本文是GraphRAG 工作原理分步解析的第二部分,如果你还没有阅读过第一部分,可以点击我的主页查看。接下来让我们进入正题。
查询
图构建完成后,我们就可以开始查询了。搜索功能的实现可在GraphRAG项目的structure_search目录中找到。
本地搜索
如果您有特定问题,可以使用GraphRAG提供的本地搜索功能(以下为一种示例方法)。
lua
graphrag query \
--root ./ragtest \
--method local \
--query "What kind of retribution is Laura seeking, and why?"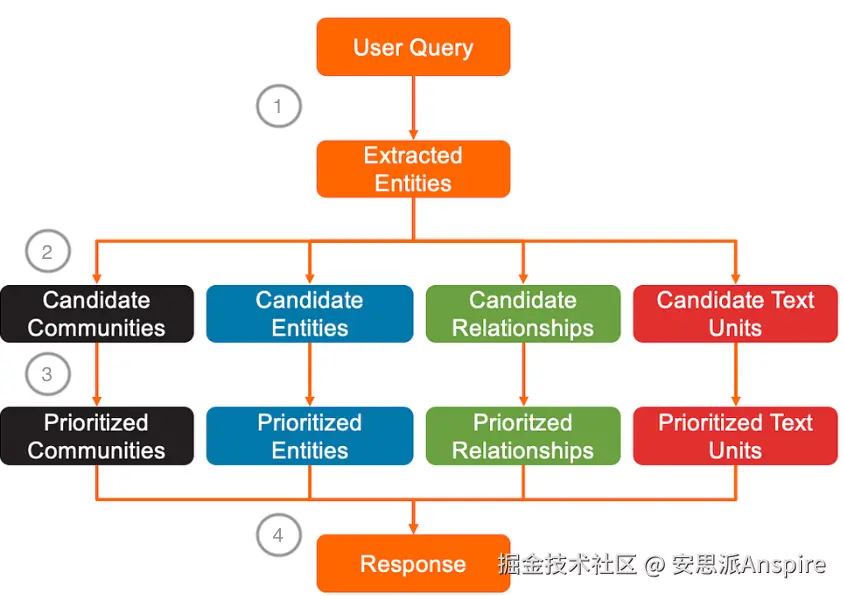
本地搜索的关键步骤
- 社区报告、文本单元、实体、关系和协变量(如有)会从ragtest/output/目录下的Parquet文件中加载,这些文件是在图构建后自动保存的。
然后,用户查询会被转换为嵌入向量,并计算其与每个实体描述的嵌入向量之间的语义相似度。

实体及其与用户查询的余弦距离快照
会检索出N个语义最相似的实体。N的值由配置中的超参数top_k_mapped_entities定义。
奇怪的是,GraphRAG会进行2倍过采样,实际检索出2 * top_k_mapped_entities个实体。这样做是为了确保提取到足够的实体,因为有时检索到的实体可能具有无效ID。

