在大数据和实时流处理领域,Kafka是当之无愧的"流量枢纽"。从日志收集(如ELK栈)到实时数据分析(如Flink+Kafka),再到数据管道(跨系统数据同步),Kafka以"百万级TPS、TB级存储、毫秒级延迟"的特性,成为分布式系统中连接数据生产者和消费者的核心中间件。
本文从核心架构、消息流转流程、高吞吐原理到实战避坑,全面拆解Kafka的底层逻辑,帮你从"会用producer/consumer"到"懂分区、调副本、解决积压",真正掌握这个流处理时代的"基础设施"。
一、先搞懂:Kafka是什么?为什么非它不可?
Kafka是一个分布式流处理平台 ,核心定位是"高吞吐、高可靠的分布式消息队列",但不止于此------它还能作为"流处理引擎"(通过Kafka Streams)实时处理数据。其核心优势可用"三高一大"概括:
- 高吞吐:单机可轻松支撑每秒数十万条消息,集群模式下突破百万TPS;
- 高可靠:通过副本机制确保消息不丢失,支持数据持久化到磁盘;
- 高扩展:分区和集群可水平扩展,新增节点即可提升容量和性能;
- 大存储:消息按日志文件持久化,支持TB级甚至PB级数据存储,且可配置保留策略(如保留7天)。
一句话总结:Kafka是"为大数据场景设计的分布式流平台",尤其适合日志收集、实时分析、数据同步等"高吞吐、大容量"场景,这也是它在互联网、金融、物联网等领域被广泛采用的核心原因。
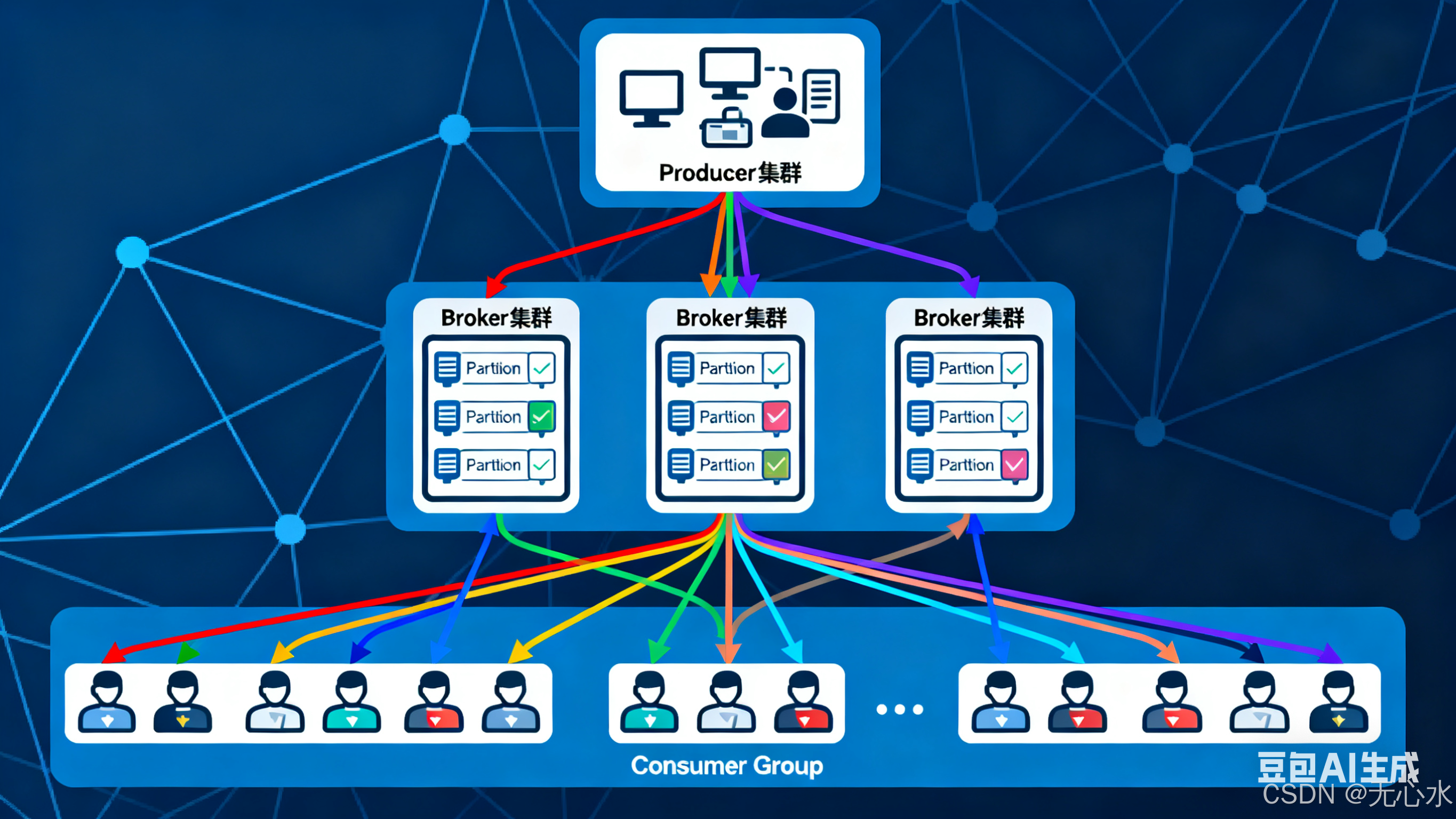
二、核心架构与组件:5大核心组件,分工决定效率
Kafka的架构设计围绕"分区并行、副本容错",核心由5大组件构成,每个组件都直接影响其高吞吐和高可靠特性。
| 组件 | 作用与核心逻辑 | 类比场景 |
|---|---|---|
| Producer(生产者) | 消息发送方(如日志采集器、业务系统),支持批量发送、压缩消息,通过"分区策略"将消息写入指定Partition。 | 快递发货点(按区域分拣包裹,批量装车) |
| Consumer(消费者) | 消息接收方(如Flink任务、数据分析系统),从Partition拉取消息,通过"消费者组"实现负载均衡或广播。 | 快递收货点(多人分工取件,每人负责一片区域) |
| Broker(代理节点) | Kafka集群的工作节点,负责存储消息(日志文件)、处理生产者/消费者请求,一个Broker可管理多个Partition。 | 快递仓库(存储包裹,对接发货/收货点) |
| Topic(主题) | 消息的逻辑分类(如"app-log-topic""user-behavior-topic"),类似"文件夹",所有消息必须属于某个Topic。 | 快递分类区("生鲜区""日用品区",按类型划分) |
| Partition(分区) | Topic的物理存储单元,每个Topic包含1个或多个Partition(可配置),消息按顺序写入Partition,实现并行读写。 | 分类区中的货架(每个货架独立存储,可并行存取) |
关键扩展:副本(Replica)与ZooKeeper
- 副本(Replica):每个Partition可配置多个副本(如3个),分为1个Leader和N-1个Follower。Leader负责处理读写请求,Follower同步Leader数据,Leader宕机后Follower自动竞选新Leader(保证高可用)。
