
基于 IoT-benchmark 的时序数据库性能测试实战:从安装到结果分析
本文详细介绍了由清华大学软件学院研发的开源时序数据库基准测试工具 IoT-benchmark,该工具基于 Java 和大数据环境开发,采用模块化设计思路,在借鉴 YCSB 工具组件分离设计的基础上新增系统监控模块及时序数据场景专属负载测试功能,支持 IoTDB、InfluxDB 等多种时序数据库及多种写入、查询工作模式。文章依次阐述了工具的基本概述、安装运行流程、核心配置参数(含服务模型、工作模式、连接信息、读写场景等)及自动化脚本使用方法,并结合中车青岛四方所的实际应用案例,展示了基于该工具的 IoTDB 与 KairosDB 性能对比测试过程、结果及可视化分析方式,为时序数据库的性能评估与选型提供了全面的工具使用指引与实践参考。

1. 基本概述
IoT-benchmark 是基于 Java 和大数据环境开发的时序数据库基准测试工具,由清华大学软件学院研发并开源。它使用方便,支持多种写入以及查询方式,支持存储测试信息和结果以供进一步查询或分析,支持与 Tableau 集成以可视化测试结果。
下图1-1囊括了测试基准流程及其他扩展功能。这些流程可以由IoT-benchmark 统一来完成。IoT Benchmark 支持多种工作负载,包括纯写入、纯查询、写入查询混合 等,支持软硬件系统监控、测试指标度量 等监控功能,还实现了初始化数据库自动化、测试数据分析及系统参数优化等功能。
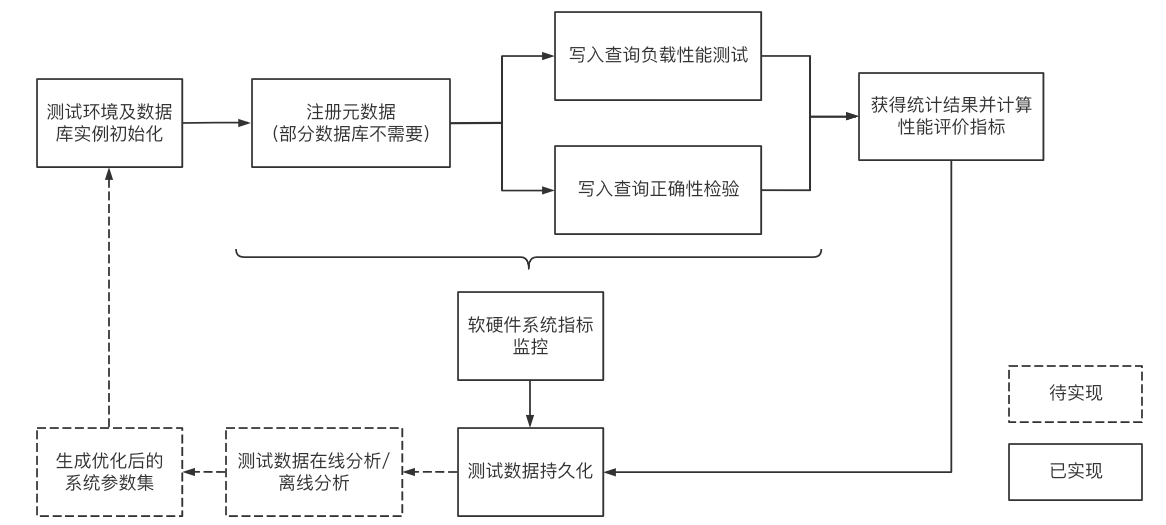
图1-1
借鉴 YCSB 测试工具将工作负载生成、性能指标测量和数据库接口三个组件分离的设计思想,IoT-benchmark 的模块化设计如图1-2所示。与基于 YCSB 的测试工具系统不同的是,IoT-benchmark 增加了系统监控模块,支持测试数据和系统指标监控数据的持久化。此外也增加了一些特别针对时序数据场景的特殊负载测试功能,如支持物联网场景的批量写入和多种乱序数据写入模式。
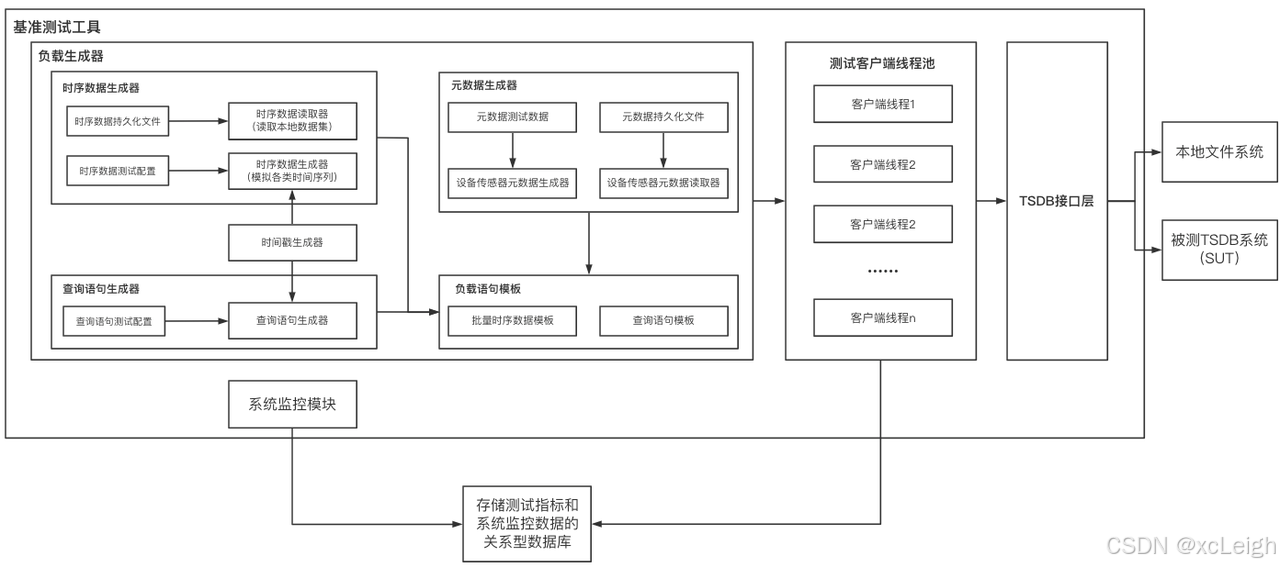
图1-2
目前 IoT-benchmark 支持如下时间序列数据库、版本和连接方式:
| 数据库 | 版本 | 连接方式 |
|---|---|---|
| IoTDB | v1.x v2.x | jdbc、sessionByTablet、sessionByRecord、sessionByRecords |
| InfluxDB | v1.x v2.x | SDK |
| TimescaleDB | -- | jdbc |
| OpenTSDB | -- | Http Request |
| QuestDB | v6.0.7 | jdbc |
| TDengine | v2.2.0.2 | jdbc |
| VictoriaMetrics | v1.64.0 | Http Request |
| KairosDB | -- | Http Request |
表1-1大数据测试基准对比
2. 安装运行
2.1 前置条件
- Java 8
- Maven 3.6+
- 对应的合适版本的数据库,如 Apache IoTDB 2.0
2.2 获取方式
- 获取二进制包:进入这里 下载需要的安装包。下载下来为一个压缩文件,选择文件夹解压即可使用。
- 源代码编译(可用 Apache IoTDB 2.0 的测试):
- 第一步(编译 IoTDB Session 最新包):进入官网下载 IoTDB 源码,在根目录下运行命令 mvn clean package install -pl session -am -DskipTests 编译 IoTDB Session 的最新包。
- 第二步(编译 IoTDB Benchmark 测试包):进入官网下载源码,在根目录下运行 mvn clean package install -pl iotdb-2.0 -am -DskipTests 编译测试 Apache IoTDB 2.0版本的测试包,测试包位置与根目录的相对路径为 ./iotdb-2.0/target/iotdb-2.0-0.0.1/iotdb-2.0-0.0.1
