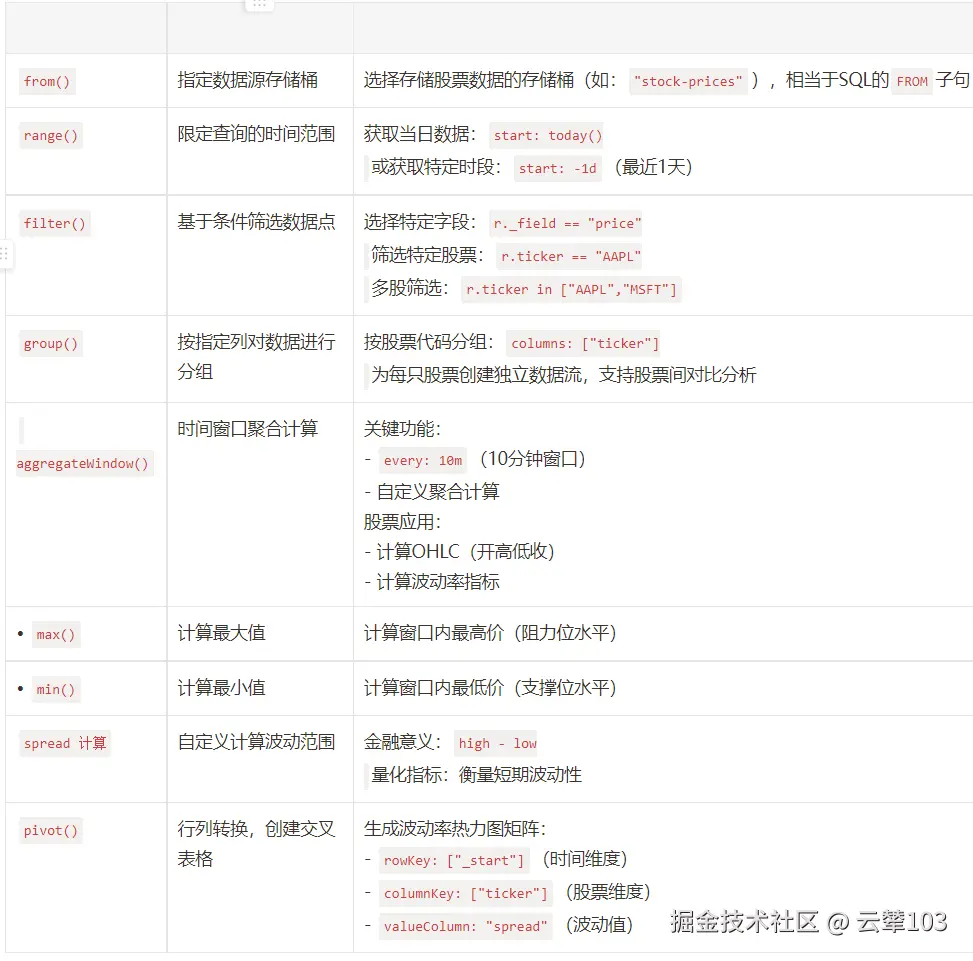
1.Bucket和Measurement
InfluxDB 数据模型将时间序列数据组织成Bucket和Measurement。 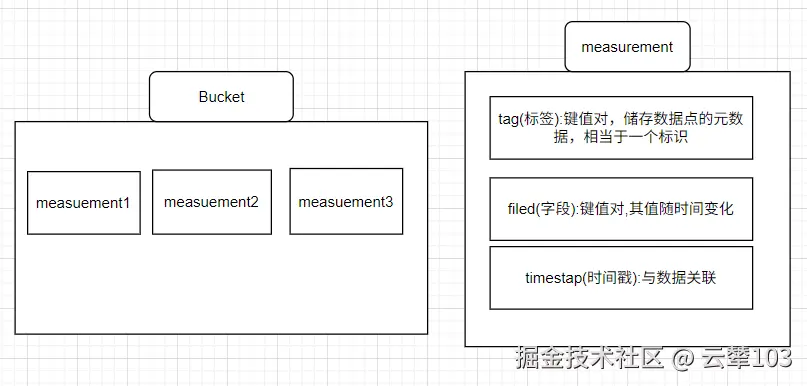
2.初体验
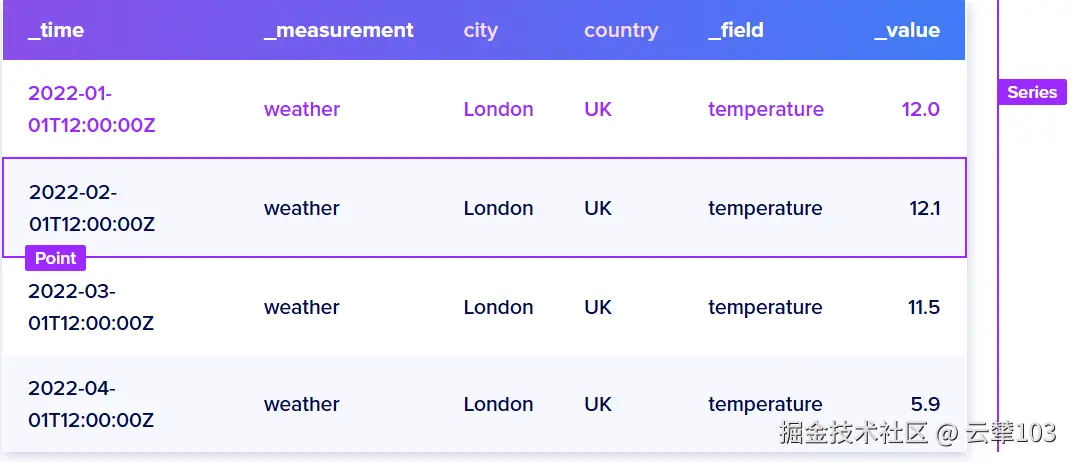
横着每一条数据对应一个Point,所有按照顺序排列的Point构成Series
如果使用了influxdb就要引入以下依赖:
Cargo.toml
Rust
influxdb2 = "0.5.2"
influxdb2-structmap = "0.2"
dotenvy = "0.15"
num-traits = "0.2"
chrono = "0.4.41"
tokio = { version = "1", features = ["full"]}
futures = "0.3.31"客户端初始化:
Rust
async fn init_client() -> Client {
let host = dotenvy::var("INFLUXDB_HOST").expect("INFLUXDB_HOST not set in environment variables");
let org = dotenvy::var("INFLUXDB_ORG").expect("INFLUXDB_ORG not set in environment variables");
let token = dotenvy::var("INFLUXDB_TOKEN").expect("INFLUXDB_TOKEN not set in environment variables");
Client::new(host, org, token)
}同时需要创建.env文件,放在Cargo.toml同级目录下,对应的格式为
ini
INFLUXDB_HOST = http://localhost:8086
INFLUXDB_ORG = manager
INFLUXDB_TOKEN = your-token3.写入数据
行协议元素
行协议的每一行都包含以下元素
- measurement:标识要将数据存储在其中的measurement的字符串。
- tag set(标签集) :逗号分隔的键值对列表,每个键值对代表一个标签。标签键和值是不带引号的字符串。
- field set(字段集) :逗号分隔的键值对列表,每个键值对代表一个字段。字段键是不带引号的字符串。
- timestamp(时间戳) :与数据关联的 Unix时间戳。

对应的行协议
Rust
weather,city=London,country=UK temperature=12.0 1641038400000000000
weather,city=London,country=UK temperature=12.1 1643716800000000000Rust实现
Rust
async fn write_stock_data(client: Client) -> Result<(), Box<dyn std::error::Error>> {
let apple = DataPoint::builder("stock_price")
.tag("ticker", "AAPL")
.field("open", 182.51)
.field("high", 184.13)
.field("low", 182.13)
.field("close", 183.86)
.field("volume", 78591230.0)
.build()?;
let tesla = DataPoint::builder("stock_price")
.tag("ticker", "TSLA")
.field("open", 242.68)
.field("high", 247.77)
.field("low", 239.60)
.field("close", 246.39)
.field("volume", 103929123.0)
.build()?;
client.write("stock-prices", stream::iter(vec![apple, tesla])).await?;
println!("成功写入股票数据");
Ok(())
}4.查询数据
使用Flux查询
- from():从 InfluxDB 存储桶查询数据。
- range():根据时间范围过滤数据。
- filter() :根据列值过滤数据。每一行由
r表示,每一列由r的属性表示。
php
from(bucket: "testt")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "weather")
|> filter(fn: (r) => r["_field"] == "temperature")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> yield(name: "mean")InfluxQL查询
SELECT:指定要查询的字段和标签。FROM:指定要查询的测量。使用测量名称或完全限定的测量名称,其中包括数据库和保留策略。例如:db.rp.measurement。WHERE:根据字段、标签和时间过滤数据。
sql
SELECT MEAN("temperature") AS "mean_temperature"
FROM "weather"
WHERE time >= '2023-01-01T00:00:00Z' AND time <= '2023-01-02T00:00:00Z'Rust实现
在Rust实现查询功能时,我们需要创建一个StockPrice结构体,因为后面在获得查询结果时,我们需要显示声明res的类型为Vec<StockPrice>,同时为其实现Default的trait,即默认构造方法。
Rust
#[derive(Debug, FromDataPoint)]
pub struct StockPrice {
ticker: String,
value: f64,
time: DateTime<FixedOffset>,
}
impl Default for StockPrice {
fn default() -> Self {
Self {
ticker: "".to_string(),
value: 0_f64,
time: chrono::MIN_DATETIME.with_timezone(&FixedOffset::east(7 * 3600)),
}
}
}具体查询代码
Rust
async fn get_stock_data(client: Client) -> Result<(), Box<dyn std::error::Error>> {
let ticker = "AAPL";
let query_str = format!(
r#"
from(bucket: "stock-prices")
|> range(start: -1w)
|> filter(fn: (r) => r.ticker == "{}")
|> last()
"#,
ticker
);
let query = Query::new(query_str);
let res: Vec<StockPrice> = client.query(Some(query)).await?;
if let Some(data) = res.first() {
println!("最新股票数据:");
println!("Ticker: {}", data.ticker);
println!("价格: ${:.2}", data.value);
println!("时间: {}", data.time.format("%Y-%m-%d %H:%M:%S"));
} else {
println!("未找到 {} 的数据", ticker);
}
Ok(())
}5.处理数据
处理数据一般是通过各种函数来实现,看下面这个案例。
Rust
from(bucket: "stock-prices")
|> range(start: today())
|> filter(fn: (r) => r._field == "price")
|> group(columns: ["ticker"]) // 按股票分组
|> aggregateWindow( // 每10分钟计算高-低波动范围
every: 10m,
fn: (values) => ({
high: max(values: values.value),
low: min(values: values.value),
spread: max(values: values.value) - min(values: values.value)
})
)
|> pivot( // 转换为波动率热力图数据
rowKey: ["_start"],
columnKey: ["ticker"],
valueColumn: "spread"
)各个函数的功能如下: