文章目录
- 项目概述
- 踩坑记录与解决方案
-
- [坑 1:手动能看到内容,代码爬取全为空 (动态渲染问题)](#坑 1:手动能看到内容,代码爬取全为空 (动态渲染问题))
- [坑 2:Selenium 启动报错 DevToolsActivePort file doesn't exist](#坑 2:Selenium 启动报错 DevToolsActivePort file doesn't exist)
- [坑 3:部分页面只有简介,结构不统一](#坑 3:部分页面只有简介,结构不统一)
- [坑 4:Selenium 访问变成"data:"页面,无内容 (反爬虫初级)](#坑 4:Selenium 访问变成“data:”页面,无内容 (反爬虫初级))
- [坑 5:Requests 拦截与 Client Challenge (反爬虫高级)](#坑 5:Requests 拦截与 Client Challenge (反爬虫高级))
- 最终实现逻辑
- 经验总结
- 源码分享
项目概述
-
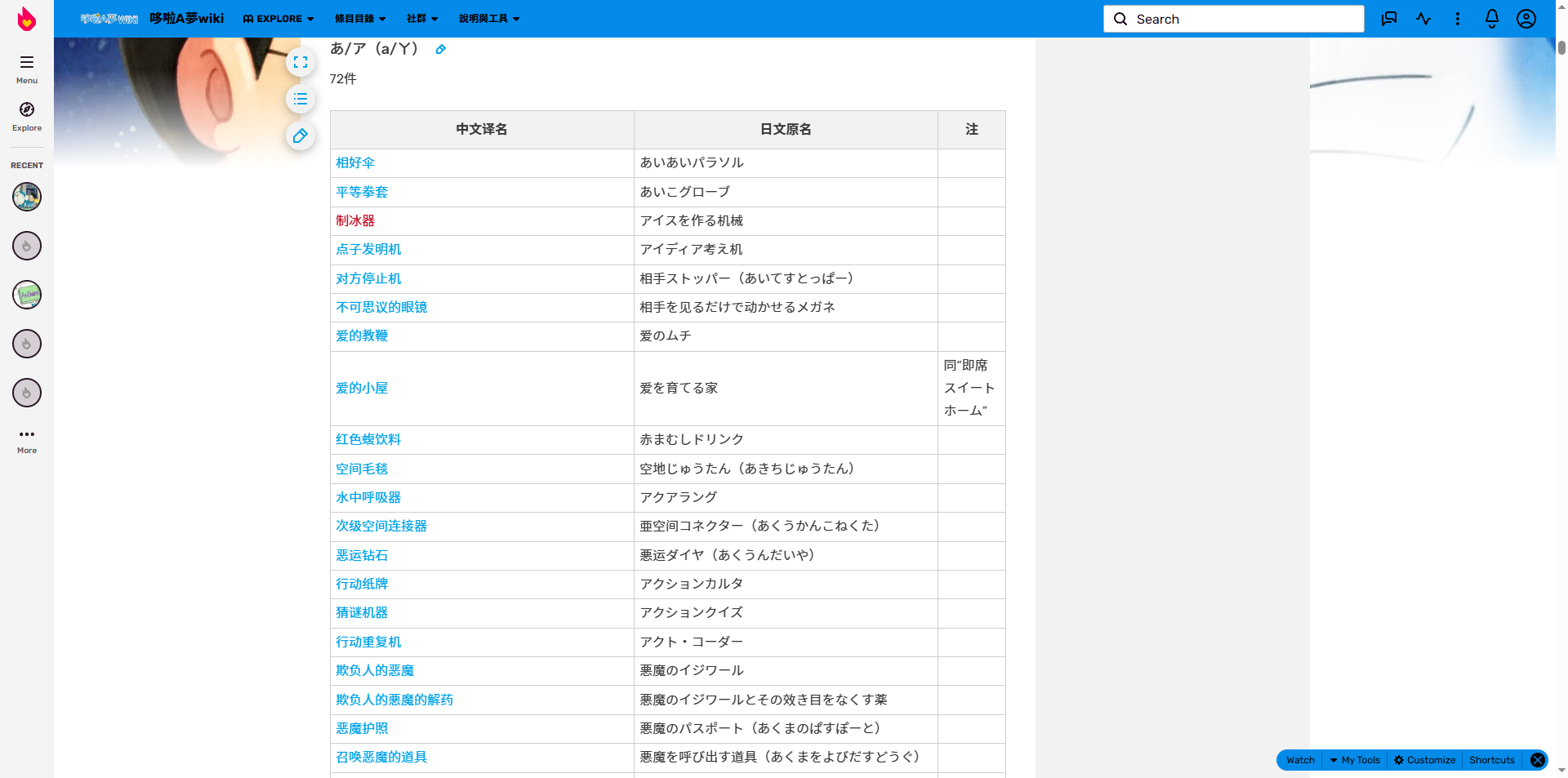
从 Doraemon Fandom Wiki 网站中的
哆啦A梦漫画道具列表网页中(哆啦A梦漫画道具列表)批量抓取哆啦A梦漫画道具的"道具介绍"和"故事内容",并保存为本地 TXT 文件。
-
前置工作:
- 哆啦A梦漫画道具列表网站的
查看网页源代码中可以看到所有的道具名称与链接,通过 Python 代码自动提取这部分信息并写入 txt ,便于后续遍历:

- 哆啦A梦漫画道具列表网站的
- 最终技术栈 :
requests:用于轻量级静态请求。selenium:用于处理动态渲染(已被替换,详见坑4)。undetected-chromedriver:最终核心驱动,用于绕过反爬虫检测。beautifulsoup4:用于解析 HTML。opencc:用于繁简体转换。
踩坑记录与解决方案
坑 1:手动能看到内容,代码爬取全为空 (动态渲染问题)
