目录
- 一、概述
-
- [1.1 背景介绍:从"训练"到"部署"](#1.1 背景介绍:从“训练”到“部署”)
- [1.2 学习目标](#1.2 学习目标)
- 二、在C++中集成ONNX模型
-
- [2.1 准备模型文件](#2.1 准备模型文件)
- [2.2 修改`Backend`以加载和运行模型](#2.2 修改
Backend以加载和运行模型)
- 三、关键一步:输出结果的后处理
- 四、运行与验证
- 五、总结与展望
一、概述
1.1 背景介绍:从"训练"到"部署"
在上一篇文章中,我们成功地跨入了Python的世界,完整地经历了一次AI模型从数据标注到训练、再到导出的全过程。我们最终的产出是一个名为best.onnx的模型文件------这是AI算法工程师工作的结晶。
然而,这个模型本身还只是一个静态的权重文件,无法独立工作。本篇文章的核心任务,就是完成从"算法研发"到"软件部署"这至关重要的一跃。我们将回归C++的主战场,学习如何使用OpenCV强大的DNN(深度神经网络)模块,在我们的Qt应用程序中加载并运行这个ONNX模型。这个过程,我们称之为模型推理(Inference)。
1.2 学习目标
通过本篇的学习,读者将能够:
- 在C++中加载ONNX模型,并对输入的图像进行预处理,使其符合模型的输入要求。
- 执行模型的前向传播(推理),获取模型的原始输出。
- 掌握关键的后处理技术:解析YOLOv8复杂的输出张量,提取出边界框、置信度和类别信息。
- 将识别出的瑕疵信息,可视化地绘制在QML界面显示的图像上,让AI的结果"看得见"。
二、在C++中集成ONNX模型
2.1 准备模型文件
首先,将上一章生成的best.onnx模型文件,从runs/detect/train/weights目录中,拷贝到项目根目录下,方便程序访问。
2.2 修改Backend以加载和运行模型
我们将为Backend类增加一个YOLOv8的封装,用于处理所有与模型推理相关的逻辑。
1. 编写代码 (backend.h)
cpp
// backend.h
#ifndef BACKEND_H
#define BACKEND_H
#include <QObject>
#include <QImage>
#include <opencv2/dnn.hpp> // 1. 包含OpenCV DNN模块头文件
class ImageProvider;
class Backend : public QObject
{
Q_OBJECT
public:
explicit Backend(ImageProvider *provider, QObject *parent = nullptr);
Q_INVOKABLE void startScan();
signals:
void imageReady(const QString &imageId);
void statusMessageChanged(const QString &message);
private:
// 2. 添加一个私有方法用于AI推理
cv::Mat runInference(const cv::Mat &inputImage);
ImageProvider *m_imageProvider;
cv::dnn::Net m_net; // 3. 添加一个Net对象,用于表示我们的神经网络
std::vector<std::string> m_classNames; // 4. 用于存储类别名称
};
#endif // BACKEND_H2. 编写代码 (backend.cpp)
这是本章的核心。我们将修改构造函数以加载模型,并实现runInference方法。
cpp
// backend.cpp
#include "backend.h"
#include "imageprovider.h"
#include <QDebug>
#include <QDir>
#include <opencv2/imgcodecs.hpp>
// ... (matToQImage辅助函数保持不变)
Backend::Backend(ImageProvider *provider, QObject *parent)
: QObject(parent), m_imageProvider(provider)
{
// --- 1. 加载ONNX模型 ---
QString modelPath = QDir::currentPath() + "/../../best.onnx";
try {
m_net = cv::dnn::readNetFromONNX(modelPath.toStdString());
if (m_net.empty()) {
qWarning() << "Failed to load ONNX model!";
} else {
qDebug() << "ONNX model loaded successfully.";
// 设置计算后端。CPU是默认选项,但可以显式指定
m_net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);
m_net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);
}
} catch (const cv::Exception& e) {
qWarning() << "Error loading model:" << e.what();
}
// --- 2. 加载类别名称 ---
// 这个顺序必须与训练时的.yaml文件严格一致!
m_classNames = {"neck_defect", "thread_defect", "head_defect"};
}
cv::Mat Backend::runInference(const cv::Mat &inputImage)
{
if (m_net.empty()) {
qDebug() << "Network not loaded.";
return inputImage;
}
// --- 3. 图像预处理 ---
// YOLOv8需要一个640x640的方形输入
const int inputWidth = 640;
const int inputHeight = 640;
cv::Mat blob;
// 将图像转换为blob格式:调整尺寸、归一化(像素值/255)、通道重排(BGR->RGB)
cv::dnn::blobFromImage(inputImage, blob, 1./255., cv::Size(inputWidth, inputHeight), cv::Scalar(), true, false);
// --- 4. 执行推理 ---
m_net.setInput(blob);
std::vector<cv::Mat> outputs;
m_net.forward(outputs, m_net.getUnconnectedOutLayersNames());
// outputs[0]是模型的原始输出,我们需要对其进行后处理
// ... 后处理代码将在下一节添加 ...
