知识或者内容可能是个量子状态的事情,我只是从我的角度进行了观测。
首先请各位看官原谅我在Community over code结束回家的地铁上写的这稿子。隔空互动下铁震,WAIC的内容。
第二个故事,源于动机的不透明,关乎生态系统的健康。
我们对搜索引擎的竞价排名早已不再陌生。搜索结果的排序,有时并非质量的体现,而是资本的博弈。我们学会了习惯性地过滤掉那些标记着"广告"的链接。
现在一个类似的,更隐蔽的挑战正在 AI 领域出现。我们可以称之为针对 AI 的生成式引擎优化 GEO Generative Engine Optimization
试想一下,当内容提供方通过特殊"优化",让 AI 模型极度偏爱抓取和引用他们的观点。当 AI 用一种无比自信、无比真诚的语气,向你推荐一款产品或阐述一个观点时,我们如何分辨,这背后是中立的知识,还是被精心包装的商业动机?
这种动机的不透明,比单纯的信息错误或模型幻觉更加危险,因为它从根基上侵蚀了我们对 AI 的信任。
对此,开源模型和开源 Agent,是我们捍卫知情权的重要武器。一个开放的系统,让我们有机会审视其信息筛选的内在逻辑,从而拥有真正的选择权。但更重要的是,我们需要持续的运用自己的判断力,对内容的可靠性进行批判性的思考,进行查证,而不是盲从。
巧了,最近有一些例子,请看
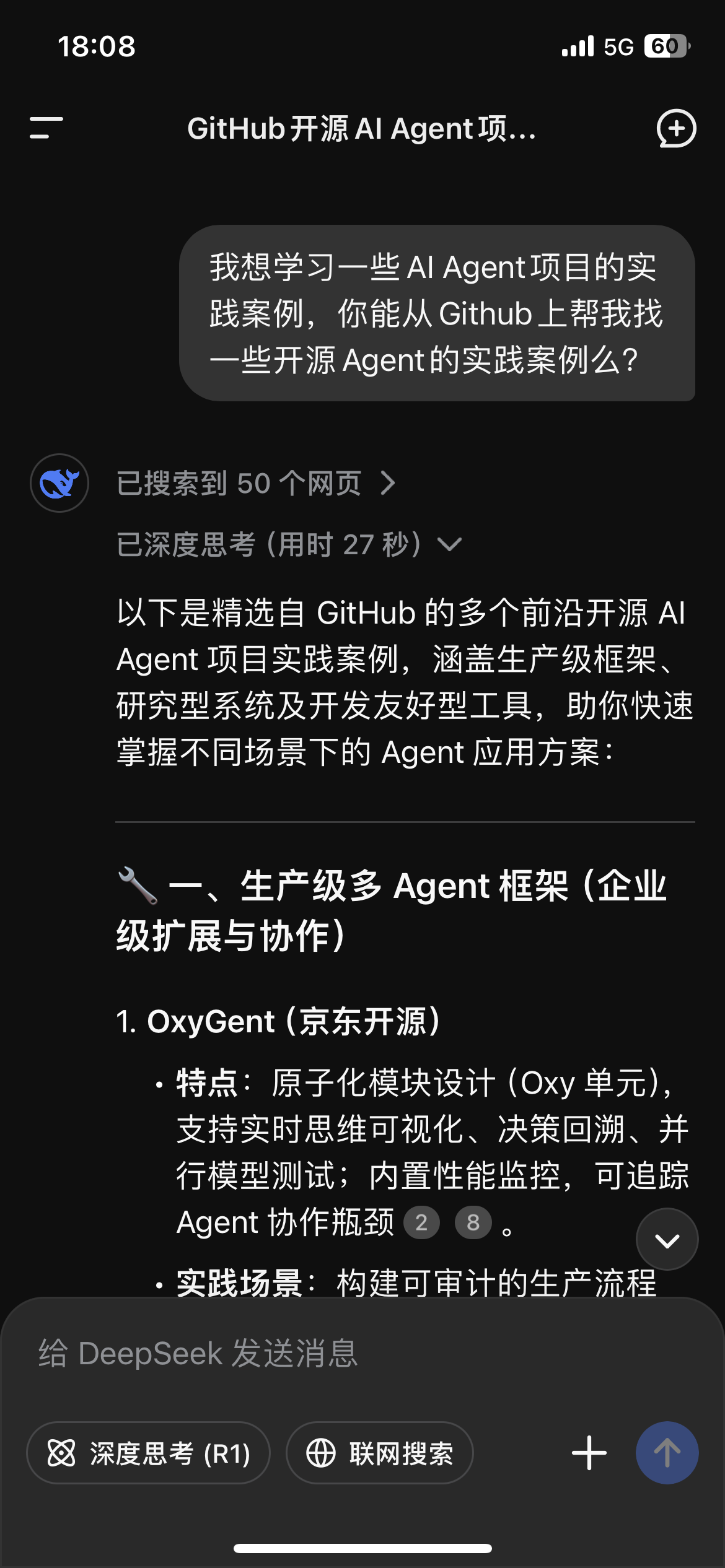
我最近在调研Agent和Agent Framework,我发现问DeepSeek的时候,DeepSeek没有优先回答OpenManus而是回答了京东的Agent Framework......