现象 :
使用 requests 获取网页源码时,状态码 200,但提取不到"道具介绍"等关键信息。用户通过浏览器右键"查看源代码"能看到内容。
原因分析 :
该网站属于动态加载网站。关键内容不是写在 HTML 源码里的,而是通过 JavaScript 动态注入的。requests 只能获取初始 HTML,无法执行 JS。
解决方案 :
引入 selenium 库,启动真实的 Chrome 浏览器来执行 JS,渲染出最终页面后再抓取。
坑 2:Selenium 启动报错 DevToolsActivePort file doesn't exist
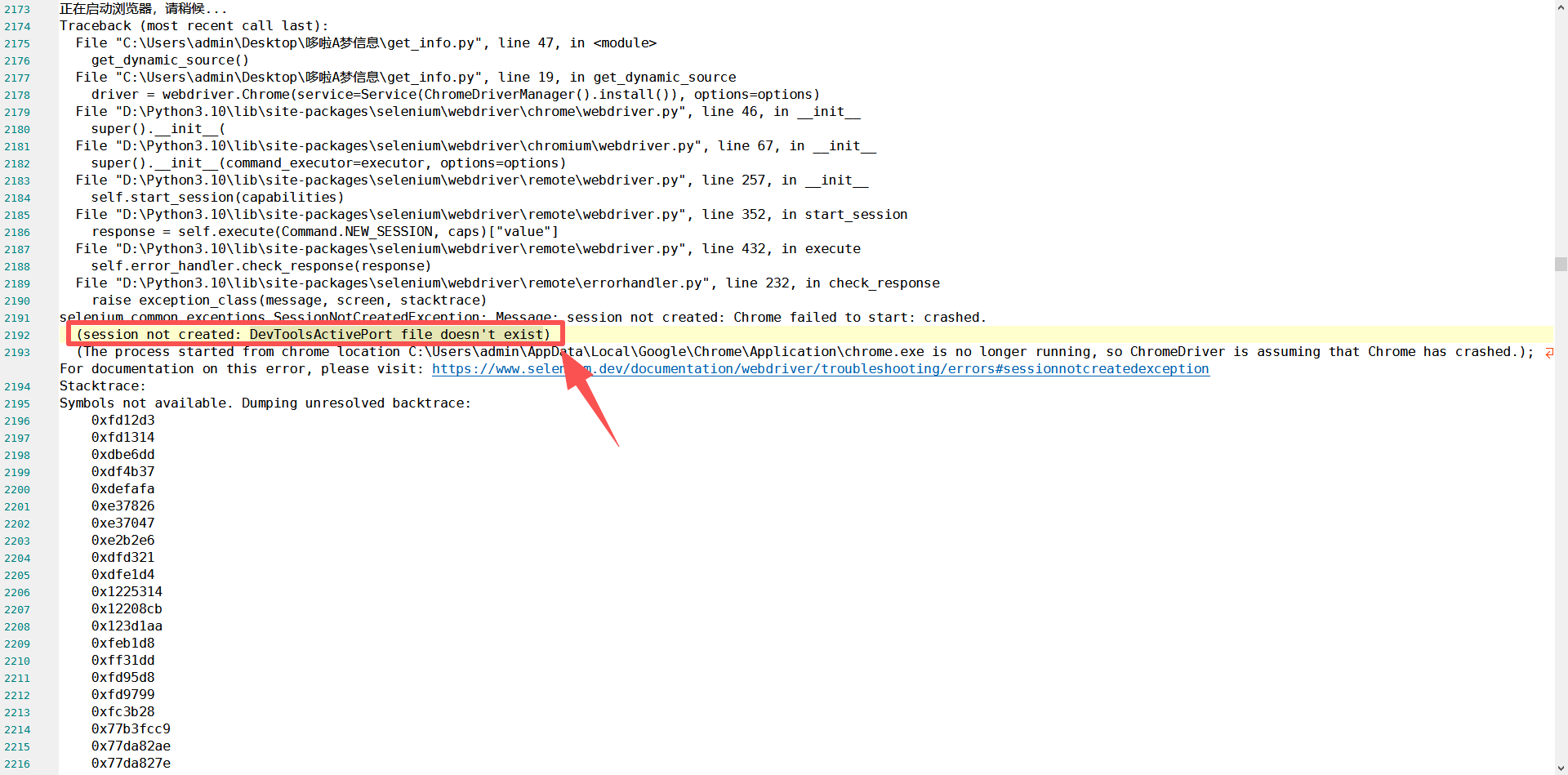
现象 :
在 Windows 环境下运行 Selenium 报错,Chrome 浏览器闪退,无法启动。
原因分析 :
这是 Windows 上 Selenium 的一种典型崩溃,通常由于沙箱、GPU 加速或端口冲突导致。
解决方案 :
在 ChromeOptions 中添加一系列稳定参数:
python
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--disable-gpu')
options.add_argument('--remote-debugging-port=9222')若仍报错,则可在任务管理器中强制关闭所有在运行的 Chrome 浏览器程序。
坑 3:部分页面只有简介,结构不统一
现象 :
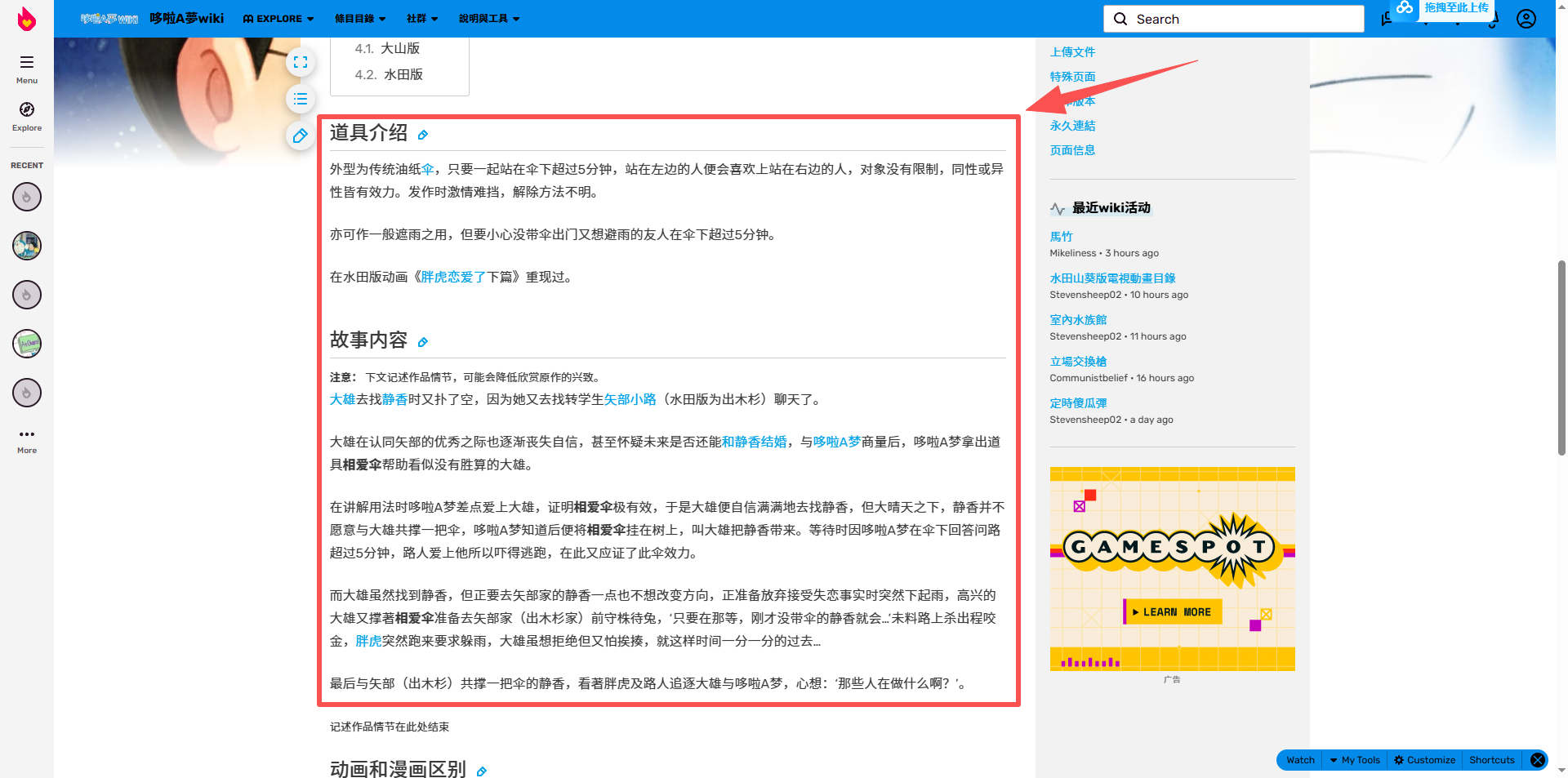
部分道具页面(如"相好伞")有标准的"道具介绍"和"故事内容"章节,但也有部分页面(如"爱的小屋")只有网页 Meta 描述,没有正文结构。
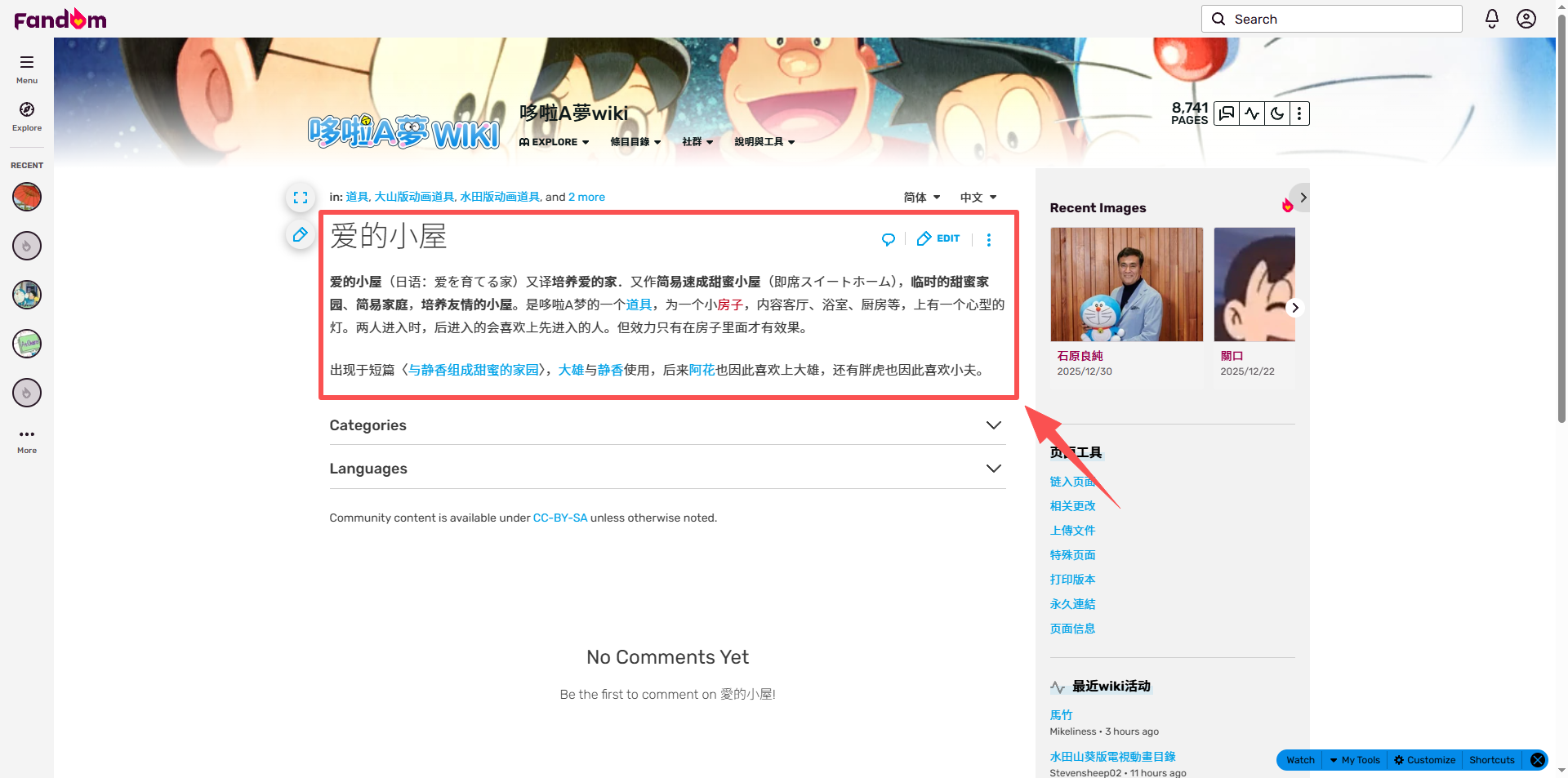
原因分析 :
Wiki 页面由用户编辑,模板不统一。
解决方案:
- 多关键字匹配:同时匹配简体("道具介绍")和繁体("道具介紹")。