2.3 测试包结构
测试包的目录结构如下所示。其中测试配置文件为conf/config.properties,测试启动脚本为benchmark.sh (Linux & MacOS) 和 benchmark.bat (Windows),详细文件用途见下表所示。
shell
-rw-r--r--. 1 root root 2881 1月 10 01:36 benchmark.bat
-rwxr-xr-x. 1 root root 314 1月 10 01:36 benchmark.sh
drwxr-xr-x. 2 root root 24 1月 10 01:36 bin
-rwxr-xr-x. 1 root root 1140 1月 10 01:36 cli-benchmark.sh
drwxr-xr-x. 2 root root 107 1月 10 01:36 conf
drwxr-xr-x. 2 root root 4096 1月 10 01:38 lib
-rw-r--r--. 1 root root 11357 1月 10 01:36 LICENSE
-rwxr-xr-x. 1 root root 939 1月 10 01:36 rep-benchmark.sh
-rw-r--r--. 1 root root 14 1月 10 01:36 routine| 名称 | 子文件 | 用途 |
|---|---|---|
| benchmark.bat | - | Windows环境运行启动脚本 |
| benchmark.sh | - | Linux/Mac环境运行启动脚本 |
| bin | startup.sh | 初始化脚本文件夹 |
| conf | config.properties | 测试场景配置文件 |
| lib | - | 依赖库文件 |
| LICENSE | - | 许可文件 |
| cli-benchmark.sh | - | 一键化启动脚本 |
| routine | 多项测试配置文件 | |
| rep-benchmark.sh | 多项测试启动脚本 |
表2-1文件和文件夹列表用途
2.4 执行测试
- 按照测试需求修改配置文件,主要参数介绍见第3节,对应配置文件为conf/config.properties,比如测试Apache IoTDB 2.0,则需要修改 DB_SWITCH=IoTDB-200-SESSION_BY_TABLET
- 启动被测时间序列数据库
- 通过运行
- 启动IoT-benchmark执行测试。执行中观测被测时间序列数据库和IoT-benchmark状态,执行完毕后查看结果和分析测试过程。
2.5 结果说明
测试的所有日志文件被存放于 logs 文件夹下,测试的结果在测试完成后被存放到 data/csvOutput 文件夹下,例如测试后我们得到了如下的结果矩阵:
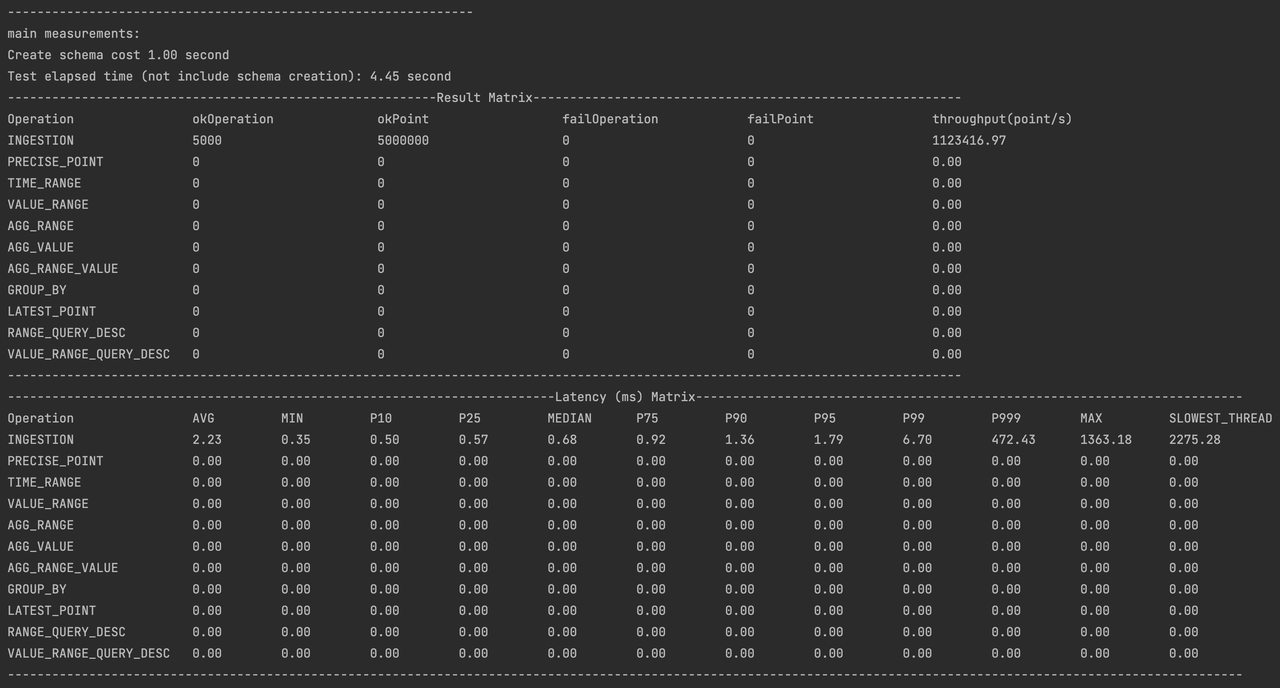
- Result Matrix
- OkOperation:成功的对应操作次数
- OkPoint:对于写入操作,是成功写入的点数;对于查询操作,是成功查询到的点数。
- FailOperation:失败的对应操作次数
- FailPoint:对于写入操作是写入失败的点数
- Latency(mx) Matrix
- AVG:操作平均耗时
- MIN:操作最小耗时
- Pn:操作整体分布的对应分位值,比如P25是下四分位数
3. 主要参数
3.1 IoTDB服务模型
参数<font style="color:rgb(60, 60, 67);">IoTDB_DIALECT_MODE</font>支持tree、table,默认值为tree。
- 当被测数据库为IoTDB-2.0及以上版本时需指定sql_dialect, 并且一个IoTDB只能指定一种。