// 暂时返回原始图像
return inputImage;
}
void Backend::startScan()
{
// ... (加载图像的代码保持不变)
QString imagePath = QDir::currentPath() + "/../../dataset/screw/test/scratch_head/000.png";
cv::Mat sourceMat = cv::imread(imagePath.toStdString());
if (sourceMat.empty()) { /* ... */ return; }
// --- 5. 调用推理函数 ---
cv::Mat resultMat = runInference(sourceMat);
QImage imageQ = matToQImage(resultMat);
if (imageQ.isNull()){ /* ... */ return; }
m_imageProvider->updateImage(imageQ);
emit imageReady("screw_processed");
emit statusMessageChanged("AI推理完成!");
}关键代码分析:
(1) cv::dnn::readNetFromONNX(...) : OpenCV DNN模块中用于从ONNX文件加载模型的函数。加载成功后会返回一个cv::dnn::Net对象。
(2) m_classNames : 我们手动定义了一个std::vector<std::string>来存储类别名称。注意:这里的顺序必须与训练时dataset.yaml文件中的names顺序严格一致 ,因为模型输出的类别ID是基于这个顺序的。
(3) cv::dnn::blobFromImage(...) : 这是一个强大的预处理函数,它能一步到位地完成YOLOv8所需的几项操作:
-
1./255.:归一化因子,将像素值从0-255范围缩放到0-1范围。 -
cv::Size(640, 640):将图像缩放或填充到640x640的尺寸。 -
cv::Scalar(): 减去均值,此处不减。 -
true: 交换R和B通道(BGR -> RGB),因为YOLOv8是在RGB图像上训练的。 -
false: 不裁剪。
(4) m_net.forward(...) : 执行网络的前向传播,即推理。推理结果会存放在outputs这个std::vector<cv::Mat>中。
三、关键一步:输出结果的后处理
YOLOv8的原始输出是一个cv::Mat,其维度通常是1 x (4 + num_classes) x 8400。我们需要编写代码来解析这个复杂的张量,提取出我们真正需要的信息。
【核心概念:解析YOLOv8输出】
对于输出矩阵的每一列(共8400列,代表8400个可能的检测框):
- 前4行是边界框的坐标(中心x, 中心y, 宽, 高)。
- 后面的N行(N是类别数)是该框属于每个类别的置信度分数。
我们的后处理流程是:
- 遍历所有8400个可能的检测框。
- 找到每个框置信度最高的类别。
- 如果这个最高置信度大于一个阈值(例如0.5),则认为这是一个有效的检测。
- 将所有有效的检测框及其信息收集起来。
- 由于同一个物体可能被多个框检测到,最后使用**非极大值抑制(NMS)**来剔除重叠的多余框。
【例8-1】 实现后处理并可视化结果。
1. 编写代码 (backend.cpp)
我们将用完整的后处理逻辑来替换runInference函数中的注释部分。
cpp
// backend.cpp
cv::Mat Backend::runInference(const cv::Mat &inputImage)