- ZooKeeper:传统Kafka依赖ZooKeeper管理元数据(如Broker存活状态、Topic-Partition映射、Leader选举结果),Kafka 2.8+支持kraft模式(无ZooKeeper),但生产环境仍以ZooKeeper模式为主。
三、消息流转全流程:从日志收集到实时分析,一步不落
以"APP日志实时收集与分析"为例,拆解Kafka从消息生产到消费的完整流程(包含分区、副本、Offset等核心细节)。
1. 初始化:搭建"数据传输管道"
- 创建Topic:运维人员创建"app-log-topic",配置3个Partition(并行处理)、2个副本(高可用),分布在3个Broker节点上(Broker-0、Broker-1、Broker-2);
- 元数据注册:ZooKeeper记录Topic信息(如"app-log-topic有3个Partition,Partition-0的Leader在Broker-0,Follower在Broker-1")。
2. 生产者发送消息:按规则写入Partition
APP日志采集器(Producer) → 确定Partition → 写入Leader副本 - 步骤1:选择Partition
生产者发送消息时,需确定写入哪个Partition,默认有3种策略:- 按Key哈希:消息带Key(如用户ID)时,通过
hash(key) % 分区数路由到固定Partition(保证同一Key的消息有序); - 轮询:无Key时,按顺序轮流写入各Partition(负载均衡);
- 自定义:通过
Partitioner接口实现业务专属路由(如按日志级别分区)。
示例:某条日志的Key为"user123",hash("user123") % 3 = 0,则写入Partition-0。
- 按Key哈希:消息带Key(如用户ID)时,通过
- 步骤2:批量发送与压缩
生产者默认开启"批量发送"(累积到64KB或等待10ms)和"消息压缩"(如snappy、gzip),大幅减少网络IO。例如:1000条日志(每条1KB)压缩后约100KB,批量发送比单条发送减少90%网络传输量。 - 步骤3:写入Leader副本
消息发送到Partition-0的Leader副本(Broker-0),Leader将消息追加到本地日志文件(00000000000000000000.log),并同步给Follower副本(Broker-1)。- 只有当"ISR列表"(In-Sync Replicas,与Leader数据同步的Follower集合)中的副本确认收到消息,Leader才返回"发送成功"(确保数据可靠)。
3. 消费者消费消息:从Partition拉取并确认
日志分析系统(Consumer) → 拉取Partition消息 → 提交Offset - 步骤1:消费者组与负载均衡
消费者属于"消费者组(Consumer Group)",同一组内的消费者分工消费Topic的Partition(1个Partition只能被组内1个消费者消费,避免重复)。例如:3个Partition由消费者组内的2个消费者处理,可能"消费者A消费Partition-0/1,消费者B消费Partition-2"。 - 步骤2:拉取消息与Offset管理
