👋 大家好,我是十三!
Make Open Source Great Again! 字节在上个月将 AI IDE 平台 Trae Agent 项目开源后,在上周又将 AI Agent 平台 Coze Studio 开源了!作为主要使用 Golang 的服务端研发,对其后端代码产生了浓厚的兴趣,为此我花了一周的时间对其一探究竟。
在 AI Agent 与大模型应用蓬勃发展的今天,软件系统的复杂性与日俱增。在这样的背景下,一个清晰、健壮且易于演进的软件架构便是决定项目成败的基石。 DDD(领域驱动设计)与整洁架构(Clean Architecture)的组合,正是应对这种高度复杂性的强大武器。它们共同倡导"关注点分离"与"高内聚、低耦合"的核心理念,而 Coze Studio 正是基于 DDD 原则架构设计。
接下来我将探讨 Coze Studio 一个生产级的 AI Agent 平台是如何划分业务边界的?它的核心领域模型长什么样?以及一条用户请求是如何在清晰的层次间优雅地流转?
1. 宏观蓝图:整洁架构的分层艺术
整洁架构,由 Robert C. Martin 提出,其核心思想通过一个经典的"洋葱图"来体现。
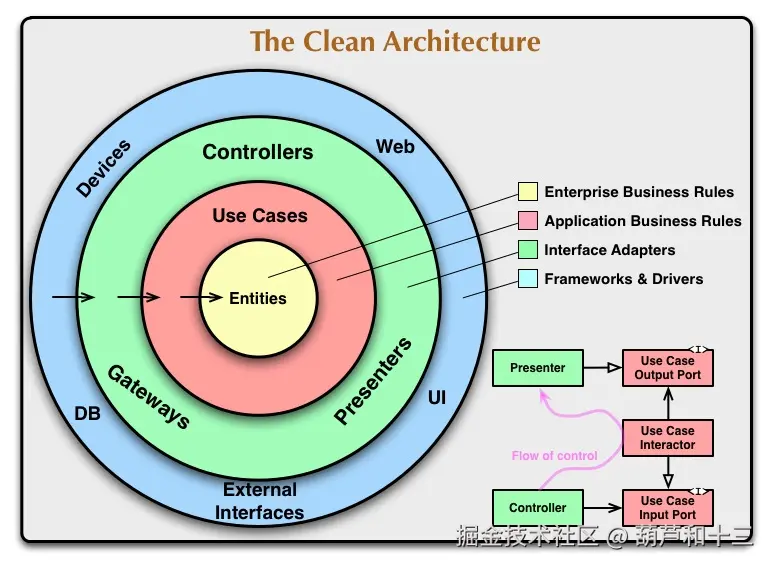
其关键原则是依赖关系规则:源码依赖关系必须只指向内部,即层级越高的(越靠近业务核心),越不应该知道层级越低的(越靠近具体实现)的任何信息。
Coze Studio 的后端项目结构,完美地诠释了这一思想。
bash
coze-studio/backend/
├── api/ # 接口层 (Interface Adapters)
├── application/ # 应用层 (Application Business Rules)
├── domain/ # 领域层 (Enterprise Business Rules)
└── infra/ # 基础设施层 (Frameworks & Drivers)这四个核心目录,清晰地对应了整洁架构的四层模型:
domain(领域层):系统的灵魂。它包含了企业级的业务规则和领域模型(实体、聚合、值对象、领域服务),是整个系统最核心、最稳定的部分。它不依赖于任何其他层。application(应用层):编排领域对象以执行具体的应用场景(用例)。它依赖于领域层的接口,但不知道任何关于 UI 或数据库的实现细节。api(接口层):作为应用的入口,负责适配和转换外部输入(如 HTTP 请求、RPC 调用)并传递给应用层。它依赖于应用层。infra(基础设施层):提供所有与外部世界交互的具体实现,如数据库访问、文件系统、第三方服务客户端等。这一层实现了领域层和应用层定义的接口,是整个系统中最容易变化的部分。
这种分层使得业务逻辑与技术实现彻底解耦,带来了极高的可测试性、可维护性和灵活性。
2. 深入领域层:DDD 的战略与战术设计
DDD 的精髓在于将业务复杂性封装在领域模型中。Coze Studio 的 domain 目录为我们提供了一个绝佳的学习范本。
2.1 限界上下文 (Bounded Context)
DDD 的战略设计核心在于识别业务边界,划分出不同的"限界上下文"。在 Coze Studio 中,domain 目录下的子目录清晰地体现了这一点:
bash
domain/
├── agent/
├── conversation/
├── knowledge/
├── memory/
├── plugin/
├── user/
└── workflow/
...每一个子目录(如 conversation, workflow)都代表一个相对独立的业务领域。这种划分使得每个模块都可以高度内聚,拥有自己专属的术语和模型,极大地降低了整个系统的认知复杂度。
2.2 聚合、实体与仓储
让我们以核心的 conversation 限界上下文为例,深入其战术设计的细节。
实体 (Entity)
Conversation 实体的定义被放在一个 crossdomain(跨域)的包中,说明它是一个被多个限界上下文共享的核心模型。
go
// file: coze-studio/backend/api/model/crossdomain/conversation/conversation.go
type Conversation struct {
ID int64 `json:"id"`
SectionID int64 `json:"section_id"`