{
if (m_net.empty()) { /* ... */ return inputImage; }
cv::Mat blob;
// --- 图像预处理 (代码同上) ---
cv::dnn::blobFromImage(inputImage, blob, 1./255., cv::Size(640, 640), cv::Scalar(), true, false);
m_net.setInput(blob);
std::vector<cv::Mat> outputs;
m_net.forward(outputs, m_net.getUnconnectedOutLayersNames());
cv::Mat output_buffer = outputs[0]; // [1, num_classes + 4, 8400]
output_buffer = output_buffer.reshape(1, {output_buffer.size[1], output_buffer.size[2]}); // [num_classes + 4, 8400]
cv::transpose(output_buffer, output_buffer); // [8400, num_classes + 4]
// --- 1. 后处理 ---
float conf_threshold = 0.5f; // 置信度阈值
float nms_threshold = 0.4f; // NMS阈值
std::vector<int> class_ids;
std::vector<float> confidences;
std::vector<cv::Rect> boxes;
float x_factor = (float)inputImage.cols / 640.f;
float y_factor = (float)inputImage.rows / 640.f;
for (int i = 0; i < output_buffer.rows; i++) {
cv::Mat row = output_buffer.row(i);
cv::Mat scores = row.colRange(4, output_buffer.cols);
double confidence;
cv::Point class_id_point;
cv::minMaxLoc(scores, nullptr, &confidence, nullptr, &class_id_point);
if (confidence > conf_threshold) {
confidences.push_back(confidence);
class_ids.push_back(class_id_point.x);
float cx = row.at<float>(0,0);
float cy = row.at<float>(0,1);
float w = row.at<float>(0,2);
float h = row.at<float>(0,3);
int left = (int)((cx - 0.5 * w) * x_factor);
int top = (int)((cy - 0.5 * h) * y_factor);
int width = (int)(w * x_factor);
int height = (int)(h * y_factor);
boxes.push_back(cv::Rect(left, top, width, height));
}
}
// --- 2. 非极大值抑制 (NMS) ---
