随着大数据应用复杂度提升,高效的日志采集和存储成为保障系统稳定性的关键。DolphinDB 作为高性能时序数据库,其高可用集群的运维需实时日志分析支持。本文基于 Fluent Bit、Kafka 与 DolphinDB 的 TextDB 引擎构建日志采集存储体系,提供从部署到查询的全流程实践,涵盖多节点环境配置、日志标签解析以及日志存储和查询,提升运维效率。
1 方案概述
本方案通过 Fluent Bit 采集 DolphinDB 日志,结合 DolphinDB 的 TextDB 引擎实现日志的储存和查询。DolphinDB 的 TextDB 可以实现如用户级日志查询等进阶功能,满足用户对日志查询的高级需求。
1.1 Fluent Bit 概述
Fluent Bit 是一款开源的遥测数据采集器,专门设计用于高效应对从资源受限系统到复杂云基础设施等广泛环境中,采集和处理遥测数据所面临的挑战。它支持多种数据源与格式,可与 Prometheus 、OpenTelemetry 等生态系统实现无缝对接。Fluent Bit 既能高效管理多样化数据源及格式,又能在确保最佳性能的同时维持低资源消耗。
1.2 DolphinDB TextDB 概述
DolphinDB 在 3.00.2 版本中,推出了基于倒排索引的文本存储引擎(TextDB)。TextDB 能够为主键存储引擎( PKEY) 中的文本数据建立倒排索引,使得用户在对有倒排索引的文本列上进行全文检索时,性能得到显著提升,满足现代应用对海量文本数据高效检索与快速响应的需求:
- 在金融领域,可提取文本中的关键信息,结合 NLP 工具实现市场情绪分析、信息过滤与处理等高效应用。
- 在物联网领域,可高效管理海量日志数据,并支持实时搜索与分析。
DolphinDB TextDB 具有以下功能和特点:
- 查询加速 :
- 对字符串类型的全文检索进行优化,相较于传统的
LIKE查询,性能显著提升。 - 对字符串类型的等值查询进行加速。
- 对字符串类型的全文检索进行优化,相较于传统的
- 多种检索方式支持:支持关键词、短语检索,前缀、后缀匹配,并允许在短语检索时指定词距。
- 多语言支持:适用于中文、英文及中英文混合内容的检索。
- 高效存储与索引:深度集成于 DolphinDB 存储引擎,相较于外部维护独立的倒排索引,减少了索引的空间占用,并提升了索引的读写效率。
1.3 方案架构概述
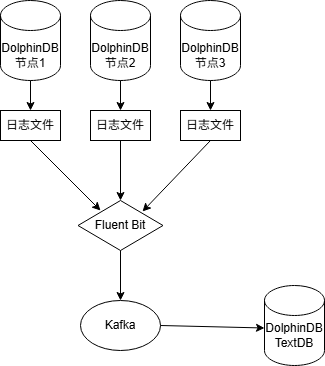
架构图
本方案提供从日志采集、传输、存储到查询分析的完整闭环,有效提升 DolphinDB 集群的运维效率:
- Fluent Bit 采集 DolphinDB 节点日志,并写入 Kafka。
- 通过 DolphinDB 的 Kafka 插件订阅 Kafka 数据,解析后写入 TextDB 表。
- 用户可通过 DolphinDB SQL 实现高效查询。
2 方案部署
2.1 安装和配置 Kafka
第一步:下载 Kafka,并解压
下载 Kafka 安装包,并上传至 Linux 服务器。
执行下面命令进行解压并且进入对应目录
tar -xzf kafka_2.13-4.0.0.tgz
cd kafka_2.13-4.0.0第二步:配置数据保存路径
修改 config/server.properties
# 数据目录位置,选择空间足够的位置
log.dirs=/tmp/kraft-combined-logs 第三步:初始化 Kafka
生成集群 UUID
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"格式化日志文件夹
bin/kafka-storage.sh format --standalone -t $KAFKA_CLUSTER_ID -c config/server.properties第四步:启动 Kafka
后台启动 Kafka
bin/kafka-server-start.sh -daemon config/server.properties第五步:创建 Kafka topic 并且配置保留策略
#创建 ddblog topic
bin/kafka-topics.sh --create --topic ddblog --bootstrap-server localhost:9092
#设置保留策略
#最长保留 15 天
bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-name ddblog --entity-type topics --add-config retention.ms=1296000000
#数据最大保存 5GB
bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-name ddblog --entity-type topics --add-config retention.bytes=5000000000
#保留策略为删除
bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --entity-name ddblog --entity-type topics --add-config cleanup.policy=delete2.2 安装和配置 Fluent Bit
2.2.1 安装 Fluent Bit
在线环境下可执行以下命令完成一键安装:
