快到年底了,系统频繁出问题。我有正当理由怀疑老板不想发年终奖所以搞事。
这不,几年都遇不到的消息队列积压现象今晚又卷土重来了。
今晚注定是个不眠夜了,原神启动。。。

组里的小伙伴火急火燎找到我说,Kafka 的消息积压一直在涨,预览图一直出不来。我加了几个服务实例,刚开始可以消费,后面消费着也卡住了。
本来刚刚下班的我就比较疲惫,想让他撤回镜像明天再上。不成想组长不讲武德,直接开了个飞书视频。
我当时本来不想理他,我已经下班了,别人上线的功能出问题关我啥事。

后来他趁我不注意搞偷袭,给我私信了,我当时没多想就点开了飞书。
本来以传统功夫的点到为止,我进入飞书不点开他的会话,是能看他给我发的最后一句话的。

我把手放在他那个会话上就是没点开,已读不回这种事做多了不好。我笑了一下,准备洗洗睡了。
正在我收手不点的时候,他突然给我来了一个电话,我大意了啊,没有挂,还强行接了他的电话。两分多钟以后就好了,我说小伙子你不讲武德。
直接喊话,今晚必须解决,大家都点咖啡算他的。
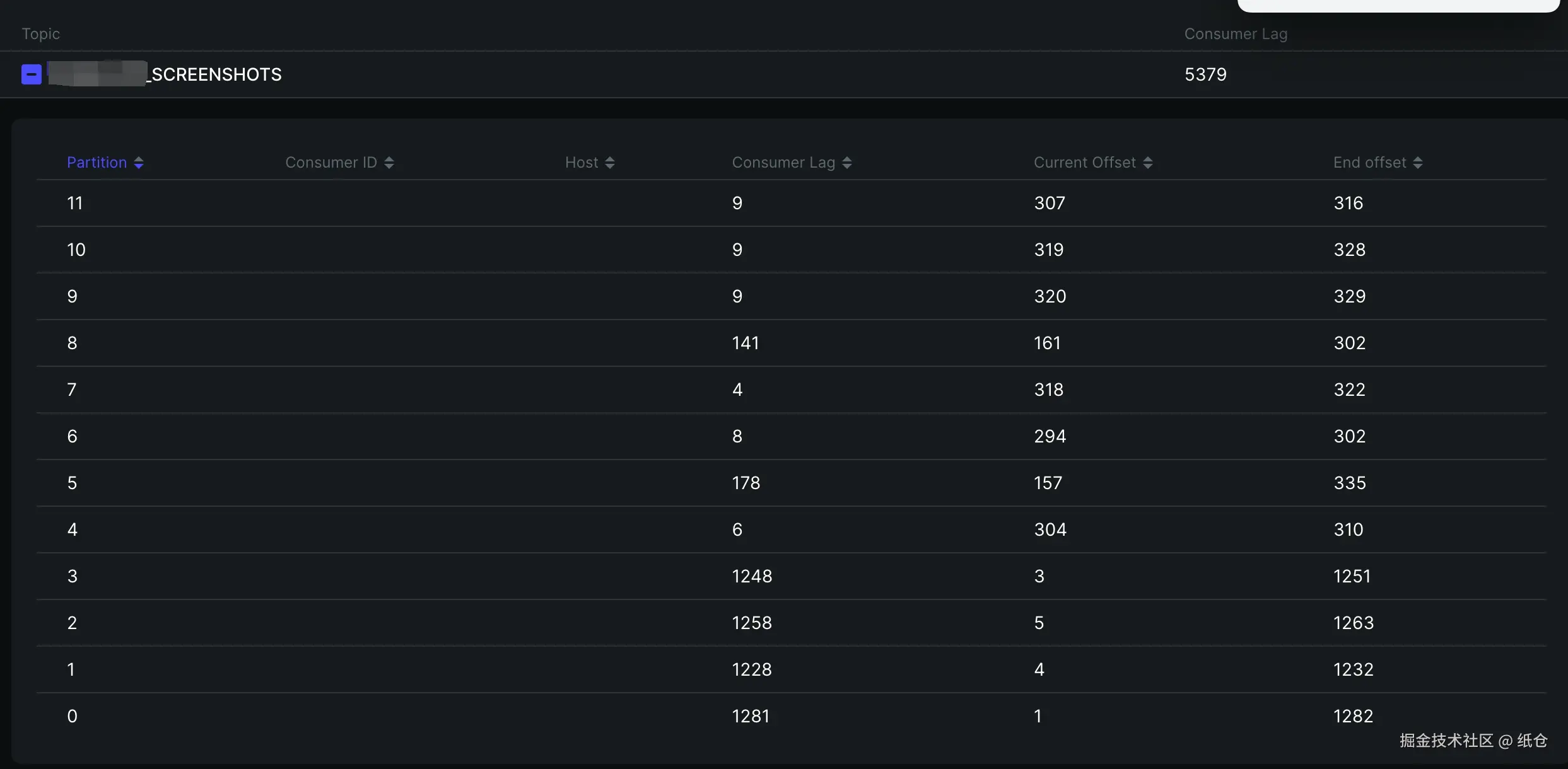
 这真没办法,都找上门来了。只能跟着查一下,早点解决早点睡觉。然后我就上 Kafka 面板一看:最初的4个分区已经积压了 1200 条,后面新加的分区也开始积压了,而且积压的速度越来越快。
这真没办法,都找上门来了。只能跟着查一下,早点解决早点睡觉。然后我就上 Kafka 面板一看:最初的4个分区已经积压了 1200 条,后面新加的分区也开始积压了,而且积压的速度越来越快。
搞清楚发生了什么?我们就得思考一下导致积压的原因。一般是消费者代码执行出错了,导致某条消息消费不了。
所以某个点卡住了,然后又有新的消息进来。
Kafka 是通过 offset 机制来标记消息是否消费过的,所以如果分区中有某一条消息消费失败,就会导致后面的没机会消费。
我用的是spring cloud stream 来处理消息队列的发送和监听。代码上是每次处理一条消息,而且代码还在处理的过程中加了 try-catch。监听器链路打印的日志显示执行成功了,try-catch也没有捕捉到任何的异常。
这一看,我就以为是消费者性能不足,突然想起 SpringCloudStream 好像有个多线程消费的机制。立马让开发老哥试试,看看能不能就这样解决了,我困得不行。

