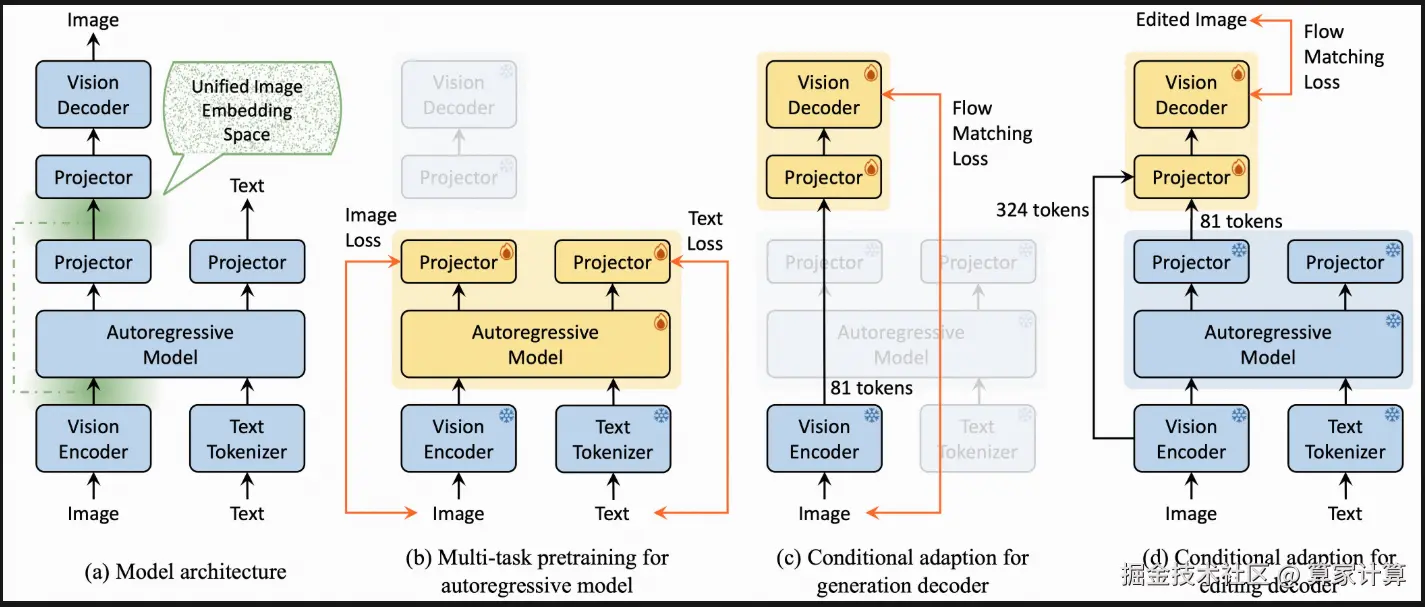
一、简介
Nexus-Gen 是一个统一的模型,它结合了大语言模型的语言推理能力和扩散模型的图像合成能力。提出了一种统一的图像嵌入空间来建模图像理解、生成和编辑任务。为了在多个任务上进行联合优化,整理了一个包含 2630 万个样本的大规模数据集,并使用多阶段策略训练 Nexus-Gen,包括自回归模型的多任务预训练以及生成和编辑解码器的条件适应。
Nexus-Gen 的定性结果:

限制:请注意,Nexus-Gen 是在有限的文本到图像数据上训练的,可能对文本提示不够鲁棒。
更新动态
2025 年 7 月 11 日 : Nexus-Gen V2 发布 。更多详情请参阅技术报告。该模型从以下几个方面进行了优化:
- 通过优化训练计划,提升了图像理解能力(在 MMMU 上得分为 45.7 )。
- 通过长短描述的训练,增强了图像生成(在 GenEval 上得分为 0.81 )的鲁棒性。
- 在图像编辑任务中提升了重建效果。团队为 Nexus-Gen 提出了一个更好的编辑解码器。
- 支持使用中文提示词进行生成和编辑。
2025 年 5 月 27 日 : 团队使用 BLIP-3o-60k 数据集对 Nexus-Gen 进行了微调,显著提高了模型在图像生
二、本地部署
| 环境 | 版本 |
|---|---|
| Python | >= 3.10 |
| controlnet-aux | == 0.0.7 |
| PyTorch | >= 2.0.0 |
| transformers | == 4.49.0 |
显卡要求:三张 24G 显存的显卡或者更高显存的显卡。
2.1.创建conda环境
2.1.1.安装 Miniconda
步骤 1:更新系统
更新您的系统软件包:
sql
sudo apt update
sudo apt upgrade -y步骤 2:下载 Miniconda 安装脚本
访问 Miniconda 的官方网站或使用以下命令直接下载最新版本的安装脚本(以 Python 3 为例):
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
步骤 3:验证安装脚本的完整性(可忽略)
下载 SHA256 校验和文件并验证安装包的完整性:(比较输出的校验和与.sha256 文件中的值是否一致,确保文件未被篡改。)
bash
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh.sha256
sha256sum Miniconda3-latest-Linux-x86_64.sh步骤 4:运行安装脚本
为安装脚本添加执行权限:
chmod +x Miniconda3-latest-Linux-x86_64.sh
运行安装脚本:
./Miniconda3-latest-Linux-x86_64.sh
步骤 5:按照提示完成安装
在安装过程中,您需要:
阅读许可协议 :按 Enter 键逐页阅读,或者按 Q 退出阅读。
接受许可协议 :输入 yes 并按 Enter。
选择安装路径 :默认路径为 "/home/您的用户名/miniconda3",直接按 Enter 即可,或输入自定义路径。
是否初始化 Miniconda :输入 yes 将 Miniconda 添加到您的 PATH 环境变量中。
步骤 6:激活 Miniconda 环境
安装完成后,使环境变量生效:
source ~/.bashrc
步骤 7:验证安装是否成功
检查 conda 版本:
conda --version
2.1.2.创建虚拟环境
创建新 conda 环境(环境名为 NexusGen ,可自主取名),后续 python 库安装和 py 文件运行都在这个 conda 环境下进行
conda create -n NexusGen python=3.10 -y
conda activate NexusGen
2.2.克隆仓库
项目地址:github.com/modelscope/...