与用户查询语义最相似的实体快照。在这个示例中,top_k_mapped_entities=10,因此过采样后本应检索到20个实体,但只有17个具有有效ID,所以实际检索到17个实体。rank列显示实体节点的度数。
摘要图:本地搜索中提取实体的检索过程
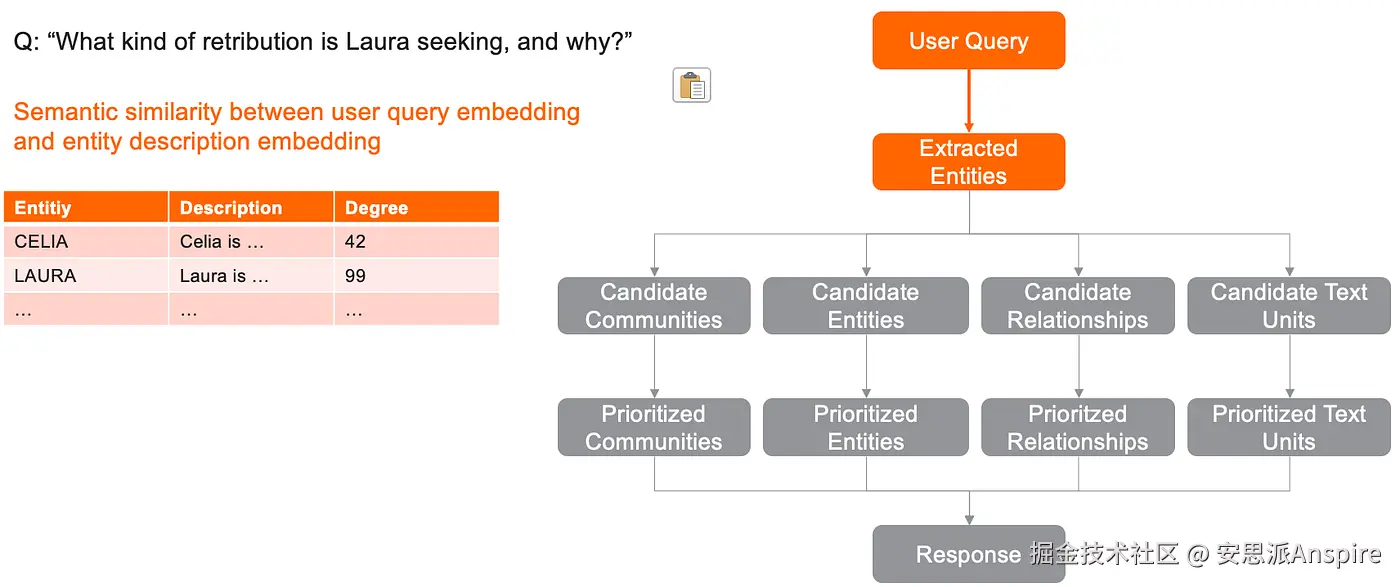
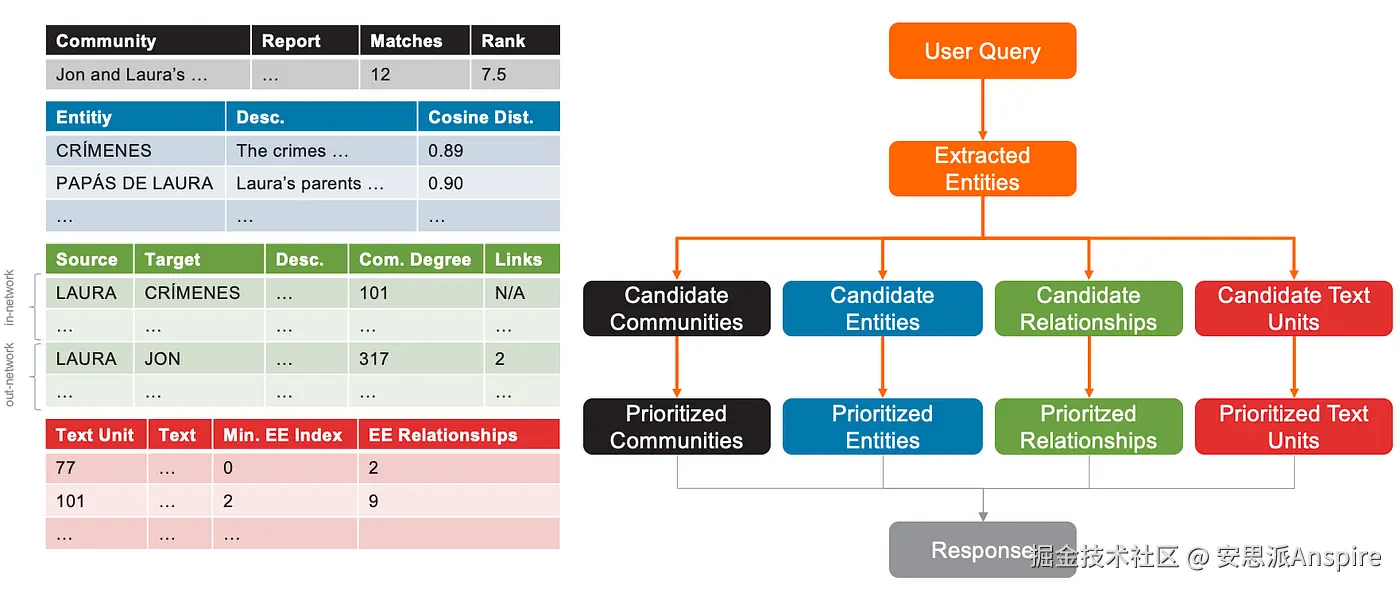
- 所有提取的实体都成为候选实体。提取实体所属的社区、关系和文本单元则分别成为候选社区、候选关系和候选文本单元。
具体来说:
-
候选社区指所有包含至少一个提取实体的社区。
-
候选关系指所有图中以提取实体为源节点或目标节点的边。
-
候选文本单元指书中包含至少一个提取实体的文本块。
摘要图:本地搜索中候选社区、实体、关系和文本单元的选择过程
- 候选对象会被排序,最相关的项会排在各自列表的顶部。这确保了回答查询时优先考虑最重要的信息。