- sql_dialect等于tree时,要满足:device数量 >= database数量
3.2 工作模式
工作模式参数"BENCHMARK_WORK_MODE"可选项有如下四种模式:
- 常用测试模式:结合配置
OPERATION_PROPORTION参数达到"纯写入"、"纯查询"和"读写混合"的测试操作。 - 生成数据模式:为了生成可以重复使用的数据集,iot-benchmark提供生成数据集的模式,生成数据集到FILE_PATH,以供后续使用正确性写入模式和正确性查询模式使用。
- 单数据库正确性写入模式:为了验证数据集写入的正确性,您可以使用该模式写入生成数据模式中生成的数据集,目前该模式仅支持IoTDB v1.0 及更新的版本和InfluxDB v1.x。
- 单数据库正确性查询模式:在运行这个模式之前需要先使用正确性写入模式写入数据到数据库。为了验证数据集写入的正确性,您可以使用该模式查询写入到数据库中的数据集,目前该模式仅支持IoTDB v1.0 和 InfluxDB v1.x。
| 模式名称 | BENCHMARK_WORK_MODE | 模式内容 |
|---|---|---|
| 常规测试模式 | testWithDefaultPath | 支持多种读和写操作的混合负载 |
| 生成数据模式 | generateDataMode | 生成Benchmark本身识别的数据 |
| 单数据库正确性写入模式 | verificationWriteMode | 需要配置 FILE_PATH 以及 DATA_SET |
| 单数据库正确性查询模式 | verificationQueryMode | 需要配置 FILE_PATH 以及 DATA_SET |
3.3 服务器连接信息
工作模式指定后,被测时序数据库的信息会通过如下参数告知IoT-benchmark
| 参数名称 | 类型 | 示例 | 系统描述 |
|---|---|---|---|
| DB_SWITCH | 字符串 | IoTDB-200-SESSION_BY_TABLET | 被测时序数据库类型 |
| HOST | 字符串 | 127.0.0.1 | 被测时序数据库网络地址 |
| PORT | 整数 | 6667 | 被测时序数据库网络端口 |
| USERNAME | 字符串 | root | 被测时序数据库登录用户名 |
| PASSWORD | 字符串 | root | 被测时序数据库登录用户的密码 |
| DB_NAME | 字符串 | test | 被测时序数据库名称 |
| TOKEN | 字符串 | 被测时序数据库连接认证Token(InfluxDB 2.0使用) |
3.4 写入场景
| 参数名称 | 类型 | 示例 | 系统描述 |
|---|---|---|---|
| CLIENT_NUMBER | 整数 | 100 | 客户端总数 |
| GROUP_NUMBER | 整数 | 20 | 数据库的数量;仅针对IoTDB。 |
| DEVICE_NUMBER | 整数 | 100 | 设备总数 |
| SENSOR_NUMBER | 整数 | 300 | 每个设备的传感器总数; 如果使用 IoTDB 表模型,则控制属性列数量 |
| INSERT_DATATYPE_PROPORTION | 字符串 | 1:1:1:1:1:1 | 设备的数据类型比例,BOOLEAN:INT32:INT64:FLOAT:DOUBLE:TEXT |
| POINT_STEP | 整数 | 1000 | 数据间时间戳间隔,即生成的数据两个时间戳之间的固定长度。 |
| OP_MIN_INTERVAL | 整数 | 0 | 操作最小执行间隔:若操作耗时大于该值则立即执行下一个,否则等待 (OP_MIN_INTERVAL-实际执行时间) ms;如果为0,则参数不生效;如果为-1,则其值和POINT_STEP一致 |
| IS_OUT_OF_ORDER | 布尔 | false | 是否乱序写入 |
| OUT_OF_ORDER_RATIO | 浮点数 | 0.3 | 乱序写入的数据比例 |