消费者通过"Offset(消费位移)"记录已消费到Partition的哪个位置(类似"书签"),每次拉取时指定"从Offset=100开始拉取100条消息"。- Offset默认保存在Kafka的内置Topic(
__consumer_offsets)中(避免依赖外部存储); - 消费完成后,消费者提交新的Offset(如"已消费到Offset=200"),下次从201开始拉取。
- Offset默认保存在Kafka的内置Topic(
- 步骤3:消息处理与异常恢复
消费者拉取消息后,执行分析逻辑(如统计错误日志数量)。若处理失败(如系统宕机),因Offset未提交,重启后会从上次的Offset重新拉取,确保消息不丢失。
四、高吞吐核心:Kafka为什么能"每秒百万条"?
Kafka的高吞吐并非偶然,而是"分区并行+磁盘优化+批量处理"三大设计的必然结果。
1. 分区并行:多Partition同时读写
每个Partition是独立的日志文件,生产者可向多个Partition并行发送消息,消费者可从多个Partition并行拉取,实现"多车道并行"。例如:1个Topic有10个Partition,理论吞吐量是单Partition的10倍(前提是Broker和消费者足够)。
2. 磁盘优化:顺序写+零拷贝,比内存还快
很多人疑惑:"Kafka消息存在磁盘,为什么比内存队列还快?" 关键在两点:
- 顺序写磁盘:消息追加到日志文件末尾(顺序写),而非随机读写(如MySQL的B+树)。顺序写磁盘的速度接近内存(机械硬盘顺序写约200MB/s,远超随机写的10MB/s);
- 零拷贝(Zero-Copy) :消费者拉取消息时,Kafka通过操作系统的
sendfile系统调用,直接将磁盘文件数据发送到网卡(跳过用户态→内核态→用户态的拷贝),减少50%以上的CPU和内存开销。
3. 批量处理:减少IO次数
- 生产者批量发送:累积一定数量(如64KB)或时间(如10ms)的消息,一次性发送,减少网络请求次数;
- 消费者批量拉取:一次拉取多条消息(默认500条),减少拉取请求次数;
- 消息压缩:批量压缩消息(如gzip压缩率可达10:1),降低网络传输和磁盘存储成本。
五、核心特性:从"可靠"到"可扩展"的关键设计
1. 高可用:副本机制+ISR列表
- 副本容错:每个Partition的多个副本中,Leader处理读写,Follower同步数据。Leader宕机后,ISR列表中的Follower通过选举成为新Leader(通常10秒内完成),服务不中断;
- ISR动态调整 :Follower若长时间未同步Leader数据(超过
replica.lag.time.max.ms,默认30秒),会被踢出ISR列表,避免拖慢整体性能。
2. 持久化:日志文件+保留策略
- 日志存储 :消息按Partition以日志文件(
.log)存储,每个文件默认1GB,满后创建新文件(便于删除旧文件); - 保留策略:可按时间(如保留7天)或大小(如总大小不超过10TB)删除旧消息,平衡存储成本和数据需求。
3. 流处理:Kafka Streams实时分析
Kafka不仅是消息队列,还内置流处理引擎(Kafka Streams),支持实时数据转换、聚合、关联。例如:通过Streams实时计算"过去10分钟的错误日志数",无需依赖Flink等外部组件。
