kafka如何保证高可用
1、消息从producer可靠的发送至broker
保证Producer 发送消息后,能够收到来自 Broker 的消息保存成功 ack;
三种ACK策略:
- Request.required.acks = 0:请求发送即认为成功,不关心有没有写成功,常用于日志进行分析场景。
- Request.required.acks = 1:当 leader partition 写入成功以后,才算写入成功,有丢数据的可能。
- Request.required.acks= -1:ISR 列表里面的所有副本都写完以后,这条消息才算写入成功,强可靠性保证。
为了实现强可靠的 kafka 系统,我们需要设置 Request.required.acks= -1,同时还会设置集群中处于正常同步状态的副本 follower 数量 min.insync.replicas>2,另外,设置 unclean.leader.election.enable=false 使得集群中 ISR 的 follower 才可变成新的 leader,避免特殊情况下消息截断的出现。
2、发送到Broker的消息可靠持久化
- Broker 返回 Producer 成功 ack 时,消息是否已经落盘?
kafka 为了获得更高吞吐,Broker 接收到消息后只是将数据写入 PageCache 后便认为消息已写入成功,而 PageCache 中的数据通过 linux 的 flusher 程序进行异步刷盘(刷盘触发条:主动调用 sync 或 fsync 函数、可用内存低于阀值、dirty data 时间达到阀值),将数据顺序写到磁盘。消息处理示意图如下:
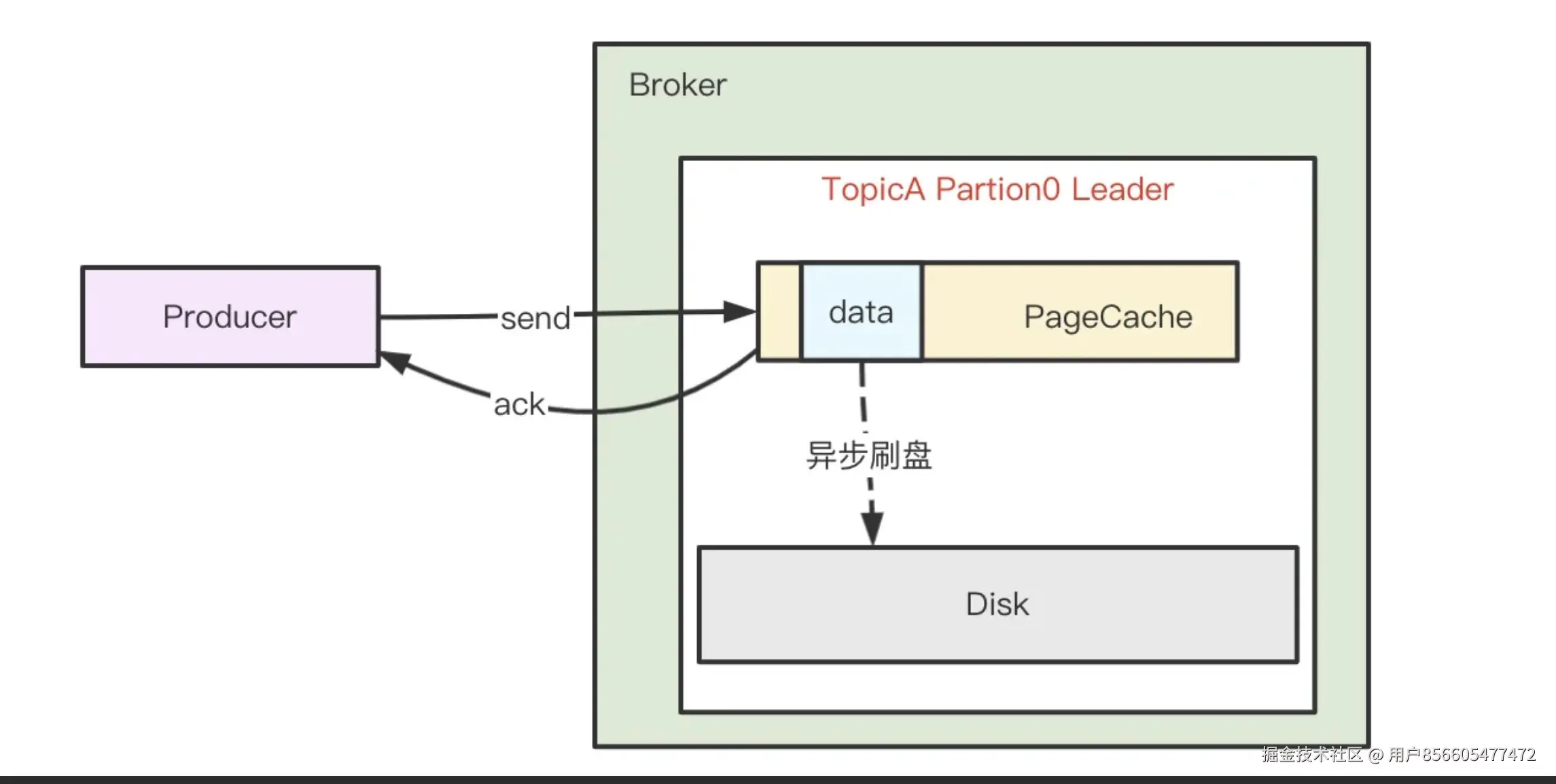
PageCache(页面缓存):
Linux内核用于缓存磁盘数据的一种内存机制,它作为文件系统与底层存储设备之间的桥梁,主要作用是平衡内存与物理磁盘之间的数据存取速率差异。
PageCache的工作原理:
- 写入缓冲:当应用程序写入文件时,数据首先被写入PageCache中的"脏页"(dirty pages),而不是直接写入磁盘
- 读取缓存:当读取文件时,内核会优先从PageCache中查找数据,若命中则无需访问磁盘
- 异步回写:内核线程(pdflush)会定期将脏页写回磁盘,保证数据最终持久化
Kafka与PageCache的关系:
Kafka高度依赖PageCache来提升性能:
- 写入路径:生产者发送的消息首先被追加到PageCache中的日志文件
- 读取路径:消费者读取消息时,直接从PageCache获取,避免磁盘I/O
- 刷盘策略 :Kafka不依赖
fsync强制刷盘,而是依靠操作系统异步刷盘机制
kafka认为消息错乱比消息丢失更为严重,所以允许消息丢失,但不允许消息错乱
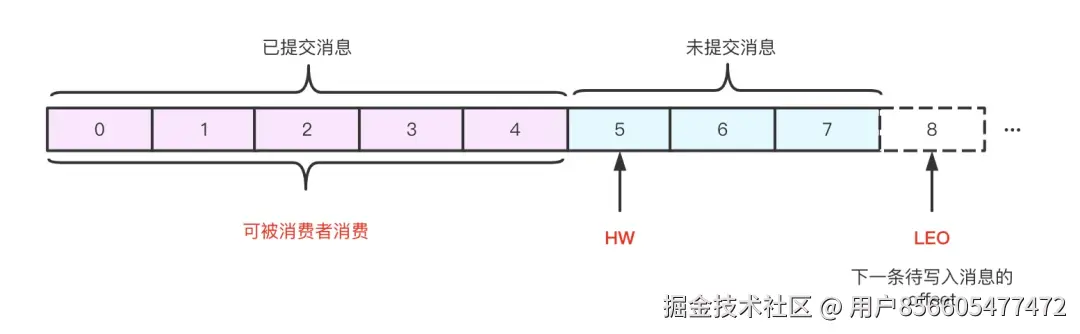
首先来看两个kafka的概念:
-
HW: High Watermark,高水位,表示已经提交(commit)的最大日志偏移量,Kafka 中某条日志"已提交"的意思是 ISR 中所有节点都包含了此条日志,并且消费者只能消费 HW 之前的数据;