- 兜底逻辑 :如果没有找到正文,尝试提取源码中的
<meta name="description" content="...">内容作为备用。
坑 4:Selenium 访问变成"data:"页面,无内容 (反爬虫初级)
现象 :
通过代码模拟浏览器访问特定页面时,地址栏 URL 瞬间变成 data:,页面全白,无法提取任何内容,但手动打开正常。
原因分析 :
网站具有反自动化检测机制(可能是 Cloudflare 的初级拦截)。检测到 navigator.webdriver 为 true 后,通过 JS 劫持页面,重定向到无效地址。
解决方案 :
采用混合策略:
- Strategy A (Requests优先) :对于"只有简介"的简单页面,尝试直接用
requests获取静态源码。静态请求不触发 JS 检测,速度快且稳定。 - Strategy B (Selenium兜底) :只有在
requests失败或需要复杂正文时,才启动Selenium。
坑 5:Requests 拦截与 Client Challenge (反爬虫高级)
现象 :
即使使用了混合策略,Selenium 依然无法获取内容。下载的源码显示标题为 <title>Client Challenge</title>,正文全是 JS 验证代码。
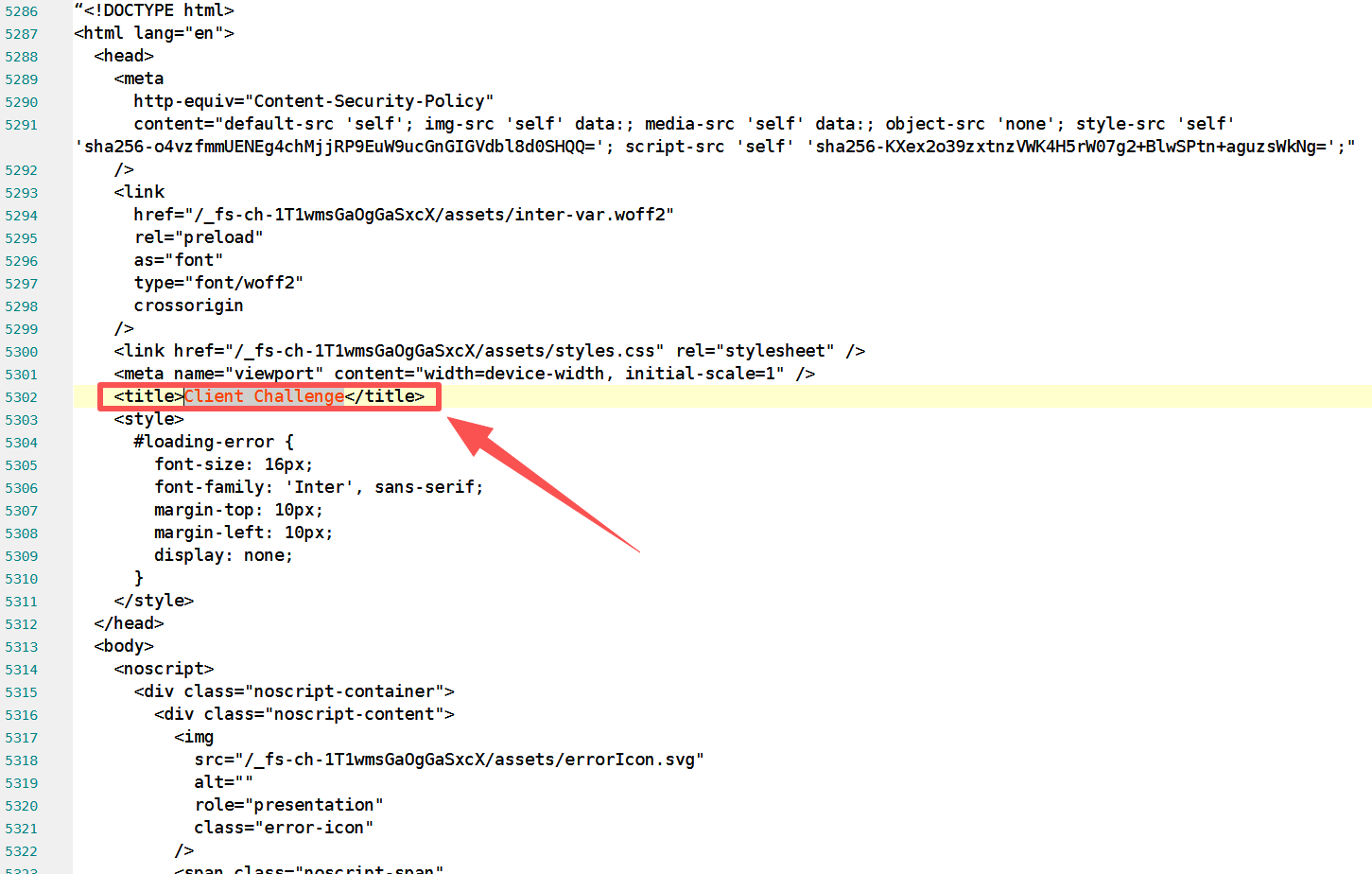
原因分析 :
网站启用了 Cloudflare 高级保护。它会在返回页面时包含一段 JS 挑战代码,浏览器执行通过后才能加载真内容。Python 的 requests 和普通 Selenium 直接被拦在门外。
解决方案 :
放弃 requests 和普通 selenium,引入 undetected-chromedriver 库。
该库通过修改 Chrome 底层驱动文件,自动隐藏自动化特征,能够通过 Cloudflare 5秒盾等验证。
最终实现逻辑
为了应对上述所有坑,最终代码采用了以下稳健逻辑:
