unsetunset1、问题来源unsetunset
做电商平台搜索优化,遇到一个典型问题:用户搜索"性价比高的手机",系统只能匹配标题包含"性价比"的商品,那些真正物美价廉但描述不同的产品完全检索不到。更离谱的是搜索"送女朋友的礼物",系统直接懵了。
核心问题是中文表达的丰富性和商品描述的多样性存在巨大语义鸿沟,用户说"商务人士用的笔记本",商家写的是"轻薄便携办公本",传统关键词匹配无法建立语义关联。

unsetunset2、问题分析unsetunset
咱们传统搜索就是在倒排索引中查找包含关键词的文档,通过TF-IDF、BM25 计算相关性得分。这套机制处理精确查询没问题,比如"iPhone 15 Pro 256G"能精准返回对应商品。
但面对意图性查询就力不从心了,像"适合学生党的平价耳机"、"老人用的智能手机"这类需求表达,传统搜索效果很差。
用户行为分析发现三个现象:搜索无果后会尝试不同关键词 2-3 次、经常使用"好用的"、"性价比高的"等模糊形容词但商品描述很少直接出现、搜索习惯趋向自然语言表达而非关键词堆砌。
技术层面,传统搜索的局限性体现在词汇匹配严格性、缺乏语义理解、无法处理上下文关系,同义词扩展只是治标不治本。
unsetunset3、解决方案探讨unsetunset
调研后选择基于向量检索的语义搜索技术,核心是将文本转换为高维向量,通过向量相似度衡量语义相关性。
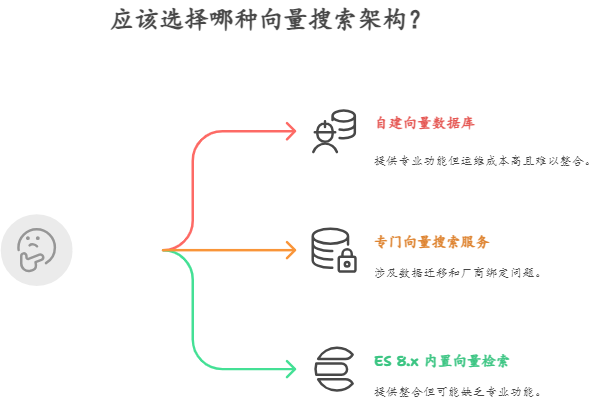
架构方案对比了三种:
-
自建向量数据库(Milvus/Pinecone)专业但运维成本高且难与ES整合
-
专门向量搜索服务存在数据迁移和厂商绑定问题
-
ES 8.x 内置向量检索功能或者 Easysearch 上新的向量功能
最终选择第三种,理由是现有架构基于 Easysearch 改造成本最低、向量检索已经成熟支持多种算法、能很好融合传统关键词搜索和语义搜索实现混合检索。

向量化模型测试了OpenAI(英文强中文一般)、百度文心(中文好但成本高),最终选择阿里云 text-embedding-v4,中文效果出色 API 稳定成本可控。
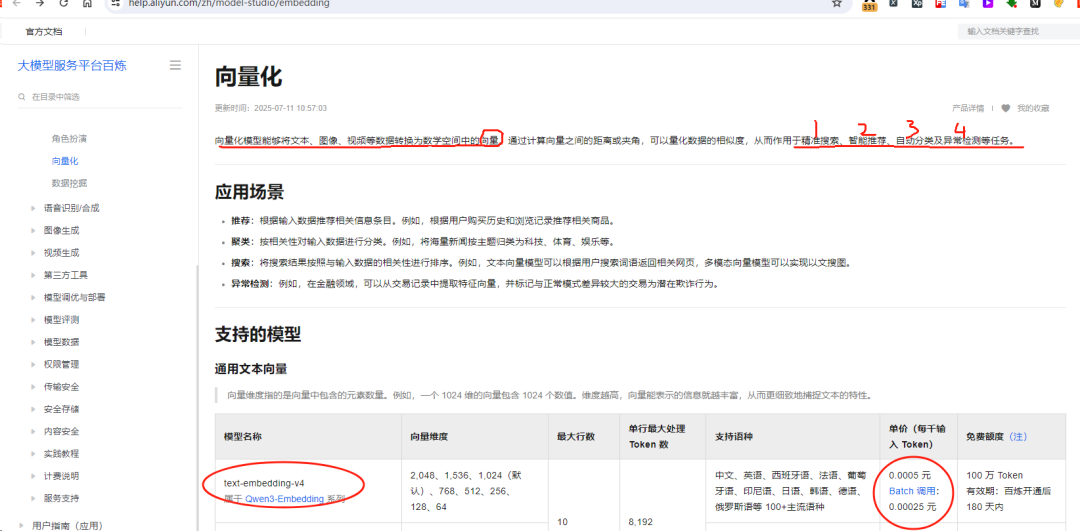
官方地址:https://help.aliyun.com/zh/model-studio/embedding
