2023年3月清华智谱 国内首发开源ChatGLM大模型
2023年8月阿里 开源大模型Qwen(通义千问)
2025年1月深度求索 开源DeepSeek大模型
2025年6月百度 开源ERNIE(文心) 4.5系列大模型
......
为什么现在会越来越多的公司,开源自己AI大模型呢?
其实想一想也是这样的,就像超市发试吃一样,先把人吸引过来。
国内AI的发展方向,国内大佬们已经做出过很多次的判断。如"国内AI应该做应用","AI大模型开源就是智商税"等等。
 但当时字节的豆包推出低价的模型时,豆包的价格,比行业价格低99.3%,这一爆炸性新闻也冲上热搜,吸引了一大波的用户,足以看到大家对普惠倾向。
但当时字节的豆包推出低价的模型时,豆包的价格,比行业价格低99.3%,这一爆炸性新闻也冲上热搜,吸引了一大波的用户,足以看到大家对普惠倾向。

再到DeepSeek开源后,又引起了一大波浪潮。
大家使用AI,第一、考虑它的费用; 第二、考虑它的安全性,比如自己的数据或信息会不会被泄露。DeepSeek开源后大家就可以更放心使用了。
这种情况不只单单是国内,国外的AI也如此。就如openai一样,当时马斯克还讽刺它应该叫closeai。的确最早大家或者说整个AI领域还是以闭源AI的方式为主,毕竟所以有AI公司还是以赚钱为目的。AI的研发需要投入大量的金钱,如硬件费用、研发人员工资、运营投入等等都需要花钱。所以还是高价的API和高价VIP服务作为赚钱的手段。
当时全球最早的开源AI就是meta的llama大模型,但整个行业还是以闭源的观念为主。后面马斯克把自己的grok开源了,开源一周左右就在github上引来了40k+的star。也就是说随着AI的发展大家的观念更青睐走开源的路线。
据统计目前全球开源大模型已经超过200+个了。如果在AI时代,特别时是已经这么多开源的大模型。你想了解和搭建属于自己的AI模型的话,知乎知学堂的大模型训练营是个不错的选择。从原理到业务场景落地,带着你把大模型前沿技术吃透,还结合真实项目案例手把手带练。学完不仅能在简历里添上亮眼的实战经历,还会成为老板特别看重的AI人才。
我们来具体看看此次百度文心一言ERNIE 4.5 模型开源情况及带来的影响。
开源的ERNIE 4.5 系列模型
开源规模与版本
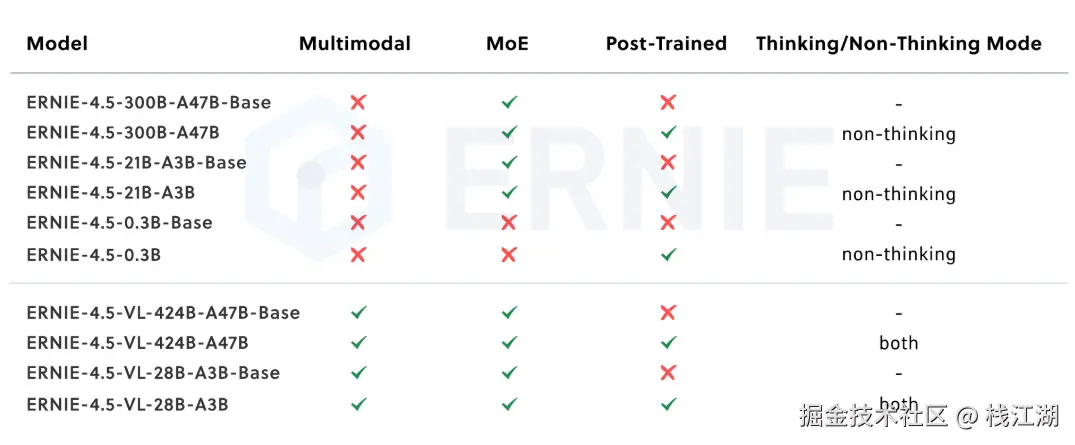
2025年6月30日百度开源了ERNIE 4.5 模型系列模型,文心4.5系统开源模型包含10款,涵盖了激活参数规模分别为47B和3B的混合专家(MoE)模型(最大的模型总参数量为424B),以及0.3B的稠密参数模型。
也就是说百度这次开源的不单单是一两个模型了而是一系列的模型,相比之用的开源更加完整。
技术创新亮点
多模态混合专家模型预训练、高效训练推理框架、针对模态的后训练

针对 MoE 架构,提出了一种创新性的多模态异构模型结构,通过跨模态参数共享机制实现模态间知识融合,同时为各单一模态保留专用参数空间。
在大语言模型的预训练中,模型FLOPs利用率(MFU)达到47%。
开源形式与生态布局
Apache 2.0 商用友好许可;权重、推理代码、开发套件一并开放;多平台发布(飞桨、HuggingFace、千帆)。