AgentID int64 `json:"agent_id"`
ConnectorID int64 `json:"connector_id"`
CreatorID int64 `json:"creator_id"`
Scene common.Scene `json:"scene"`
Status ConversationStatus `json:"status"`
Ext string `json:"ext"`
CreatedAt int64 `json:"created_at"`
UpdatedAt int64 `json:"updated_at"`
}这个结构体非常"干净",它只包含了数据属性。值得注意的是,它通过 AgentID、CreatorID 等字段来关联其他聚合,但只保存其 ID,而非整个对象,这正是 DDD 的最佳实践,确保了聚合边界的清晰。
仓储接口 (Repository Interface)
领域模型如何被持久化?答案是通过仓储。领域层只定义仓储的接口,而不关心其实现。
go
// file: coze-studio/backend/domain/conversation/conversation/repository/repository.go
type ConversationRepo interface {
Create(ctx context.Context, msg *entity.Conversation) (*entity.Conversation, error)
GetByID(ctx context.Context, id int64) (*entity.Conversation, error)
UpdateSection(ctx context.Context, id int64) (int64, error)
Delete(ctx context.Context, id int64) error
List(ctx context.Context, req *entity.ListMeta) ([]*entity.Conversation, bool, error)
}这个 ConversationRepo 接口就是领域层与基础设施层之间的"契约",它定义了所有对 Conversation 聚合的持久化操作。
领域服务 (Domain Service)
复杂的业务逻辑不适合放在实体中,而是应该由领域服务来承担。
go
// file: coze-studio/backend/domain/conversation/conversation/service/conversation.go
type Conversation interface {
Create(ctx context.Context, req *entity.CreateMeta) (*entity.Conversation, error)
GetByID(ctx context.Context, id int64) (*entity.Conversation, error)
NewConversationCtx(ctx context.Context, req *entity.NewConversationCtxRequest) (*entity.NewConversationCtxResponse, error)
Delete(ctx context.Context, id int64) error
List(ctx context.Context, req *entity.ListMeta) ([]*entity.Conversation, bool, error)
GetCurrentConversation(ctx context.Context, req *entity.GetCurrent) (*entity.Conversation, error)
}应用层的代码将通过调用这个 Conversation 服务接口来执行业务逻辑,而无需关心其内部实现的复杂性。
"贫血"还是"充血"?Coze Studio 的选择与权衡
一个反常识的设计:Coze Studio 采用的是典型的"贫血领域模型"(Anemic Domain Model)------即 Conversation 实体本身只包含数据和 getter/setter,所有的业务逻辑都放在了领域服务 ConversationService 中。
这与经典的、推崇"充血领域模型"(Rich Domain Model)的 DDD 思想有所不同。"充血模型"强调数据和操作应该内聚在同一个实体对象中。
那么,Coze Studio 为何做出这样的选择呢?我觉得这是一种务实的权衡:
- 简单性和可测试性:贫血模型 + 领域服务的组合,逻辑清晰,结构简单。领域服务是无状态的,其依赖通过接口注入,非常容易进行单元测试。而充血模型中,业务逻辑分散在各个实体中,可能会导致更复杂的依赖关系和测试难度。
- 避免 ORM 复杂性:充血模型常常需要处理复杂的对象生命周期、懒加载、事务边界等问题,这会极大地增加 ORM 的使用难度。贫血模型则让数据持久化变得非常直接和可控。
因此,Coze Studio 的架构选择,是在遵循 DDD 核心思想(限界上下文、分层)的同时,根据其技术栈(Go)和工程化需求,做出的一种权衡。
3. 串联各层:一次请求的生命周期
让我们以"创建一次会话"为例,描绘一个请求在 Coze Studio 各层之间流转的完整路径:
-
接口层 (
api):- 用户的 HTTP POST 请求
POST /v1/conversation/create首先到达api/router/coze/api.go中定义的路由。 - 路由将请求分发给
api/handler/coze/目录下的CreateConversation处理函数。 - Handler 函数负责解析请求参数,然后调用应用层的服务。
- 用户的 HTTP POST 请求
-
应用层 (
application):- 在
application/conversation/目录下,有一个用例(UseCase)或应用服务。 - 它接收到来自 Handler 的调用,然后调用领域服务 的
Create方法来执行核心业务逻辑。
- 在
-
领域层 (
domain):domain/conversation/conversation/service/conversation_impl.go中的Create方法被执行。- 它可能会进行一系列业务规则校验。
- 然后,它调用
ConversationRepo接口 的Create方法,请求持久化新的Conversation实体。
-
基础设施层 (
infra):infra层提供了ConversationRepo接口的具体实现,例如infra/impl/mysql/conversation_repo.go(路径为推测)。- 这个实现类使用 GORM(从代码依赖中可知)将
Conversation实体对象转换为数据库记录,并将其插入到 MySQL 表中。 - 执行结果沿着调用链一路返回,最终由接口层的 Handler 封装成 HTTP 响应返回给用户。
这个流程清晰地展示了依赖倒置的威力:每一层都只依赖于其内部的接口,而不知道外部的具体实现,从而实现了完美的解耦。
4. 解耦的艺术:infra 中的 contract 与 impl
Coze Studio 在 infra 层以及其他很多地方,都采用了 contract(契约,即接口)和 impl(实现)分离的模式,这是将解耦思想贯彻到底的体现。
bash
infra/
├── contract/ # 定义基础设施需要实现的接口
└── impl/ # 提供这些接口的具体技术实现例如,领域层可能需要一个 ID 生成器,于是在 domain 层或 infra/contract 中会定义一个 IDGenerator 接口。而 infra/impl/idgen/ 目录下则会提供一个基于某种算法(如雪花算法)的具体实现。
这种方式使得切换技术栈变得异常容易。如果未来决定将 ID 生成策略从雪花算法换成分布式的 UUID,只需要在 infra/impl 中提供一个新的实现,而上层的业务代码一行都不需要改动。
结论:架构是艺术品的地基
Coze Studio 的后端架构让我学到了一种新的 DDD 与整洁架构在 Go 语言中的具体落地方式,好的架构从来不是过度设计,而是对业务复杂性恰如其分的掌控与驾驭。 我觉得 Code Studio 的源码无疑是一份极具价值的、可以反复学习的艺术工程。
👨💻 关于十三Tech
资深服务端研发工程师,AI 编程实践者。
专注分享真实的技术实践经验,相信 AI 是程序员的最佳搭档。
希望能和大家一起写出更优雅的代码!
📧 联系方式 :569893882@qq.com
🌟 GitHub :@TriTechAI