curl https://raw.githubusercontent.com/fluent/fluent-bit/master/install.sh | sh离线环境下,可下载对应发行版安装包,使用系统包管理器安装;或参考官方编译指南从源代码构建。
2.2.2 配置文件和参数解析
创建并且配置 fluent-bit.yml
service:
flush: 1
log_level: info
http_server: false
parsers:
- name: dol
format: regex
regex: ^(?<time>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d{9}),(?<thread>[^ ]*) (?<loglevel>[^ ]*) :(?<mesg>.*)$
time_key: time
time_format: "%Y-%m-%d %H:%M:%S.%L"
pipeline:
inputs:
- name: tail
path: /root/3.00.2.1/server/dolphindb.log
buffer_chunk_size: 30M
buffer_max_size: 30M
tag: signle
Threaded: true
parser: dol
inputs:
- name: tail
path: /root/3.00.2.1/server/clusterDemo/log/controller.log
tag: controller
buffer_chunk_size: 30M
buffer_max_size: 30M
Threaded: true
parser: dol
inputs:
- name: tail
path: /root/3.00.2.1/server/clusterDemo/log/agent.log
tag: agent
buffer_chunk_size: 30M
buffer_max_size: 30M
Threaded: true
parser: dol
inputs:
- name: tail
path: /root/3.00.2.1/server/clusterDemo/log/dnode1.log
tag: dnode1
buffer_chunk_size: 30M
buffer_max_size: 30M
Threaded: true
parser: dol
inputs:
- name: tail
path: /root/3.00.2.1/server/clusterDemo/log/dnode2.log
tag: dnode2
buffer_chunk_size: 30M
buffer_max_size: 30M
Threaded: true
parser: dol
filters:
- name: modify
match: 'signle'
Add:
- nodeName single
filters:
- name: modify
match: 'controller'
Add:
- nodeName controller
filters:
- name: modify
match: 'agent'
Add:
- nodeName agent
filters:
- name: modify
match: 'dnode1'
Add:
- nodeName dnode1
filters:
- name: modify
match: 'dnode2'
Add:
- nodeName dnode2
outputs:
- name: kafka
match: '*'
brokers: 127.0.0.1:9092
topics: ddblog参数解析
下面的参数解析部分只包含本文所使用的配置项,其他配置项可以查看官方文档进行深入了解。
service 部分参数:
- flush:引擎刷新时间,每次读取日志的间隔,单位秒。
- log_level:Fluent-bit 自身的日志等级。有 off、 error、warn、 info、 debug 和 trace 这6个等级。
- http_server:是否启用自身的 http 服务器。
parsers 部分参数(可以定义多个解析器,每个部分都有自己的属性):
- name:解析器的唯一名称。
- format:指定解析器的格式,此处的可用选项为:json、regex、ltsv 或 logfmt。
- regex:如果 format 为 regex,则必须设置此选项,以指定将用于解析和撰写结构化消息的 Ruby 正则表达式。
- time_key:如果日志条目提供带有时间戳的字段,则此选项指定该字段的名称。
- time_format:指定时间字段的格式,以便正确识别和分析它。Fluent Bit 使用 strptime 来解析时间。有关可用的修饰符,请参阅 strptime文档。%L 字段描述符支持秒的小数部分。
pipeline 部分分成 inputs、filters、outputs 三部分。inputs 是指定负责收集或接收数据的插件的名称,此组件用作管道中的数据源;filters 是筛选条件用于根据特定条件转换、扩充或丢弃事件。outputs 是定义已处理数据的目标。输出指定数据将发送到的位置,例如发送到远程服务器、文件或其他服务。
inputs 部分参数:
可以定义多个输入数据源,每个部分都有自己的属性。