优先级排序是必要的,因为LLM的上下文长度并非无限,能传递给模型的信息量有限。配置中设置的超参数决定了为实体、关系、文本单元和社区分配的上下文窗口token数量。默认情况下,text_unit_prop=0.5且community_prop=0.1,这意味着配置中指定的max_tokens的50%将用于文本单元,10%用于社区报告,剩余40%用于实体和关系的描述。max_tokens的默认值为12000。
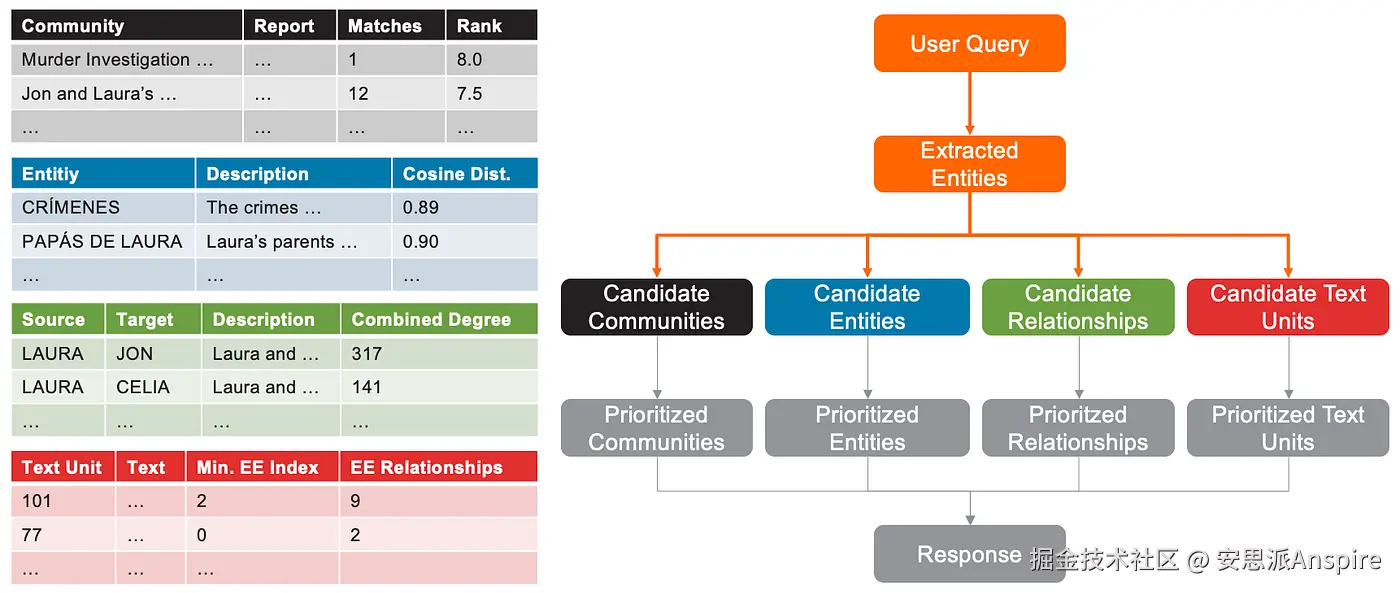
- 社区按其匹配数量(即社区中提取的实体出现的不同文本单元的数量)排序。若出现平局,则按其排名(LLM分配的重要性)排序。假设max_tokens=12000且community_prop=0.1,那么社区报告最多可占用1200个token。社区报告只能完整包含,不进行截断------要么完整纳入某个社区报告,要么完全不纳入。

按匹配数量和排名排序的候选社区快照。匹配数指提取实体出现的不同文本单元的数量。排名是LLM确定的社区重要性评分。
- 候选实体不进行排序,保持实体按与用户查询的语义相似度排序的顺序。会尽可能多的将候选实体添加到上下文中。如果max_tokens的40%分配给实体和关系,意味着最多有4800个token可用。

候选实体快照
- 候选关系的优先级排序因是网络内关系还是网络外关系而不同。网络内关系指两个提取实体之间的关系。网络外关系指一个提取实体与另一个非提取实体集中的实体之间的关系。网络内候选关系按其组合度数(源节点和目标节点度数之和)排序。网络外候选关系首先按外部实体与内部实体的链接数量排序,若出现平局,则按组合度数排序。

网络内关系表。rank列显示组合度数。

网络外关系表示例。rank列显示组合度数,attributes列显示外部实体与内部实体(Crímenes、Papás de Laura和Laura)的链接数量。
查找网络内和网络外关系是一个迭代过程,一旦可用的token空间被填满(在我们的示例中,可用token = 4800 --- 实体描述所占用的token),该过程就会停止。网络内关系会优先添加到上下文中,因为它们被认为更重要。然后,在空间允许的情况下,再添加网络外关系。

优先排序的候选关系快照。注意前两行是网络内关系。默认情况下不使用权重,且网络内关系的链接信息已过时/不正确。
- 候选文本单元按提取实体的顺序排序,其次按与该文本单元相关联的提取实体关系数量排序。实体顺序确保了提及与用户查询语义最相似的实体的文本单元被优先考虑。例如,如果Crímenes是与用户查询语义最相似的实体,而文本单元CB6F...是提取出Crímenes的文本块,那么即使与该文本单元相关联的提取实体关系很少,CB6F...也会排在列表顶部。