| BATCH_SIZE_PER_WRITE | 整数 | 1 | 批写入数据行数(一次写入多少行数据) |
| START_TIME | 时间 | 2022-10-30T00:00:00+08:00 | 写入数据的开始时间戳;以该时间戳为起点开始模拟创建数据时间戳。 |
| LOOP | 整数 | 86400 | 总操作次数:具体每种类型操作会按OPERATION_PROPORTION定义的比例划分 |
| OPERATION_PROPORTION | 字符 | 1:0:0:0:0:0:0:0:0:0:0 | # 各操作的比例,按照顺序为 写入:Q1:Q2:Q3:Q4:Q5:Q6:Q7:Q8:Q9:Q10, 请注意使用英文冒号。比例中的每一项是整数。 |
3.5 查询场景
| 参数名称 | 类型 | 示例 | 系统描述 |
|---|---|---|---|
| QUERY_DEVICE_NUM | 整数 | 2 | 每条查询语句中查询涉及到的设备数量 |
| QUERY_SENSOR_NUM | 整数 | 2 | 每条查询语句中查询涉及到的传感器数量 |
| QUERY_AGGREGATE_FUN | 字符 | count | 在聚集查询中使用的聚集函数,比如count、avg、sum、max_time等 |
| STEP_SIZE | 整数 | 1 | 时间过滤条件的时间起点变化步长,若设为0则每个查询的时间过滤条件是一样的,单位:POINT_STEP |
| QUERY_INTERVAL | 整数 | 250000 | 起止时间的查询中开始时间与结束时间之间的时间间隔,和Group By中的时间间隔 |
| QUERY_LOWER_VALUE | 整数 | -5 | 条件查询子句时的参数,where xxx > QUERY_LOWER_VALUE |
| GROUP_BY_TIME_UNIT | 整数 | 20000 | Group by语句中的组的大小 |
| LOOP | 整数 | 10 | 总操作次数:具体每种类型操作会按OPERATION_PROPORTION定义的比例划分 |
| OPERATION_PROPORTION | 字符 | 0:0:0:0:0:0:0:0:0:0:1 | 写入:Q1:Q2:Q3:Q4:Q5:Q6:Q7:Q8:Q9:Q10 |
3.6 操作比例
| 编号 | 查询类型 | IoTDB 示例 SQL |
|---|---|---|
| Q1 | 精确点查询 | select v1 from root.db.d1 where time = ? |
| Q2 | 时间范围查询 | select v1 from root.db.d1 where time > ? and time < ? |
| Q3 | 带值过滤的时间范围查询 | select v1 from root.db.d1 where time > ? and time < ? and v1 > ? |
| Q4 | 时间范围聚合查询 | select count(v1) from root.db.d1 where and time > ? and time < ? |
| Q5 | 带值过滤的全时间范围聚合查询 | select count(v1) from root.db.d1 where v1 > ? |
| Q6 | 带值过滤的时间范围聚合查询 | select count(v1) from root.db.d1 where v1 > ? and time > ? and time < ? |
| Q7 | 时间分组聚合查询 | select count(v1) from root.db.d1 group by ([?, ?), ?, ?) |
| Q8 | 最新点查询 | select last v1 from root.db.d1 |
| Q9 | 倒序范围查询 | select v1 from root.sg.d1 where time > ? and time < ? order by time desc |