-
LEO: Log End Offset,表示当前 log 文件中下一条待写入消息的 offset;
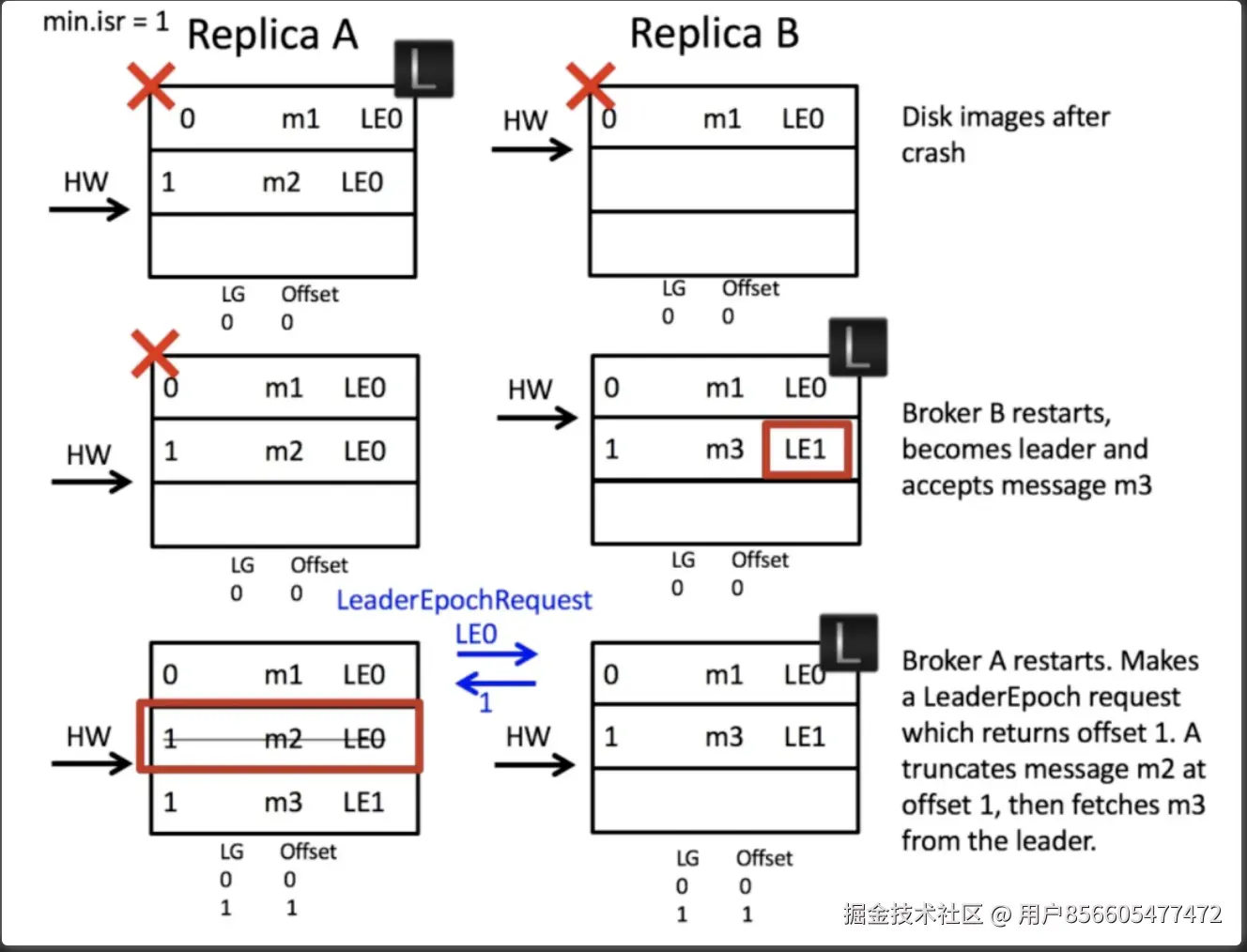
下图A是主节点,B是从节点,如果B还没来的及拉取m2这条数据A就宕机,B则会被选为leader副本,然后B收到了一条新数据m3,此时A节点重启,重启后采用Leader Epoch思想(先与leader副本进行数据同步来确定如何处理当前副本的数据),与leader副本进行数据同步后发现offset 1的位置上的数据为m3,则会丢弃掉m2,记录m3
这种消息丢失,我认为只会出现在producer的 Request.required.acks = 0 或 1 时才会出现问题,如果-1的话不会出现,因为如果B没写入A就挂掉,producer应该会重试
但是即使Request.required.acks = -1,极端情况下主从副本全部写入pageCache,然后全部宕机,数据依然会丢失,且producer会收到写入成功的返回值