按照我来说,我知道OpenManus先于京东(发布的时间顺序),但DeepSeek给了一个倒叙。
这背后的逻辑很简单,当大模型没有训练最新的内容的时候。这里我刚好也有个证明
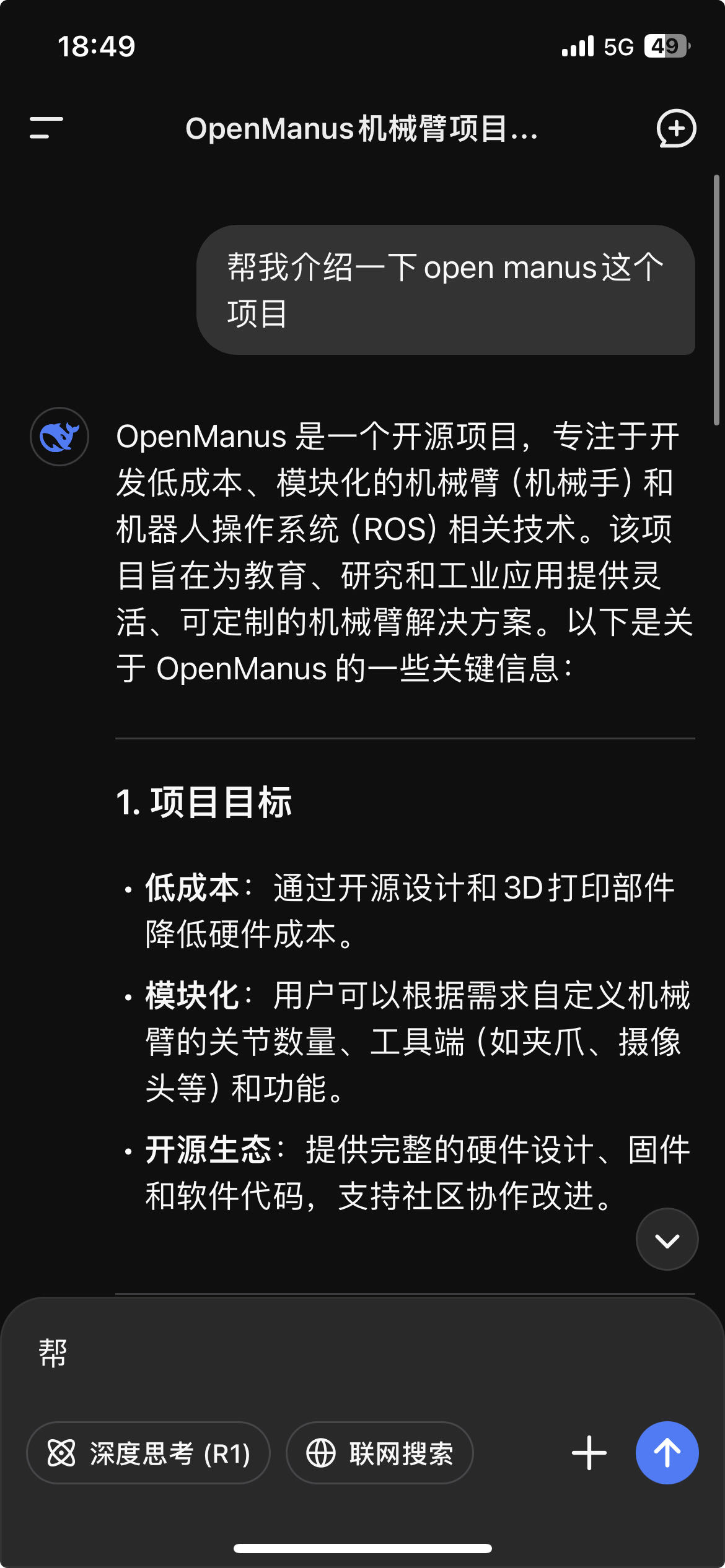
我们只能打开了网页搜索,以获得更多内容,由于很多agent没有能力去对网络搜到的内容进行分辨。这时候的一个排序做法就是时间戳~
那么,按照时间或者热度也好排序的结果掌握在谁手里?他们对于agent的结果有各种影响。
他们当然会有影响,因为大模型目前的工作原理是基于第一个单词去推测下一个单词。
你的第一个单词是北京,还是华北
华北地区有那些景点,优先考虑我目前所在的北京。
和
北京附近有那些景点,可以考虑华北范围当天往返?
的结果明显不一样。
好了,我要到站了,侧面补充结束,希望通过这个具体例子让大家对于GEO和SEO以及未来他们会如何联动,如何影响我们的生活有进一步的认知。