国产化适配鲲鹏arm环境:hive on tez 单节点部署实践总结
本文详细指导如何在已安装Java的鲲鹏服务器环境下,从下载Hadoop开始,依次配置环境变量、YARN和HDFS设置,然后安装并配置Hive数据库和tez单机版,最后验证服务运行。涉及关键步骤如配置文件和启动服务。
准备
环境要求
硬件要求
最低配置:任意CPU、一根内存(大小不限)、一块硬盘(大小不限)。
具体配置视实际应用场景而定。
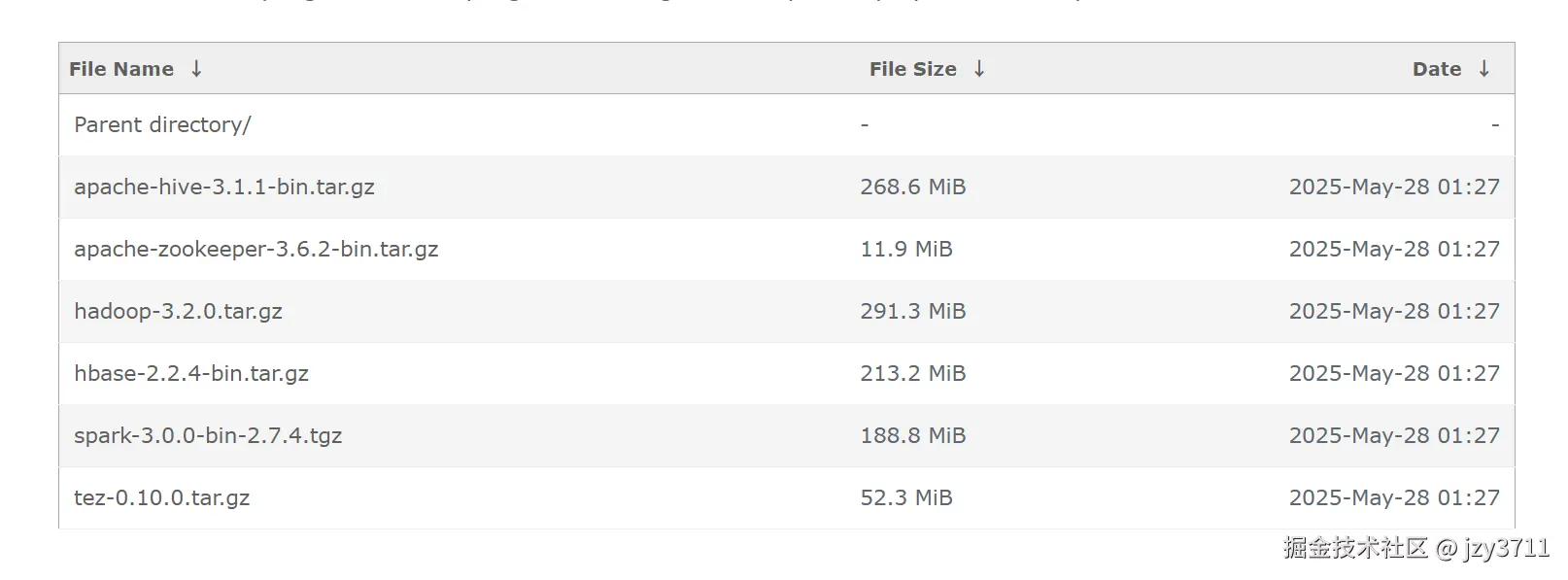
操作系统和软件要求
| 项目 | 版本 | 说明 | 管理节点(Server) | 计算/存储节点 |
|---|---|---|---|---|
| 操作系统 | - openEuler 22.03 LTS SP1 | - | √ | √ |
| JDK | BiSheng JDK 1.8(优选BiSheng JDK 1.8.0_342) | openEuler 22.03 LTS SP1与BiSheng JDK 1.8.0_262不兼容,需更换为BiSheng JDK 1.8.0_342。 | √ | √ |
部署hadoop
环境变量
shell
#hadoop
export HADOOP_HOME=/home/kpnre/software/hadoop-3.2.0
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#java
export JAVA_HOME=/home/kpnre/software/bisheng-jdk1.8.0_452
export PATH=$PATH:$JAVA_HOME/bin配置文件
/hadoop-3.2.0/etc/hadoop/hdfs-site.xml
xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- namenode web端访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>10.x.x.29:9870</value>
</property>
<property>
<name>hadoop.proxyuser.kpnre.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.kpnre.groups</name>
<value>*</value>
</property>
</configuration>hadoop-3.2.0/etc/hadoop/yarn-site.xml
xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>10.19.198.29</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>16384</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 启用 YARN 日志聚合 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间(单位:秒) -->
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
</property>
</configuration>启动hadoop
shell
start-all.sh验证
在浏览器中输入URL地址,访问Hadoop Web页面,URL格式为"http://server1:50070"。 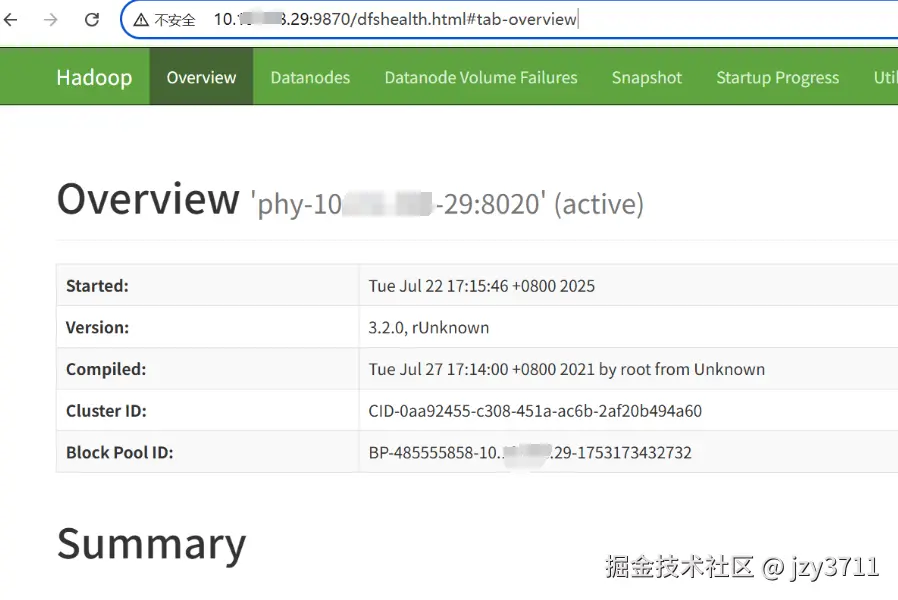
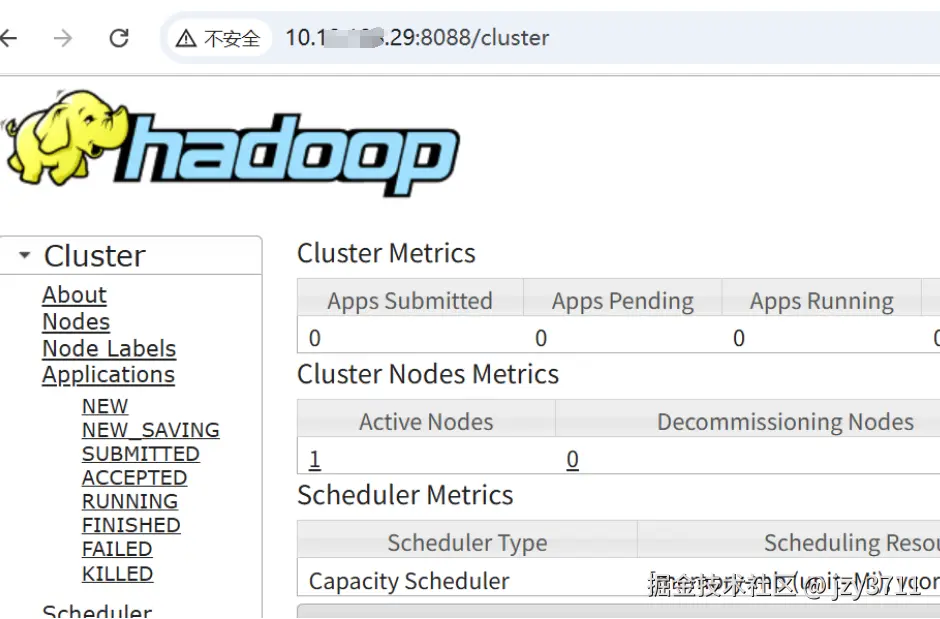
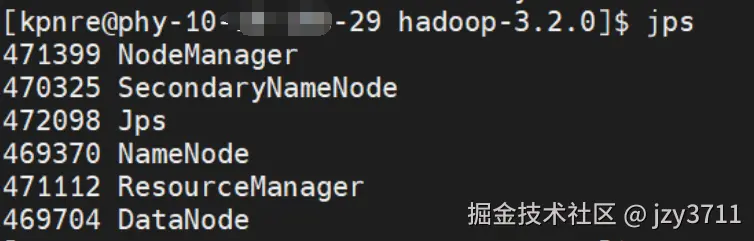
部署hive
前置条件
mysql安装完成
- 将mysql-connector-java放进lib
shell
cp /usr/share/java/mysql-connector-java-5.1.48.jar /home/kpnre/software/apache-hive-3.1.2-bin/lib && cd /home/kpnre/software/apache-hive-3.1.2-bin/lib && sudo chown hadoop:hadoop mysql-connector-java-5.1.48.jar- 配置hive云数据库
mysql
create database hive character set utf8;
grant all on hiveb.* to 'root'@'hive' identified by 'passwd';
flush privileges;- 初始化数据库
shell
cd /home/kpnre/software/apache-hive-3.1.2-bin
bin/schematool --dbType mysql --initSchema环境变量
shell
export HIVE_HOME=/home/kpnre/software/apache-hive-3.1.1-bin
export PATH=$PATH:$HIVE_HOME/bin配置文件