git clone https://github.com/modelscope/Nexus-Gen.git
会在使用以上命令的当前目录下自动创建文件夹Nexus-Gen。
2.3.安装依赖
之前导入的git库内部有 requirements.txt,但是不全面,经过整合需要以下配置(内容可另存requirements.txt):
安装命令:pip install -r requirements.txt
注意:如果下载太慢,可以进行国内源替换(临时),基本所有python库单独或者 txt 集合下载都可以添加 源。
pip install -r requirements.txt -i <清华源 or 阿里源 等国内镜像源加速 python 库的下载>
e.g. pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
以下是修改后的 requirements.txt
ini
torch>=2.0.0
torchvision
cupy-cuda12x
transformers
controlnet-aux==0.0.7
imageio
imageio[ffmpeg]
safetensors
einops
sentencepiece
protobuf
modelscope
ftfy
pynvml
pandas
accelerate
qwen_vl_utils
flash-attn (这个库需要在安装 torch 之后才能安装)
transformers==4.49.0
gradio2.4.下载模型
之前 github.com/modelscope/... 克隆的文件夹内部有 download_models.py 文件,可以直接运行,运行之后,会在该文件同目录下自动创建 models 文件夹。然后再生成 Nexus-GenV2 和 FLUX 文件夹。
python download_models.py
download_models.py 文件内容:
ini
from modelscope import snapshot_download
snapshot_download('DiffSynth-Studio/Nexus-GenV2', local_dir='models/Nexus-GenV2')
flux_path = snapshot_download('black-forest-labs/FLUX.1-dev',
allow_file_pattern=[
"text_encoder/model.safetensors",
"text_encoder_2/*",
"ae.safetensors",
],
local_dir='models/FLUX/FLUX.1-dev')三、启动
注意:之前下载的git仓库里面的 app.py 源码仅支持单卡运行,测试环境采用的是三张 4090 24G 显卡,所以 app.py 已经接受修改。
如果单卡显存足够大,可以忽略针对git克隆后文件夹内 app.py,editing_decoder.py,modules.py 修改。(editing_decoder.py 和 modules.py 在 "Nexus-Gen/modeling/decoder/" 目录下)
运行demo,出现 "Running on local URL" 字样就可以浏览器打开了
python app.py
以下是文件修改后启动项目的 demo UI:
图像编辑
图像生成
图像理解
四、注意事项
针对该 demo 使用 3 张 4090 24G 显存的显卡 进行 图片生成、图片理解、图片编辑 三项功能。源文件也做了相应修改,以下作为修改参考。
4.1.app.py 文件修改
原git上下载的 app.py 需要替换为以下内容。
python
import gradio as gr
import torch
from PIL import Image
import os
import random
import gc
import subprocess
import time
import psutil
from transformers import AutoConfig
from qwen_vl_utils import process_vision_info, smart_resize
from modeling.decoder.generation_decoder import NexusGenGenerationDecoder
from modeling.decoder.editing_decoder import NexusGenEditingDecoder
from modeling.ar.modeling_qwen2_5_vl import Qwen2_5_VLForConditionalGeneration
from modeling.ar.processing_qwen2_5_vl import Qwen2_5_VLProcessor
import numpy as np
# <--- 新增: DynamicCache兼容性修复 ---
def patch_dynamic_cache_compatibility():
"""修复DynamicCache兼容性问题"""
try:
from transformers.cache_utils import DynamicCache
if not hasattr(DynamicCache, 'is_compileable'):
DynamicCache.is_compileable = lambda self: False
print("✅ DynamicCache兼容性补丁已应用")
except Exception as e:
print(f"⚠️ DynamicCache补丁应用失败: {e}")
# 立即应用兼容性补丁
patch_dynamic_cache_compatibility()
# --- 兼容性修复结束 ---
# <--- 新增: 应用启动时的初始化清理 ---
def initialize_clean_gpu_environment():
"""应用启动时清理所有GPU残留"""
print("=" * 60)
print("🚀 Nexus-Gen 应用启动 - 初始化GPU环境")
print("=" * 60)
# 1. 显示启动前的GPU状态
print("📊 启动前GPU状态:")
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
try:
allocated = torch.cuda.memory_allocated(i) / 1024**3
reserved = torch.cuda.memory_reserved(i) / 1024**3
print(f" GPU {i}: 已分配 {allocated:.2f}GB, 已保留 {reserved:.2f}GB")
except:
print(f" GPU {i}: 无法获取状态")
# 2. 安全清理残留进程(排除当前进程)
print("🔄 清理残留进程...")
try:
current_pid = os.getpid()
# 查找并终止其他Python进程,但排除当前进程
for proc in psutil.process_iter(['pid', 'name', 'cmdline']):
try:
if proc.info['pid'] != current_pid and proc.info['name'] and 'python' in proc.info['name'].lower():
cmdline = ' '.join(proc.info['cmdline']) if proc.info['cmdline'] else ''
# 只终止包含nexus或flux的进程,避免误杀其他Python程序
if any(keyword in cmdline.lower() for keyword in ['nexus', 'flux', 'diffsynth']):
print(f" 终止进程: PID {proc.info['pid']} - {cmdline[:50]}...")
proc.terminate()
proc.wait(timeout=3)
except (psutil.NoSuchProcess, psutil.AccessDenied, psutil.TimeoutExpired):
continue
time.sleep(1) # 等待进程完全终止
print(" ✅ 残留进程清理完成")
except ImportError:
print(" ⚠️ psutil未安装,跳过进程清理")
except Exception as e:
print(f" ⚠️ 进程清理警告: {e}")
# 3. 强制清理所有GPU显存
print("🧹 强制清理GPU显存...")
if torch.cuda.is_available():
try:
# 清理PyTorch缓存
for i in range(torch.cuda.device_count()):
with torch.cuda.device(i):
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
# 强制垃圾回收
gc.collect()
time.sleep(1) # 等待清理完成
print(" ✅ GPU显存清理完成")
except Exception as e:
print(f" ⚠️ GPU清理警告: {e}")
# 4. 显示清理后的GPU状态
print("📊 清理后GPU状态:")
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
try:
allocated = torch.cuda.memory_allocated(i) / 1024**3
reserved = torch.cuda.memory_reserved(i) / 1024**3
print(f" GPU {i}: 已分配 {allocated:.2f}GB, 已保留 {reserved:.2f}GB")
except:
print(f" GPU {i}: 无法获取状态")
print("✨ GPU环境初始化完成,开始加载模型...")
print("=" * 60)
# 立即执行初始化清理
initialize_clean_gpu_environment()
# --- 初始化清理结束 ---
def bound_image(image, max_pixels=262640):
resized_height, resized_width = smart_resize(
image.height,
image.width,
max_pixels=max_pixels,
)
return image.resize((resized_width, resized_height))
# <--- 新增: 显存管理函数 ---
def clear_gpu_memory():
"""清理所有GPU显存"""
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
with torch.cuda.device(i):
torch.cuda.empty_cache()
gc.collect()
def print_gpu_memory():
"""打印GPU显存使用情况"""
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
allocated = torch.cuda.memory_allocated(i) / 1024**3
reserved = torch.cuda.memory_reserved(i) / 1024**3
print(f"GPU {i}: 已分配 {allocated:.2f}GB, 已保留 {reserved:.2f}GB")
# --- 显存管理函数结束 ---
# Initialize model and processor
model_path = 'models/Nexus-GenV2'
model_config = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
# <--- 修改: 真正的组件分片策略 ---
print("🎯 组件分片策略:")
print(" 📍 cuda:0: 图像理解专用 (主模型)")
print(" 📍 cuda:1: 延迟加载生成&编辑解码器")
print(" 📍 cuda:2: 延迟加载生成&编辑解码器")
print("=" * 60)
# 主模型只加载到cuda:0,专门用于图像理解
understanding_device = "cuda:0"
# --- 组件分片策略结束 ---
# <--- 修改: 主模型只加载到cuda:0 ---
print("📦 加载主模型 (Qwen2.5-VL) 到 cuda:0 专用于图像理解...")