优先排序的文本单元表示例
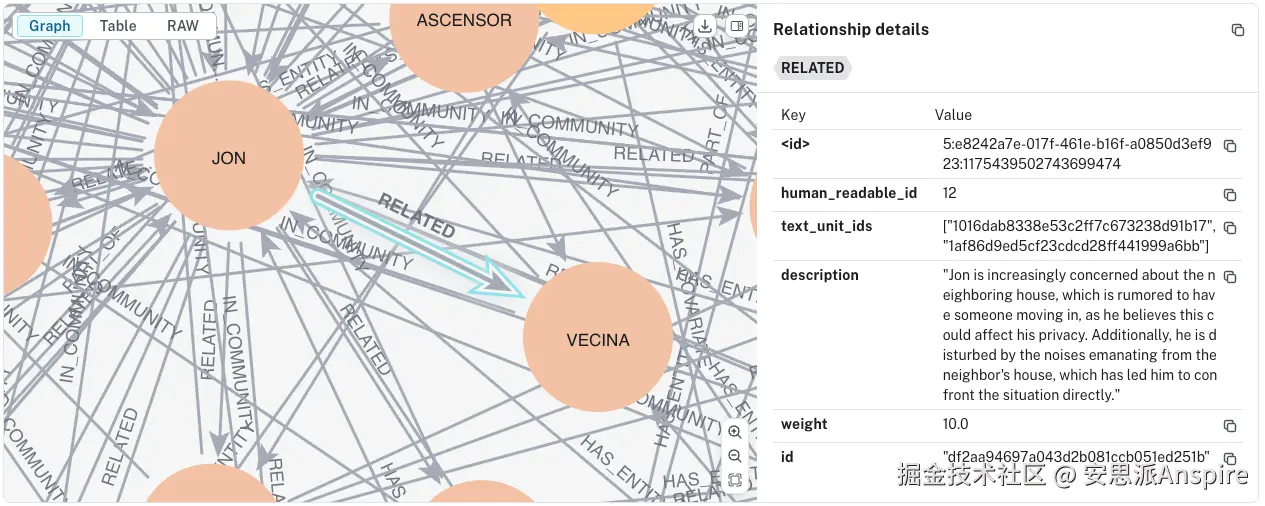
每个图边(关系)都有一个属性,表明它来自哪些文本单元。这一属性使得追踪提取实体的关系与其被检测到的文本单元成为可能。
假设max_tokens=12000且text_unit_prop=0.5,那么文本单元最多可占用6000个token。与社区报告一样,文本单元会被添加到上下文中,直到达到token限制,不进行截断。
摘要图:本地搜索中候选社区、实体、关系和文本单元的排序过程
- 最后,经过优先级排序的社区报告、实体、关系和文本单元的描述------按此顺序------会被拼接起来,作为上下文提供给LLM,由LLM生成对用户查询的详细回答。
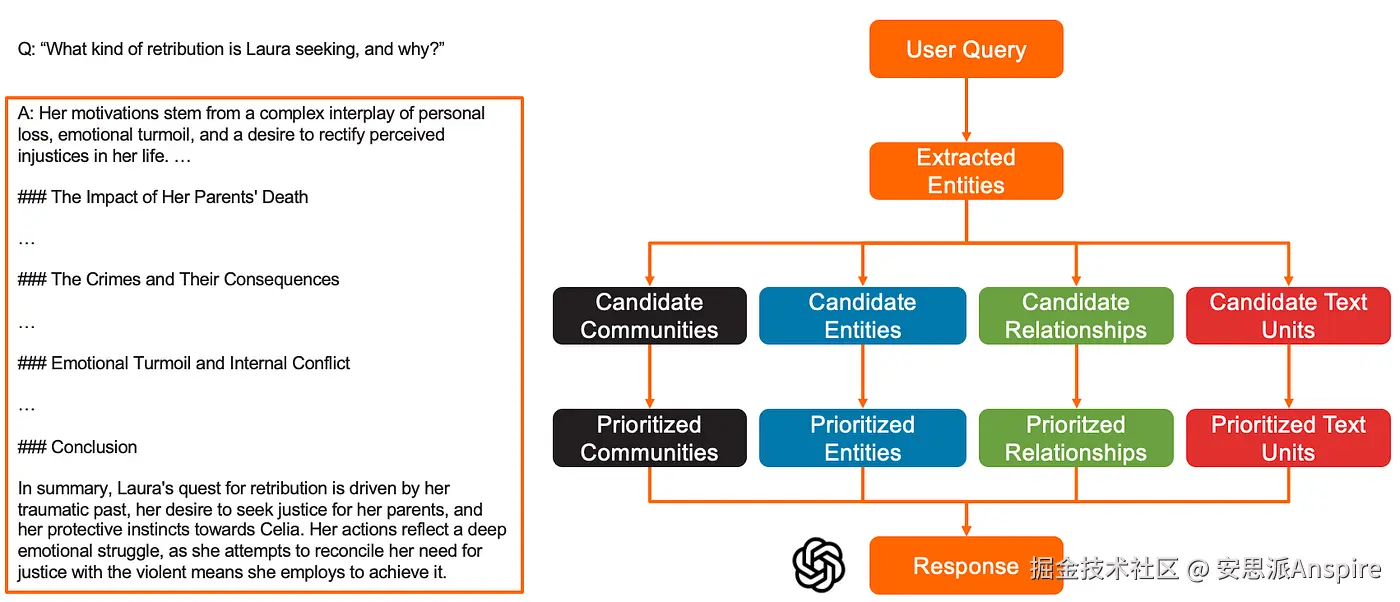
摘要图:本地搜索中对用户查询的回答生成过程
全局搜索
如果您有一般性问题,请使用全局搜索功能(以下是其中一种示例用法)。
lua
graphrag query \
--root ./ragtest \
--method global \
--query "What themes are explored in the book?"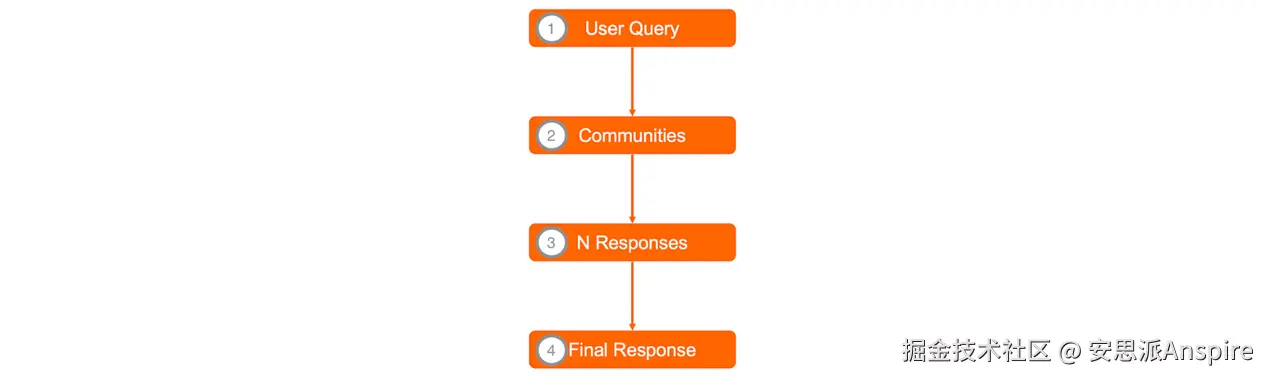
全局搜索的关键步骤
- 社区报告和实体从保存它们的Parquet文件中加载。
对于每个社区,会计算一个occurence_weight。occurence_weight表示该社区相关实体出现的不同文本单元的标准化计数。该值反映了该社区在文档中的普遍程度。