apache-hive-3.1.1-bin/conf/hive-site.xml
xml
<configuration>
<!-- WARNING!!! This file is auto generated for documentation purposes ONLY! -->
<!-- WARNING!!! Any changes you make to this file will be ignored by Hive. -->
<!-- WARNING!!! You must make your changes in hive-site.xml instead. -->
<!-- Hive Execution Parameters -->
<property>
<name>hive.exec.script.wrapper</name>
<value/>
<description/>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>******</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.ds.connection.url.hook</name>
<value/>
<description>Name of the hook to use for retrieving the JDO connection URL. If empty, the value in javax.jdo.option.ConnectionURL is used</description>
</property>
<property>
<name>javax.jdo.option.Multithreaded</name>
<value>true</value>
<description>Set this to true if multiple threads access metastore through JDO concurrently.</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://10.x.x.29:3306/hive?useSSL=false</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>hive.server2.thrift.client.connect.retry.limit</name>
<value>10</value>
<description>Number of retries while opening a connection to HiveServe2</description>
</property>
<property>
<name>tez.queue.name</name>
<value>default</value> <!-- 根据你的 YARN 队列名称进行设置 -->
</property>
<property>
<name>tez.session.am.dag.submit.timeout.secs</name>
<value>0</value> <!-- 根据你的资源需求设置 -->
</property>
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
</configuration>启动hive
shell
hive --service metastore &验证
-
查看端口。默认hiveserver2的端口号为10000。
perlnetstat -anp|grep 10000如下所示即为启动成功。
bashtcp6 0 0 :::10000 :::* LISTEN 27800/java -
在server1使用beeline连接。
bash``` beeline -u jdbc:hive2://server1:10000 -n root ``` 回显信息如下。 ``` SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/local/apache-hive-3.1.0-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/local/hadoop-3.1.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Connecting to jdbc:hive2://server1:10000 Connected to: Apache Hive (version 3.1.0) Driver: Hive JDBC (version 3.1.0) Transaction isolation: TRANSACTION_REPEATABLE_READ Beeline version 3.1.0 by Apache Hive 0: jdbc:hive2://server1:10000> ``` -
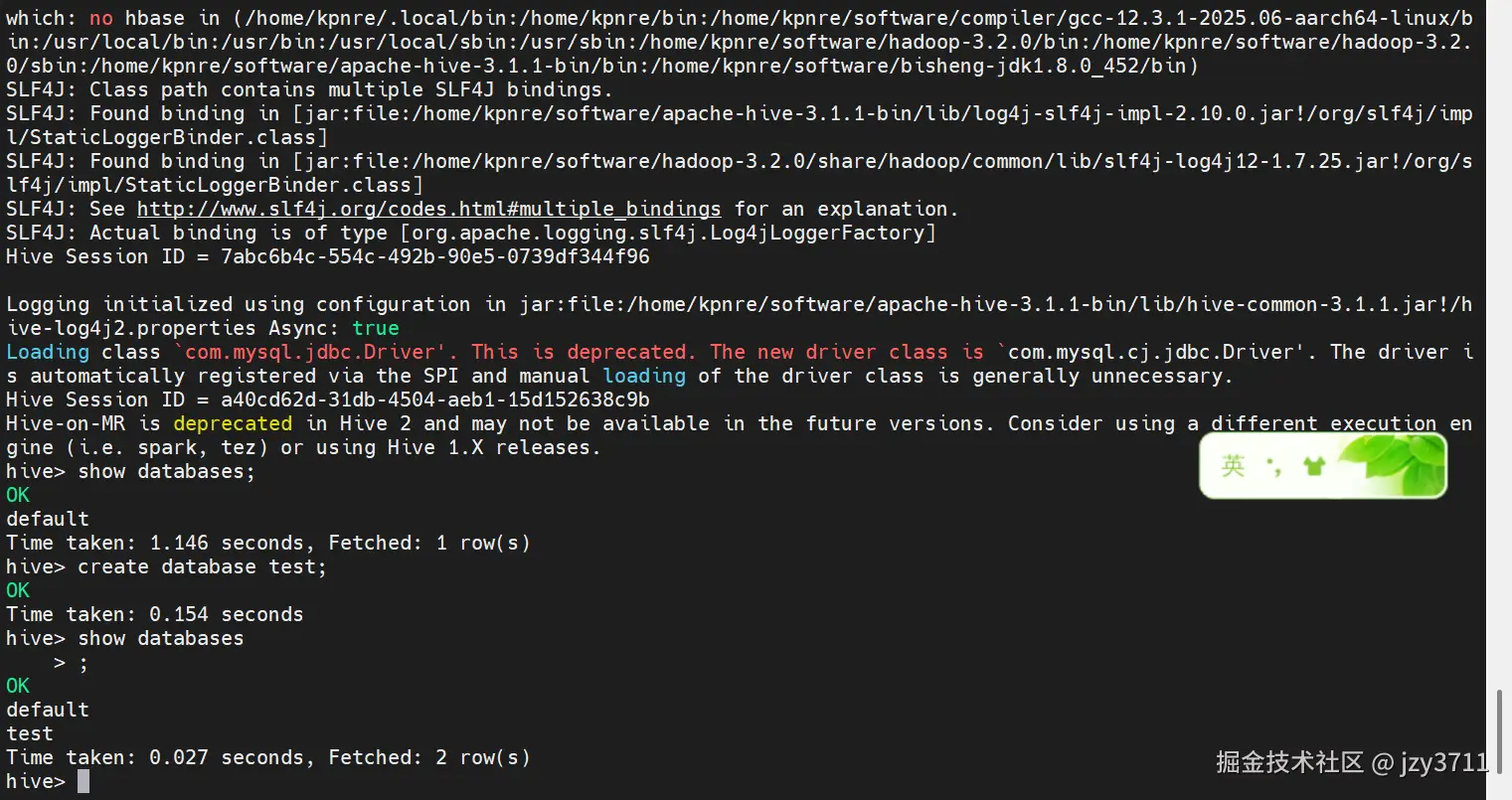
查看已创建的数据库。
inishow databases;如下所示,即Hive启动正常成功。
