 'Spark 作业ID',
jobGroup STRING COMMENT 'Spark 作业组',
-- Stage 标识
stageId BIGINT COMMENT 'Spark Stage ID',
name STRING COMMENT 'Stage 名称',
-- 时间指标 (毫秒级时间戳)
submissionTime BIGINT COMMENT 'Stage 提交时间 (毫秒)',
completionTime BIGINT COMMENT 'Stage 完成时间 (毫秒)',
stageDuration BIGINT COMMENT 'Stage 持续时间 (毫秒)',
-- 执行器性能指标
numTasks BIGINT COMMENT 'Stage 中任务数量',
executorRunTime BIGINT COMMENT '执行器总运行时间 (毫秒)',
executorCpuTime BIGINT COMMENT '执行器总 CPU 时间 (毫秒)',
executorDeserializeTime BIGINT COMMENT '执行器总反序列化时间 (毫秒)',
executorDeserializeCpuTime BIGINT COMMENT '执行器总反序列化 CPU 时间 (毫秒)',
resultSerializationTime BIGINT COMMENT '结果总序列化时间 (毫秒)',
jvmGCTime BIGINT COMMENT 'JVM GC 总时间 (毫秒)',
-- 内存和磁盘指标
resultSize BIGINT COMMENT '结果大小 (字节)',
diskBytesSpilled BIGINT COMMENT '溢写到磁盘的字节数',
memoryBytesSpilled BIGINT COMMENT '溢写到内存的字节数',
peakExecutionMemory BIGINT COMMENT '峰值执行内存 (字节)',
-- 输入/输出指标 (您用例的关键)
recordsRead BIGINT COMMENT '任务在 Stage 中读取的总记录数',
bytesRead BIGINT COMMENT '任务在 Stage 中读取的总字节数',
recordsWritten BIGINT COMMENT '任务在 Stage 中写入的总记录数',
bytesWritten BIGINT COMMENT '任务在 Stage 中写入的总字节数',
-- Shuffle 指标 (如果适用)
shuffleFetchWaitTime BIGINT COMMENT '任务等待 Shuffle Fetch 的总时间 (毫秒)',
shuffleTotalBytesRead BIGINT COMMENT 'Shuffle 中读取的总字节数',
shuffleTotalBlocksFetched BIGINT COMMENT 'Shuffle 中获取的总块数',
shuffleLocalBlocksFetched BIGINT COMMENT 'Shuffle 中获取的本地块数',
shuffleRemoteBlocksFetched BIGINT COMMENT 'Shuffle 中获取的远程块数',
shuffleLocalBytesRead BIGINT COMMENT 'Shuffle 中读取的本地字节数',
shuffleRemoteBytesRead BIGINT COMMENT 'Shuffle 中读取的远程字节数',
shuffleRemoteBytesReadToDisk BIGINT COMMENT 'Shuffle 中读取到磁盘的远程字节数',
shuffleRecordsRead BIGINT COMMENT 'Shuffle 中读取的总记录数',
shuffleWriteTime BIGINT COMMENT '任务写入 Shuffle 数据的总时间 (毫秒)',
shuffleBytesWritten BIGINT COMMENT 'Shuffle 中写入的总字节数',
shuffleRecordsWritten BIGINT COMMENT 'Shuffle 中写入的总记录数',
--
appName STRING COMMENT '任务名称',
appId STRING COMMENT '任务的spark appid'
)
PARTITIONED BY (
ymd STRING COMMENT '日期分区,格式为 YYYYMMDD'
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
STORED AS TEXTFILE
LOCATION 'obs://${youer_bucket_name}/spark/spark_metrics/stageMetrics_flightRecorder/';数据呈现:
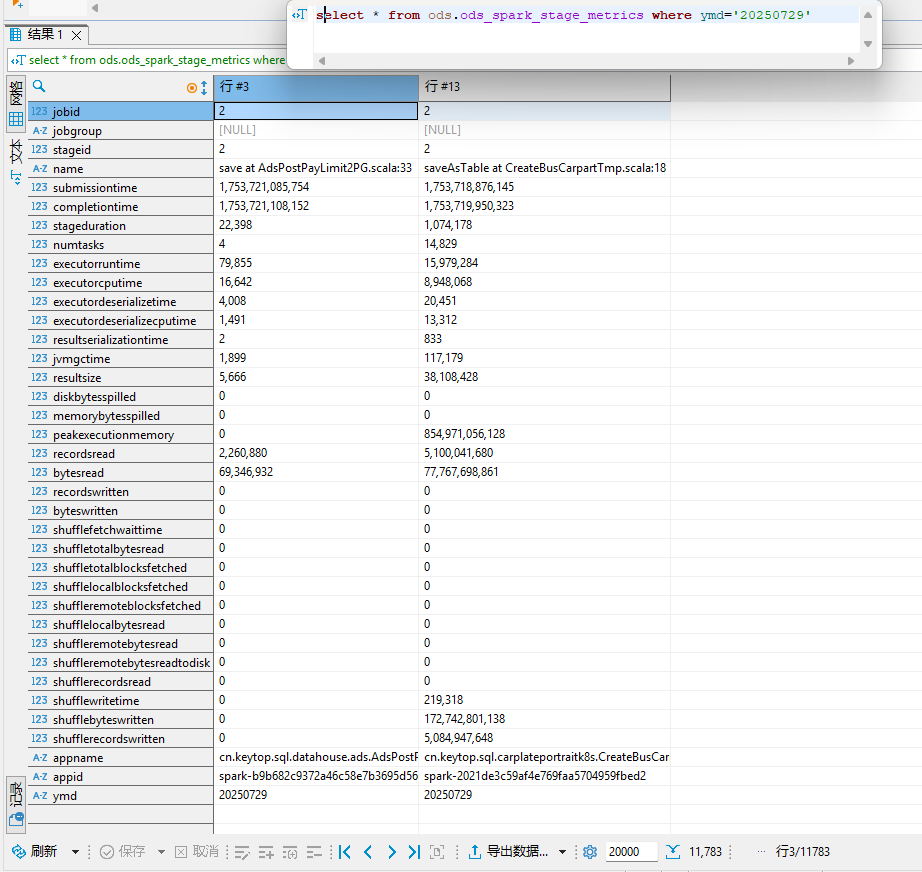
可以看到我们已经拿到了任务的读写数据量信息。但是还有问题就是:每个任务会产生多条数据,很多时候无法通用且明确知道哪条数据或者那几条数据的读写代表着整个spark任务的总读写数据量。