| Q10 | 倒序带值过滤的范围查询 | select v1 from root.sg.d1 where time > ? and time < ? and v1 > ? order by time desc |
3.7 测试过程和测试结果持久化
IoT-benchmark目前支持通过配置参数将测试过程和测试结果持久化:
| 参数名称 | 类型 | 示例 | 系统描述 |
|---|---|---|---|
| TEST_DATA_PERSISTENCE | 字符串 | None | 结果持久化选择,支持None,IoTDB,MySQL和CSV |
| RECORD_SPLIT | 布尔 | true | 是否将结果划分后输出到多个记录, IoTDB 暂时不支持 |
| RECORD_SPLIT_MAX_LINE | 整数 | 10000000 | 记录行数的上限(每个数据库表或CSV文件按照总行数为1千万切分存放) |
| TEST_DATA_STORE_IP | 字符串 | 127.0.0.1 | 输出数据库的IP地址 |
| TEST_DATA_STORE_PORT | 整数 | 6667 | 输出数据库的端口号 |
| TEST_DATA_STORE_DB | 字符串 | result | 输出数据库的名称 |
| TEST_DATA_STORE_USER | 字符串 | root | 输出数据库的用户名 |
| TEST_DATA_STORE_PW | 字符串 | root | 输出数据库的用户密码 |
- 如果我们设置"
TEST_DATA_PERSISTENCE=CSV",测试执行时和执行完毕后我们可以在IoT-benchmark根目录下看到新生成的data文件夹,其下包含csv文件夹记录测试过程;csvOutput文件夹记录测试结果。 - 如果我们设置"
TEST_DATA_PERSISTENCE=MySQL",它会在测试开始前在指定的MySQL数据库中创建命名如"testWithDefaultPath_被测数据库名称_备注_测试启动时间"的数据表记录测试过程;会在名为"CONFIG"的数据表(如果不存在则创建该表),写入本次测试的配置信息;当测试完成时会在名为"FINAL_RESULT"的数据表(如果不存在则创建该表)中写入本次测试结果。
3.8 自动化脚本
一键化启动脚本
您可以通过cli-benchmark.sh脚本一键化启动IoTDB、监控的IoTDB Benchmark和测试的IoTDB Benchmark,但需要注意该脚本启动时会清理IoTDB中的所有数据,请谨慎使用。
首先,您需要修改cli-benchmark.sh中的IOTDB_HOME参数为您本地的IoTDB所在的文件夹。
然后您可以使用脚本启动测试
bash
> ./cli-benchmark.sh测试完成后您可以在logs文件夹中查看测试相关日志,在server-logs文件夹中查看监控相关日志。
自动执行多项测试
通常,除非与其他测试结果进行比较,否则单个测试是没有意义的。因此,我们提供了一个接口来通过一次启动执行多个测试。
- 配置 routine
这个文件的每一行应该是每个测试过程会改变的参数(否则就变成复制测试)。例如,"例程"文件是:
plain
LOOP=10 DEVICE_NUMBER=100 TEST
LOOP=20 DEVICE_NUMBER=50 TEST
LOOP=50 DEVICE_NUMBER=20 TEST然后依次执行3个LOOP参数分别为10、20、50的测试过程。
注意:
您可以使用"LOOP=20 DEVICE_NUMBER=10 TEST"等格式更改每个测试中的多个参数,不允许使用不必要的空间。 关键字"TEST"意味着新的测试开始。如果您更改不同的参数,更改后的参数将保留在下一次测试中。
- 开始测试
配置文件routine后,您可以通过启动脚本启动多测试任务:
bash
> ./rep-benchmark.sh然后测试信息将显示在终端中。