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_path,
config=model_config,
trust_remote_code=True,
torch_dtype="auto",
device_map=understanding_device, # 只加载到cuda:0
)
processor = Qwen2_5_VLProcessor.from_pretrained(model_path, trust_remote_code=True)
model.eval()
print(f"✅ 主模型已加载到 {understanding_device}")
print_gpu_memory()
# --- 主模型加载结束 ---
# Initialize Flux Decoder paths
flux_path = "models"
generation_decoder_path = "models/Nexus-GenV2/generation_decoder.bin"
editing_decoder_path = "models/Nexus-GenV2/edit_decoder.bin"
# <--- 修改: 真正的延迟加载和组件分片 ---
print("📦 设置延迟加载策略 - 避免初始化时显存溢出...")
# 全局解码器变量
generation_decoder = None
editing_decoder = None
current_task = None # 跟踪当前任务类型
def clear_all_decoders():
"""清理所有解码器"""
global generation_decoder, editing_decoder
if generation_decoder is not None:
del generation_decoder
generation_decoder = None
print(" 🗑️ 图像生成解码器已释放")
if editing_decoder is not None:
del editing_decoder
editing_decoder = None
print(" 🗑️ 图像编辑解码器已释放")
# 清理cuda:1和cuda:2的显存
for device_id in [1, 2]:
if torch.cuda.is_available() and device_id < torch.cuda.device_count():
with torch.cuda.device(device_id):
torch.cuda.empty_cache()
gc.collect()
print(" ✅ 所有解码器已清理")
def get_generation_decoder():
"""延迟初始化图像生成解码器"""
global generation_decoder, current_task
# 如果当前不是生成任务,先清理其他解码器
if current_task != "generation":
clear_all_decoders()
current_task = "generation"
if generation_decoder is None:
print("📦 初始化图像生成解码器 (cuda:1)...")
try:
generation_decoder = NexusGenGenerationDecoder(
generation_decoder_path,
flux_path,
device="cuda:1", # 只使用cuda:1
enable_cpu_offload=True # 启用CPU offload节省显存
)
print("✅ 图像生成解码器已加载到 cuda:1")
print_gpu_memory()
except Exception as e:
print(f"❌ 图像生成解码器加载失败: {e}")
# 如果cuda:1显存不足,尝试使用CPU offload
try:
generation_decoder = NexusGenGenerationDecoder(
generation_decoder_path,
flux_path,
device="cpu", # 降级到CPU
enable_cpu_offload=True
)
print("⚠️ 图像生成解码器已降级到CPU")
except Exception as e2:
print(f"❌ CPU降级也失败: {e2}")
raise e2
return generation_decoder
def get_editing_decoder():
"""延迟初始化图像编辑解码器"""
global editing_decoder, current_task
# 如果当前不是编辑任务,先清理其他解码器
if current_task != "editing":
clear_all_decoders()
current_task = "editing"
if editing_decoder is None:
print("📦 初始化图像编辑解码器 (cuda:2)...")
try:
editing_decoder = NexusGenEditingDecoder(
editing_decoder_path,
flux_path,
model_path,
device="cuda:2", # 只使用cuda:2
enable_cpu_offload=True # 启用CPU offload节省显存
)
print("✅ 图像编辑解码器已加载到 cuda:2")
print_gpu_memory()
except Exception as e:
print(f"❌ 图像编辑解码器加载失败: {e}")
# 如果cuda:2显存不足,尝试使用CPU offload
try:
editing_decoder = NexusGenEditingDecoder(
editing_decoder_path,
flux_path,
model_path,
device="cpu", # 降级到CPU
enable_cpu_offload=True
)
print("⚠️ 图像编辑解码器已降级到CPU")
except Exception as e2:
print(f"❌ CPU降级也失败: {e2}")
raise e2
return editing_decoder
print("✅ 延迟加载策略设置完成")
# --- 延迟加载策略结束 ---
# Define system prompt
SYSTEM_PROMPT = "You are a helpful assistant."
def image_understanding(image, question):
"""图像理解功能 - 专用cuda:0"""
print("=== 开始图像理解任务 (专用cuda:0) ===")
# 确保其他任务的解码器被清理
global current_task
if current_task != "understanding":
clear_all_decoders()
current_task = "understanding"
print_gpu_memory()
if image is not None:
# Convert numpy array to PIL Image
if isinstance(image, np.ndarray):
image = Image.fromarray(image)
messages = [
{
"role": "system",
"content": SYSTEM_PROMPT
},
{
"role": "user",
"content": [
{
"type": "image",
"image": image,
},
{"type": "text", "text": question if question else "Please give a brief description of the image."},
],
}
]
else:
# Text-only Q&A mode
messages = [
{
"role": "system",
"content": SYSTEM_PROMPT
},
{
"role": "user",
"content": [
{"type": "text", "text": question},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
if image is not None:
image_inputs, _ = process_vision_info(messages)
image_inputs = [bound_image(image) for image in image_inputs]
inputs = processor(
text=[text],
images=image_inputs,
padding=True,
return_tensors="pt",
)
else:
inputs = processor(
text=[text],
padding=True,
return_tensors="pt",
)
inputs = inputs.to(understanding_device)
# <--- 兼容性修复 ---
with torch.no_grad():
# 设置模型为非编译模式,避免DynamicCache问题
if hasattr(model, '_dynamo_compile'):
model._dynamo_compile = False
generated_ids = model.generate(
**inputs,
max_new_tokens=1024,
do_sample=True, # 禁用采样以提高稳定性 (废弃)
use_cache=True,
pad_token_id=processor.tokenizer.eos_token_id
)
# --- 兼容性修复结束 ---
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print("=== 图像理解任务完成 ===")
print_gpu_memory()
return output_text[0]
def image_generation(prompt):
"""图像生成功能 - 使用cuda:1"""
print("=== 开始图像生成任务 (cuda:1) ===")
print_gpu_memory()
generation_instruction = 'Generate an image according to the following description: {}'
prompt = generation_instruction.format(prompt)
messages = [{"role": "user", "content": [{"type": "text", "text": prompt}]}]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = processor(text=[text], padding=True, return_tensors="pt")
inputs = inputs.to(understanding_device) # 先在cuda:0上处理
generation_image_grid_thw = torch.tensor([[1, 18, 18]]).to(understanding_device)
# <--- 兼容性修复 ---
with torch.no_grad():
if hasattr(model, '_dynamo_compile'):
model._dynamo_compile = False
outputs = model.generate(
**inputs,
max_new_tokens=1024,
return_dict_in_generate=True,
generation_image_grid_thw=generation_image_grid_thw,
do_sample=True,
use_cache=True,
pad_token_id=processor.tokenizer.eos_token_id
)
# --- 兼容性修复结束 ---
if not hasattr(outputs, 'output_image_embeddings'):
raise ValueError("Failed to generate image embeddings")
else:
output_image_embeddings = outputs.output_image_embeddings
# 获取生成解码器并生成图像
decoder = get_generation_decoder()
seed = random.randint(0, 10000)
image = decoder.decode_image_embeds(output_image_embeddings, cfg_scale=3.0, seed=seed)
print("=== 图像生成任务完成 ===")
print_gpu_memory()
return image
def get_image_embedding(vision_encoder, processor, image, target_size=(504, 504)):
image = image.resize(target_size, Image.BILINEAR)
inputs = processor.image_processor(images=[image], videos=None, return_tensors='pt', do_resize=False)
device = vision_encoder.device
pixel_values = inputs["pixel_values"].to(device)
image_grid_thw = inputs["image_grid_thw"].to(device)
pixel_values = pixel_values.type(vision_encoder.dtype)
with torch.no_grad():
image_embeds = vision_encoder(pixel_values, grid_thw=image_grid_thw)
return image_embeds
def image_editing(image, instruction):
"""图像编辑功能 - 使用cuda:2"""
print("=== 开始图像编辑任务 (cuda:2) ===")
print_gpu_memory()
if '<image>' not in instruction:
instruction = '<image> ' + instruction
instruction = instruction.replace('<image>', '<|vision_start|><|image_pad|><|vision_end|>')
messages = [{"role": "user", "content": [{"type": "text", "text": instruction}]}]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# Convert numpy array to PIL Image if needed
input_image = Image.fromarray(image) if not isinstance(image, Image.Image) else image
bounded_image = bound_image(input_image)
inputs = processor(
text=[text],
images=[bounded_image],
padding=True,
return_tensors="pt",
)
inputs = inputs.to(understanding_device) # 先在cuda:0上处理
generation_image_grid_thw = torch.tensor([[1, 18, 18]]).to(understanding_device)
# <--- 兼容性修复 ---
with torch.no_grad():
if hasattr(model, '_dynamo_compile'):
model._dynamo_compile = False
outputs = model.generate(
**inputs,
max_new_tokens=1024,
return_dict_in_generate=True,
generation_image_grid_thw=generation_image_grid_thw,
do_sample=True,
use_cache=True,
pad_token_id=processor.tokenizer.eos_token_id
)
# --- 兼容性修复结束 ---
if not hasattr(outputs, 'output_image_embeddings'):
raise ValueError("Failed to generate image embeddings")
else:
output_image_embeddings = outputs.output_image_embeddings
# 获取参考图像嵌入
ref_embeddings = get_image_embedding(model.visual, processor, input_image, target_size=(504, 504))
# 获取编辑解码器并编辑图像
decoder = get_editing_decoder()
edited_image = decoder.decode_image_embeds(output_image_embeddings, ref_embed=ref_embeddings, cfg_scale=1.0)
print("=== 图像编辑任务完成 ===")
print_gpu_memory()
return edited_image
def edit_with_instruction(image, instruction):
return image_editing(image, instruction)
def understand_with_image(image, question):
return image_understanding(image, question)
# Create Gradio interface
with gr.Blocks(title="Nexus-Gen Demo") as demo:
gr.Markdown("# Nexus-Gen Demo")
with gr.Tab("Image Generation"):
with gr.Row():
with gr.Column():
prompt_input = gr.Textbox(label="Input Prompt", lines=3, placeholder="Describe the image you want to generate")
generate_btn = gr.Button("Generate") # , variant="primary"
with gr.Column():
output_image = gr.Image(label="Generated Image") # , type="pil"
def generate_with_option(prompt):
return image_generation(prompt)
generate_btn.click(
fn=generate_with_option,
inputs=[prompt_input], # , option_dropdown
outputs=[output_image] # output_text
)
gr.Examples(
examples=[
"A cut dog sitting on a bench in a park, wearing a red collar.",
"A woman in a blue dress standing on a beach at sunset.",
"一只可爱的猫。"
],
inputs=[prompt_input],
outputs=[output_image],
fn=generate_with_option,
cache_examples=False,
)
with gr.Tab("Image Editing"):
with gr.Row():
with gr.Column():
input_image = gr.Image(label="Upload Image to Edit") # , type="numpy"
edit_instruction = gr.Textbox(label="Editing Instruction", lines=2, placeholder="Describe how to edit the image...")
edit_btn = gr.Button("Edit Image") # , variant="primary"
with gr.Column():
edited_image = gr.Image(label="Edited Image") # , type="pil"
edit_btn.click(
fn=edit_with_instruction,
inputs=[input_image, edit_instruction],
outputs=[edited_image]
)
gr.Examples(
examples=[
["assets/examples/cat.png", "Add a pair of sunglasses for the cat."],
["assets/examples/cat.png", "给猫加一副太阳镜。"],
],
inputs=[input_image, edit_instruction],
outputs=edited_image,
fn=edit_with_instruction,
cache_examples=False,
)
with gr.Tab("Multimodal Q&A"):
with gr.Row():
with gr.Column():
qa_image = gr.Image(label="Upload Image (Optional)")# type="numpy"
qa_question = gr.Textbox(label="Input Question", lines=2, placeholder="You can:\n1. Upload an image and ask questions about it\n2. Ask text-only questions\n3. Upload an image without a question for automatic description")
qa_btn = gr.Button("Generate Response") # , variant="primary"
with gr.Column():
qa_answer = gr.Textbox(label="Answer", lines=10)
qa_btn.click(
fn=understand_with_image,
inputs=[qa_image, qa_question],
outputs=[qa_answer]
)
# 例子
gr.Examples(
examples=[
# Visual Q&A examples
["assets/examples/cat.png", "What color is the cat?"],
# Text Q&A examples
[None, "What are the main differences between electric and traditional fuel vehicles?"],
# Image description example
["assets/examples/cat.png", "...."],
],
inputs=[qa_image, qa_question],
outputs=[qa_answer],
fn=understand_with_image,
cache_examples=False,
)
if __name__ == "__main__":
print_gpu_memory()
print("🌐 启动Web界面...")
print("=" * 60)
demo.launch(server_name="0.0.0.0", server_port=8080) # , share=True4.2.editing_decoder.py 文件修改
经过GPU组分配计算流程和资源,可以运行图像编辑,但模型本身不保证长期稳定性和出图质量。可以复制以下文件替换原先git仓库下载的editing_decoder.py 文件。
python
import torch
from diffsynth import ModelManager
from diffsynth.models.utils import load_state_dict
from diffsynth.models.flux_dit import FluxDiT
from modeling.decoder.modules import ImageEmbeddingMerger
from transformers import AutoConfig
from .pipelines import NexusGenEditingPipeline
class FluxDiTStateDictConverter:
def __init__(self):
pass
def from_diffusers(self, state_dict):
return state_dict
def state_dict_converter():
return FluxDiTStateDictConverter()
class NexusGenEditingDecoder:
def __init__(self, decoder_path, flux_path, qwenvl_path, device='cuda', torch_dtype=torch.bfloat16, enable_cpu_offload=False, fp8_quantization=False):
self.device = device
self.torch_dtype = torch_dtype
self.enable_cpu_offload = enable_cpu_offload
self.fp8_quantization = fp8_quantization
self.pipe, self.embedding_merger = self.get_pipe(decoder_path, flux_path, qwenvl_path, device, torch_dtype)
def get_pipe(self, decoder_path, flux_path, qwenvl_path, device="cuda", torch_dtype=torch.bfloat16):
# 🔧 强制启用CPU offload以节省显存
print("🔧 强制启用CPU offload模式 (简化负载均衡版)")
# 强制使用CPU作为基础设备
model_manager = ModelManager(torch_dtype=torch_dtype, device='cpu')
# 分批加载模型并确保在CPU上
model_paths = [
f"{flux_path}/FLUX/FLUX.1-dev/text_encoder/model.safetensors",
f"{flux_path}/FLUX/FLUX.1-dev/text_encoder_2",
f"{flux_path}/FLUX/FLUX.1-dev/ae.safetensors",
]
print("📦 分批加载FLUX模型组件到CPU...")
for i, model_path in enumerate(model_paths):
print(f" 加载组件 {i+1}/3: {model_path.split('/')[-1]} -> CPU")
model_manager.load_models([model_path])
# 🔧 确保所有模型都在CPU上
for model in model_manager.model:
if hasattr(model, 'to'):
model.to('cpu')
print(f" ✅ 模型已移至CPU")
# 清理GPU缓存
torch.cuda.empty_cache()
print("✅ FLUX模型组件已全部加载到CPU")
# 加载解码器权重
state_dict = load_state_dict(decoder_path)
dit_state_dict = {key.replace("pipe.dit.", ""): value for key, value in state_dict.items() if key.startswith('pipe.dit.')}
embedding_merger_state_dict = {key.replace("embedding_merger.", ""): value for key, value in state_dict.items() if key.startswith('embedding_merger.')}
# 🔧 ImageEmbeddingMerger保持在cuda:2
model_config = AutoConfig.from_pretrained(qwenvl_path, trust_remote_code=True)
print("📦 初始化ImageEmbeddingMerger (cuda:2)...")
embedding_merger = ImageEmbeddingMerger(
model_config,
num_layers=1,
out_channel=4096,
expand_ratio=4, # 保持原始值以兼容权重
device="cuda:2" # 明确指定cuda:2
)
# 🔧 启用更激进的分块处理以节省显存
embedding_merger.set_chunked_processing(
enabled=True,
chunk_size=32, # 更小的chunk
projector_chunk_size=8 # 更小的projector chunk
)
# 加载权重
print("📦 加载ImageEmbeddingMerger权重...")
try:
embedding_merger.load_state_dict(embedding_merger_state_dict)
print("✅ ImageEmbeddingMerger权重加载成功")
except Exception as e:
print(f"❌ 权重加载失败: {e}")
raise e
embedding_merger.to("cuda:2", dtype=torch_dtype)
print("✅ ImageEmbeddingMerger已移至 cuda:2")
# 🔧 关键修改:DiT模型加载到cuda:1而不是cuda:2
print("📦 加载DiT模型到 cuda:1 (负载均衡)...")
FluxDiT.state_dict_converter = staticmethod(state_dict_converter)
model_manager.load_model_from_single_file(
decoder_path,
state_dict=dit_state_dict,
model_names=['flux_dit'],
model_classes=[FluxDiT],
model_resource='diffusers'
)
# 🔧 将DiT模型移动到cuda:1
dit_torch_dtype = torch_dtype if not self.fp8_quantization else torch.float8_e4m3fn
dit_model = model_manager.model[-1] # 最后加载的是DiT模型
dit_model.to("cuda:1", dtype=dit_torch_dtype) # 移动到cuda:1
print("✅ DiT模型已移至 cuda:1")
# 🔧 创建pipeline,指定device为cuda:1(DiT所在设备)
print("📦 创建pipeline (cuda:1)...")
pipe = NexusGenEditingPipeline.from_model_manager(model_manager, device="cuda:1")
# 🔧 强制启用CPU offload
print("🔄 启用pipeline CPU offload...")
pipe.enable_cpu_offload()
if self.fp8_quantization:
print("🔄 启用FP8量化...")
pipe.dit.quantize()
# 🔧 验证负载均衡状态
self._verify_load_balance()
return pipe, embedding_merger
def _verify_load_balance(self):
"""验证负载均衡状态"""
print("🔍 验证负载均衡状态:")
for device_name in ["cuda:1", "cuda:2"]:
if torch.cuda.is_available():
device_idx = int(device_name.split(':')[1])
allocated = torch.cuda.memory_allocated(device_idx) / 1024**3
reserved = torch.cuda.memory_reserved(device_idx) / 1024**3
print(f" {device_name}: 已分配 {allocated:.2f}GB, 已保留 {reserved:.2f}GB")
print("✅ 负载均衡验证完成")
@torch.no_grad()
def decode_image_embeds(self,
embed,
ref_embed=None,
embeds_grid=torch.tensor([[1, 18, 18]]),
ref_embeds_grid=torch.tensor([[1, 36, 36]]),
height=512,
width=512,
num_inference_steps=50,
seed=42,
negative_prompt="",
cfg_scale=1.0,
embedded_guidance=3.5,
**pipe_kwargs):
# 🔧 显存监控和清理
def print_memory_usage(stage):
print(f" 📊 {stage}:")
for device_name in ["cuda:1", "cuda:2"]:
if torch.cuda.is_available():
device_idx = int(device_name.split(':')[1])
allocated = torch.cuda.memory_allocated(device_idx) / 1024**3
reserved = torch.cuda.memory_reserved(device_idx) / 1024**3
print(f" {device_name}: 已分配 {allocated:.2f}GB, 已保留 {reserved:.2f}GB")
print("🔄 开始图像解码 (简化负载均衡版)")
print_memory_usage("解码开始")
# 🔧 数据准备在cuda:2(ImageEmbeddingMerger所在设备)
embeds_grid = embeds_grid.to(device="cuda:2", dtype=torch.long)
ref_embeds_grid = ref_embeds_grid.to(device="cuda:2", dtype=torch.long)
embed = embed.unsqueeze(0) if len(embed.size()) == 2 else embed
embed = embed.to(device="cuda:2", dtype=self.torch_dtype)
ref_embed = ref_embed.unsqueeze(0) if ref_embed is not None and len(ref_embed.size()) == 2 else ref_embed
ref_embed = ref_embed.to(device="cuda:2", dtype=self.torch_dtype) if ref_embed is not None else None
print_memory_usage("数据转移到cuda:2完成")
# 🔧 动态调整分块大小以进一步节省显存
total_tokens = embed.shape[1]
if ref_embed is not None:
total_tokens += ref_embed.shape[1]
if total_tokens > 300:
# 大尺寸输入使用超小chunk
self.embedding_merger.set_chunked_processing(
enabled=True,
chunk_size=16,
projector_chunk_size=4
)
print(f"🔧 大尺寸输入检测 ({total_tokens} tokens),使用超小chunk")
else:
# 中等尺寸输入使用小chunk
self.embedding_merger.set_chunked_processing(
enabled=True,
chunk_size=32,
projector_chunk_size=8
)
# 🔧 在cuda:2上执行嵌入合并
print("🔄 执行嵌入合并 (cuda:2)...")
visual_emb = self.embedding_merger(embed, embeds_grid, ref_embed, ref_embeds_grid)
visual_emb = visual_emb.to(device="cuda:2", dtype=self.torch_dtype)
# 清理输入数据
del embed, ref_embed
with torch.cuda.device("cuda:2"):
torch.cuda.empty_cache()
print_memory_usage("嵌入合并完成")
# 🔧 关键修改:将visual_emb转移到cuda:1(DiT所在设备)
print("🔄 转移visual_emb: cuda:2 -> cuda:1")
visual_emb = visual_emb.to("cuda:1")
# 清理cuda:2的缓存
with torch.cuda.device("cuda:2"):
torch.cuda.empty_cache()
print_memory_usage("数据转移到cuda:1完成")
# 🔧 在cuda:1上执行diffusion pipeline
print("🔄 执行diffusion pipeline (cuda:1)...")
image = self.pipe(prompt="",
image_embed=visual_emb,
num_inference_steps=num_inference_steps,
embedded_guidance=embedded_guidance,
negative_prompt=negative_prompt,
cfg_scale=cfg_scale,
height=height,
width=width,
seed=seed,
**pipe_kwargs)
# 最终清理
del visual_emb
with torch.cuda.device("cuda:1"):
torch.cuda.empty_cache()
print_memory_usage("解码完成")
print("✅ 简化负载均衡图像解码完成")
return image4.3.modules.py 文件修改
同理,加载模型和后续推理计算采用不同cuda,避免显存占用完报出异常。
python
import math
import torch
import torch.nn as nn
from typing import Optional, Tuple
from transformers.activations import ACT2FN
from transformers.modeling_rope_utils import _compute_default_rope_parameters
def rotate_half(x):
"""Rotates half the hidden dims of the input."""
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
def apply_multimodal_rotary_pos_emb(q, k, cos, sin, mrope_section, unsqueeze_dim=1):
mrope_section = mrope_section * 2
cos = torch.cat([m[i % 3] for i, m in enumerate(cos.split(mrope_section, dim=-1))], dim=-1).unsqueeze(
unsqueeze_dim
)
sin = torch.cat([m[i % 3] for i, m in enumerate(sin.split(mrope_section, dim=-1))], dim=-1).unsqueeze(
unsqueeze_dim
)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
class Qwen2_5_VLRotaryEmbedding(nn.Module):
def __init__(self, config, device=None):
super().__init__()
# BC: "rope_type" was originally "type"
if hasattr(config, "rope_scaling") and config.rope_scaling is not None:
self.rope_type = config.rope_scaling.get("rope_type", config.rope_scaling.get("type"))
else:
self.rope_type = "default"
self.max_seq_len_cached = config.max_position_embeddings
self.original_max_seq_len = config.max_position_embeddings
self.config = config
self.rope_init_fn = _compute_default_rope_parameters
inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device)
self.register_buffer("inv_freq", inv_freq, persistent=False)
self.original_inv_freq = self.inv_freq
def _dynamic_frequency_update(self, position_ids, device):
"""
dynamic RoPE layers should recompute `inv_freq` in the following situations:
1 - growing beyond the cached sequence length (allow scaling)
2 - the current sequence length is in the original scale (avoid losing precision with small sequences)
"""
seq_len = torch.max(position_ids) + 1
if seq_len > self.max_seq_len_cached: # growth
inv_freq, self.attention_scaling = self.rope_init_fn(
self.config, device, seq_len=seq_len, **self.rope_kwargs
)
self.register_buffer("inv_freq", inv_freq, persistent=False) # TODO joao: may break with compilation
self.max_seq_len_cached = seq_len
if seq_len < self.original_max_seq_len and self.max_seq_len_cached > self.original_max_seq_len: # reset
self.register_buffer("inv_freq", self.original_inv_freq, persistent=False)
self.max_seq_len_cached = self.original_max_seq_len
@torch.no_grad()
def forward(self, x, position_ids):
if "dynamic" in self.rope_type:
self._dynamic_frequency_update(position_ids, device=x.device)
# Core RoPE block. In contrast to other models, Qwen2_5_VL has different position ids for the grids
# So we expand the inv_freq to shape (3, ...)
inv_freq_expanded = self.inv_freq[None, None, :, None].float().expand(3, position_ids.shape[1], -1, 1)
position_ids_expanded = position_ids[:, :, None, :].float() # shape (3, bs, 1, positions)
# Force float32 (see https://github.com/huggingface/transformers/pull/29285)
device_type = x.device.type
device_type = device_type if isinstance(device_type, str) and device_type != "mps" else "cpu"
with torch.autocast(device_type=device_type, enabled=False):
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(2, 3)
emb = torch.cat((freqs, freqs), dim=-1)
cos = emb.cos()
sin = emb.sin()
# Advanced RoPE types (e.g. yarn) apply a post-processing scaling factor, equivalent to scaling attention
cos = cos * self.attention_scaling
sin = sin * self.attention_scaling
return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
"""
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
"""
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
if n_rep == 1:
return hidden_states
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
class Qwen2_5_VLAttention(nn.Module):
def __init__(self, config, layer_idx: Optional[int] = None):
super().__init__()
self.config = config
self.layer_idx = layer_idx
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.hidden_size // self.num_heads
self.num_key_value_heads = config.num_key_value_heads
self.num_key_value_groups = self.num_heads // self.num_key_value_heads
self.is_causal = True
self.attention_dropout = config.attention_dropout
self.rope_scaling = config.rope_scaling
if (self.head_dim * self.num_heads) != self.hidden_size:
raise ValueError(
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
f" and `num_heads`: {self.num_heads})."
)
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=True)
self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True)
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True)
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
def forward(
self,
hidden_states: torch.Tensor,
position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, # necessary, but kept here for BC
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
bsz, q_len, _ = hidden_states.size()
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
query_states = query_states.view(bsz, q_len, -1, self.head_dim).transpose(1, 2)
key_states = key_states.view(bsz, q_len, -1, self.head_dim).transpose(1, 2)
value_states = value_states.view(bsz, q_len, -1, self.head_dim).transpose(1, 2)
cos, sin = position_embeddings
query_states, key_states = apply_multimodal_rotary_pos_emb(
query_states, key_states, cos, sin, self.rope_scaling["mrope_section"]
)
# repeat k/v heads if n_kv_heads < n_heads
key_states = repeat_kv(key_states, self.num_key_value_groups)
value_states = repeat_kv(value_states, self.num_key_value_groups)
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
# Fix precision issues in Qwen2-VL float16 inference
# Replace inf values with zeros in attention weights to prevent NaN propagation
if query_states.dtype == torch.float16:
attn_weights = torch.where(torch.isinf(attn_weights), torch.zeros_like(attn_weights), attn_weights)
# upcast attention to fp32
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)
attn_output = torch.matmul(attn_weights, value_states)
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
f" {attn_output.size()}"
)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.reshape(bsz, q_len, -1)
attn_output = self.o_proj(attn_output)
return attn_output
class Qwen2MLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = config.intermediate_size
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
return down_proj
class Qwen2RMSNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-6):
"""
Qwen2RMSNorm is equivalent to T5LayerNorm
"""
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states):
input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(torch.float32)
variance = hidden_states.pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
return self.weight * hidden_states.to(input_dtype)
def extra_repr(self):
return f"{tuple(self.weight.shape)}, eps={self.variance_epsilon}"
class Qwen2_5_VLDecoderLayer(nn.Module):
def __init__(self, config, layer_idx: int):
super().__init__()
self.hidden_size = config.hidden_size
self.self_attn = Qwen2_5_VLAttention(config, layer_idx)
self.mlp = Qwen2MLP(config)
self.input_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.post_attention_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
def forward(
self,
hidden_states: torch.Tensor,
position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, # necessary, but kept here for BC
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
residual = hidden_states
hidden_states = self.input_layernorm(hidden_states)
# Self Attention
hidden_states = self.self_attn(
hidden_states=hidden_states,
position_embeddings=position_embeddings,
)
hidden_states = residual + hidden_states
# Fully Connected
residual = hidden_states
hidden_states = self.post_attention_layernorm(hidden_states)
hidden_states = self.mlp(hidden_states)
hidden_states = residual + hidden_states
return hidden_states
class ImageEmbeddingMerger(nn.Module):
def __init__(self, config, num_layers=2, out_channel=4096, expand_ratio=4, device='cpu'):
super().__init__()
self.config = config
self.num_layers = num_layers
self.layers = nn.ModuleList([Qwen2_5_VLDecoderLayer(config, layer_idx) for layer_idx in range(num_layers)])
# 🔧 保持原始结构以兼容预训练权重
print(f"📦 ImageEmbeddingMerger配置 (修复版):")
print(f" 输入维度: {config.hidden_size}")
print(f" 中间维度: {out_channel * expand_ratio} (expand_ratio={expand_ratio})")
print(f" 输出维度: {out_channel}")
self.projector = nn.Sequential(
Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps),
nn.Linear(config.hidden_size, out_channel * expand_ratio), # 保持16384
Qwen2RMSNorm(out_channel * expand_ratio, eps=config.rms_norm_eps),
ACT2FN[config.hidden_act],
nn.Linear(out_channel * expand_ratio, out_channel),
Qwen2RMSNorm(out_channel, eps=config.rms_norm_eps)
)
self.base_grid = torch.tensor([[1, 72, 72]], device=device)
self.rotary_emb = Qwen2_5_VLRotaryEmbedding(config=config, device=device)
# 🔧 显存优化配置
self.enable_chunked_processing = True
self.chunk_size = 256 # 每次处理256个tokens
self.projector_chunk_size = 64 # projector的chunk大小
def get_position_ids(self, image_grid_thw):
"""
Generates position ids for the input embeddings grid.
modified from the qwen2_vl mrope.