- 初始化 :使用
undetected-chromedriver(配置好 User-Agent 和最大化窗口),并初始化繁简转换器。 - 循环处理 :
- Step 1 (轻量请求) :尝试用
requests获取页面 -> 解析 HTML -> 提取 Meta Description。 - Step 2 (成功则写入) :如果 Step 1 拿到了内容,直接转简体、保存文件、删除列表行。不启动浏览器,极快且安全。
- Step 3 (失败则重器) :如果 Step 1 失败(遇到 Cloudflare Challenge 或只有正文),启动
undetected-chromedriver。 - Step 4 (浏览器处理):等待 10 秒(过 Cloudflare 验证) -> 提取"道具介绍"和"故事内容" -> 若无正文则再次尝试提取 Meta。
- Step 5 (收尾):成功则保存并删除行,失败则保留行。
- Step 6 (延时):避免请求过快被封。
- Step 1 (轻量请求) :尝试用
经验总结
- 不要迷信一种工具:不要上来就用 Selenium,也不要死磕 Requests。混合策略往往能平衡速度和成功率。
- 工具库要与时俱进 :普通
selenium在反爬虫面前已显吃力,undetected-chromedriver是目前绕过 Cloudflare 的首选。
源码分享
python
import os
import time
import re
import requests
import opencc
import undetected_chromedriver as uc
from bs4 import BeautifulSoup
from selenium.webdriver.chrome.options import Options
# --- 配置部分 ---
INPUT_FILE = "哆啦A梦漫画道具.txt"
OUTPUT_DIR = "哆啦A梦漫画道具"
