AI Agent多模态融合策略研究与实证应用
一、引言
随着人工智能领域的发展,AI Agent逐渐成为执行复杂任务的重要智能体。然而,单一模态输入(如仅使用文本或图像)限制了其对现实环境的理解能力。多模态信息融合,结合文本、图像、语音、视频等异构信息,能大幅提升Agent的感知、推理与决策水平。本文将探讨如何通过多模态信息融合优化AI Agent模型,并提供可复现的代码实战案例。
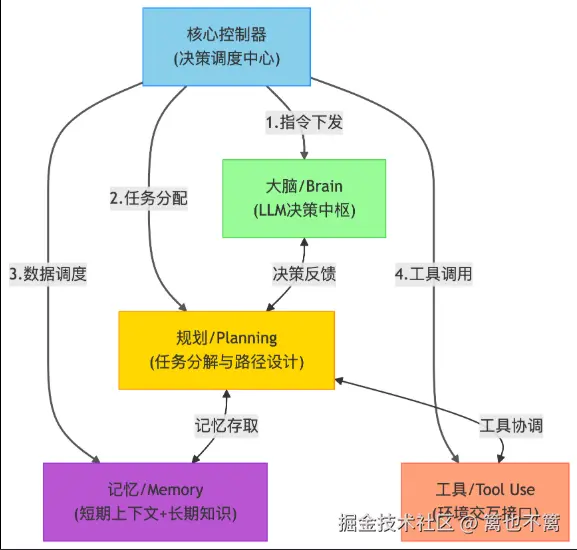
二、多模态AI Agent模型概述
1. 什么是多模态信息融合?
多模态信息融合(Multimodal Fusion)是指将来自不同模态(文本、图像、语音等)的信息在模型内部进行联合建模,以增强表示能力和推理效果。
2. AI Agent中的应用价值
- 感知增强:融合语音+图像识别,增强场景理解能力;
- 交互优化:结合语言生成和视觉反馈,提高任务互动效率;
- 决策智能:融合模态信息提升策略制定与环境适应能力。
三、多模态AI Agent架构设计
1. 总体架构
plaintext
[环境输入] → [图像Encoder] →┐
│→ [融合模块] → [Transformer Agent] → [策略输出]
[语言输入] → [文本Encoder] →┘2. 融合机制分类
- 早期融合(Early Fusion):在输入层拼接模态向量;
- 中期融合(Mid Fusion):在中间层做特征对齐和融合;
- 后期融合(Late Fusion):各模态独立决策后再合并输出。
四、实战案例:图文问答型AI Agent模型实现(基于PyTorch)
我们以图文问答(Visual Question Answering, VQA)为例,构建一个融合图像和文本的AI Agent,使用CLIP和Transformer结构。
1. 环境依赖安装
bash
pip install torch torchvision transformers2. 模型构建
(1)引入依赖
python
import torch
import torch.nn as nn
from transformers import BertTokenizer, BertModel
from torchvision.models import resnet50(2)图像Encoder(ResNet)
python
class ImageEncoder(nn.Module):
def __init__(self):
super().__init__()
resnet = resnet50(pretrained=True)
self.features = nn.Sequential(*list(resnet.children())[:-2]) # 去除FC层
self.pool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
x = self.features(x)
x = self.pool(x)
return x.view(x.size(0), -1) # [batch, 2048](3)文本Encoder(BERT)
python
class TextEncoder(nn.Module):
def __init__(self):
super().__init__()
self.bert = BertModel.from_pretrained('bert-base-uncased')
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
return outputs.last_hidden_state[:, 0, :] # [CLS]向量(4)融合模块 + 策略决策
python
class MultiModalAgent(nn.Module):
def __init__(self, hidden_dim=512):
super().__init__()
self.img_encoder = ImageEncoder()
self.txt_encoder = TextEncoder()
self.fusion = nn.Linear(2048 + 768, hidden_dim)
self.classifier = nn.Linear(hidden_dim, 10) # 假设有10个回答类别
def forward(self, image, input_ids, attention_mask):
img_feat = self.img_encoder(image)
txt_feat = self.txt_encoder(input_ids, attention_mask)
fused = torch.cat([img_feat, txt_feat], dim=1)
hidden = torch.relu(self.fusion(fused))
return self.classifier(hidden)五、模型训练与测试流程
1. 输入准备(伪代码示例)
python
from transformers import BertTokenizer
from PIL import Image
from torchvision import transforms
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
def prepare_input(image_path, question_text):
image = transform(Image.open(image_path).convert('RGB')).unsqueeze(0)
tokens = tokenizer(question_text, return_tensors='pt', padding=True, truncation=True)
return image, tokens['input_ids'], tokens['attention_mask']2. 模拟推理流程
python
agent = MultiModalAgent()
agent.eval()
image, input_ids, attention_mask = prepare_input("dog.jpg", "What is the animal in the image?")
output = agent(image, input_ids, attention_mask)
pred = torch.argmax(output, dim=1)
print("预测类别:", pred.item())六、优化方向与未来提升
1. 引入跨模态对齐机制(如Co-Attention)
使用跨模态注意力机制(如ViLBERT、CLIP)提高模态对齐效果。
2. 应用更强的视觉模型(如Vision Transformer)
代替ResNet50使用ViT或CLIP-Vision模块,获取更强的图像表示。
3. 融合语音与动作模态
在复杂AI Agent(如机器人助手)中,可引入语音识别与动作识别作为新的模态。
七、总结
本文从多模态信息融合的理论基础出发,构建了一个结合图像与文本的AI Agent模型,并通过PyTorch代码实现了完整的图文问答流程。未来,多模态智能体将在医疗、自动驾驶、虚拟助手等领域展现巨大潜力。模型优化的核心是提升不同模态的协同理解与推理能力,从而打造真正"理解世界"的AI Agent。