我半眯着眼睛被提醒吵醒了。开发老哥把多线程改成10之后,发现积压更快了,而且还有pod会挂。老哥查了一下多线程的配置 concurrency。
原来指的是消费者线程,一个消费者线程会负责处理一个分区。对于我们来说,增加之后可能会导致严重的流量倾斜,难怪pod会挂掉,赶紧恢复了回去。
看来想糊弄过去是不行了,我把pod运行的日志全部拉下来。查了一下日志,日志显示执行成功了,但同时有超时错误,这就见了鬼了。
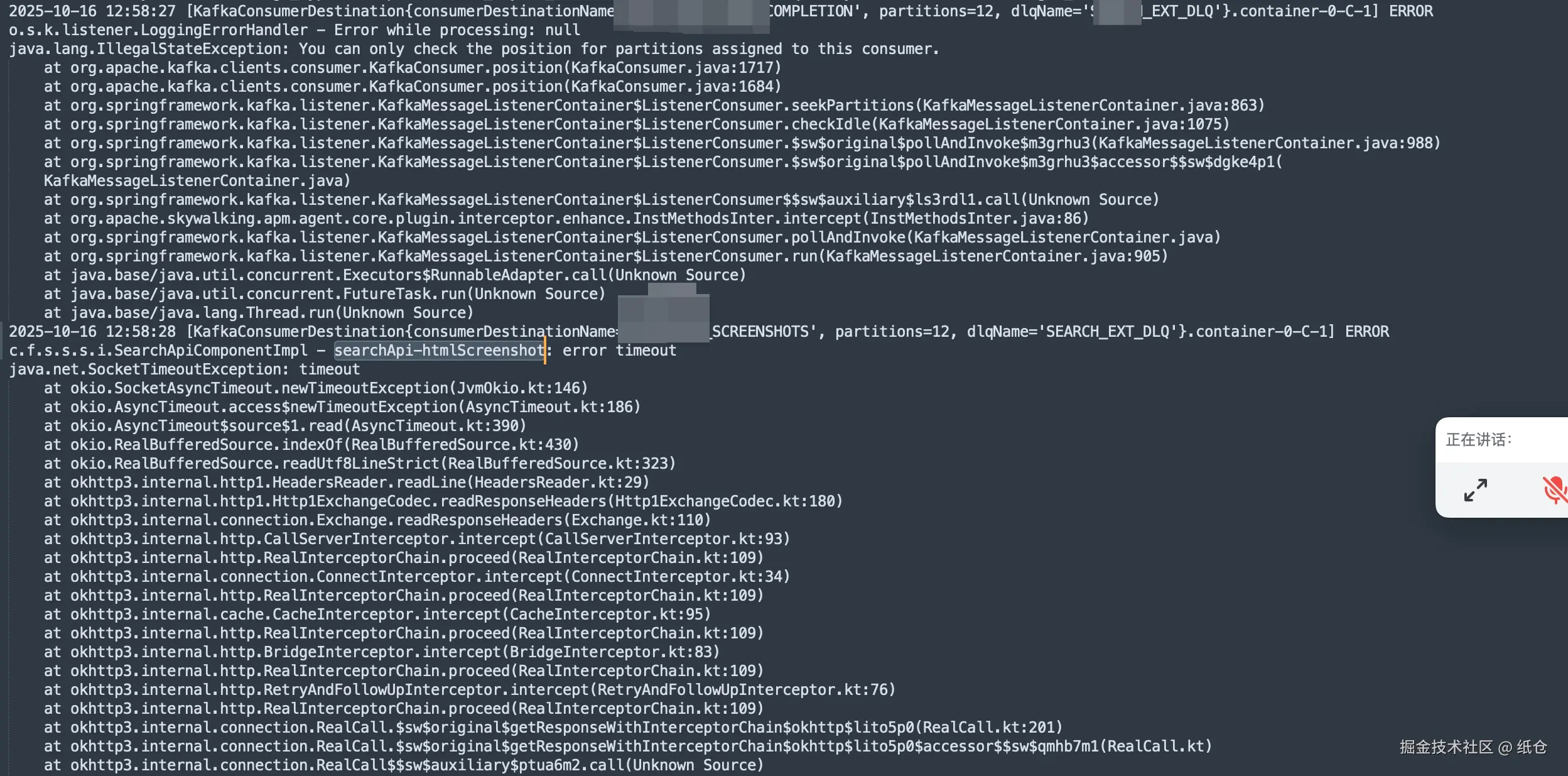
作为一个坚定的唯物主义者,我是不信见鬼的。但此刻我汗毛倒竖,吓得不敢再看屏幕一眼。