HEADLESS_MODE = True # 默认为 False (可见模式),测试通过。如需后台运行改为 True
# 伪装请求头
REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
def sanitize_filename(name):
return re.sub(r'[\\/*?:"<>|]', "", name).strip()
def get_meta_description_via_bs4(html_text):
"""使用 BeautifulSoup 解析 requests 返回的 HTML 文本"""
soup = BeautifulSoup(html_text, 'html.parser')
tag = soup.find('meta', attrs={'name': lambda x: x and x.lower() == 'description'})
if tag and tag.get('content'):
return tag.get('content')
return None
def get_section_content(soup, keyword_simp, keyword_trad):
"""提取 h2 章节"""
for h2 in soup.find_all('h2'):
headline_span = h2.find('span', class_='mw-headline')
if headline_span:
headline_text = headline_span.get_text(strip=True)
if keyword_simp in headline_text or keyword_trad in headline_text:
content_parts = []
for sibling in h2.find_next_siblings():
if sibling.name == 'h2':
break
if sibling.name in ['p', 'div']:
text = sibling.get_text(strip=True)
if text and len(text) > 2:
content_parts.append(text)
return "\n\n".join(content_parts) if content_parts else None
return None
def main():
if not os.path.exists(INPUT_FILE):
print(f"错误:未找到文件 {INPUT_FILE}")
return
# 1. 检查并创建输出文件夹 (如果不存在)
if not os.path.exists(OUTPUT_DIR):
os.makedirs(OUTPUT_DIR)
print(f"已创建输出文件夹: {OUTPUT_DIR}")
else:
print(f"输出文件夹已存在: {OUTPUT_DIR}")
print("正在初始化繁简转换器...")
try:
converter = opencc.OpenCC('t2s')
except Exception as e:
print(f"OpenCC 初始化失败: {e}")
return
# --- 初始化 Undetected ChromeDriver ---
print("正在初始化反爬虫浏览器...")
options = Options()
options.add_argument('--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36')
options.add_argument('--start-maximized')
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
if HEADLESS_MODE:
options.add_argument('--headless')
driver = None
try:
driver = uc.Chrome(options=options)
driver.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
print("浏览器启动成功。")
with open(INPUT_FILE, 'r', encoding='utf-8') as f:
lines = f.readlines()
remaining_lines = []
for i, line in enumerate(lines):
line = line.strip()
if not line:
continue
if ':' in line:
parts = line.split(':', 1)
elif ':' in line:
parts = line.split(':', 1)
else:
remaining_lines.append(line)
continue
prop_name = parts[0].strip()
prop_url = parts[1].strip()
# --- 新增逻辑:检查文件是否已存在 ---
safe_name = sanitize_filename(prop_name)
output_file = os.path.join(OUTPUT_DIR, f"{safe_name}.txt")
if os.path.exists(output_file):
print(f"[{i+1}/{len(lines)}] [跳过] 文件已存在: {safe_name}.txt")
# 文件已存在,跳过处理,并且不加入 remaining_lines (即删除源文件中的该行)
continue
# -----------------------------------
print(f"\n正在处理 [{prop_name}] ({i+1}/{len(lines)})...")
