- Selenium的诞生与演变
1.1 【 项目起源 】
在2004年,Jason Huggins在ThoughtWorks公司发起了Selenium项目,并利用JavaScript创建了验证浏览器页面行为的工具。这个JavaScript类库不仅成为了Selenium的核心组件,还衍生出了seleniumRC和Selenium IDE。当时,QTP mercury是主流的商业自动化工具,而Selenium作为开源自动化工具,通过其命名展现了与化学元素硒的联系,象征着其在自动化领域的独特地位与价值。
随着Selenium 1.0的发布,这一工具开始在自动化测试领域崭露头角,为开发者们提供了全新的测试体验。
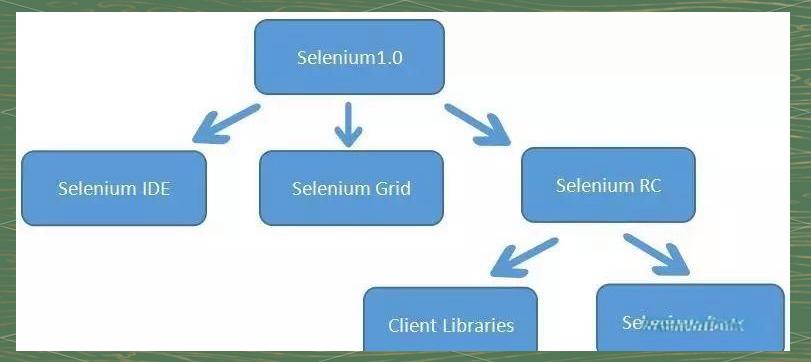
1.2 【 Selenium 1.0的三大组件 】
Selenium 1.0的诞生,标志着这一自动化测试工具在功能上的完善与成熟。它融合了Selenium IDE、Selenium Grid和Selenium RC三大核心组件,为开发者们提供了更加强大且灵活的测试解决方案。其中,Selenium IDE 是 Firefox 浏览器的一个插件,具备简单的浏览器操作录制与回放功能。Selenium Grid 可以充分利用现有计算机基础设施来加速 Web-App 的功能测试,通过 Grid,测试人员可以轻松地在多台机器和不同环境中并行执行测试用例。Selenium RC(Remote Control)是Selenium工具套件中的核心组件,支持使用多种编程语言编写自动化测试脚本,并通过Selenium RC服务器作为代理来访问和测试Web应用。
- WebDriver的创新与合并
2.1 【 WebDriver的开创 】
在2006年,Google的Simon Stewart发起了WebDriver,旨在改善Selenium RC的局限性。通过直接操控浏览器,WebDriver实现了更高级的测试,并克服了JavaScript安全模型的限制。它利用原生浏览器支持或浏览器扩展来直接操控浏览器,与浏览器深度集成,还结合了操作系统级的调用以模拟用户输入,提供了更丰富的测试功能。

2.2 【 与Selenium的合并 】
尽管Selenium与WebDriver最初是两个独立的项目,但它们的创建者Simon Stewart在2009年8月的一份邮件中阐述了项目合并的决策。Selenium和WebDriver在2009年合并以取得最佳框架,结合了Selenium广泛的浏览器支持和WebDriver的先进API。
2.3 【 Selenium 2.0的形成 】
随着合并,Selenium 2.0应运而生,简而言之,Selenium 2.0就是Selenium 1.0与WebDriver的完美结合。在Selenium 2.0中,WebDriver成为了主推的技术,可以被视为Selenium RC的继承与升级。尽管Selenium为了保持兼容性,并未在Selenium 2.0中完全摒弃Selenium RC,但掌握WebDriver无疑是学习Selenium 2.0的核心。
- Selenium 3.0的发布
3.1 【 Selenium3.0的特性更新 】
直到2016年7月,Selenium 3.0终于悄然亮相 ,首个beta版在众人惊喜中发布。相较于前代,Selenium 3.0带来了诸多显著的更新与改进:首先是RC(Remote Control)组件的彻底移除,标志着Selenium更为简洁和高效的架构实现。Selenium3.0仅兼容Java8及更高版本,Firefox浏览器驱动已独立出来,不再与Selenium2中的版本一致。MAC OS系统已集成了Safari的浏览器驱动,其默认路径位于/usr/bin/safaridriver目录下,而Selenium 3.0仅支持IE 9.0及更高版本。