但是内心又觉得不甘心,于是我偷偷瞄了一眼屏幕。不看还好,一喵你猜我发现了啥?
消费者组重平衡了,这就像是在黑暗中有一束光照向了我,猪八戒发现嫦娥原来一直暗恋自己,我的女神其实不需要拉屎。
有了重平衡就好说了,无非就是两种情况,一是服务挂掉了,二是服务消费者执行超时了。现在看来服务没有挂,那就是超时了,也正好和上面的日志能对上。

那怎么又看到监听器执行的结果是正常的呢?
这就得从 Kafka 的批量拉取机制说起了,这货和我们人类直觉上的的队列机制不太一样。我们一般理解的队列是发送一个消息给队列,然后队列就异步把这消息给消费者。但是这货是消费者主动去拉取一批来消费。
然后好死不死,SpringCloudStream 为了封装得好用符合人类的认知,就做成了一般理解的队列那种方式。
SpringCloudStream 一批拉了500条记录,然后提供了一个监听器接口让我们实现。入参是一个对象,也就是500条数据中的一条,而不是一个数组。

我们假设这500条数据的ID是 001-500,每一条数据对应的消费者需要执行10s。那么总共就需要500 x 10s=5000s。
再假设消费者执行的超时时间是 300s,而且消费者执行的过程是串行的。那么500条中最多只能执行30条,这就能解释为什么看消费链路是正常的,但是还超时。
因为单次消费确实成功了,但是批次消费也确实超时了。
我咧个豆,破案了。

于是我就想到了两种方式来处理这个问题:第一是改成单条消息消费完立马确认,第二是把批次拉取的数据量改小一点。
第一种方案挺好的,就是性能肯定没有批量那么好,不然你以为 Kafka 的吞吐量能薄纱ActiveMQ这些传统队列。吞吐量都是小事,这个方案胜在可以立马去睡觉了。只需要改一个配置:ack-mode: RECORD
第二种方案是后来提的,其实单单把批次拉取的数据量改小性能提升还不是很明显。不过既然我们都能拿到一批数据了,那多线程安排上就得了。
先改配置,一次只拉取50条 max.poll.records: 50。然后启用线程池处理,完美!
java
@StreamListener("<TOPIC>")
public void consume(List<byte[]> payloads) {
List<CompletableFuture<Void>> futures = payloads.stream().map(bytes -> {
Payload payload = JacksonSnakeCaseUtils.parseJson(new String(bytes), Payload.class);
return CompletableFuture.runAsync(() -> {
// ........
}, batchConsumeExecutor).exceptionally(e -> {
log.error("Thread error {}", bytes, e);
return null;
});
}).collect(Collectors.toList());
try {
// 等待这批消息中的所有任务全部完成
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
errorMessage = "OK";
} catch (Exception e) {
errorMessage = "Ex: " + e.getMessage();
} finally {
// ...
}
}