4. Exactly-Once语义:精确一次处理
通过"事务消息+Offset原子提交",保证消息"仅被处理一次"(既不重复也不丢失)。例如:金融交易消息,确保不会因重复消费导致多扣钱。
六、实战避坑:Kafka最容易踩的5个坑
1. 分区数不合理:性能瓶颈或资源浪费
- 坑:分区数太少(如1个),无法发挥并行优势,导致吞吐上不去;分区数太多(如1000个),Broker元数据管理压力大,消费者重平衡耗时过长。
- 解决:分区数=预期最大TPS/单分区最大TPS(单分区TPS约1000-2000)。例如:预期TPS 1万,设置5-10个分区;同时分区数≤消费者组内消费者数量(避免闲置分区)。
2. 副本数配置不当:可靠性不足或性能下降
- 坑:副本数=1(无备份),Broker宕机直接丢数据;副本数过多(如5个),Leader同步压力大,写入性能下降。
- 解决:核心数据副本数=3(1个Leader+2个Follower,平衡可靠与性能);非核心数据副本数=2。
3. 消费者重平衡(Rebalance)频繁:消费中断
- 坑:消费者组内成员变化(如新增/下线消费者)、Topic分区数变化时,会触发重平衡(重新分配Partition与消费者的映射),期间消费中断(通常几秒到几十秒)。
- 解决 :
- 避免频繁上下线消费者;
- 配置
session.timeout.ms=30000(会话超时)和heartbeat.interval.ms=3000(心跳间隔),减少不必要的重平衡; - 采用"静态成员"(
group.instance.id),固定消费者身份,降低重平衡频率。
4. 消息积压:消费者处理太慢
- 坑:生产者速度>消费者处理速度,Partition消息越堆越多(积压),甚至触发磁盘满告警。
- 解决 :
- 临时扩容:增加消费者组内的消费者数量(≤分区数),分担消费压力;
- 优化消费逻辑:批量处理消息、异步化非核心操作、减少远程调用;
- 监控积压:通过
kafka-consumer-groups.sh查看LAG(积压量),超过阈值告警(如LAG>10万)。
5. 数据倾斜:某分区消息过多
- 坑:因Key分布不均(如某用户日志占比80%),导致其对应的Partition消息量远超其他,成为瓶颈(该分区的消费者忙死,其他闲着)。
- 解决 :
- 无Key消息:用轮询策略避免倾斜;
- 有Key消息:对热点Key加随机后缀(如"user123_0""user123_1"),分散到多个Partition,消费时再去掉后缀合并处理。
七、总结:Kafka为什么是流处理时代的"基础设施"?
Kafka的成功源于"为大数据场景量身定制":
- 性能上,分区并行+磁盘顺序写+零拷贝,支撑百万级TPS,满足高吞吐需求;
- 可靠性上,副本机制+ISR+持久化,确保数据不丢失,适配核心业务;
- 扩展性上,分区和集群水平扩展,轻松应对数据量增长;
- 功能性上,从消息队列到流处理,一站式解决数据传输与实时分析需求。
无论是日志收集、实时监控,还是数据同步、流处理,Kafka都能以其"三高一大"的特性,成为架构中的"数据枢纽"。
互动话题:你在项目中用Kafka处理过哪些场景?遇到过最棘手的问题是什么?欢迎在评论区分享你的实战经验~