总结: Broker 接收到消息后只是将数据写入 PageCache 后便认为消息已写入成功,但是,通过副本机制并结合 ACK 策略可以大概率规避单机宕机带来的数据丢失问题,并通过 HW、副本同步机制、 Leader Epoch 等多种措施解决了多副本间数据同步一致性问题,最终实现了 Broker 数据的可靠持久化。
3、消费者从kafka消费消息
enable.auto.commit = true,消费者拉取数据后,会间隔一段时间(默认5s),自动提交偏移量,如果逻辑没有处理完成,消费者崩溃,未处理的消息就会丢失
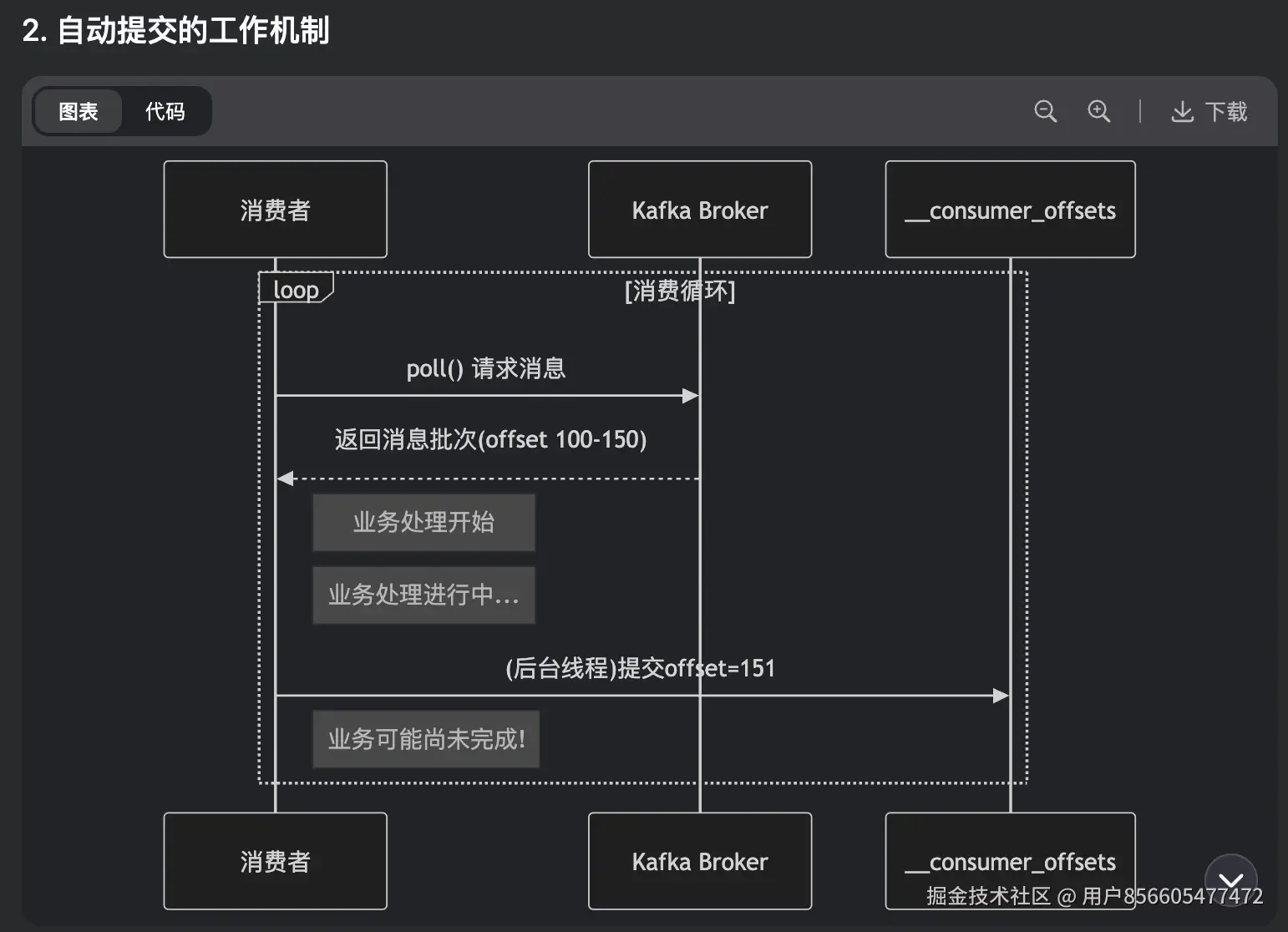
如果想要精准消费,保证消息不丢失,应该使用手动提交偏移量的方式,auto.commit = false,而且消费逻辑需要支持幂等。
kafka高性能探究
零拷贝技术:
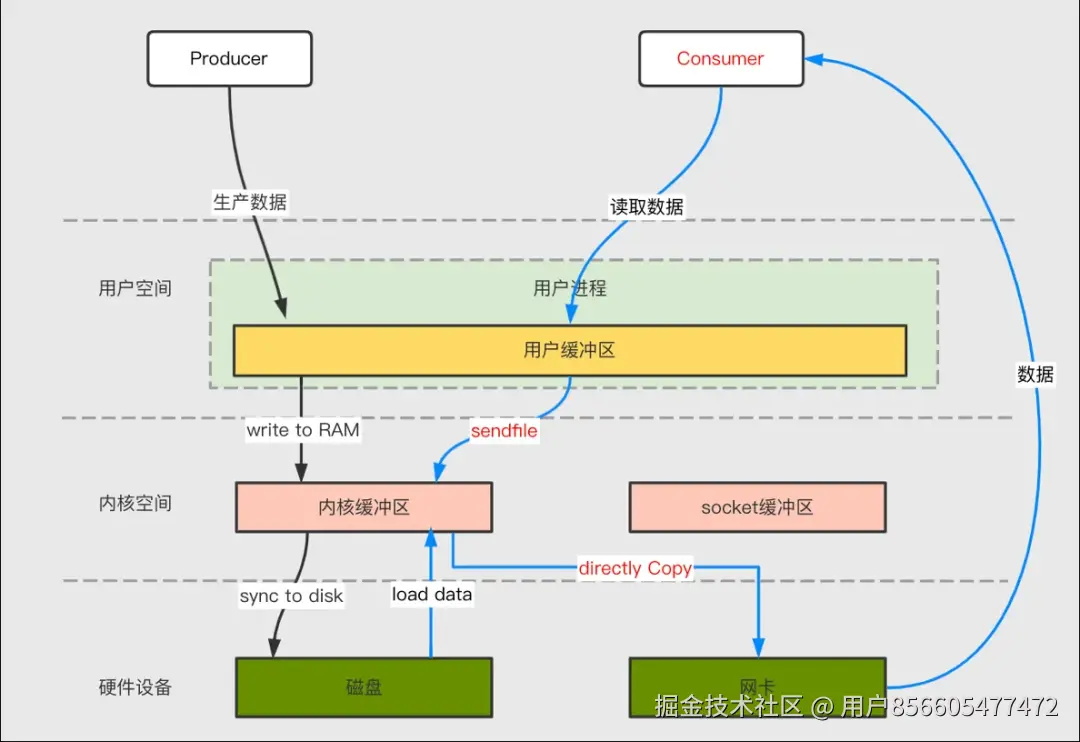