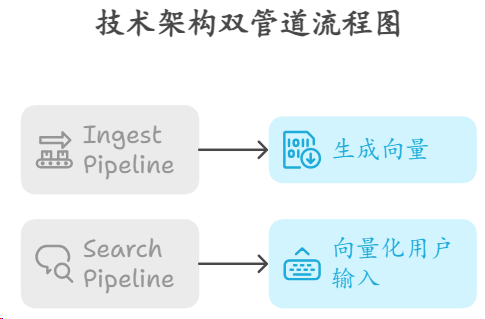
技术架构采用双管道:
-
Ingest Pipeline 负责写入时生成向量
-
Search Pipeline 负责查询时向量化用户输入
整个过程对业务代码透明。
unsetunset4、解决问题实战unsetunset
说了这么多理论,接下来看看具体怎么实现。
整个实现过程可以分为几个关键步骤:
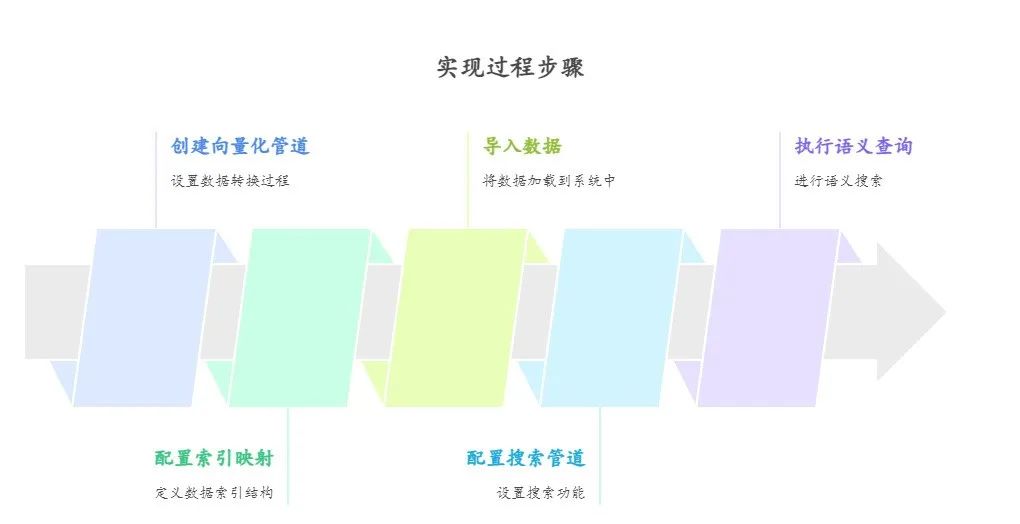
-
创建向量化管道
-
配置索引映射
-
导入数据
-
配置搜索管道
-
执行语义查询。
4.0 选型外部语义库,创建API
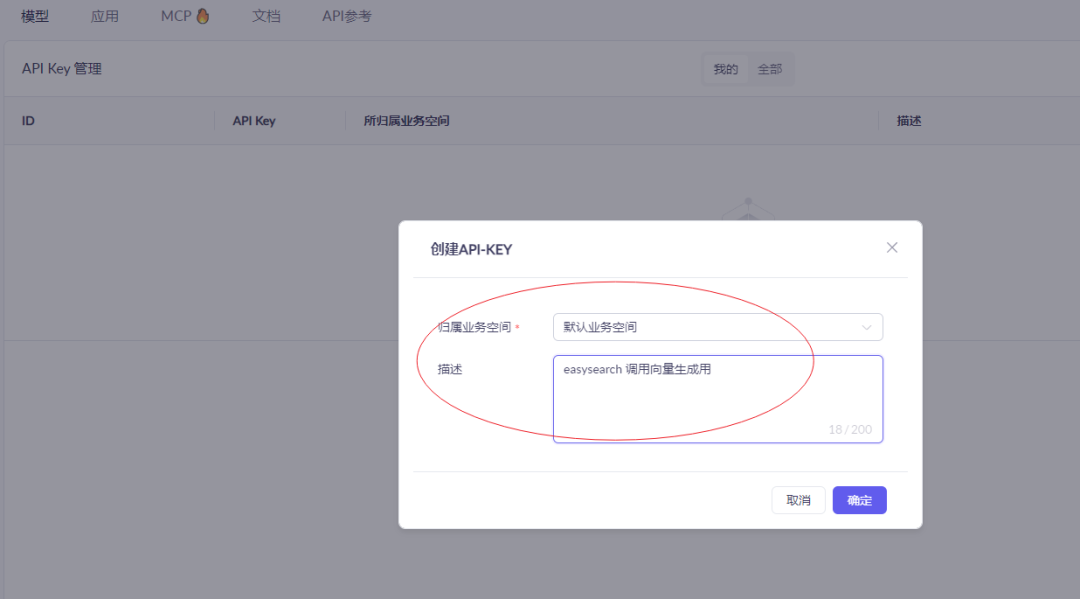
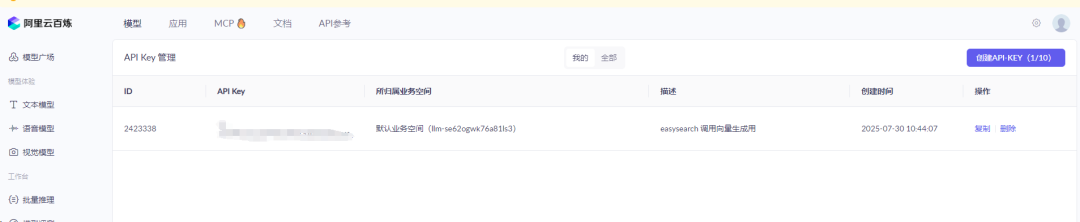
参考上面截图就可以申请获得免费的 API-key 使用。
4.1 创建用于数据写入时向量化的 Ingest Pipeline
这个 Pipeline 会在商品数据写入 ES 时自动调用阿里云的向量化 API,为每个商品生成 256 维的向量表示:
go
PUT _ingest/pipeline/product-embedding-aliyun
{
"description": "商品文本向量化管道",
"processors": [
{
"text_embedding": {
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "sk-XXXXXXXXXXXXXXXXX",
"text_field": "product_description",
"vector_field": "product_vector",
"model_id": "text-embedding-v4",
"dims": 256,
"batch_size": 10
}
}
]
}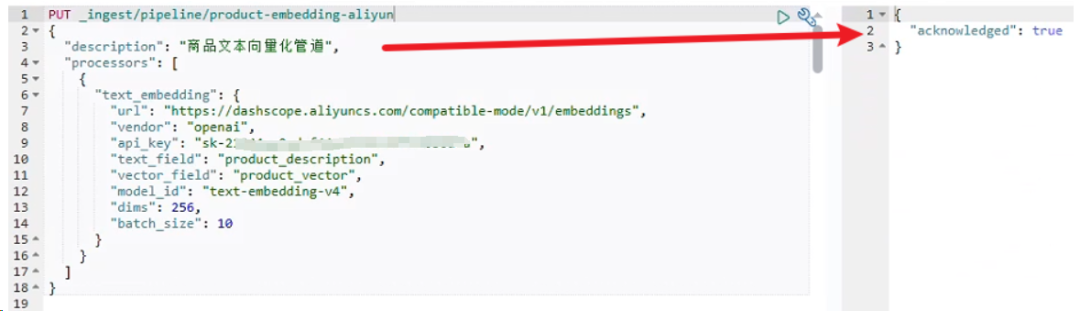
这里有几个参数需要特别说明。
-
text_field 指定了需要向量化的文本字段,我们选择product_description 是因为这个字段包含了商品的详细信息。
-
vector_field 是生成的向量存储字段。dims设置为256维,这是在存储成本和检索精度之间找到的平衡点。
-