注意:
如果您关闭终端或失去与客户端机器的连接,测试过程将终止。 如果输出传输到终端,则与任何其他情况相同。
使用此接口通常需要很长时间,您可能希望将测试过程作为守护程序执行。这样,您可以通过启动脚本将测试任务作为守护程序启动:
bash
> ./rep-benchmark.sh > /dev/null 2>&1 &在这种情况下,如果您想知道发生了什么,可以通过以下命令查看日志信息:
bash
> cd ./logs
> tail -f log_info.log4. 实际案例
我们以中车青岛四方车辆研究所有限公司应用为例,参考《ApacheIoTDB在智能运维平台存储中的应用》中描述的场景进行实际操作说明。
测试目标:模拟中车青岛四方所场景因切换时间序列数据库实际需求,对比预期使用的IoTDB和原有系统使用的KairosDB性能。
测试环境:为了保证在实验过程中消除其他无关服务与进程对数据库性能的影响,以及不同数据库之间的相互影响,本实验中的本地数据库均部署并运行在资源配置相同的多个独立的虚拟机上。因此,本实验搭建了 4 台 Linux( CentOS7 /x86) 虚拟机,并分别在上面部署了IoT-benchmark、 IoTDB数据库、KairosDB数据库、MySQL数据库。每一台虚拟机的具体资源配置如表4-1所示。每一台虚拟机的具体用途如表4-2所示。
表4-1虚拟机配置信息
| 硬件配置信息 | 系统描述 |
|---|---|
| OS System | CentOS7 |
| CPU核数 | 16 |
| 内存 | 32G |
| 硬盘 | 200G |
| 网卡 | 千兆 |
表4-2虚拟机用途
| IP | 用途 |
|---|---|
| 172.21.4.2 | IoT-benchmark |
| 172.21.4.3 | Apache-iotdb |
| 172.21.4.4 | KaiosDB |
| 172.21.4.5 | MySQL |
4.1 写入测试
场景描述:创建100个客户端来模拟100列车、每列车3000个传感器、数据类型为DOUBLE类型、数据时间间隔为500ms(2Hz)、顺序发送。参考以上需求我们需要修改IoT-benchmark配置参数如表4-3中所列。
表4-3配置参数信息
| 参数名称 | IoTDB值 | KairosDB值 |
|---|---|---|
| DB_SWITCH | IoTDB-013-SESSION_BY_TABLET | KairosDB |
| HOST | 172.21.4.3 | 172.21.4.4 |
| PORT | 6667 | 8080 |
| BENCHMARK_WORK_MODE | testWithDefaultPath | |
| OPERATION_PROPORTION | 1:0:0:0:0:0:0:0:0:0:0 | |
| CLIENT_NUMBER | 100 | |
| GROUP_NUMBER | 10 | |
| DEVICE_NUMBER | 100 | |
| SENSOR_NUMBER | 3000 | |
| INSERT_DATATYPE_PROPORTION | 0:0:0:0:1:0 | |
| POINT_STEP | 500 | |
| OP_MIN_INTERVAL | 0 | |
| IS_OUT_OF_ORDER | false | |
| BATCH_SIZE_PER_WRITE | 1 | |
| LOOP | 10000 | |
| TEST_DATA_PERSISTENCE | MySQL | |
| TEST_DATA_STORE_IP | 172.21.4.5 | |
| TEST_DATA_STORE_PORT | 3306 | |
| TEST_DATA_STORE_DB | demo | |
| TEST_DATA_STORE_USER | root | |
| TEST_DATA_STORE_PW | admin | |
| REMARK | demo |