ini0: jdbc:hive2://server1:10000> show databases; INFO : Compiling command(queryId=root_20210118113531_49c3505a-80e1-4aba-9761-c2f77a06ac5f): show databases INFO : Concurrency mode is disabled, not creating a lock manager INFO : Semantic Analysis Completed (retrial = false) INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null) INFO : Completed compiling command(queryId=root_20210118113531_49c3505a-80e1-4aba-9761-c2f77a06ac5f); Time taken: 0.903 seconds INFO : Concurrency mode is disabled, not creating a lock manager INFO : Executing command(queryId=root_20210118113531_49c3505a-80e1-4aba-9761-c2f77a06ac5f): show databases INFO : Starting task [Stage-0:DDL] in serial mode INFO : Completed executing command(queryId=root_20210118113531_49c3505a-80e1-4aba-9761-c2f77a06ac5f); Time taken: 0.029 seconds INFO : OK INFO : Concurrency mode is disabled, not creating a lock manager +----------------+ | database_name | +----------------+ | default | +----------------+ 1 row selected (1.248 seconds)
部署tez
配置文件
hadoop-3.2.0/etc/hadoop/hadoop-env.sh
shell
export TEZ_CONF_DIR=/home/kpnre/software/tez-0.10.0/conf/tez-site.xml
export TEZ_JARS=/home/kpnre/software/tez-0.10.0