batch_size 设置为10,可以提高向量化的效率。
4.2 创建商品索引并定义向量字段的映射关系。
这一步很关键,向量字段的配置直接影响到后续的检索性能:
go
PUT /ecommerce-products
{
"mappings": {
"properties": {
"product_id": {
"type": "keyword"
},
"product_name": {
"type": "text",
"analyzer": "ik_max_word"
},
"product_description": {
"type": "text",
"analyzer": "ik_max_word"
},
"category": {
"type": "keyword"
},
"price": {
"type": "double"
},
"brand": {
"type": "keyword"
},
"product_vector": {
"type": "knn_dense_float_vector",
"knn": {
"dims": 256,
"model": "lsh",
"similarity": "cosine",
"L": 99,
"k": 1
}
}
}
}
}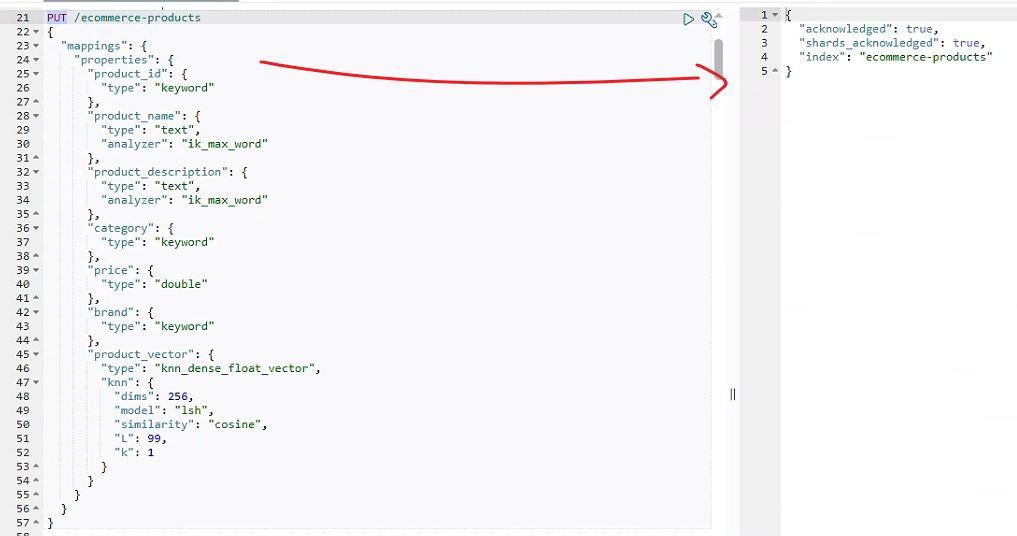
向量字段的配置是整个方案的核心。
- type 设置为 knn_dense_float_vector 表示这是一个用于kNN检索的稠密向量字段。
- model 选择 lsh(Locality Sensitive Hashing),这是一种在保证检索精度的同时显著提升查询性能的算法。
- similarity 设置为 cosine,余弦相似度对向量长度不敏感,更适合文本语义比较。
L和k参数是LSH算法的配置,经过我们的初步测试验证,L=99, k=1这个组合在我们的测试业务场景下性能最佳。
写入结果如下图所示:
4.3 批量导入商品数据。
在导入时指定使用刚才创建的Pipeline,系统会自动为每个商品生成向量:
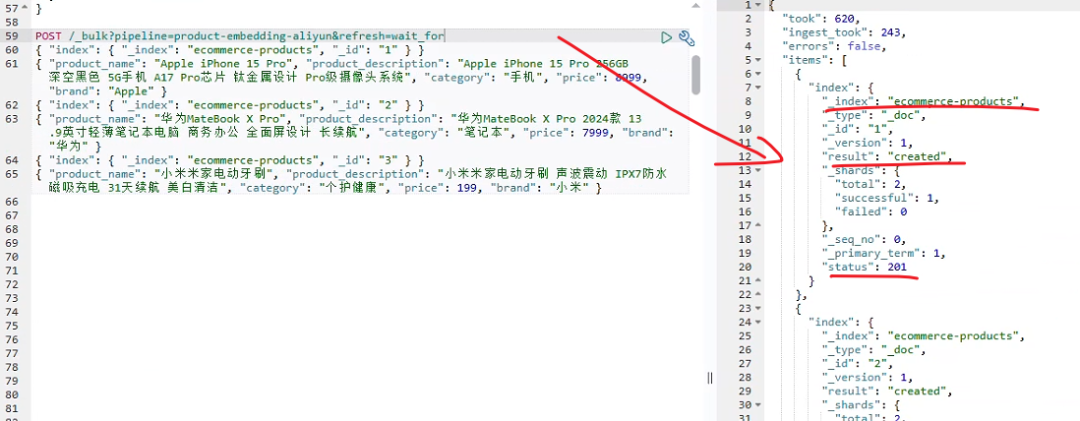
go
POST /_bulk?pipeline=product-embedding-aliyun&refresh=wait_for