# --- 策略 A: Requests (快速通道) ---
meta_via_requests = None
print(" -> [尝试1] 正在使用 Requests 静态抓取...")
try:
response = requests.get(prop_url, headers=REQUEST_HEADERS, timeout=10)
if response.status_code == 200:
meta_via_requests = get_meta_description_via_bs4(response.text)
except:
pass
final_text = ""
has_content = False
use_selenium = False
if meta_via_requests:
print(" -> [成功] Requests 抓取成功,跳过浏览器。")
final_text = f"【道具介绍】\n{meta_via_requests}\n\n(注:内容来源为网页 Meta 描述)"
has_content = True
else:
# --- 策略 B: Undetected Chrome (强力通道) ---
print(" -> [尝试2] Requests 无效,正在使用反爬虫浏览器...")
use_selenium = True
try:
driver.get(prop_url)
time.sleep(10)
if "challenge" in driver.current_url:
print(" -> [警告] 遇到 Cloudflare 挑战,再等待 10 秒...")
time.sleep(10)
soup = BeautifulSoup(driver.page_source, 'html.parser')
intro = get_section_content(soup, "道具介绍", "道具介紹")
story = get_section_content(soup, "故事内容", "故事內容")
if intro or story:
if intro:
final_text += f"【道具介绍】\n{intro}\n\n"
else:
final_text += "【道具介绍】\n(未找到该章节)\n\n"
if story:
final_text += f"【故事内容】\n{story}"
else:
final_text += "【故事内容】\n(未找到该章节)"
has_content = True
else:
desc = get_meta_description_via_bs4(driver.page_source)
if desc:
final_text = f"【道具介绍】\n{desc}\n\n(注:内容来源为网页 Meta 描述)"
has_content = True
else:
print(" -> [失败] 浏览器页面也无法获取内容。")
except Exception as e:
print(f" -> [错误] 浏览器访问出错: {e}")
remaining_lines.append(line)
continue
# 保存文件
if has_content:
final_text_simplified = converter.convert(final_text)
with open(output_file, 'w', encoding='utf-8') as f_out:
f_out.write(final_text_simplified)
print(f"成功!(已转简体) 保存至: {output_file}")
# 成功则不加入 remaining_lines
else:
remaining_lines.append(line)
if use_selenium:
time.sleep(2)
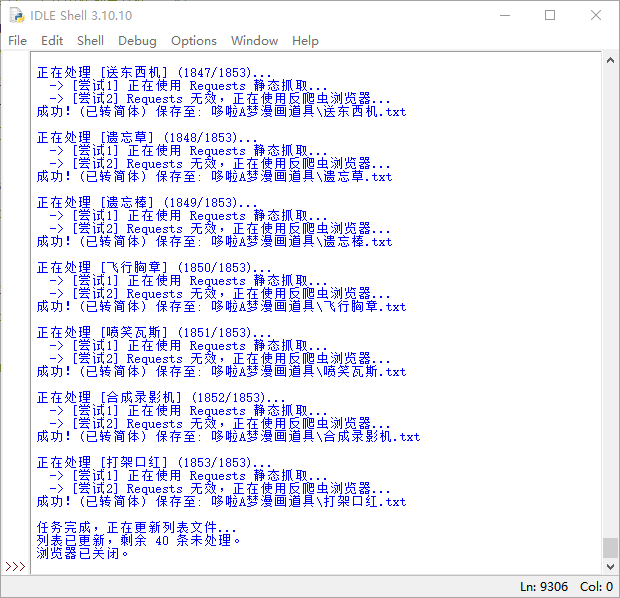
print("\n任务完成,正在更新列表文件...")
with open(INPUT_FILE, 'w', encoding='utf-8') as f:
f.write('\n'.join(remaining_lines))
if remaining_lines:
f.write('\n')
print(f"列表已更新,剩余 {len(remaining_lines)} 条未处理。")
except Exception as e:
print(f"程序发生严重错误: {e}")
finally:
if driver:
driver.quit()
print("浏览器已关闭。")
if __name__ == '__main__':
main()