Kafka 中存在大量的网络数据持久化到磁盘(Producer 到 Broker)和磁盘文件通过网络发送(Broker 到 Consumer)的过程,这一过程的性能直接影响 Kafka 的整体吞吐量。传统的 IO 操作存在多次数据拷贝和上下文切换,性能比较低。Kafka 利用零拷贝技术提升上述过程性能,其中网络数据持久化磁盘主要用mmap技术,网络数据传输环节主要使用 sendfile 技术。
索引加速之 mmap
传统模式下,数据从网络传输到文件需要 4 次数据拷贝、4 次上下文切换和两次系统调用。如下图所示:
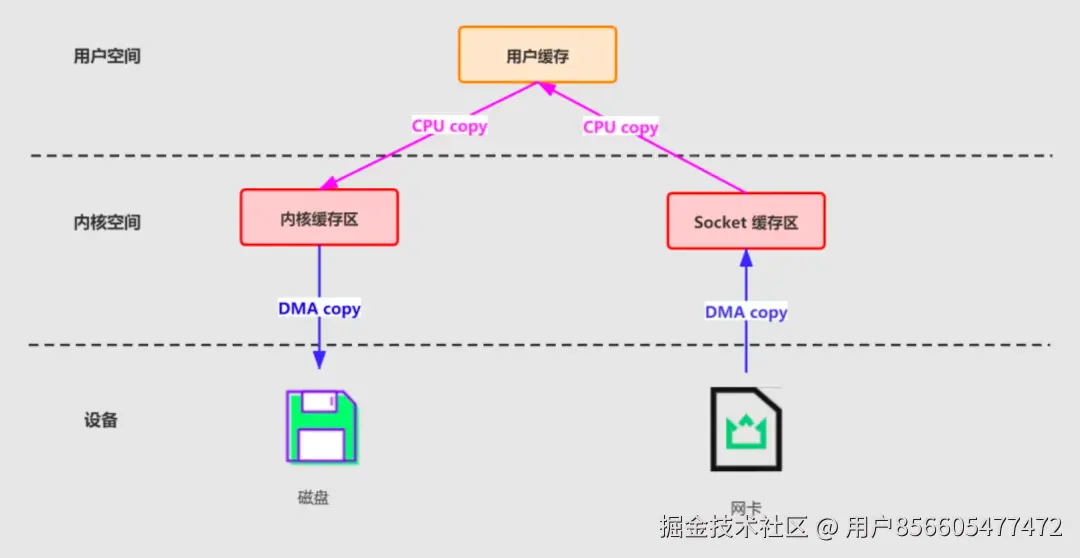
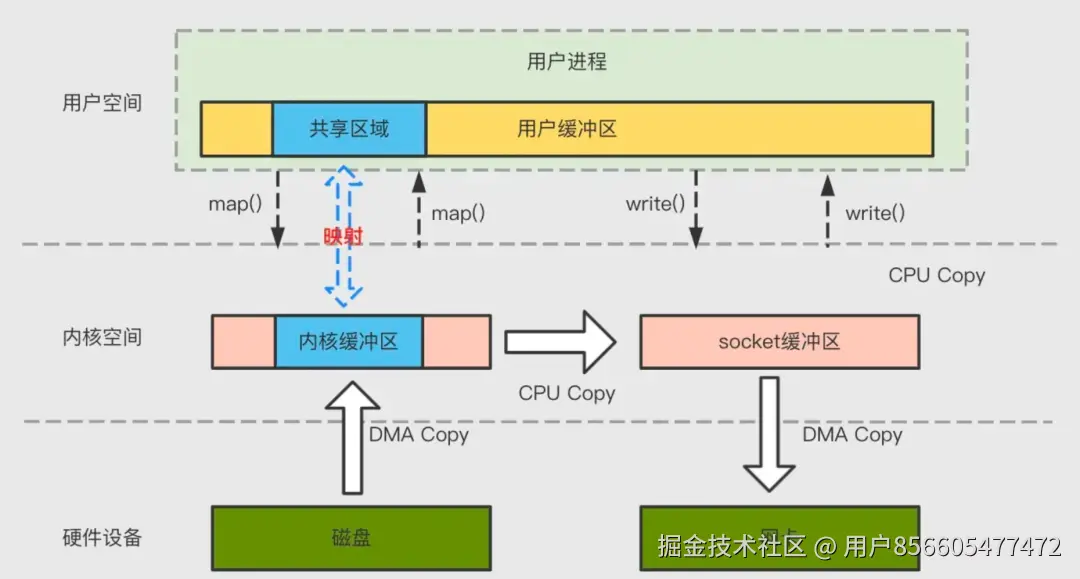
为了减少上下文切换以及数据拷贝带来的性能开销,Kafka使用mmap来处理其索引文件。Kafka中的索引文件用于在提取日志文件中的消息时进行高效查找。这些索引文件被维护为内存映射文件,这允许Kafka快速访问和搜索内存中的索引,从而加速在日志文件中定位消息的过程。