- name:使用的数据源插件名称,本文使用的是 tail 插件。
- path:DolphinDB 不同节点的日志路径。
- tag:该日志标签,用于后面添加一列区分不同节点。
- buffer_chunk_size:设置初始缓冲区大小以读取文件数据。
- buffer_max_size:设置每个受监控文件的缓冲区大小限制。当需要增加缓冲区时(例如:非常长的行),此值用于限制内存缓冲区可以增长的量。
- Threaded:是否在其自己的线程中运行此输入。
- parser:指定解析器的名称以将条目解释为结构化消息。
filters 部分参数:
- name:使用的过滤器名称,本文使用的是 modify。
- match:匹配输入数据标签。
- Add:添加键/值对数据。
outputs 部分参数:
- name:使用的输出插件名称,本文使用的是 Kafka 插件。
- brokers:单个或多个 Kafka 代理列表。
- topics:Kafka 的主题。
2.2.3 启动 Fluent Bit
可以通过下面的命令启动 Fluent-bit。
nohup /opt/fluent-bit/bin/fluent-bit -c fluent-bit.yml > fluent-bit.log &2.3 DolphinDB 接收和查询日志数据
第一步:安装 Kafka 插件
在线环境下可执行以下脚本完成安装:
installPlugin("kafka")
try{
loadPlugin("kafka")
}catch(ex){
print(ex)
}离线环境下,可先到官网插件市场下载对应版本 Kafka 插件,然后上传到 DolphinDB 所在服务器并解压到 <DolphinDB安装目录>/server/plugins 文件夹中。最后执行下面脚本加载 Kafka 插件
try{
loadPlugin("kafka")
}catch(ex){
print(ex)
}第二步:建立库表
确保 DolphinDB 版本在 3.00.2 及以上。执行下面的脚本建立对应的库表
db1=database(,VALUE,[2025.01.01])
db2=database(,VALUE,['dnode1'])
db=database("dfs://ddblog",COMPO,[db1,db2],engine="PKEY")
tb=table(1:0,["timestamp",'thread','loglevel','mesg','nodeName'],[NANOTIMESTAMP,STRING,SYMBOL,STRING,SYMBOL])
pt=db.createPartitionedTable(tb,'data',partitionColumns=`timestamp`nodeName,primaryKey=`nodeName`thread`loglevel`timestamp,indexes={'mesg':'textindex(parser=english,full=false,lowercase=true,stem=false)'})第三步:订阅 Kafka 数据写入库表
使用 Kafka 插件订阅日志数据并写入 TextDB 库表,相关参数需根据实际部署配置调整。
// 建立消费者
consumerCfg = dict(STRING, ANY)
consumerCfg["group.id"] = string(now())
//需要上游 Kafka 具体IP和端口
consumerCfg["metadata.broker.list"] = "localhost:9092";
consumer = kafka::consumer(consumerCfg)
//订阅对应主题
kafka::subscribe(consumer, "ddblog");
//解析函数
def parser(msg) {
// 指定 msgAsTable 为 true 后,回调时会返回 table
// 将其中的 payload 列传入指定 schema 的 parseJsonTable,获取解析后的 JSON 数据
tmp=select nanotimestamp(long(_'@timestamp' * 1000000000)) as timestamp,thread,loglevel,mesg,nodeName from parseJsonTable(msg.payload, table(["@timestamp","thread","loglevel","mesg","nodeName"] as name, `DOUBLE`STRING`STRING`STRING`STRING as type))
return tmp
}
//构建自动清理流表
enableTableShareAndCachePurge(streamTable(1:0,["timestamp",'thread','loglevel','mesg','nodeName'],[NANOTIMESTAMP,STRING,SYMBOL,STRING,SYMBOL]),"share_ddblog",4000000)
//提交订阅任务
kafka::createSubJob(consumer, share_ddblog, parser, "sub_ddblog", 1, true, true, 10000)
//订阅ddb流表写入dfs表