首先在172.21.4.3和172.21.4.4上分别启动被测时间序列数据库Apache-IoTDB和KairosDB,之后在172.21.4.2、172.21.4.3和172.21.4.4上通过ser-benchamrk.sh脚本启动服务器资源监控(图4-1)。然后按照表4-3在172.21.4.2分别修改iotdb-0.13-0.0.1和kairosdb-0.0.1文件夹内的conf/config.properties文件满足测试需求。先后使用benchmark.sh启动对Apache-IoTDB和KairosDB的写入测试。
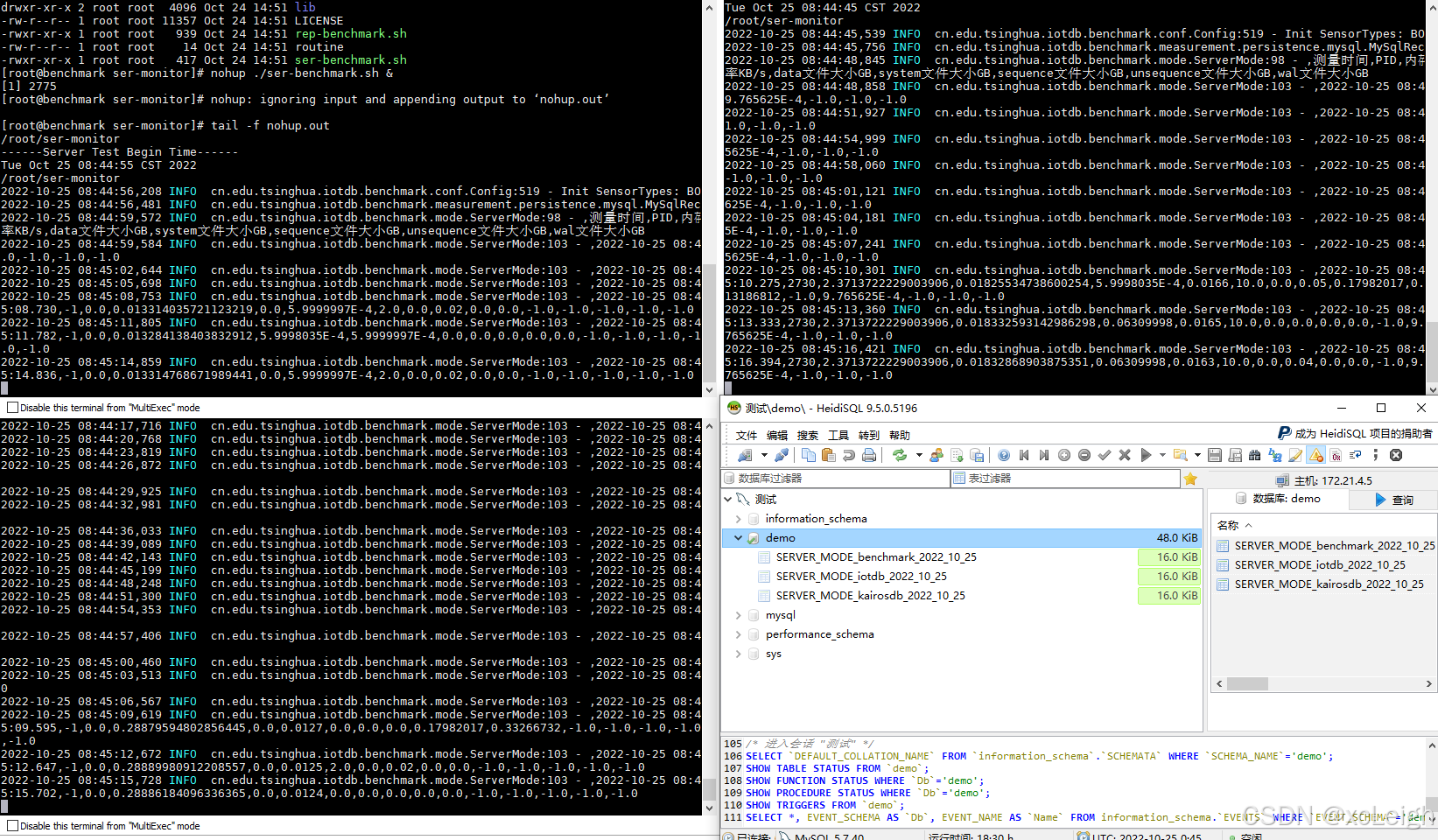
img
图4-1服务器监控任务
例如我们首先启动对KairosDB的测试,IoT-benchmark会在MySQL数据库中创建CONFIG数据表存放本次测试配置信息(图4-2),测试执行中会有日志输出当前测试进度(图4-3)。测试完成时会输出本次测试结果(图4-3),同时将结果写入FINAL_RESULT数据表中(图4-4)。
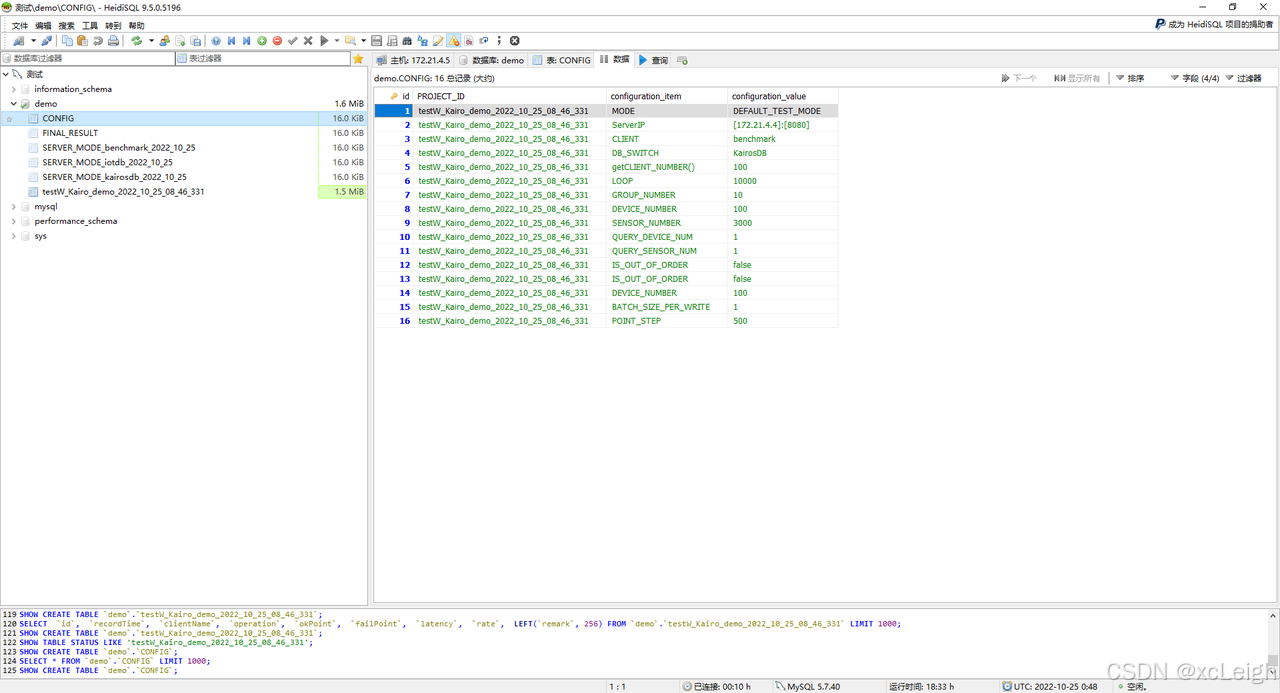
图4-2测试配置信息表
图4-3测试进度和结果
图4-4测试结果表
之后我们再启动对Apache-IoTDB的测试,同样的IoT-benchmark会在MySQL数据库CONFIG数据表中写入本次测试配置信息,测试执行中会有日志输出当前测试进度。测试完成时会输出本次测试结果,同时将结果写入FINAL_RESULT数据表中。
依照测试结果信息我们知道同样的配置写入Apache-IoTDB和KairosDB写入延时时间分别为:55.98ms和1324.45ms;写入吞吐分别为:5,125,600.86点/秒和224,819.01点/秒;测试分别执行了585.30秒和11777.99秒。并且KairosDB有写入失败出现,排查后发现是数据磁盘使用率已达到100%,无磁盘空间继续接收数据。而Apache-IoTDB无写入失败现象,全部数据写入完毕后占用磁盘空间仅为4.7G(如图4-5所示);从写入吞吐和磁盘占用情况上看Apache-IoTDB均优于KairosDB。当然后续还有其他测试来从多方面观察和对比,比如查询性能、文件压缩比、数据安全性等。
那么测试过程中各个服务器资源使用情况如何呢?每个写操作具体的表现如何呢?这个时候我们就可以通过安装和使用Tableau来可视化服务器监控表和测试过程记录表内的数据了。Tableau的使用本文不展开介绍,通过它连接测试数据持久化的数据表后具体结果下如图(以Apache-IoTDB为例):

图4-6Tableau可视化测试过程
4.2 查询测试
场景描述:在写入测试场景下模拟10个客户端对时序数据库Apache-IoTDB内存放的数据进行全类型查询任务。配置如下:
表4-4配置参数信息
| 参数名称 | 示例 |
|---|---|
| CLIENT_NUMBER | 10 |
| QUERY_DEVICE_NUM | 2 |
| QUERY_SENSOR_NUM | 2 |
| QUERY_AGGREGATE_FUN | count |
| STEP_SIZE | 1 |
| QUERY_INTERVAL | 250000 |
| QUERY_LOWER_VALUE | -5 |
| GROUP_BY_TIME_UNIT | 20000 |
| LOOP | 30 |
| OPERATION_PROPORTION | 0:1:1:1:1:1:1:1:1:1:1 |
执行结果:
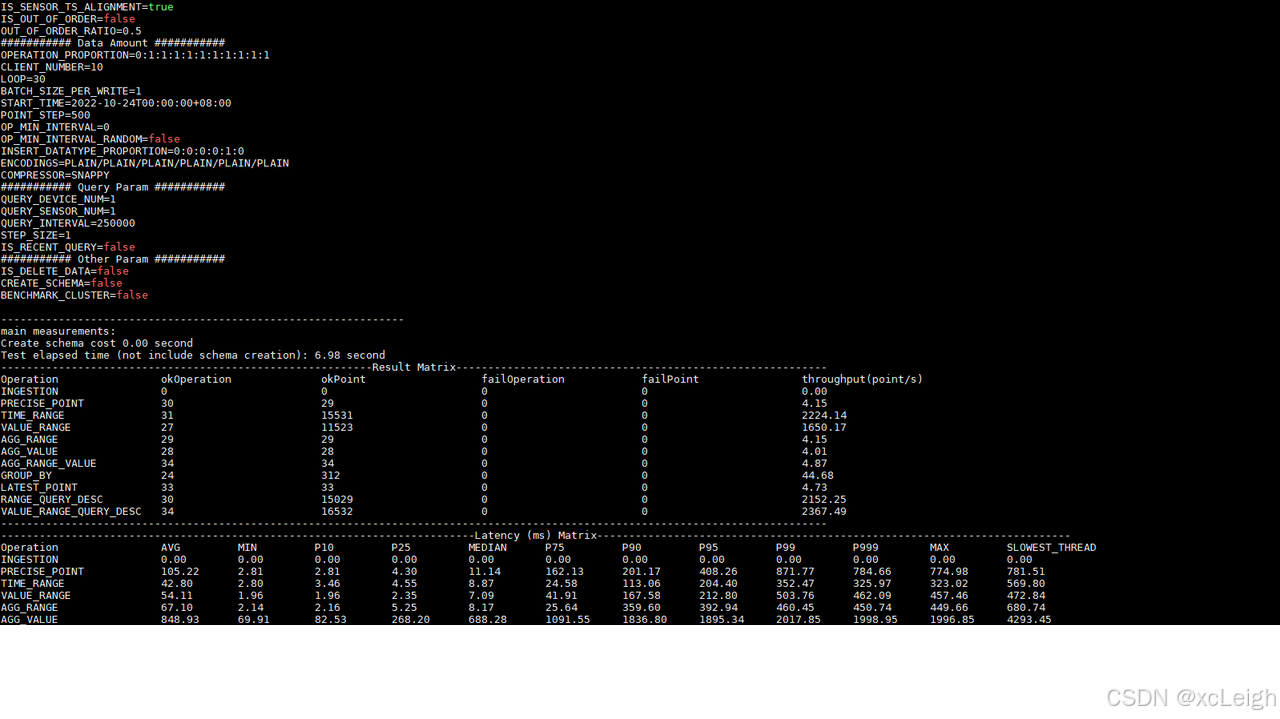
图4-7查询测试结果
4.3 其他参数说明
之前章节中针对Apache-IoTDB和KairosDB进行写入性能对比,但是用户如果要执行模拟真实写入速率测试该如何配置?测试时间过长该如何控制呢?生成的模拟数据有哪些规律吗?如果IoT-Benchmark服务器配置较低,可以使用多台机器模拟压力输出吗?