export HADOOP_CLASSPATH=${HADOOP_CLASSPATH}:${TEZ_CONF_DIR}:${TEZ_JARS}/*:${TEZ_JARS}/lib/*tez-0.10.0/conf/tez-site.xml
xml
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 注意你的路径以及文件名是否和我的一样 -->
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/tez.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>false</value>
</property>
<property>
<name>tez.am.resource.cpu.vcores</name>
<value>1</value>
</property>
<property>
<name>tez.task.resource.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>tez.task.resource.cpu.vcores</name>
<value>1</value>
</property>
<property>
<name>hive.tez.container.size</name>
<value>2048</value>
</property>
<property>
<name>tez.am.resource.memory.mb</name>
<value>2048</value>
</property>
</configuration>验证
-
使用Tez引擎。
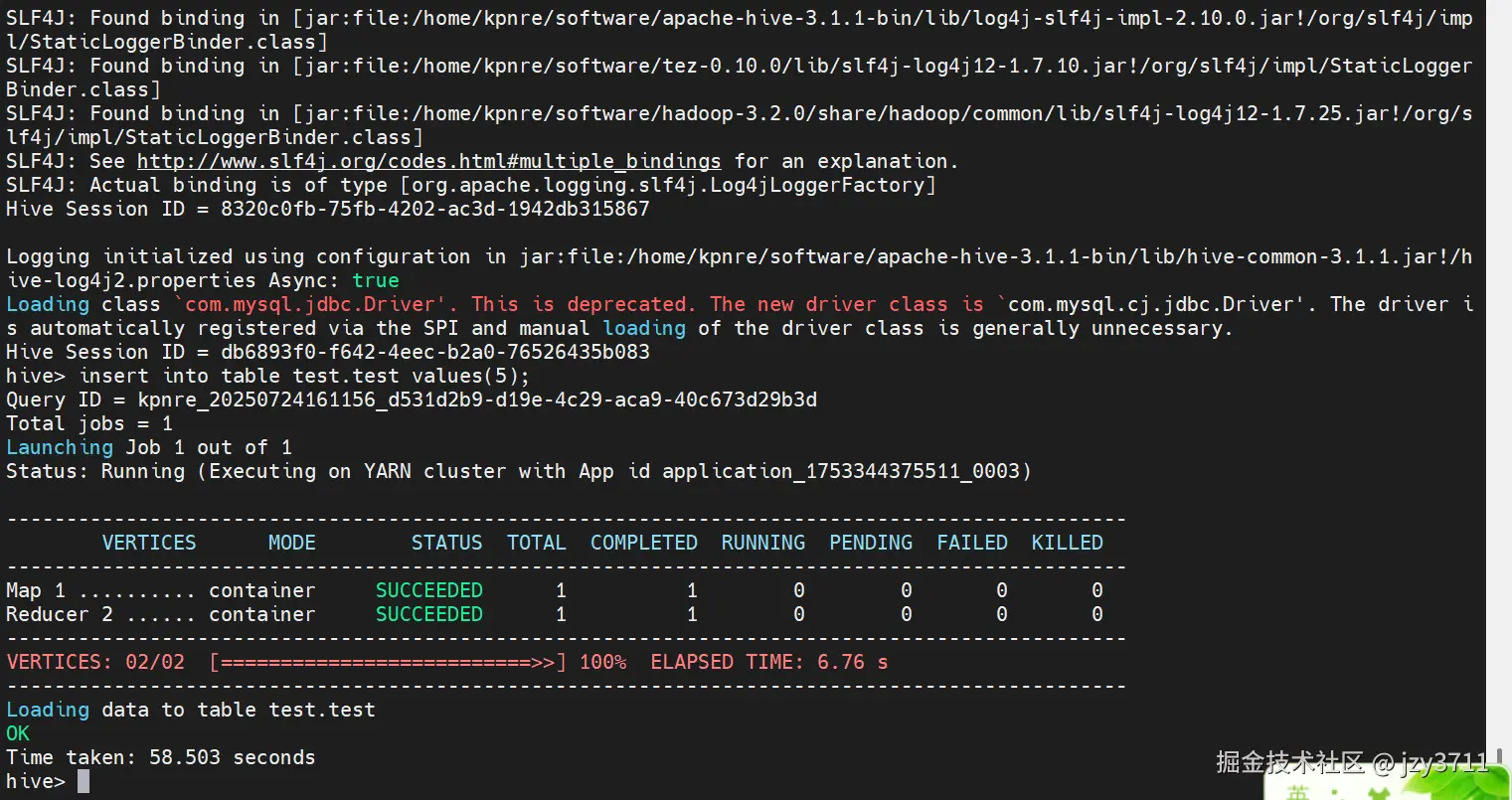
iniset hive.execution.engine=tez; -
创建student表。
ccreate table student(id int, name string); -
向表中插入数据。
sqlinsert into student values(1,"zhangsan"); insert into student values(2,"lisi"); -
查询student表,如下图所示,查询结果无误即安装成功。
csharpselect * from student;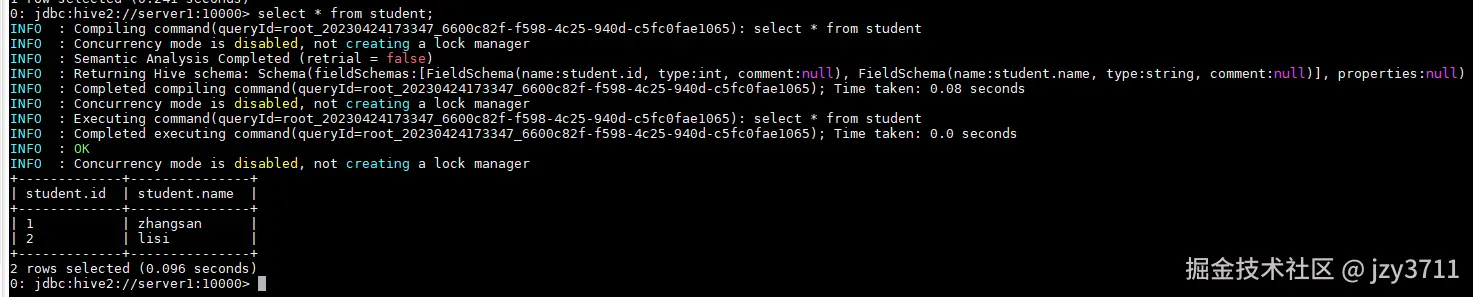
参考
hadoop+hive单机部署 鲲鹏BoostKit大数据使能套件