{ "index": { "_index": "ecommerce-products", "_id": "1" } }
{ "product_name": "Apple iPhone 15 Pro", "product_description": "Apple iPhone 15 Pro 256GB 深空黑色 5G手机 A17 Pro芯片 钛金属设计 Pro级摄像头系统", "category": "手机", "price": 8999, "brand": "Apple" }
{ "index": { "_index": "ecommerce-products", "_id": "2" } }
{ "product_name": "华为MateBook X Pro", "product_description": "华为MateBook X Pro 2024款 13.9英寸轻薄笔记本电脑 商务办公 全面屏设计 长续航", "category": "笔记本", "price": 7999, "brand": "华为" }
{ "index": { "_index": "ecommerce-products", "_id": "3" } }
{ "product_name": "小米米家电动牙刷", "product_description": "小米米家电动牙刷 声波震动 IPX7防水 磁吸充电 31天续航 美白清洁", "category": "个护健康", "price": 199, "brand": "小米" }4.4 配置 Search Pipeline 为默认搜索管道
Search Pipeline 用于在搜索时对用户查询进行向量化。
go
PUT /_search/pipeline/semantic_search_aliyun
{
"request_processors": [
{
"semantic_query_enricher": {
"tag": "product_semantic_search",
"description": "商品语义搜索向量化处理器",
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "sk-XXXXXXXXXXXXXX",
"default_model_id": "text-embedding-v4",
"vector_field_model_id": {
"product_vector": "text-embedding-v4"
}
}
}
]
}
然后将这个Search Pipeline设置为索引的默认搜索管道:

go
PUT /ecommerce-products/_settings
{
"index.search.default_pipeline": "semantic_search_aliyun"
}4.5 执行语义搜索
完成这些配置后,就可以执行语义搜索了。
当 用户搜索"商务人士适合的笔记本"时,系统会自动将这个查询转换为向量,然后在向量空间中找到最相似的商品:
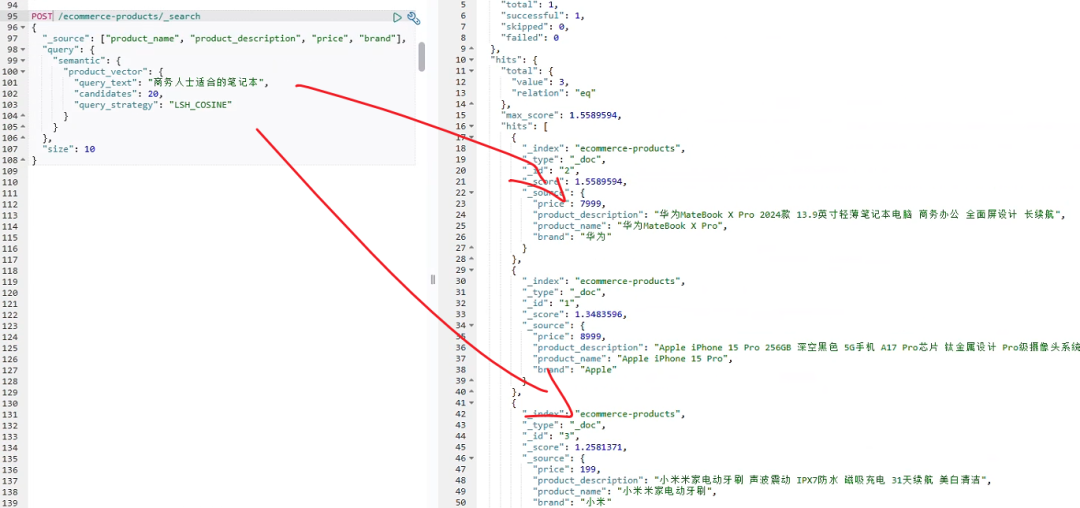
go
GET /ecommerce-products/_search
{
"_source": ["product_name", "product_description", "price", "brand"],
"query": {
"semantic": {
"product_vector": {
"query_text": "商务人士适合的笔记本",
"candidates": 20,
"query_strategy": "LSH_COSINE"
}
}
},
"size": 10
}这个查询的魅力在于,即使商品描述中没有直接出现"商务人士"这个词汇,但只要包含"商务办公"、"轻薄便携"等语义相关的表达,都能被检索到。这就是语义搜索的威力所在。
在实际应用中,我们发现纯语义搜索有时会过度泛化,对于一些精确查询反而不如关键词搜索准确。比如用户搜索"iPhone 15 Pro"这种明确的商品名称时,传统的关键词匹配更加精准。为了解决这个问题,我们设计了混合搜索策略。
但这里有个技术坑需要注意,不能直接在 bool 查询中将 semantic 查询和其他查询混合使用,会报null_pointer_exception错误。
swift
"error": { "root_cause": [ { "type": "null_pointer_exception", "reason": "Cannot invoke \"org.easysearch.ai.action.embedding.EmbeddingRequest.dimensions(java.lang.Integer)\" because \"this.embeddingRequest\" is null" } ], "type": "null_pointer_exception", "reason": "Cannot invoke \"org.easysearch.ai.action.embedding.EmbeddingRequest.dimensions(java.lang.Integer)\" because \"this.embeddingRequest\" is null" }, "status": 500}解决方案是采用分离式的混合搜索,先分别执行关键词搜索和语义搜索,然后在应用层进行结果融合。
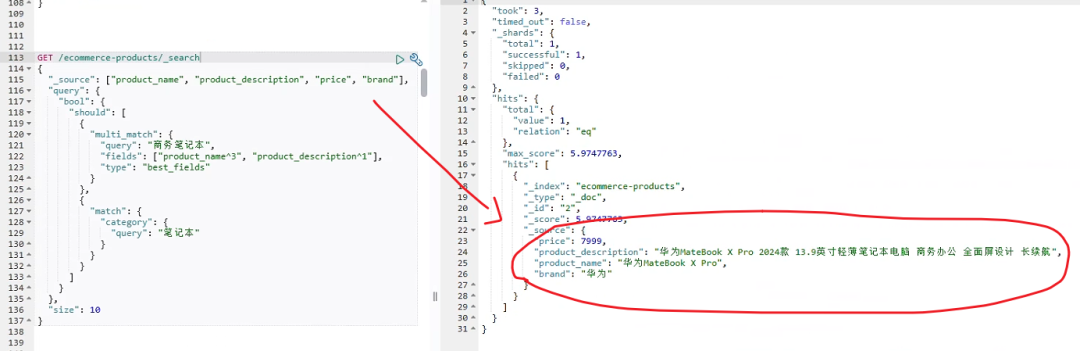
go
GET /ecommerce-products/_search
{
"_source": ["product_name", "product_description", "price", "brand"],
"query": {
"bool": {
"should": [
{
"multi_match": {
"query": "商务笔记本",
"fields": ["product_name^3", "product_description^1"],
"type": "best_fields"
}
},
{
"match": {
"category": {
"query": "笔记本"
}
}
}
]
}
},
"size": 10
}unsetunset5、小结unsetunset
以预处理管道的方式生成向量真是一个绝佳的设计,不知道大家有没有体会?
我之前的 RAG 系统都是自己实现的?现在有了预处理管道接入生成向量模型的实现,的确非常方便。
语义搜索让搜索引擎具备真正的理解能力,不是关键词匹配而是用户意图洞察,对任何处理大量文本信息的业务都值得实践,既提升用户体验更带来商业价值。
Logstash 9.X 同步写入 Easysearch 常见问题及解决方案
部署 Easysearch 出现 fatal error in thread main, exiting ,怎么解决?
投标环节:如何科学、合理地介绍 Elasticsearch 国产化替代方案------Easysearch?
将斯坦福 GloVe 词向量数据集索引到 Easysearch 以实现语义搜索