"""
batch_size = image_grid_thw.shape[0]
spatial_merge_size = self.config.vision_config.spatial_merge_size
t, h, w = (
image_grid_thw[0][0],
image_grid_thw[0][1],
image_grid_thw[0][2],
)
llm_grid_t, llm_grid_h, llm_grid_w = (
t.item(),
h.item() // spatial_merge_size,
w.item() // spatial_merge_size,
)
scale_h = self.base_grid[0][1].item() / h.item()
scale_w = self.base_grid[0][2].item() / w.item()
range_tensor = torch.arange(llm_grid_t).view(-1, 1)
expanded_range = range_tensor.expand(-1, llm_grid_h * llm_grid_w)
time_tensor = expanded_range * self.config.vision_config.tokens_per_second
t_index = time_tensor.long().flatten().to(image_grid_thw.device)
h_index = torch.arange(llm_grid_h).view(1, -1, 1).expand(llm_grid_t, -1, llm_grid_w).flatten().to(image_grid_thw.device) * scale_h
w_index = torch.arange(llm_grid_w).view(1, 1, -1).expand(llm_grid_t, llm_grid_h, -1).flatten().to(image_grid_thw.device) * scale_w
# 3, B, L
position_ids = torch.stack([t_index, h_index, w_index]).unsqueeze(0).repeat(batch_size, 1, 1).permute(1, 0, 2)
return position_ids
def forward(self, embeds, embeds_grid, ref_embeds=None, ref_embeds_grid=None):
"""主前向传播函数 - 修复版"""
def print_tensor_info(tensor, name):
if tensor is not None:
print(f" 📊 {name}: {tensor.shape}, {tensor.dtype}, {tensor.device}")
print("🔄 ImageEmbeddingMerger forward pass (修复版):")
print_tensor_info(embeds, "embeds")
print_tensor_info(ref_embeds, "ref_embeds")
# 🔧 根据输入大小选择处理策略
total_tokens = embeds.shape[1]
if ref_embeds is not None:
total_tokens += ref_embeds.shape[1]
if self.enable_chunked_processing and total_tokens > self.chunk_size:
print(f"📦 使用分块处理策略 (总tokens: {total_tokens})")
return self._forward_chunked(embeds, embeds_grid, ref_embeds, ref_embeds_grid)
else:
print(f"📦 使用标准处理策略 (总tokens: {total_tokens})")
return self._forward_standard(embeds, embeds_grid, ref_embeds, ref_embeds_grid)
def _forward_standard(self, embeds, embeds_grid, ref_embeds=None, ref_embeds_grid=None):
"""标准前向传播,适用于小尺寸嵌入"""
position_ids = self.get_position_ids(embeds_grid)
hidden_states = embeds
if ref_embeds is not None:
position_ids_ref_embeds = self.get_position_ids(ref_embeds_grid)
position_ids = torch.cat((position_ids, position_ids_ref_embeds), dim=-1)
hidden_states = torch.cat((embeds, ref_embeds), dim=1)
position_embeddings = self.rotary_emb(hidden_states, position_ids)
# 🔧 使用梯度检查点减少显存
for i, layer in enumerate(self.layers):
if self.training and hidden_states.requires_grad:
hidden_states = torch.utils.checkpoint.checkpoint(
layer, hidden_states, position_embeddings, use_reentrant=False
)
else:
hidden_states = layer(hidden_states, position_embeddings)
# 在每层后清理不必要的缓存
if torch.cuda.is_available() and i < len(self.layers) - 1:
torch.cuda.empty_cache()
# 🔧 分块应用projector以减少显存峰值
hidden_states = self._apply_projector_chunked(hidden_states)
return hidden_states
def _forward_chunked(self, embeds, embeds_grid, ref_embeds=None, ref_embeds_grid=None):
"""分块处理策略,适用于大尺寸嵌入 - 修复版"""
print(f" 🔄 分块处理 (chunk_size={self.chunk_size})")
# 处理目标嵌入
print(" 📦 处理目标嵌入...")
target_features = self._process_embeddings_chunked(embeds, embeds_grid)
# 清理中间变量
torch.cuda.empty_cache()
if ref_embeds is not None:
# 处理参考嵌入
print(" 📦 处理参考嵌入...")
ref_features = self._process_embeddings_chunked(ref_embeds, ref_embeds_grid)
# 拼接结果
print(" 📦 拼接处理后的特征...")
final_features = torch.cat([target_features, ref_features], dim=1)
# 清理中间变量
del target_features, ref_features
torch.cuda.empty_cache()
return final_features
else:
return target_features
def _process_embeddings_chunked(self, embeddings, grid):
"""分块处理嵌入 - 修复版"""
chunks = []
num_chunks = (embeddings.shape[1] + self.chunk_size - 1) // self.chunk_size
# 🔧 修复:预先计算完整的position_ids
full_position_ids = self.get_position_ids(grid)
for i in range(num_chunks):
start_idx = i * self.chunk_size
end_idx = min((i + 1) * self.chunk_size, embeddings.shape[1])
print(f" 处理chunk {i+1}/{num_chunks} (tokens {start_idx}:{end_idx})")
chunk = embeddings[:, start_idx:end_idx]
# 🔧 修复:为chunk提取对应的position_ids片段
chunk_position_ids = full_position_ids[:, :, start_idx:end_idx]
chunk_result = self._process_single_chunk(chunk, chunk_position_ids)
chunks.append(chunk_result)
# 清理中间变量
del chunk, chunk_result, chunk_position_ids
torch.cuda.empty_cache()
result = torch.cat(chunks, dim=1)
del chunks, full_position_ids
torch.cuda.empty_cache()
return result
def _process_single_chunk(self, chunk, chunk_position_ids):
"""处理单个chunk - 修复版"""
# 🔧 修复:直接使用传入的chunk_position_ids,而不是重新计算
hidden_states = chunk
position_embeddings = self.rotary_emb(hidden_states, chunk_position_ids)
# 使用梯度检查点处理Transformer层
for layer in self.layers:
if self.training and hidden_states.requires_grad:
hidden_states = torch.utils.checkpoint.checkpoint(
layer, hidden_states, position_embeddings, use_reentrant=False
)
else:
hidden_states = layer(hidden_states, position_embeddings)
# 分块应用projector
result = self._apply_projector_chunked(hidden_states)
# 清理
del hidden_states, position_embeddings
torch.cuda.empty_cache()
return result
def _apply_projector_chunked(self, hidden_states):
"""分块应用projector,减少显存峰值"""
if hidden_states.shape[1] <= self.projector_chunk_size:
# 小张量直接处理
return self.projector(hidden_states)
print(f" 📦 分块应用projector (chunk_size={self.projector_chunk_size})")
chunks = []
for i in range(0, hidden_states.shape[1], self.projector_chunk_size):
end_idx = min(i + self.projector_chunk_size, hidden_states.shape[1])
chunk = hidden_states[:, i:end_idx]
# 应用projector
chunk_result = self.projector(chunk)
chunks.append(chunk_result)
# 清理
del chunk, chunk_result
torch.cuda.empty_cache()
result = torch.cat(chunks, dim=1)
del chunks
torch.cuda.empty_cache()
return result
def set_chunked_processing(self, enabled, chunk_size=None, projector_chunk_size=None):
"""动态设置分块处理参数"""
self.enable_chunked_processing = enabled
if chunk_size is not None:
self.chunk_size = chunk_size
if projector_chunk_size is not None:
self.projector_chunk_size = projector_chunk_size
print(f"🔧 分块处理设置: enabled={enabled}, chunk_size={self.chunk_size}, projector_chunk_size={self.projector_chunk_size}")
# 🔧 修复说明:
# 1. 在_process_embeddings_chunked中预先计算完整的position_ids
# 2. 为每个chunk提取对应的position_ids片段 (chunk_position_ids)
# 3. 在_process_single_chunk中直接使用传入的chunk_position_ids
# 4. 确保position_embeddings与chunk的大小完全匹配