std::vector<int> indices;
cv::dnn::NMSBoxes(boxes, confidences, conf_threshold, nms_threshold, indices);
// --- 3. 结果可视化 ---
cv::Mat resultImage = inputImage.clone();
for (int idx : indices) {
cv::Rect box = boxes[idx];
int class_id = class_ids[idx];
// 绘制边界框
cv::rectangle(resultImage, box, cv::Scalar(0, 255, 0), 2);
// 绘制标签
std::string label = cv::format("%s: %.2f", m_classNames[class_id].c_str(), confidences[idx]);
cv::putText(resultImage, label, cv::Point(box.x, box.y - 10), cv::FONT_HERSHEY_SIMPLEX, 0.7, cv::Scalar(0, 255, 0), 2);
}
return resultImage;
}关键代码分析:
(1) 坐标还原 : 模型的输出是基于640x640输入的归一化坐标,我们必须乘以x_factor和y_factor将其还原到原始图像的坐标系。
(2) cv::minMaxLoc(...) : 一个方便的函数,用于在单行/列的Mat中快速找到最大值(置信度)及其位置(类别ID)。
(3) cv::dnn::NMSBoxes(...) : OpenCV DNN模块内置的非极大值抑制函数。它接收原始的框和置信度,返回一个indices向量,其中包含了最终保留下来的框的索引。
(4) cv::rectangle(...) 和 cv::putText(...): OpenCV的绘图函数,用于在最终结果图上画出边界框和带有类别、置信度的标签文本。
四、运行与验证
现在,一切准备就绪。重新编译并运行ScrewDetector项目。
1. 运行结果
点击"开始检测"按钮。稍等片刻,界面上将会显示出带有绿色边界框和标签的螺丝图像。程序成功地识别出了图片中的head_defect(头部瑕疵)!同时,状态栏也会更新为"AI推理完成!"。
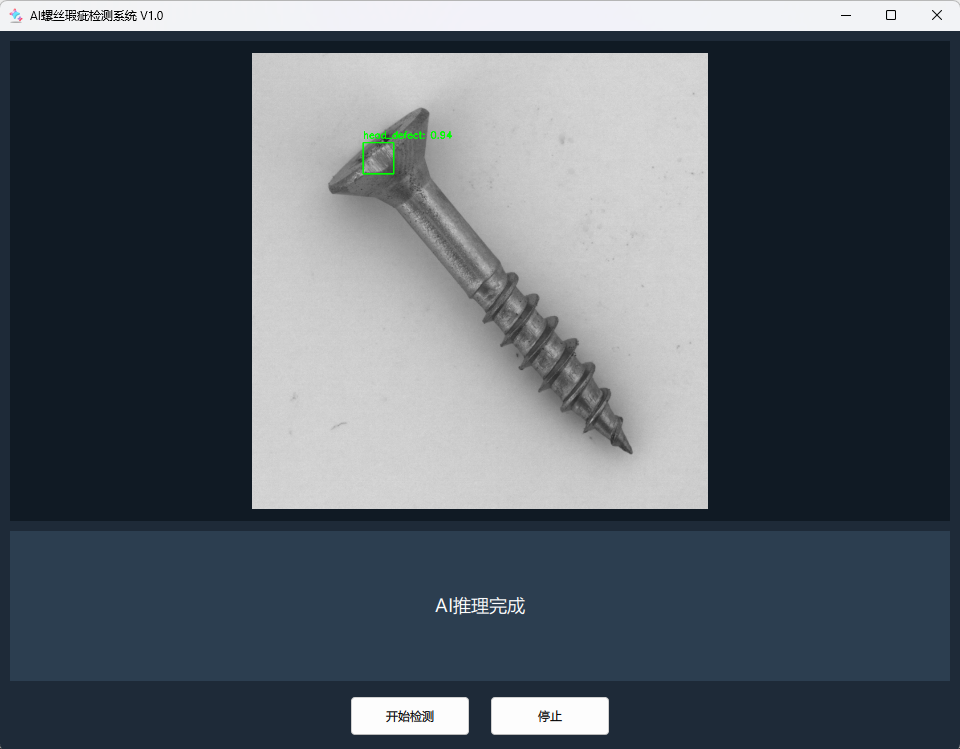
2. 尝试其他图片
可以尝试修改Backend::startScan()中的imagePath,换成数据集中其他的图片(例如good文件夹下的图片),重新运行,观察AI模型是否会误检。运行效果如下:
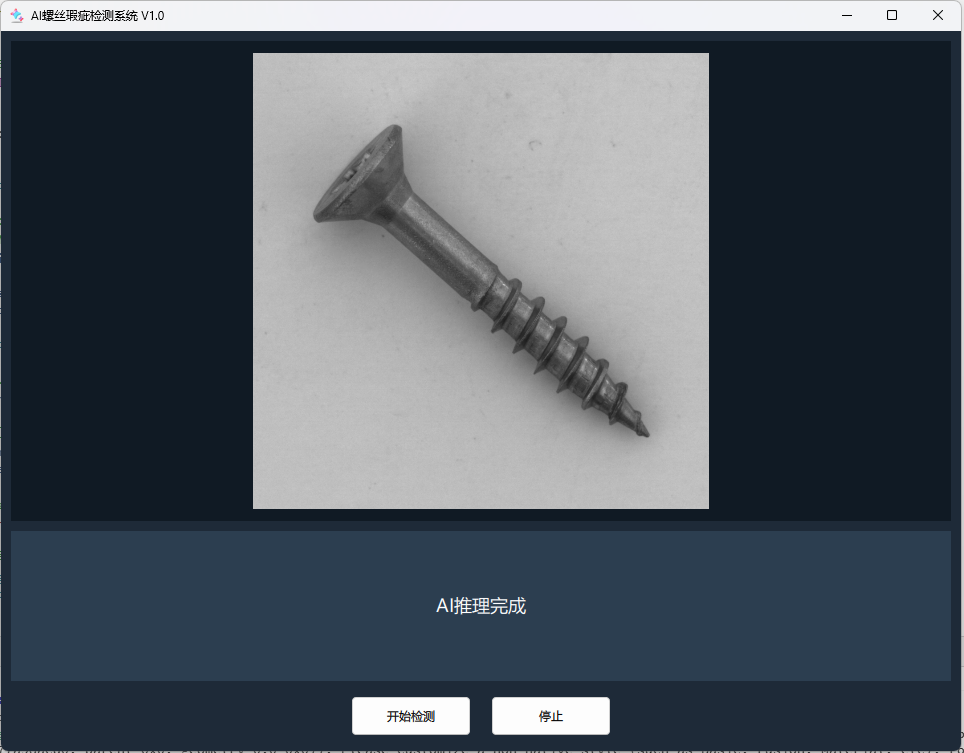
可以看到,对于没有瑕疵的图片,AI模型不会检测出瑕疵,验证了模型的有效性。
五、总结与展望
在本篇文章中,我们成功地跨越了Python与C++之间的鸿沟,将上一章训练的AI模型部署到了我们的Qt应用程序中。我们掌握了使用OpenCV DNN模块加载ONNX模型 、对输入图像进行预处理 以及最关键的YOLOv8输出后处理技术。
至此,我们的应用程序已经拥有了真正的"AI大脑",能够对静态图片进行智能瑕疵检测。然而,在真实的工业场景中,产品是连续不断地在传送带上移动的。如何处理来自摄像头的实时视频流?如何保证处理速度?
这将是我们下一篇文章【《使用Qt Quick从零构建AI螺丝瑕疵检测系统》------9. 接入真实硬件:驱动USB摄像头】的核心主题。我们将让程序从处理单张图片,升级为处理实时动态视频。