表4-5配置参数信息
| 场景 | 参数 | 值 | 说明 |
|---|---|---|---|
| 模拟真实写入速率 | OP_INTERVAL | -1 | 也可输入整数控制操作间隔 |
| 指定测试时长(1小时) | TEST_MAX_TIME | 3600000 | 单位 ms;需要LOOP执行时间大于该值 |
| 定义模拟数据规律:支持全部数据类型,数量平均分类;支持五种数据分布,数量平均分布;字符串长度为10;小数位数为2 | INSERT_DATATYPE_PROPORTION | 1:1:1:1:1:1 | 数据类型分布比率 |
| LINE_RATIO | 1 | 线性 | |
| SIN_RATIO | 1 | 傅里叶函数 | |
| SQUARE_RATIO | 1 | 方波 | |
| RANDOM_RATIO | 1 | 随机数 | |
| CONSTANT_RATIO | 1 | 常数 | |
| STRING_LENGTH | 10 | 字符串长度 | |
| DOUBLE_LENGTH | 2 | 小数位数 | |
| 三台机器模拟300台设备数据写入 | BENCHMARK_CLUSTER | true | 开启多benchmark模式 |
| BENCHMARK_INDEX | 0、1、3 | 以写入测试 写入参数为例:0号负责设备编号0-99数据写入;1号负责设备编号100-199数据写入;2号负责设备编号200-299数据写入; |
🌐 附:IoTDB的各大版本
📄 Apache IoTDB 是一款工业物联网时序数据库管理系统,采用端边云协同的轻量化架构,支持一体化的物联网时序数据收集、存储、管理与分析 ,具有多协议兼容、超高压缩比、高通量读写、工业级稳定、极简运维等特点。
| 版本 | IoTDB 二进制包 | IoTDB 源代码 | 发布说明 |
|---|---|---|---|
| 2.0.5 | - All-in-one - AINode - SHA512 - ASC | - 源代码 - SHA512 - ASC | release notes |
| 1.3.5 | - All-in-one - AINode - SHA512 - ASC | - 源代码 - SHA512 - ASC | release notes |
| 0.13.4 | - All-in-one - Grafana 连接器 - Grafana 插件 - SHA512 - ASC | - 源代码 - SHA512 - ASC | release notes |
✨ 去获取:https://archive.apache.org/dist/iotdb/
联系博主
xcLeigh 博主,全栈领域优质创作者,博客专家,目前,活跃在CSDN、微信公众号、小红书、知乎、掘金、快手、思否、微博、51CTO、B站、腾讯云开发者社区、阿里云开发者社区等平台,全网拥有几十万的粉丝,全网统一IP为 xcLeigh。希望通过我的分享,让大家能在喜悦的情况下收获到有用的知识。主要分享编程、开发工具、算法、技术学习心得等内容。很多读者评价他的文章简洁易懂,尤其对于一些复杂的技术话题,他能通过通俗的语言来解释,帮助初学者更好地理解。博客通常也会涉及一些实践经验,项目分享以及解决实际开发中遇到的问题。如果你是开发领域的初学者,或者在学习一些新的编程语言或框架,关注他的文章对你有很大帮助。
亲爱的朋友,无论前路如何漫长与崎岖,都请怀揣梦想的火种,因为在生活的广袤星空中,总有一颗属于你的璀璨星辰在熠熠生辉,静候你抵达。
愿你在这纷繁世间,能时常收获微小而确定的幸福,如春日微风轻拂面庞,所有的疲惫与烦恼都能被温柔以待,内心永远充盈着安宁与慰藉。
至此,文章已至尾声,而您的故事仍在续写,不知您对文中所叙有何独特见解?期待您在心中与我对话,开启思想的新交流。
💞 关注博主 🌀 带你实现畅游前后端!
🏰 大屏可视化 🌀 带你体验酷炫大屏!
💯 神秘个人简介 🌀 带你体验不一样得介绍!
🥇 从零到一学习Python 🌀 带你玩转Python技术流!
🏆 前沿应用深度测评 🌀 前沿AI产品热门应用在线等你来发掘!
💦 注 :本文撰写于CSDN平台 ,作者:xcLeigh (所有权归作者所有) ,https://xcleigh.blog.csdn.net/,如果相关下载没有跳转,请查看这个地址,相关链接没有跳转,皆是抄袭本文,转载请备注本文原地址。

📣 亲,码字不易,动动小手,欢迎 点赞 ➕ 收藏,如 🈶 问题请留言(或者关注下方公众号,看见后第一时间回复,还有海量编程资料等你来领!),博主看见后一定及时给您答复 💌💌💌