subscribeTable(tableName="share_ddblog",actionName="write2dfs",handler=loadTable("dfs://ddblog",`data),msgAsTable=true,batchSize=200000,throttle=10,reconnect=true)第四步:进行查询
可以通过 SQL 语句进行查询,TextDB 的具体用法可以参考官网手册。
例子:查询日期为 2025.05.21,single 节点上关于 "PKEY" 的信息
select * from loadTable("dfs://ddblog",`data) where nodeName='single' and date(timestamp)=2025.05.12 and matchAll(mesg, "[PKEY]")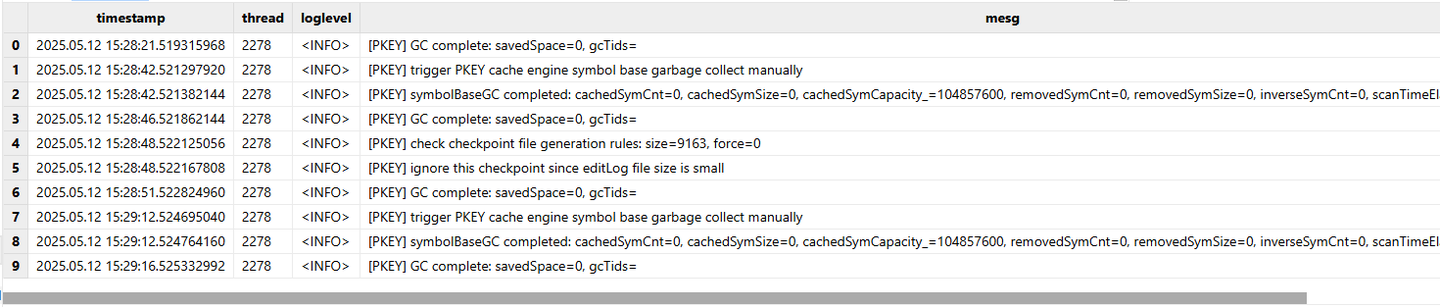
第五步:设置自动清理历史数据(可选)
写入的日志会保存在 DolphinDB 的数据库之中,如果有清理历史数据的需要,可以参考下面的方法进行设置保存策略。
setRetentionPolicy(dbHandle=database("dfs://ddblog"),retentionHours=24*30,retentionDimension=0)- dbHandle: 分布式数据库的句柄。数据库的分区方案必须包含 DATE 类型或 DATEHOUR 类型。
- retentionHours: 正整数,表示数据保留时间,单位是小时。分级存储和数据保留策略都以分区为单位进行,因此 retentionHours 配置的时间必须是分区精度的倍数,如按天分区,则需要为 24 的整数倍。
- retentionDimension: 整数,表示时间分区所在的层次。默认值是 0,表示第一层分区是按时间分区。
3 进阶用法:用户级别日志管理
在多用户平台中,不同用户需要记录和存储各自的日志信息。然而当前 DolphinDB 系统对于流数据计算、量化回测等无法提交至 batchJob 后台任务,或存在日志打印限制的应用场景,普通用户只能通过 writeLog 接口写入日志。这种机制存在两个主要局限:其一,普通用户无法直接查询自身写入的日志内容;其二,不同用户产生的日志信息缺乏有效隔离机制。针对这些问题,可通过结合 DolphinDB 的函数视图功能解决。
实现方法
自定义函数视图:
def writeUserLog(msg){
userId=getCurrentSessionAndUser()[1]
writeLog("[USER_LOG:"+userId+"]"+string(msg))
}
addFunctionView(writeUserLog)授权相关用户执行该函数视图
grant("test",VIEW_EXEC,writeUserLog)重新相关用户,然后调用该函数写入日志:
writeUserLog("hello,world")
writeUserLog("bye")查询相关用户日志(日志 DolphinDB 服务器上面):
select *
from
loadTable("dfs://ddblog",`data)
where
nodeName='single'
and date(timestamp)=2025.06.06
and matchAll(mesg, "[USER_LOG:test]")
也可以封装成函数,在上游服务器调用:
def getUserLog(startTime,endTime){
userId=getCurrentSessionAndUser()[1]
conn=xdb("192.168.100.252",28849,"admin","123456")
return remoteRun(conn,"select * from loadTable(\"dfs://ddblog\",`data) where nodeName='single' and timestamp >="+string(startTime) +" and timestamp <="+string(endTime)+" and matchAll(mesg, \"[USER_LOG:"+userId+"]\")")
}
addFunctionView(getUserLog)
getUserLog(2025.06.06 00:00:00.000,2025.06.06 20:00:00.000)
普通用户通过调用 writeUserLog 和 getUserLog 函数视图,可在流式计算、量化回测等场景中实现日志信息的用户级别管理。
4 结语
本文基于 Flluent Bit、Kafka 与 DolphinDB TextDB 引擎,构建了一套高效、可扩展的日志采集与存储方案,为复杂环境下的系统运维提供了全流程实践指导。通过整合 Fluent Bit 的轻量级日志采集能力、Kafka 的高吞吐消息队列以及 DolphinDB TextDB 的高性能检索特性,该方案不仅实现了海量日志的实时采集与存储,还显著提升了日志查询效率,助力运维团队快速定位问题、优化系统性能。
在金融、物联网等场景中,该方案可进一步结合 DolphinDB 的脚本计算与自定义函数功能,实现用户级日志权限管理、智能告警等高级需求,充分释放日志数据的业务价值。未来,随着日志分析需求的多样化,开发者可基于此方案灵活扩展,例如集成自然语言处理(NLP)工具进行语义分析,或结合流计算引擎实现实时异常检测,持续赋能智能化运维体系建设。