社区表快照
- 所有社区先被打乱顺序,然后进行分批。打乱顺序可以减少偏差,确保并非所有最相关的社区都集中在同一批次中。每个批次中的社区按其community_weight排序。本质上,实体出现在多个文本块中的社区会被优先考虑。

摘要图:全局搜索中的社区分批过程
- 对于每个批次,LLM会以社区报告为上下文,针对用户查询生成多个回答,并为每个回答分配一个分数,以反映其对回答用户问题的帮助程度(提示词)。通常每个批次生成5个回答。
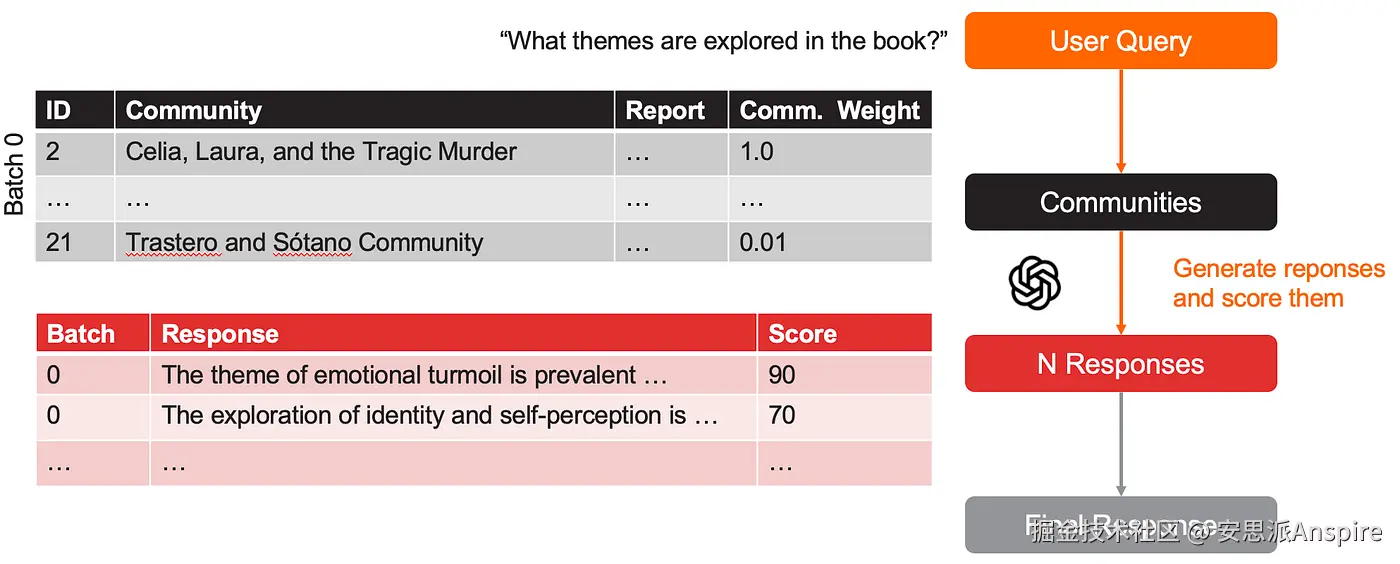
摘要图:全局搜索中每个批次的回答生成过程
所有回答会按分数排序,分数为0的回答会被丢弃。

按分数排序的所有用户问题回答表。analyst列表示批次ID。
- 经过排序的回答文本会被拼接成一个输入,作为上下文传递给LLM,以生成用户问题的最终答案(提示词)。

摘要图:全局搜索中的最终回答生成过程
结论
本文通过真实数据和代码层面的见解,逐步介绍了微软GraphRAG实现的图构建、本地搜索和全局搜索的过程。自2024年初我开始使用这个项目以来,官方文档已经有了显著改进,但本文的深入探讨填补了知识空白,揭示了其内部运作机制。迄今为止,这是我遇到的关于GraphRAG的最详细、最新的资料,希望对您有所帮助。
现在,我建议您尝试超越默认配置:试着调整参数、微调实体提取的提示词,或使用不同的索引方法。大胆实验,在您自己的项目中充分利用GraphRAG的强大功能吧!