mmap 将内核中读缓冲区(read buffer)的地址与用户空间的缓冲区(user buffer)进行映射,从而实现内核缓冲区与应用程序内存的共享,省去了将数据从内核读缓冲区(read buffer)拷贝到用户缓冲区(user buffer)的过程,整个拷贝过程会发生 4 次上下文切换,1 次 CPU 拷贝和 2次 DMA 拷贝。
网络数据传输之 sendfile
传统方式实现:先读取磁盘、再用 socket 发送,实际也是进过四次 copy。如下图所示:
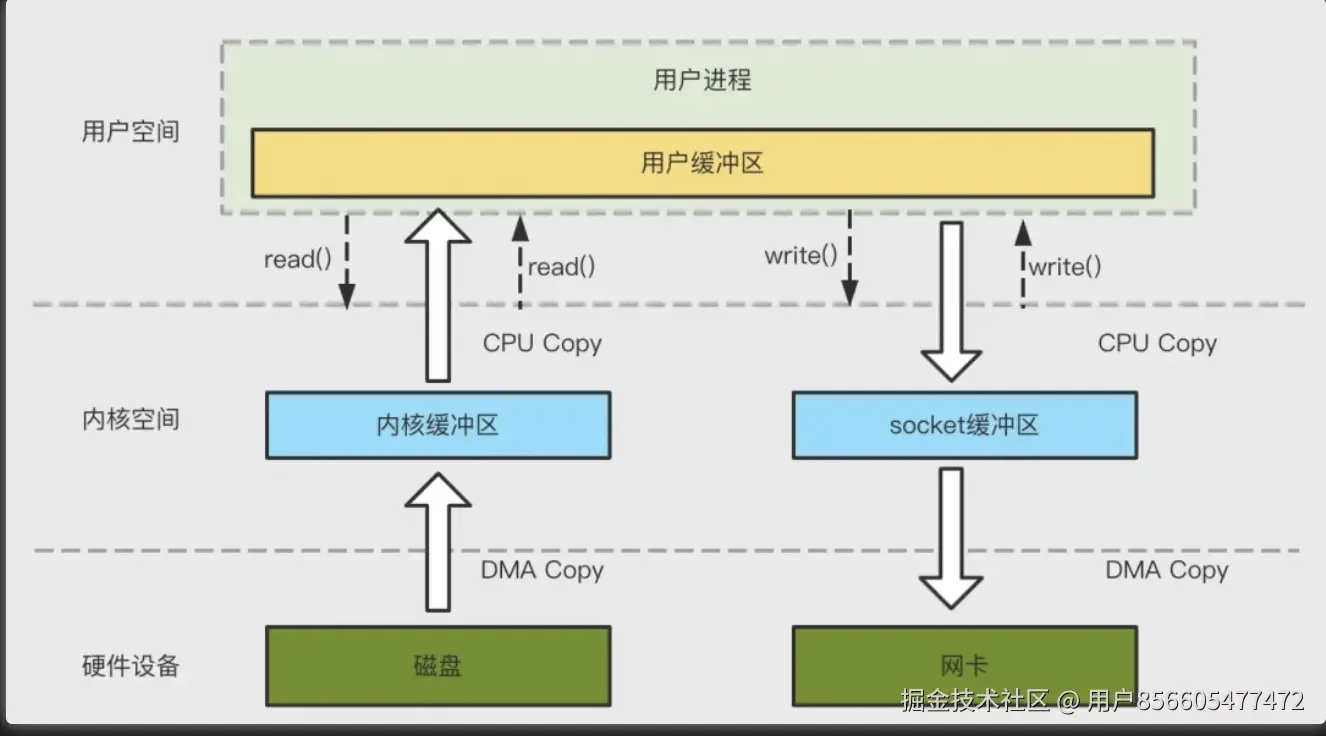
为了减少上下文切换以及数据拷贝带来的性能开销,Kafka 在 Consumer 从 Broker 读数据过程中使用了 sendfile 技术。具体在这里采用的方案是通过 NIO 的 transferTo/transferFrom 调用操作系统的 sendfile 实现零拷贝。总共发生 2 次内核数据拷贝、2 次上下文切换和一次系统调用,消除了 CPU 数据拷贝,如下: